C++11的发展史:

C++11中的{}:

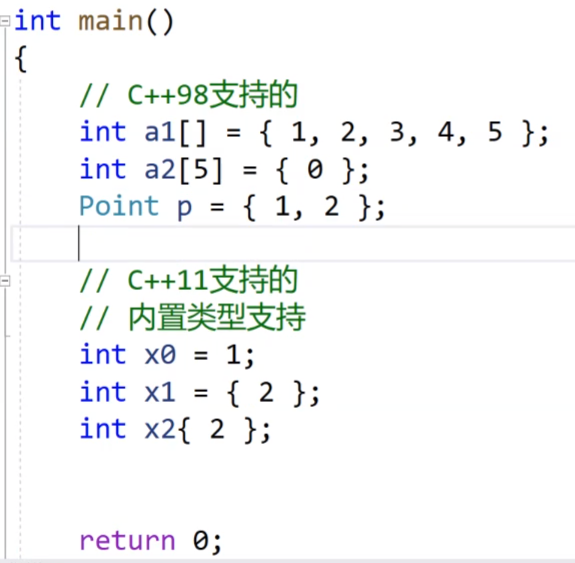
看这个图片,我们的C++11是所有的对象都可以使用{}来进行初始化,之前我们的int类型的数据要使用赋值符号来进行初始化,现在的话我们可以直接使用花括号来进行,并且连赋值符号都可以去掉。
不光是内置类型的,自定义类型的也是可以的:

普通的括号,是我们之前调用构造函数初始化的方式。
之前我们讲过隐式类型转换有单参数的隐式类型转换和多参数的隐式类型转换。
我们看上面图片的第二行使用花括号初始化的方式这个就是我们的多参数的隐式类型转换。
第三行的只有一个参数没有花括号,这个就是单参数的隐式类型转换。
为什么我们可以只传一个参数,因为我们的Date日期类的构造函数的参数都是缺省参数。
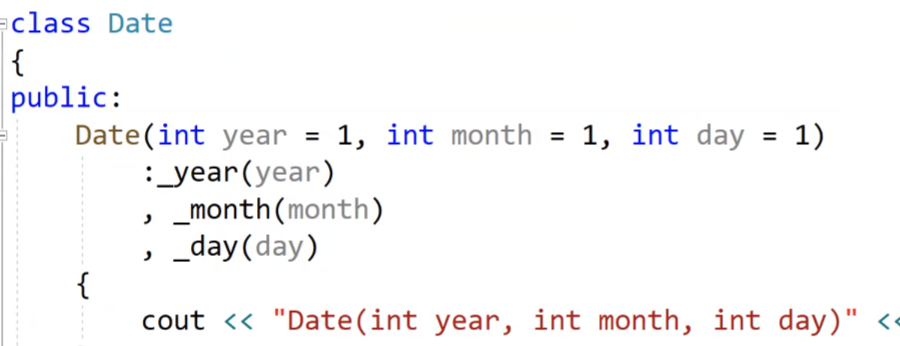
我们传一个,后面的参数就可以使用缺省值代替;

我们的d1本质是构造+拷贝构造,拿后面的数据构造一个临时对象的日期类,然后拷贝构造给d1,但是经过编译器优化以后就是直接构造;

看上面,这种方式的使用场景,我们的vector里面存的是Date,我们push_back()数据,我们可以传有名对象进去,也可以传匿名对象进去,这两种的话,其实都比不上我们直接花括号进行多参数的隐式类型转换来得方便。
我们看上面这个图的d3,他的话,我们的C++11刚才说了就是所有的对象都可以使用{}来进行初始化,这个d3我们可以省略赋值符号,直接花括号就可以。
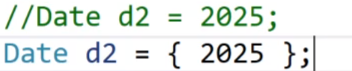

