一、文生文功能
(1)前端部分
使用 Pinia 状态管理库创建的聊天机器人消息存储模块,它实现了文生文(文本生成文本)的核心逻辑。
1.Pinia状态管理
这个模块管理两个主要状态:
messages:存储所有聊天历史记录,包括用户消息和 AI 回复receiveText:临时存储 AI 流式返回的文本内容
主要包含两个核心方法:
startSending:处理用户消息发送逻辑handleText:处理 AI 模型返回的流式响应
messages 数组中的每个元素都是一个对象,具有以下结构:

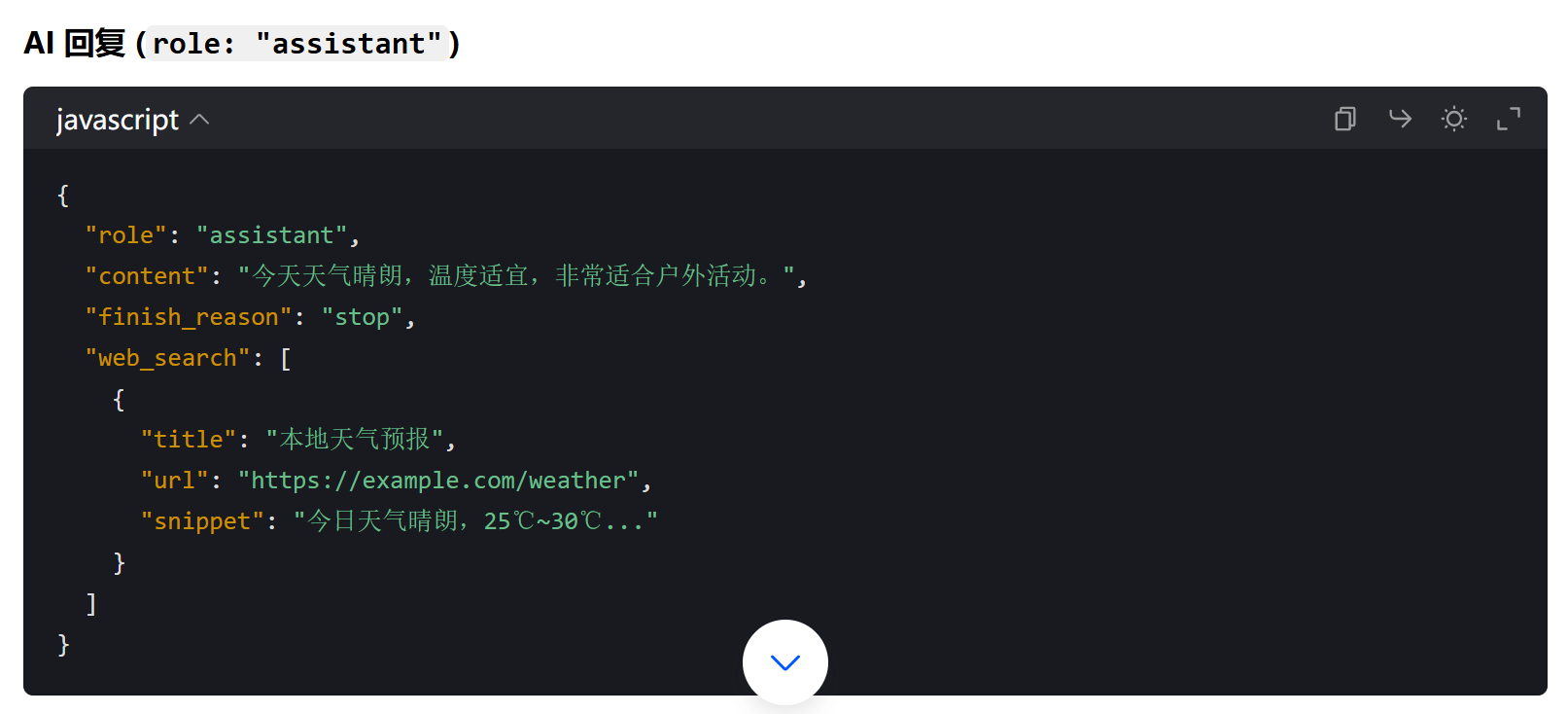
2.消息流转过程
-
用户发送消息
- 用户输入文本后,
startSending方法会创建一个用户消息对象并添加到messages数组 - 同时预添加一个空的 AI 回复对象,初始状态为
"start"
- 用户输入文本后,
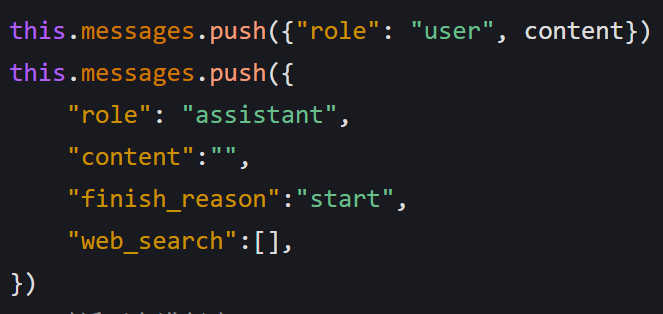
