深入解析BERT自然语言处理框架:原理、结构与应用
在自然语言处理(NLP)领域,BERT(Bidirectional Encoder Representations from Transformers)框架的出现无疑是一个重要的里程碑。它凭借其强大的语言表示能力和广泛的应用前景,彻底改变了我们对文本数据的理解和处理方式。本文将深入解析BERT框架的原理、结构和应用,帮助读者更好地理解这一强大的工具。
一、BERT框架简介
BERT是一个基于Transformer的双向编码器表示模型,通过预训练学习到丰富的语言表示,并可应用于各种自然语言处理任务。其核心优势在于能够同时考虑文本中的上下文信息,从而捕捉到更加丰富的语义特征。

(一)模型结构
BERT基于Transformer的编码器部分,采用多层自注意力机制和前馈神经网络。这种结构使得BERT能够同时考虑文本中的上下文信息,从而更准确地捕捉语义。
(二)预训练任务
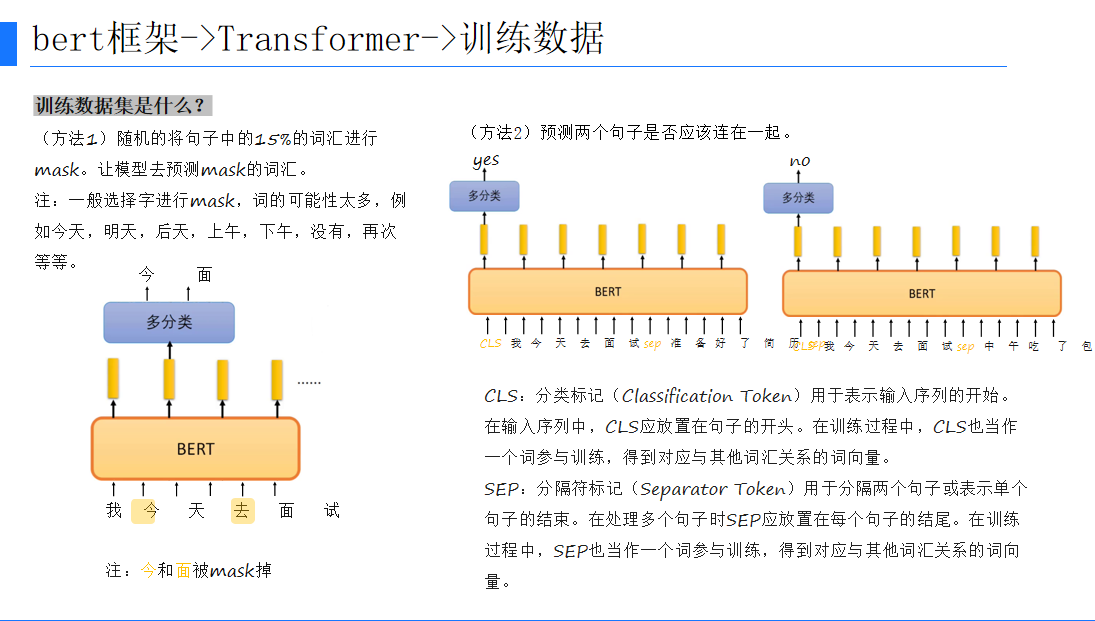
BERT通过两个无监督的预测任务进行预训练:遮蔽语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。MLM任务中,模型需要预测被遮蔽的词;NSP任务中,模型需要判断两个句子是否连续。
(三)双向性
与单向语言模型(如GPT)不同,BERT是双向的。它在预测一个词时会同时考虑该词前后的上下文,从而更准确地捕捉语义信息。
(四)微调(Fine-tuning)
完成预训练后,BERT可以通过微调适应各种下游任务。微调是在特定任务的数据集上对预训练模型进行进一步训练,使其更好地适应该任务。
(五)表现与影响
BERT在多项自然语言处理任务中取得了显著成绩,刷新了多项基准测试记录。它的成功推动了预训练语言模型的发展,为后续更多先进模型的出现奠定了基础。