但是d2就不能去掉赋值符号了,因为他没有花括号,如果有花括号的话,其实是可以去掉赋值符号的,即便你是单参数也是可以的。

{2024, 7, 25} 这种大括号初始化形式创建了一个未命名的对象 。它没有被赋予一个实际的变量名,只是用于临时构造出一个合适类型(这里应该是 Date 类型相关对象)的数据。
临时对象具有常性,不可修改,我们对他引用的话就要加上const修饰。
C++11中的std::initializer_list:
initializer_list我们之前就已经学习过了,
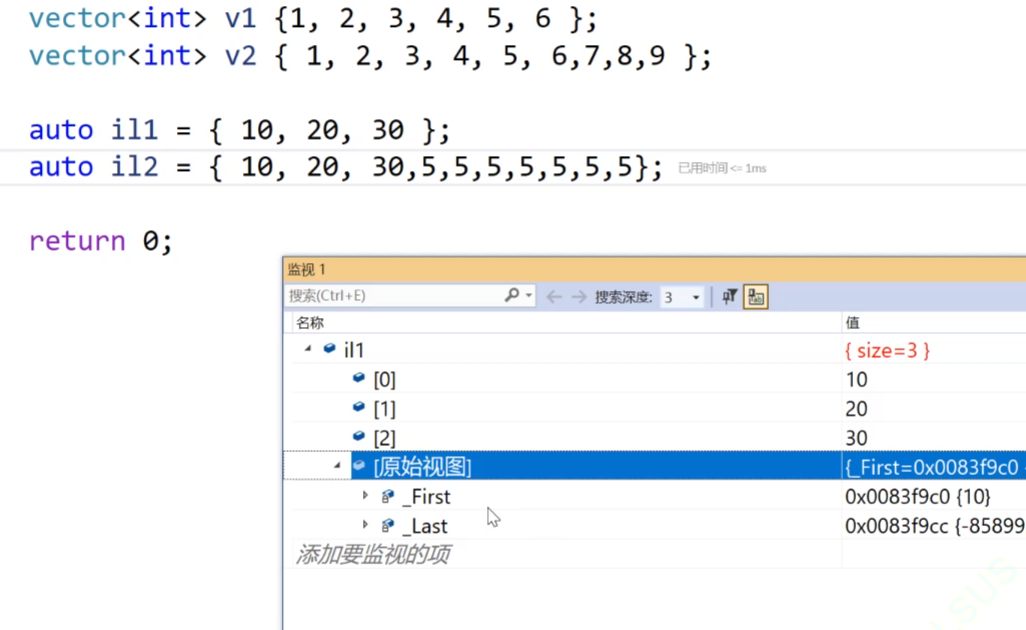
initializer_list的底层是把这个数组拷贝过来,他的内部其实是存着两个指针,这两个指针分别指向这个数组的开始和结束。所以你可以传任意大的数组过来,因为他的这个对象里面只存储着两个指针,这两个指针指向数组的开始和结束。
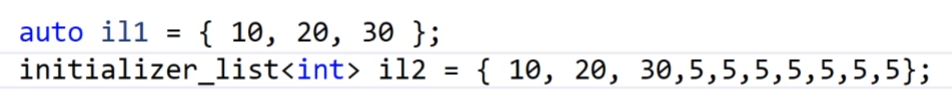
当然我们可以使用auto,也可以正牌的使用initializer_list,因为auto会自动地识别的,你使用这种initializer_list的初始化方式,auto就会自动的识别为initializer_list类型的。
其实这里的上面的v1和v2的初始化方式initializer_list得到的,也是一种隐式类型转化,使用initializer_list的方式构造一个vector,然后再拷贝构造给给v1,当然编译器优化以后,相当于是直接进行构造了。 直接构造的话相当于是传参直接传给上面的initializer_list,
细节上说就是后面的花括号隐式类型转换使用initializer_list构造成一个vector,然后再拷贝构造给v1。
右值引用和移动语义:

我们上面的初始化方式的改变其实对C++影响不大,但是这里的这个右值引用和移动语义意义是非常大的

左值可以取地址,右值不能取地址。(右值一般来说不可修改)
因为左值的话,都是我们定义出来分配到某些空间的,右值的话,他一般不在这些空间里面,他可能是存在寄存器里面的。
右值可以是字符串常量,常数,临时对象,表达式之类的。
右值一般都是不可修改的。
我们说左值是相对于右值持久存在的,右值的话,生命周期基本上就是当前这一行,当前一行结束的话,他基本上就销毁了。

看上面的图片,这个右值x+y表达式,这个结果就是由临时对象存起来的。
string定义的匿名对象也是右值。(匿名对象)取不到地址。
string定义的有名对象是左值,这个我们可以取到地址。
左值引用和右值引用:
左值引用就是给左值取别名,右值引用就是给右值取别名:

我们看第二点,他说左值引用一般引用左值,不能直接引用右值,加上const的左值引用可以引用右值,因为右值是不可修改的,所以右值引用也就不能被修改,所以我们的左值引用加上const就可以引用右值。
所以我们的函数传参的时候,我们的参数一般都是const修饰的引用类型,这样的话,我们既可以传左值进去,也可以传右值进去。
然后第三点说的是,我们的右值引用一般引用的是右值,但是有的时候也可以引用左值,我们可以使用move,move是一个函数