-
AI 流式响应
- 每次接收到新的文本片段时,
handleText方法会更新 AI 回复对象 finish_reason会从"start"变为"respond",表示正在生成回复content字段会逐步追加新的文本片段
- 每次接收到新的文本片段时,
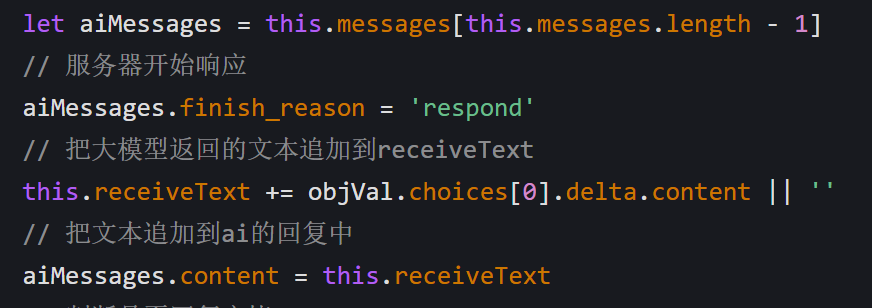
这里receiveText一点一点追加大模型返回的文本片段,然后赋值给大模型消息对象的content字段
-
回复完成
- 当 AI 完成回复时,
finish_reason会被设置为最终状态(如"stop") - 如果有网络搜索结果,会添加到
web_search字段 - 最后将最新的两条消息(用户 + AI)保存到服务器
- 当 AI 完成回复时,
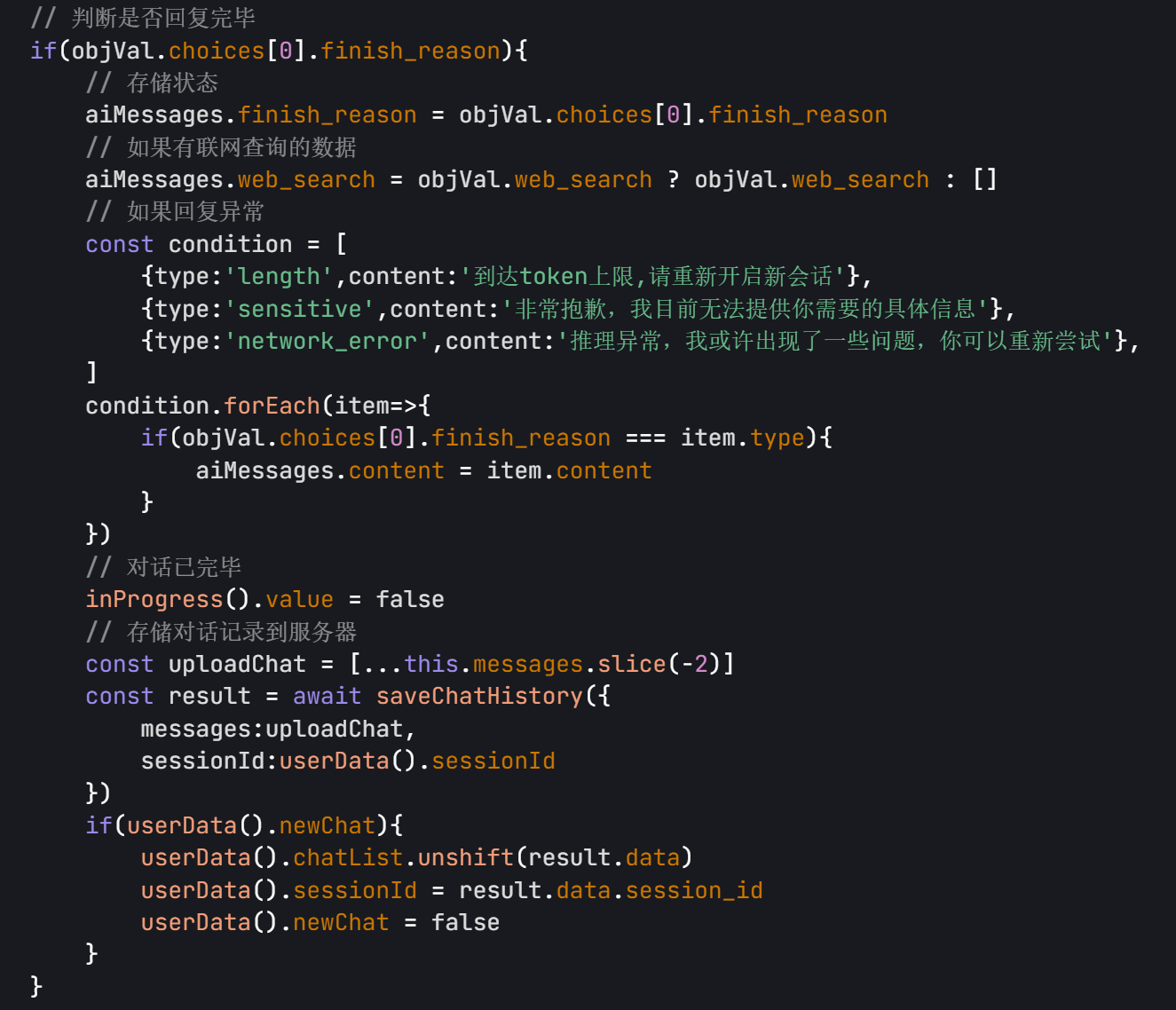
- 在流式响应过程中,每个数据块(token)会依次返回,此时
finish_reason字段通常是null或undefined - 当回复完成时,最后一个数据块会包含
finish_reason字段,指示回复是如何结束的

以下是完整的message数组示例:
javascript
[
{
"role": "user",
"content": "推荐几部科幻电影"
},
{
"role": "assistant",
"content": "以下是几部值得一看的科幻电影:1.《星际穿越》2.《盗梦空间》3.《2001太空漫游》",
"finish_reason": "stop",
"web_search": [
{
"title": "豆瓣科幻电影Top10",
"url": "https://movie.douban.com/chart",
"snippet": "豆瓣评分最高的科幻电影排行榜..."
}
]
},
{
"role": "user",
"content": "《星际穿越》的导演是谁?"