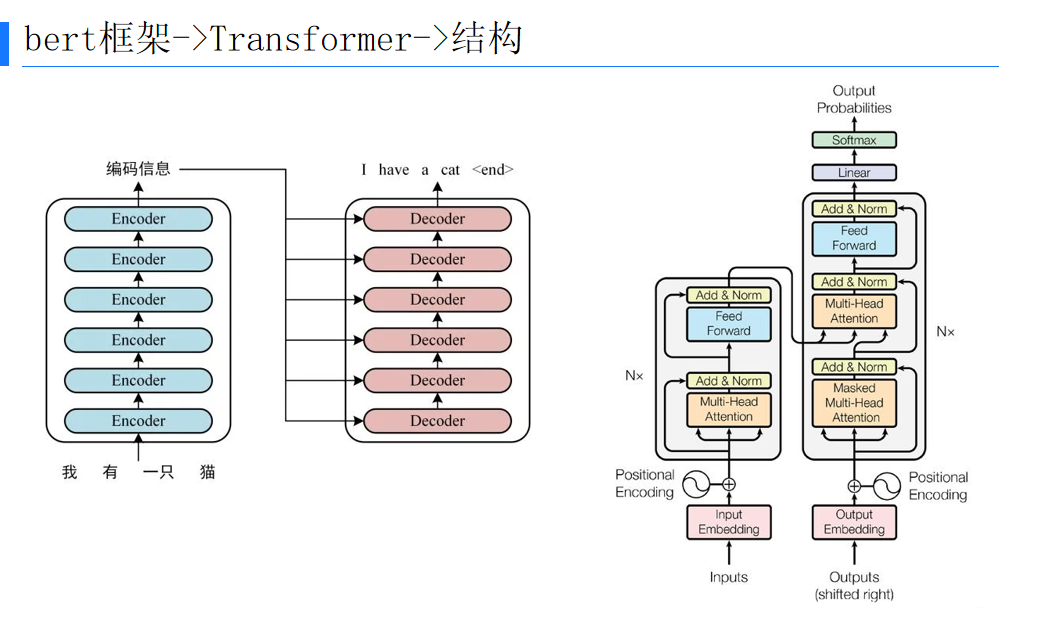
二、BERT框架的Transformer结构
Transformer架构是BERT的基础,其核心是自注意力机制(Self-Attention)和多头注意力机制(Multi-Head Attention)。Transformer摒弃了传统的RNN/LSTM/GRU等循环神经网络结构,完全依赖于注意力机制来处理序列数据。
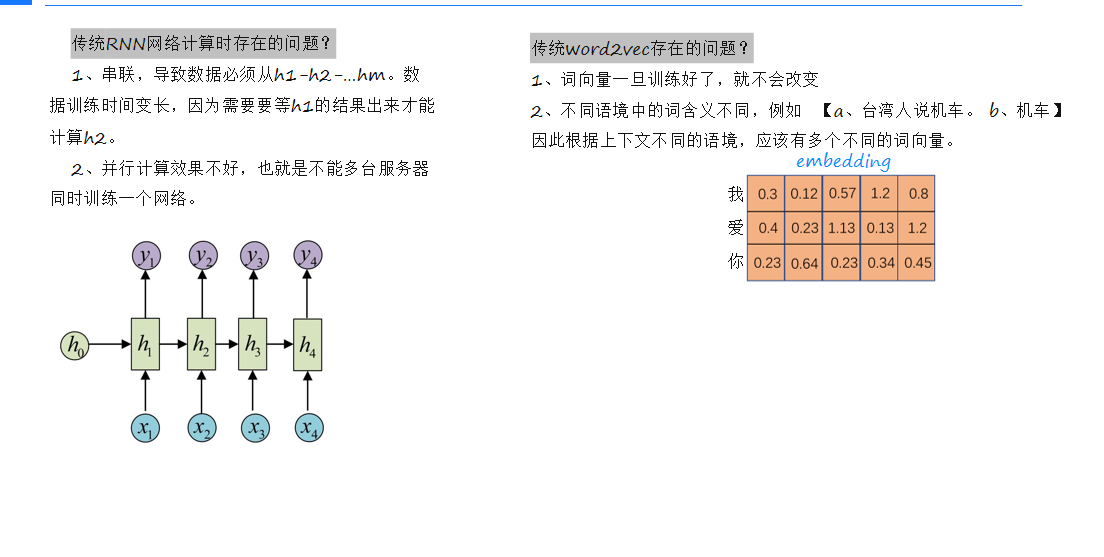
(一)传统RNN网络的问题
传统RNN网络存在以下问题:计算时是串联的,数据必须依次通过每个时间步,导致训练时间长;并行计算效果差,无法多台服务器同时训练。
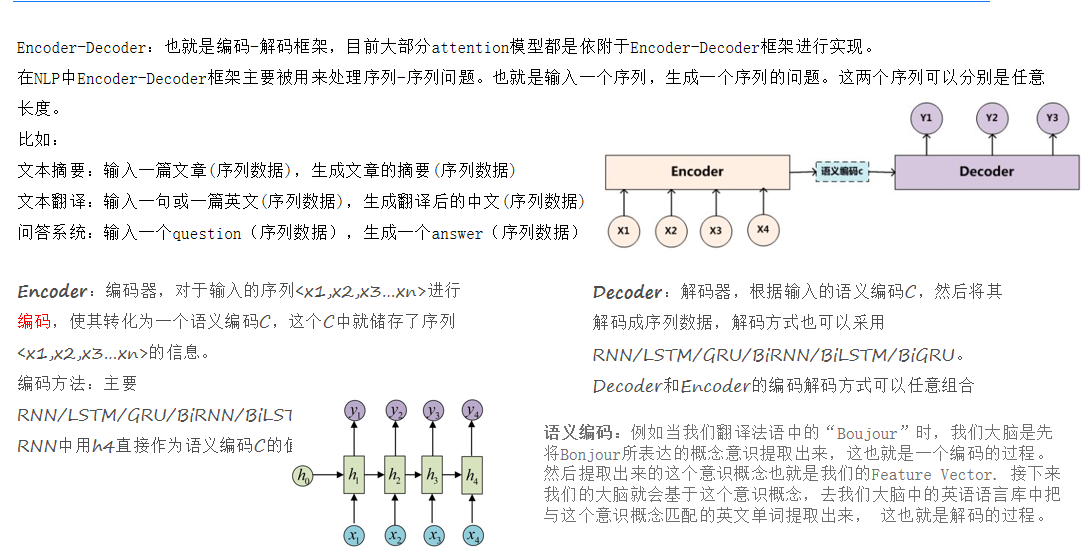