我们看上面的图片,我们使用右值引用给我们的右值取别名。
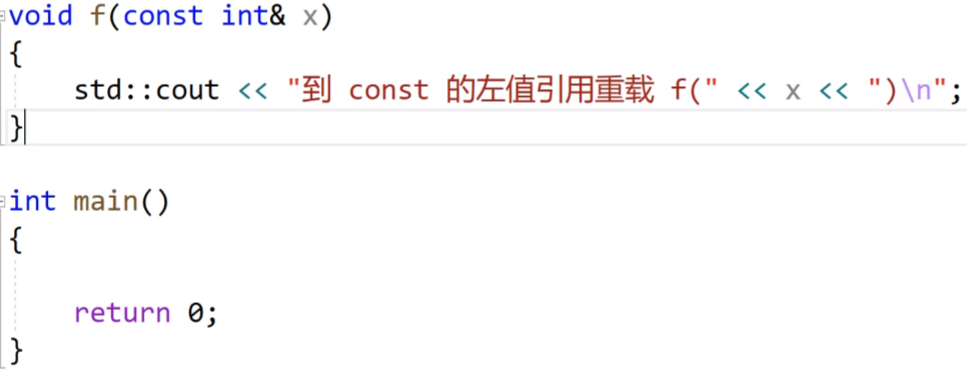
然后是这个,普通的左值引用是因用不了右值的。(左值是可以被修改的,但是右值不能被修改,这里显然就是权限的放大)。

这里加上const修饰就没问题了。
我们继续看:

右值引用也是引用不了左值的。
这里我们要用move来进行:

我们的move函数的作用是强转:

move可以强制的把左值转成右值引用。
后面的两点我们就暂且不讲,后面的话我们会讲。
左值和右值的参数匹配:

我们看我们的函数,我们的这个函数可以传·左值,也可以传右值。
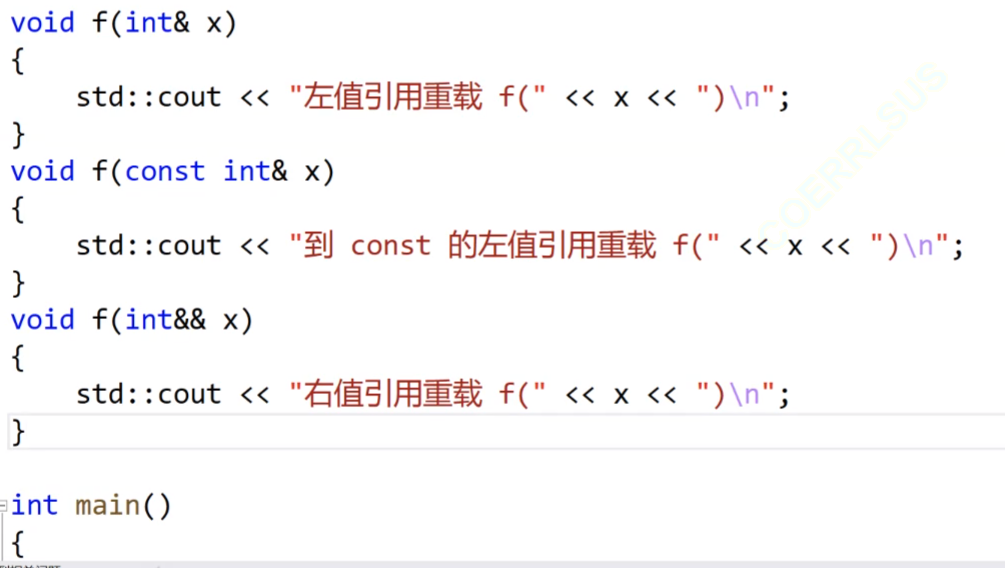
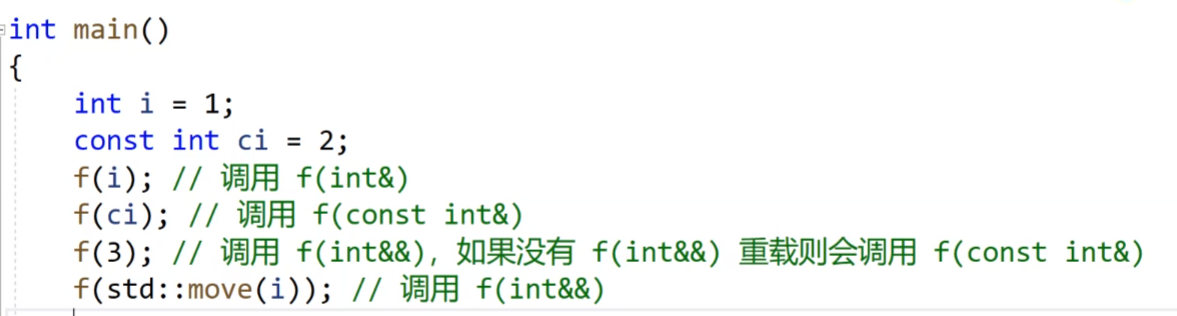
但是当我们函数重载,把这三种类型都重载起来的话(这里要说一下,函数的参数一样,但是一个有缺省值,一个没有缺省值,这个不能构成函数重载,因为如果我们要调这个函数不传参数的话,他知道我们调的是有缺省值的,但是如果我们调这个函数传参的话,他就不知道我们调的是哪个函数了),我们就是那个适合我们使用哪个函数。