},
{
"role": "assistant",
"content": "《星际穿越》是由克里斯托弗·诺兰执导的。",
"finish_reason": "stop",
"web_search": []
}
]3.HTTP 请求封装中的流式数据处理
- 使用
onChunkReceived监听流式数据 - 将二进制数据转换为字符串并处理编码
- 实现缓冲区机制,按行解析 SSE (Server-Sent Events) 格式数据
- 过滤有效数据块并传递给
chatbotMessage存储模块处理
javascript
requestTask.onChunkReceived(response=>{
// 将ArrayBuffer转换为字符串
let arrayBuffer = response.data
const arrayBufferss = new Uint8Array(arrayBuffer)
let string = ''
for(let i = 0; i < arrayBufferss.length; i++){
string += String.fromCharCode(arrayBufferss[i])
}
// 处理编码并追加到缓冲区
buffer += decodeURIComponent(escape(string))
// 按行解析数据
while(buffer.includes('\n')){
const index = buffer.indexOf('\n')
const chunk = buffer.slice(0,index)
buffer = buffer.slice(index + 1)
// 处理SSE格式数据
if(chunk.startsWith('data: ') && !chunk.includes('[DONE]')){
const jsonData = JSON.parse(chunk.replace('data: ',''))
chatbotMessage().handleText(jsonData)
}
}
})大模型返回的SSE数据格式
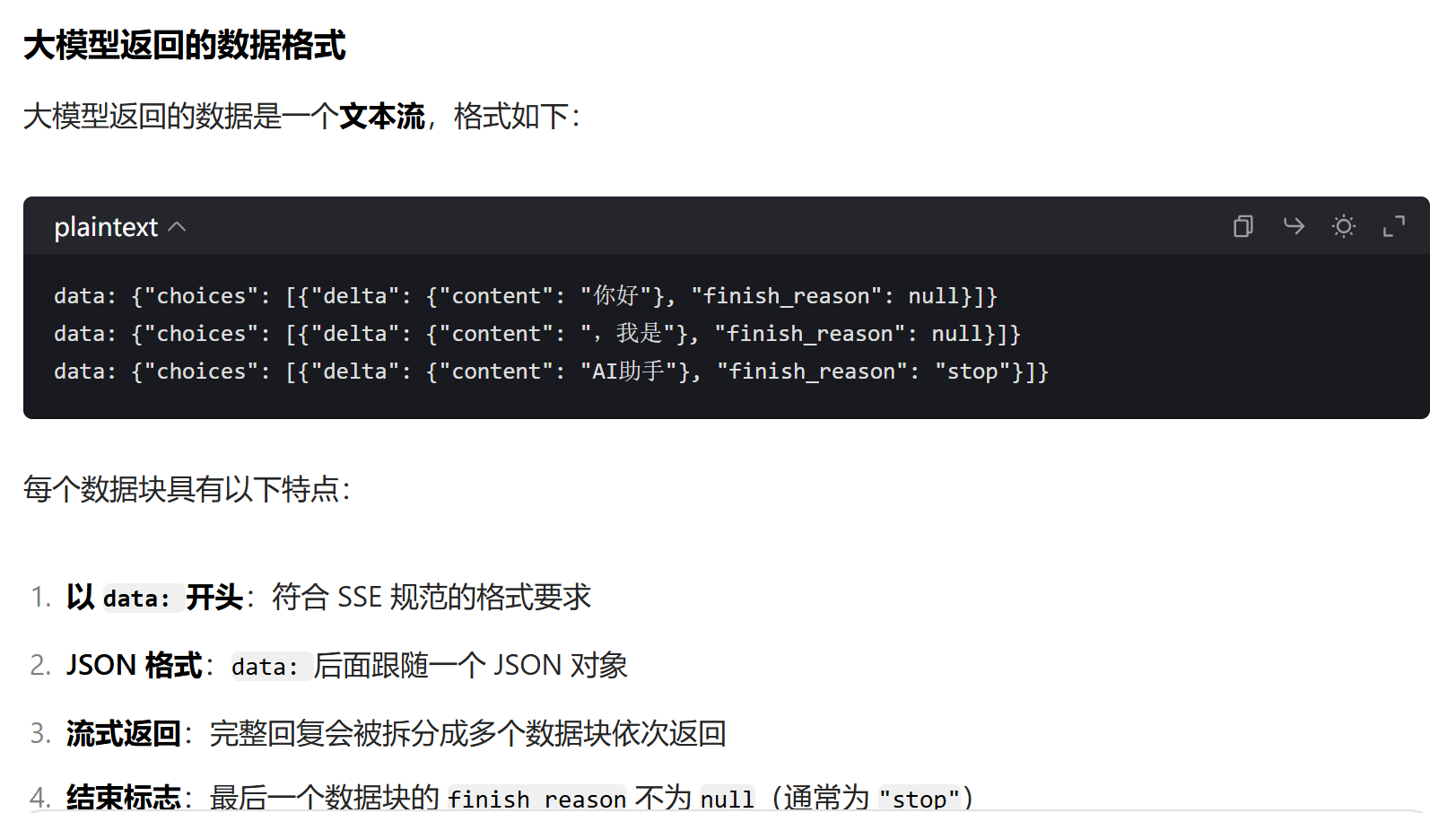
4.实时UI渲染
html
<view class="zhipu-message" v-if="item.role === 'assistant'">
<towxml :nodes="appContext.$towxml(item.content,'markdown')"></towxml>
<!-- 加载动画 -->
<loadingVue v-if="item.finish_reason == 'start'"></loadingVue>
<!-- 网络搜索结果 -->
</view>item.content是当前 AI 回复的内容towxml组件将 Markdown 格式的文本渲染为富文本- 每当
item.content更新时,towxml会重新渲染,显示最新内容
(2)后端部分
javascript
async createCompletions(ctx) {
const { messages } = ctx.request.body;
await Validate.isarrayCheck(messages, "缺少对话信息", "messages");- 从请求体中获取对话历史
messages - 使用
Validate.isarrayCheck验证messages是否为数组 - 如果验证失败,会抛出错误并返回相应的错误信息
javascript
const data = await ai.createCompletions({
model: "glm-4-0520",
messages,
stream: true,
tools: [
{
type: "web_search",