(二)Transformer的结构
Transformer由编码器(Encoder)和解码器(Decoder)组成。编码器将输入序列编码为语义编码C,解码器根据C解码成输出序列。
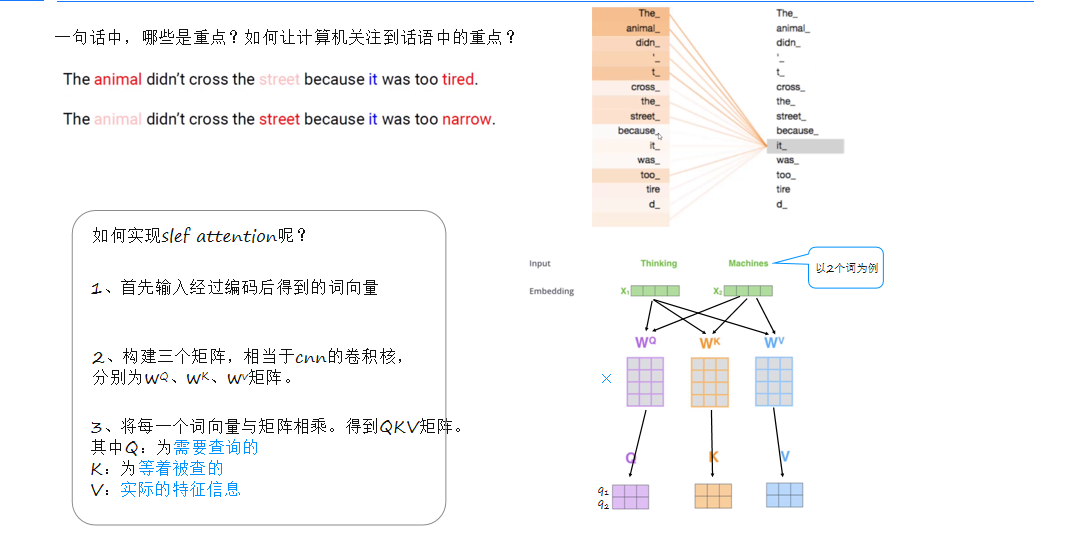
(三)自注意力机制(Self-Attention)
自注意力机制通过计算每个词与其他词的相关性来分配权重,从而让模型关注到话语中的重点。
(四)多头注意力机制(Multi-Head Attention)
多头注意力机制通过不同的head得到多个特征表达,然后将所有特征拼接在一起并降维,从而得到更丰富的特征。
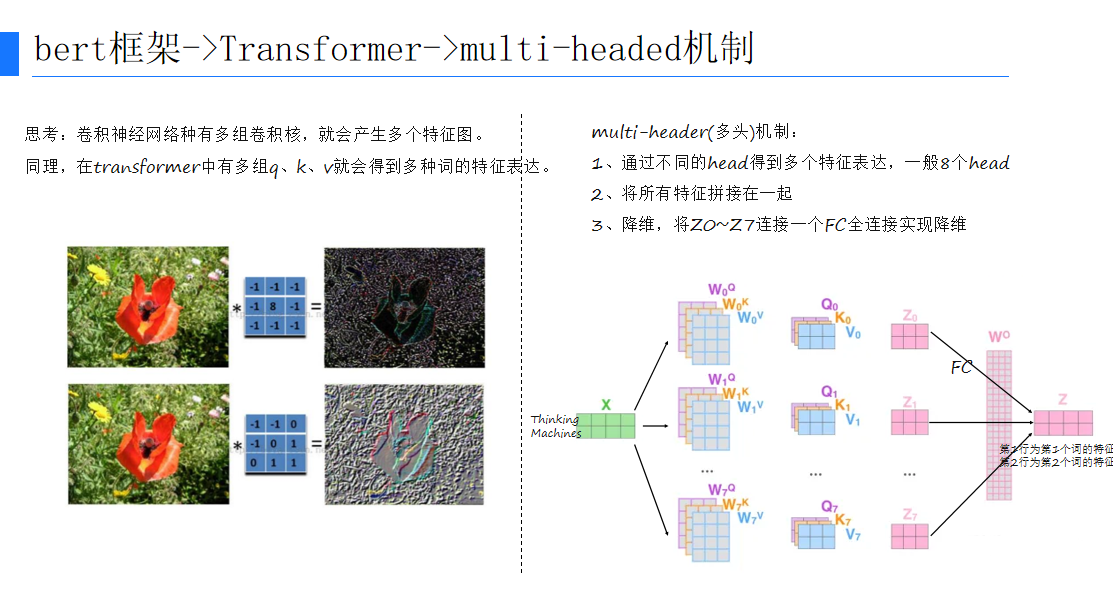
(五)位置编码
Transformer通过位置编码来引入词的顺序信息。位置编码采用三角函数形式,能够使PE分布在0,1区间,且不同语句相同位置的字符PE值相同。