我们看上面的,我们先看左边的图,我们的函数传值返回(自定义类型的)要调用拷贝构造,生成一份临时对象返回,然后我们的主函数,把我们的临时对象的数据拷贝构造给给新初始化的对象。
调用两次拷贝构造。没有优化的话代价比较大。
移动构造和移动赋值:
我们新学两个默认的成员函数,

我们看上面的概念,移动构造是一种拷贝构造,移动构造的话,他的第一个参数我们要求他是右值引用。参数列表后面也可以有其他的参数,但是必须要有缺省值。
我们看上面我们的红色字体写出来的,这两个函数我们构成了函数重载,右值的话,我们就使用右值引用,左值的话,我们使用左值引用。
我们这里写一个移动构造:
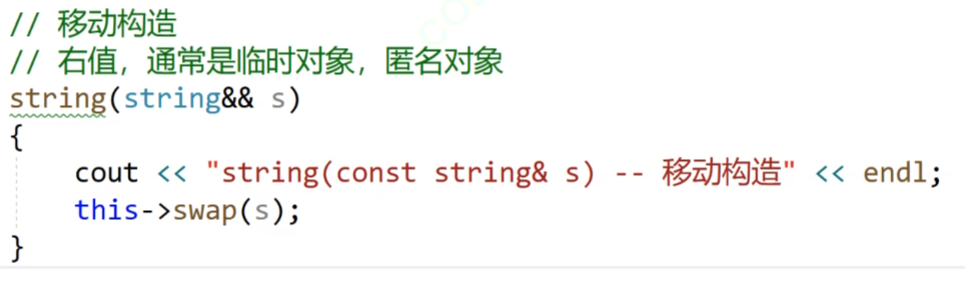
移动构造的参数是右值,右值的话,一般生命周期只有这个一行,这一行结束以后右值就销毁了。
因为这个右值快被销毁了,但是我们想要里面的数据,我们要把他拷贝一份然后销毁吗?
那就有点浪费了,我们就调用swap函数,直接把这个右值的数据和我们的this指针指向的对象的数据进行交换,然后右值里面的数据就到了我们这了,因为我们的这个拷贝构造作用的对象都是刚刚实例化的对象,我们的数据初始状态是这个, 
把这个数据和右值里面的数据交换,然后右值销毁就可以了。这样的话消耗也比较小。
我们继续往下看:
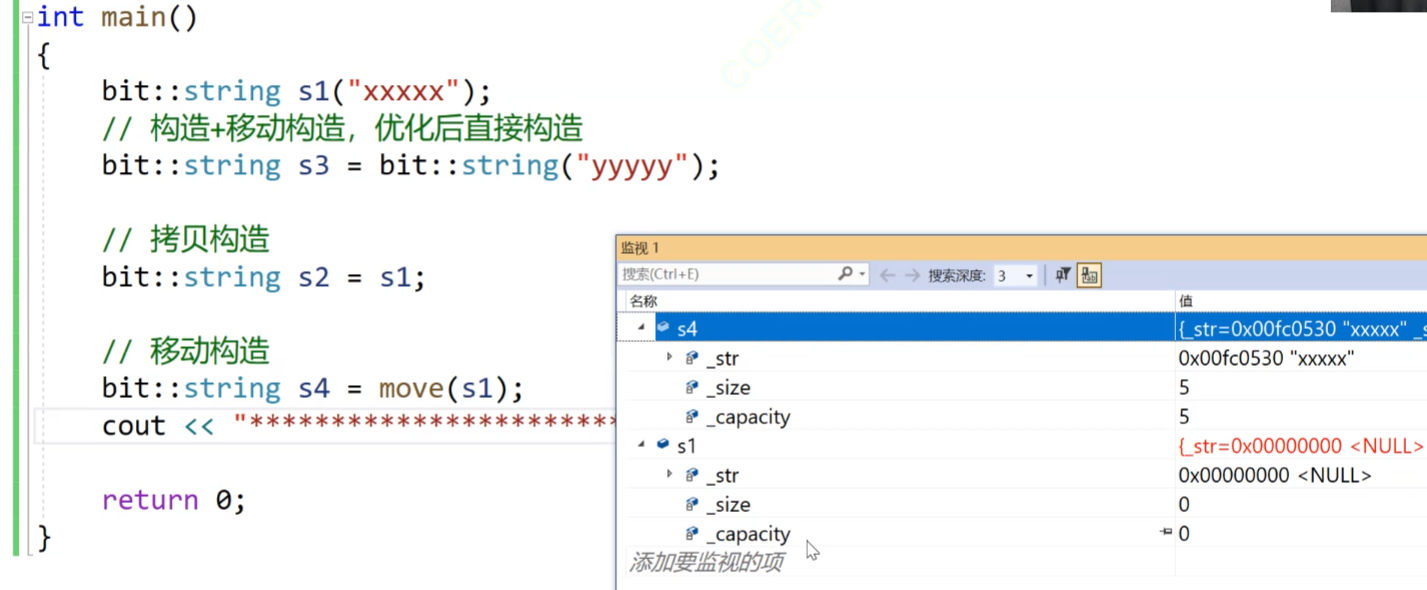
我们看这个代码,我们的s3的话,我们右边实现进行一个构造+移动构造,因为他是右边构造了一个匿名对象,然后把匿名对象拷贝构造给s3,所以他就是移动构造。
s2的话,虽然我们的s1构造的他也是传了一个常量字符串,可以算右值,但是他是把s1构造出来,然后让s1拷贝构造给s2,因为s1是一个有名对象,是一个左值,所以是拷贝构造。
s4的话,他是把左值使用move强转成右值,所以这就是移动构造,但是我们使用move的话有风险,我们看图中的右边,我们的s1使用move强转后移动构造给s4,我们的s1的数据居然被销毁了
当我们有了移动构造的话,有什么好处呢?

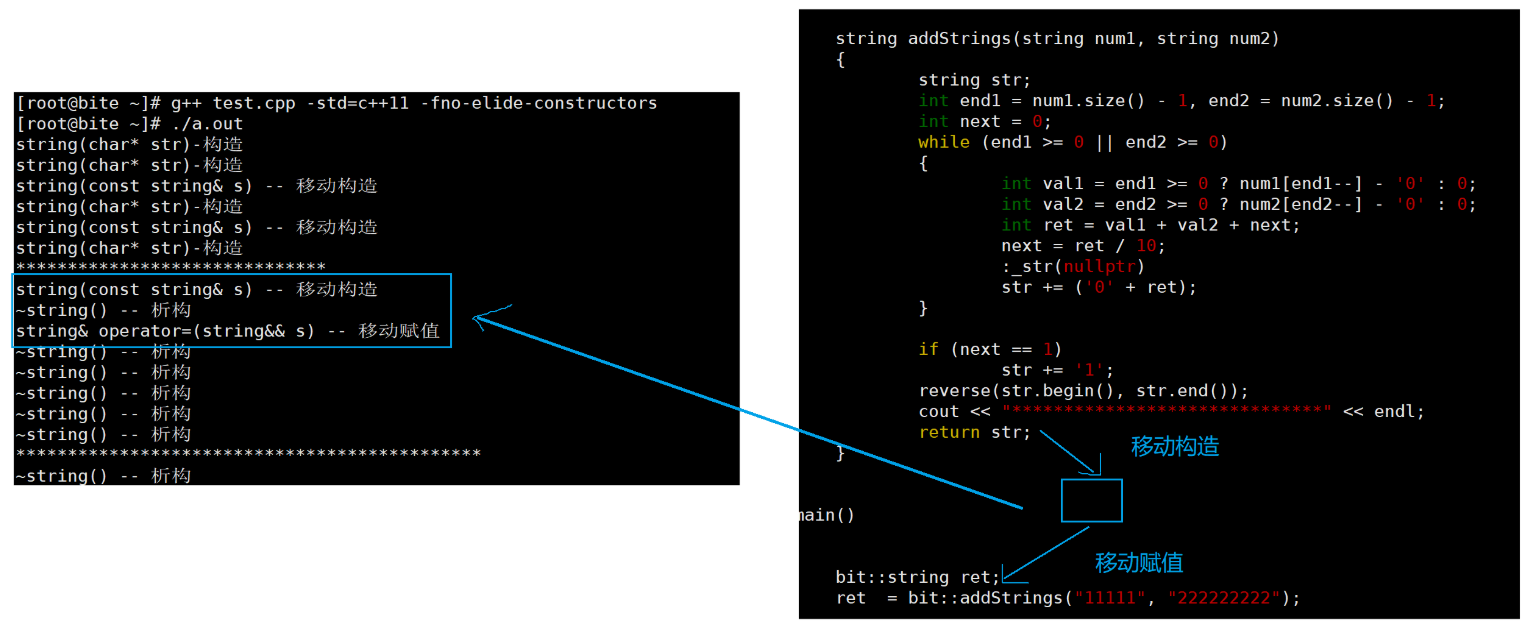
我们看上面的图片:
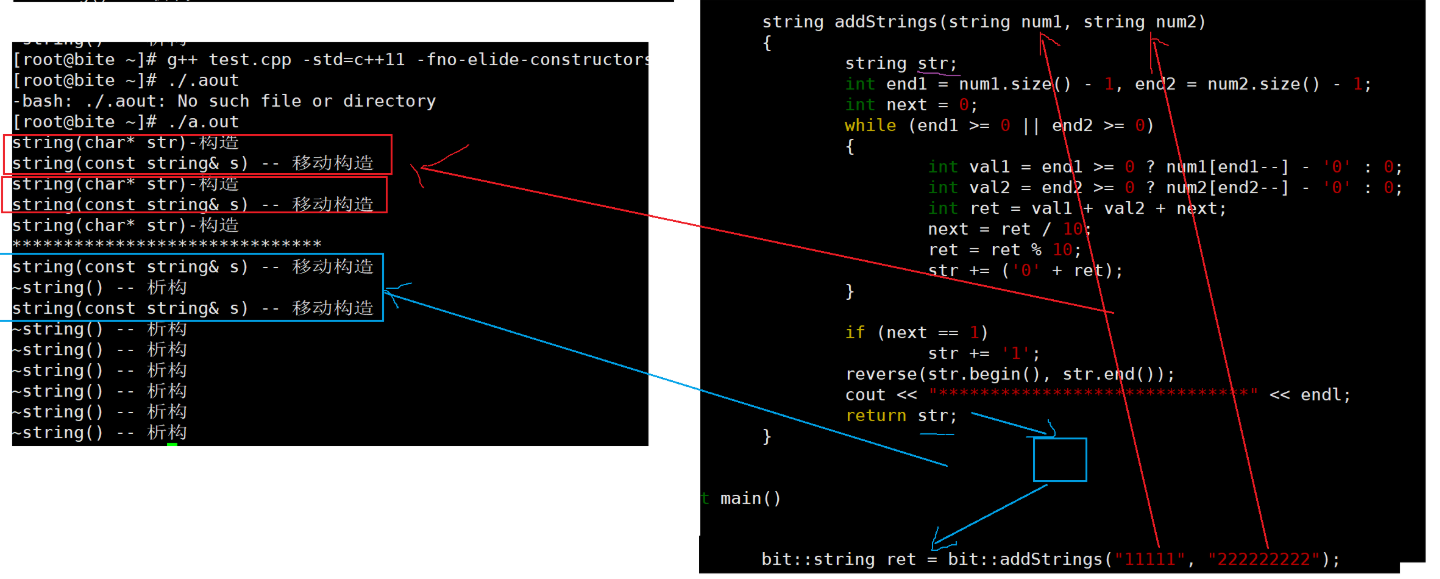
我们看主函数,我们调用addstrings函数,我们的函数我们传了两个(常量字符串)右值,如果只有拷贝构造的时候,我们的addstrings函数的传值返回会调用拷贝构造生成临时对象,然后临时对象调用拷贝构造给到ret。
但是如果有移动构造的话,我们看临时对象调用拷贝构造赋值给ret这个过程,因为他是一个临时对象,所以拷贝构造升级成移动构造,我们直接把数据交换就可以了, 然后我们看str返回值,这里的话你可以认为编译器会给他进行一个特殊处理,相当于给他move一下让他拷贝构造生成临时对象的过程 也变成移动构造。,swap两次就好了,极大的减少了负担。
这里就是大大的改变,我们的左值的话,我们还是要深拷贝,但是我们的右值的话,直接swap就可以了。
在vs上我们看不了他的不优化的场景,不优化的场景我们可以在Linux上看:
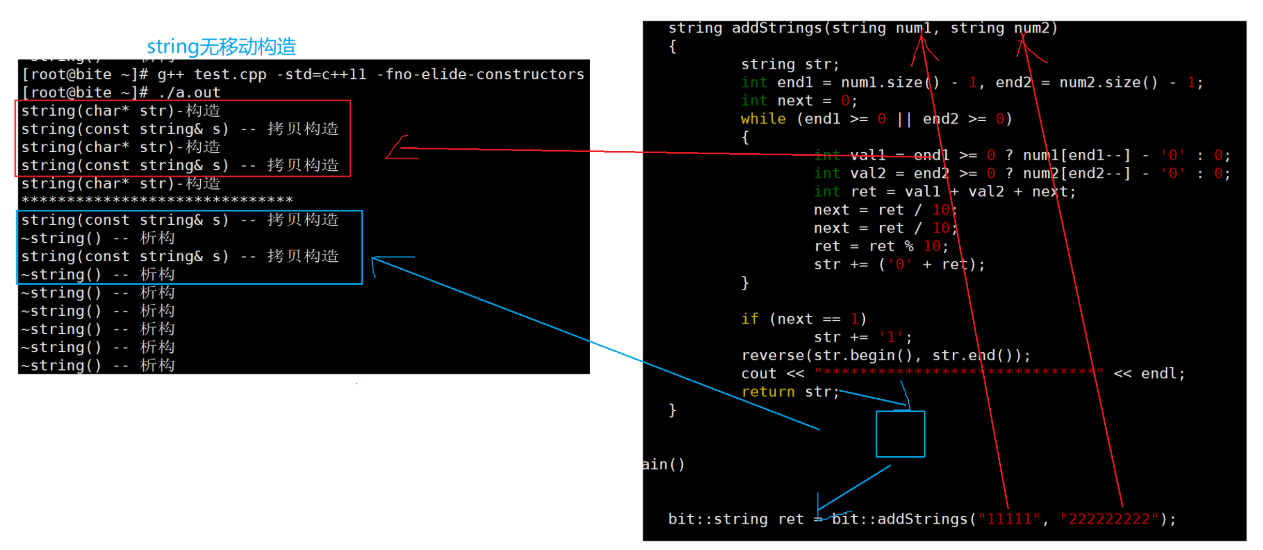
我们看这个没有移动构造的,,没有的话,我们的两个参数传值传参都是要调用拷贝构造的,这个消耗就比较大,,然后函数结束的时候传值返回要调用拷贝构造生成临时对象,临时对象再拷贝构造给到ret。