三、BERT框架的使用
BERT框架的使用主要分为下载预训练模型、安装依赖库和进行微调训练三个步骤。
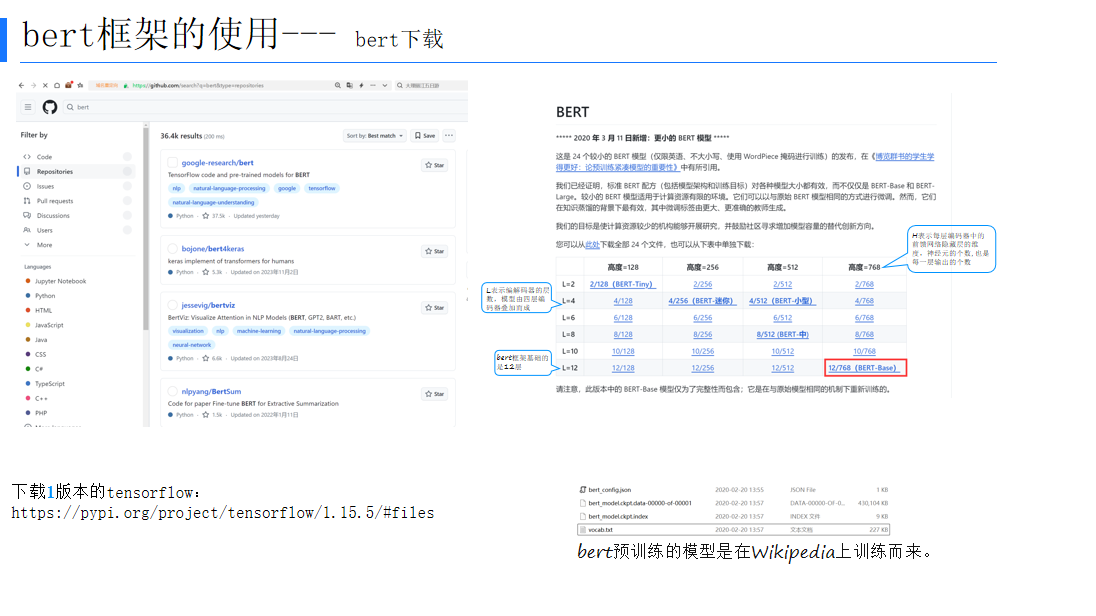
(一)BERT下载
BERT预训练模型是在Wikipedia等大规模语料上训练而来。下载BERT模型时,需要根据具体任务选择合适的版本。
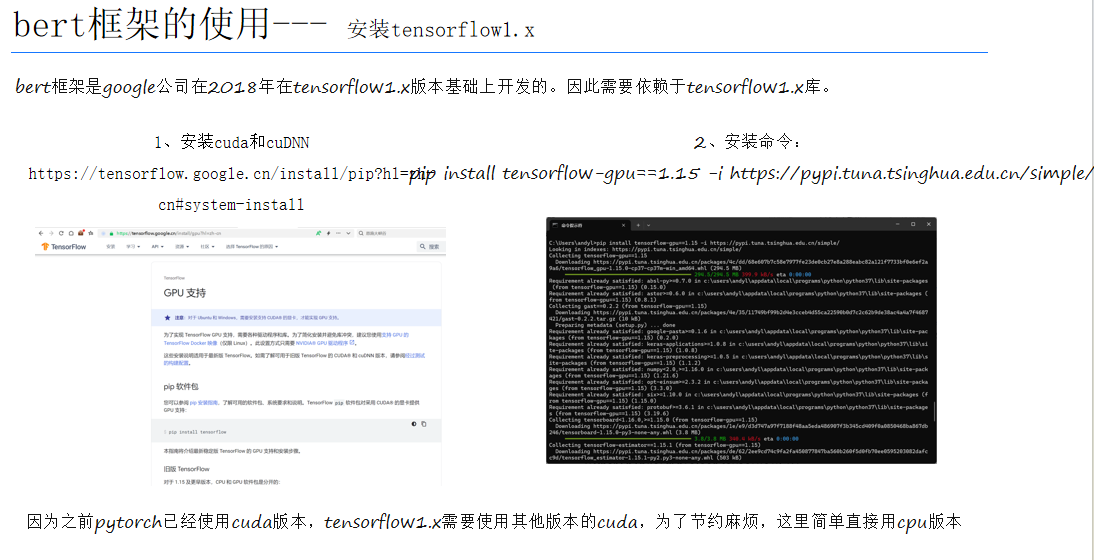
(二)安装TensorFlow 1.x
BERT框架基于TensorFlow 1.x开发,因此需要安装TensorFlow 1.x库。安装时需注意版本兼容性。
(三)微调训练
微调训练是BERT框架的核心环节。通过在特定任务的数据集上对预训练模型进行进一步训练,BERT可以更好地适应该任务。