//这个是我们有移动构造的:
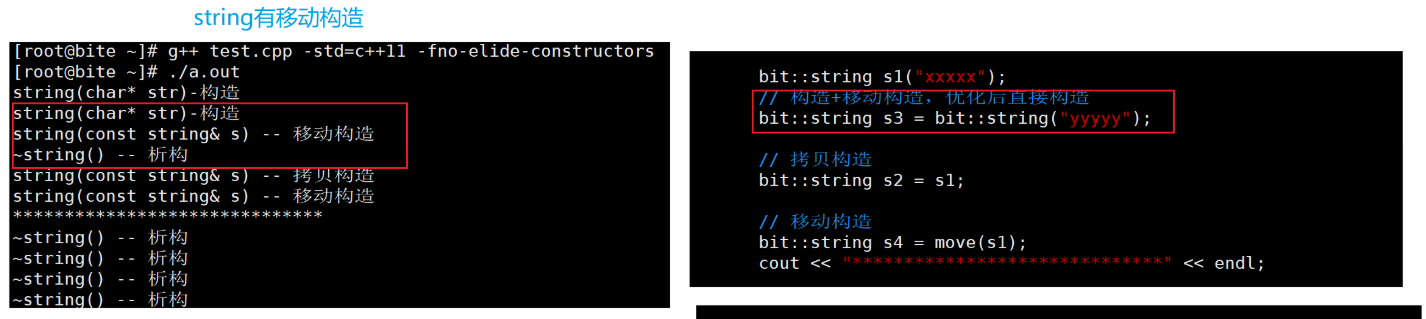
上面之前的拷贝构造升级成移动构造,消耗减少;
上面的右值(临时对象和匿名对象)在结束这行代码以后,生命周期结束,就会自动的调用析构。
移动赋值:
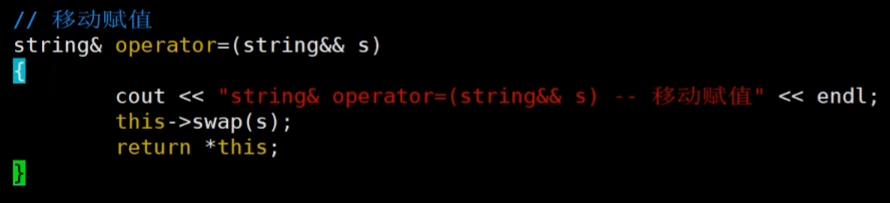
移动赋值,
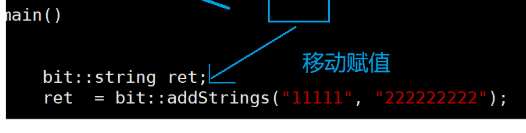
当我们的主函数里面是这种的话,我们的ret是已经存在的,ret是已经存在的话,那他就不是拷贝构造了,他就是复制重载,
当我们实现了移动赋值的话:
我们看这个图片:我们的函数传值返回会调用拷贝构造,有移动构造的话,我们的编译器会把str转换为右值可以调用移动构造,然后我们的会调用复制重载,但是我们的这个函数的返回值是一个临时对象,他是一个右值,他这一行结束以后生命周期就结束了,
 那我们为什么要在开辟一段空间然后赋值给他呢?
那我们为什么要在开辟一段空间然后赋值给他呢?
我们可以直接把他和我们的ret的数据进行交换呢?
我们交换以后右值会带着我们不要的数据进行销毁。这就很好。
当然可以,我们这个移动复制做到了。
容易混淆的点:
看这个代码:
为什么我们的传值返回和传值传参要调用拷贝构造?

我们之前学习类和对象的时候,我们说自定义类型的传值传参和传值返回会调用拷贝构造,这样的消耗比较大,我们尽量还是使用传引用传参,这样消耗小一点。
但是有的时候我们的传引用不太行。
这里我们看上面的函数,我们在函数里面实例化出了一个对象,然后我们返回这个对象,主函数里面我们接受他给 result(类实例化的对象)来初始化,
我们这里的话就不能使用传引用返回来进行,因为出了我们的函数以后我们的对象 obj 就自动的调用析构函数进行析构了,这时候我们的引用就成了野引用了。
{ 举个例子:野引用就是(我把林冲都给杀了,然后我再派人去找豹子头,那一定找不到,这就是有问题的)。(这个我们之前讲过,今天复习一下)。}
那我们都说了,我们出了函数以后我们的 obj 都已经被析构了,那我们传引用回去一定是初始化不了result的,我们这个函数就使用传值返回,既然我们的obj本身被销毁了,我们就在obj被销毁之前,拷贝一份回去,,我们这里就要调用拷贝构造来进行拷贝,我们把拷贝的这份数据就叫做------临时对象。(这份临时对象是我们的obj的拷贝)
所以说,我们的自定义类型传值返回要调用拷贝构造;
但是至于传值传参要调用拷贝构造,这个当然毋庸置疑,我们把一个对象传过去,当然要把他的数据拷贝上来。