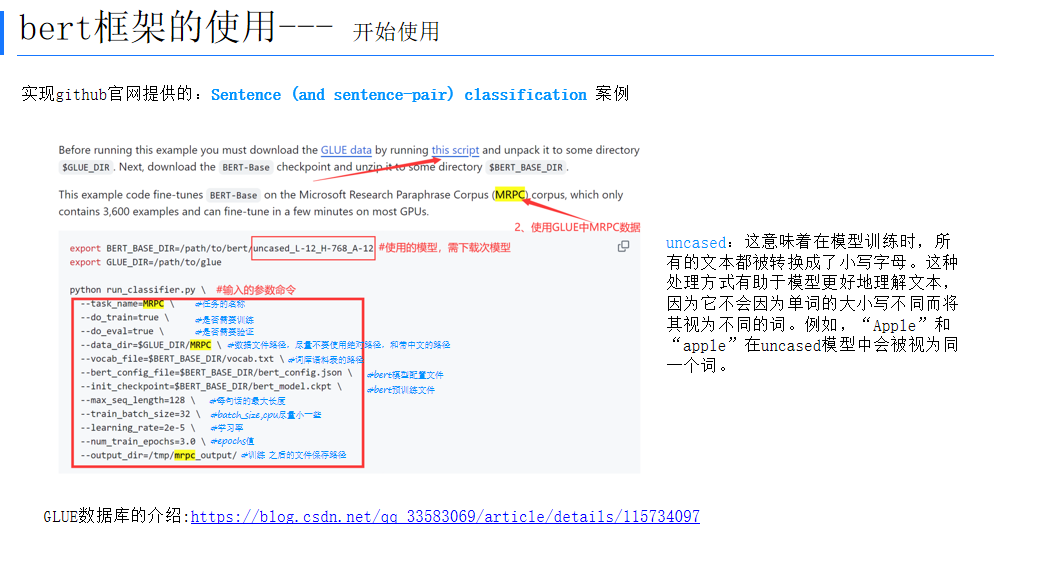
四、BERT框架的应用
BERT框架在自然语言处理领域有广泛的应用,包括但不限于以下几种:
(一)文本分类
BERT可以用于文本分类任务,如情感分析、主题分类等。通过微调,BERT能够学习到文本的语义特征,从而准确地对文本进行分类。
(二)命名实体识别
BERT在命名实体识别任务中表现出色。它能够识别出文本中的实体,如人名、地名、组织名等。
(三)问答系统
BERT可以用于问答系统,如机器阅读理解。通过理解问题和上下文,BERT能够准确地回答问题。
五、总结
BERT框架凭借其强大的语言表示能力和广泛的应用前景,已经成为自然语言处理领域的重要工具。通过深入理解BERT的原理、结构和应用,我们可以更好地利用这一工具解决实际问题。未来,随着技术的不断发展,BERT框架也将不断完善和优化,为自然语言处理领域带来更多的惊喜。