我们看这个图片,这个图片就是我们上面的代码的底层(不优化),我们实例化对象obj调用构造函数,然后传值返回调用拷贝构造,拷贝构造一份obj生成临时对象。
然后你还记得我们的拷贝构造的定义吗,拷贝构造是把一份数据赋值给正要初始化的对象。
而赋值重载的话,是两个对象本身就是存在的,早就初始化过了,然后一个对象赋值给另一个对象
这里就很显然,result对象正在初始化,这时候这个就是拷贝构造。
把result初始化完后,临时对象的生命就结束了,临时对象是一个右值,他的生命周期只有这一行
然后我们先析构临时对象,再析构obj,尊从析构函数的先构造的后析构,后构造的先析构的原理
/
简单理解:传值返回会调用拷贝构造生成临时对象,临时对象可以拷贝构造赋值给刚实例化的对象
这里我们在再讲一个普通的内置类型的函数的这类型:
这个虽然是内置类型相比自定义类型的简单多了,但还是说一下吧。
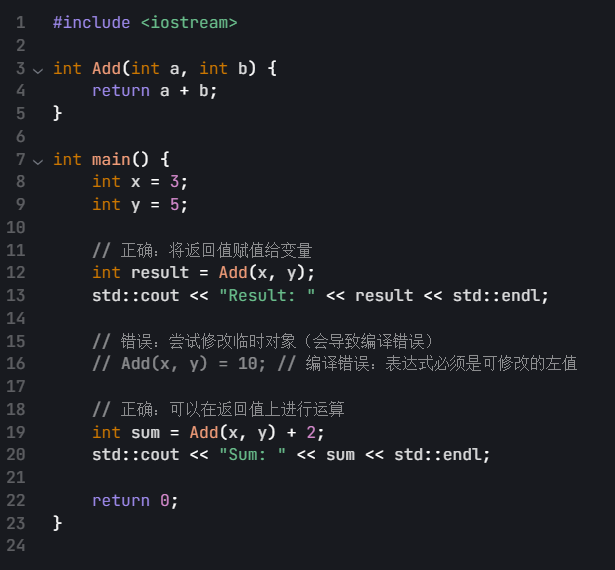
看这个函数,这个是一个普通的加法函数,他的返回值是一个int类型的,它返回的是一个式子,我们刚才上面的说了,表达式就是右值。右值一般是不可以修改的。
但是:看下面,其实
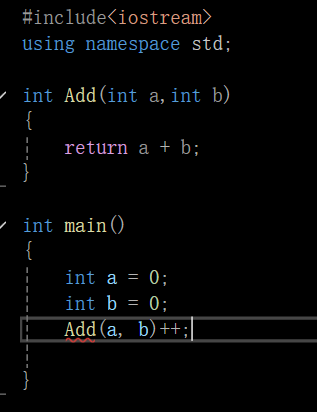

不管你这里是不是返回的一个表达式,这里的话,你都是不能修改的,因为我们要返回这个值,但似乎我们的变量在出了函数以后就被销毁了,所以我们的传值返回都是先把这个变量的数据拷贝一份,,,生成一个临时对象,然后返回到主函数的调用里面去。
这时候这个就是一个临时对象,具有常性,不可修改。
我们继续看:
我们看赋值给result,这里我们的result不再是自定义类型的,而是内置类型的。
我们再看第三个正确的说明,我们可以给返回值的临时对象加上一个2,再赋值给新的变量,这个是可以的,因为这个相加就是一个式子,一个表达式,,表达式计算的结果就是一个临时对象,我们的函数的返回值自己并没有自增。
Add(x, y) + 2 整体构成一个右值表达式,其计算结果也是一个右值。我们说右值一般是不能修改的。