web_search: {
enable: true,
search_result: true,
},
},
],
});- 调用 AI 模型的
createCompletions方法生成回复 - 指定使用
glm-4-0520模型 - 传递完整的对话历史
messages - 设置
stream: true启用流式响应 - 启用网络搜索工具,允许模型在生成回答时参考实时网络信息
javascript
ctx.status = 200;
for await (const chunk of data) {
console.log(chunk.toString());
ctx.res.write(chunk);
}- 设置 HTTP 状态码为 200(成功)
- 使用
for await...of遍历异步可迭代对象data- 每次迭代获取模型生成的一个数据块(可能是一个单词、一个句子片段等)
- 通过
ctx.res.write(chunk)将数据块实时写入 HTTP 响应- 这些数据会立即传输到前端,而不需要等待整个回复完成
与前端的配合
前端代码(之前分析过的)会这样处理这个流式响应:
- 接收二进制数据块并转换为文本
- 按行解析 SSE 格式的数据
- 提取 JSON 对象并更新聊天界面
- 随着新数据的到来,文本会逐字显示在界面上
二、实时语音功能
(1)前端部分
1. 初始化与准备工作
- 引入必要的模块和变量 :在input-box.vue文件中,引入了阿里云相关的请求接口
aliToken、aliyunUrl、appKey,以及自定义的语音识别类SpeechTranscription。
javascript
import {aliToken,aliyunUrl,appKey} from '@/api/request.js'
import {SpeechTranscription} from '@/voice/st.js'-
获取 Token :在主页面加载时,调用
aliToken接口获取阿里云语音识别所需的 Token。 -
实例化语音识别对象 :使用获取到的 Token、URL 和 AppKey 实例化
SpeechTranscription对象,并存储在launckVoice变量中。
javascript
onLoad(async()=>{
const token = await aliToken()
const st = new SpeechTranscription({
url:aliyunUrl,
token:token.data,
appkey:appKey
})
launckVoice.value = st
})2. 开始语音录制与识别
-
长按开始说话 :用户长按 "按住 说话" 按钮,触发
longpress方法。 -
检查当前是否有正在进行的对话,如果有则返回。
-
显示语音录制区域。
-
调用
launckVoice.value.start方法开始语音识别,并传入默认的开始参数。 -
调用
recorderManager.start方法开始录音。
javascript
const longpress = async()=>{
if(inProgress().queryValue())return false
showAudio.value = true
await launckVoice.value.start(launckVoice.value.defaultStartParams())
recorderManager.start({
duration:100000,
sampleRate:16000,
numberOfChannels:1,
format:'PCM',
frameSize:4
})
}- 实时输出录音 :使用
recorderManager.onFrameRecorded监听录音的每一帧数据,并将其发送给阿里云语音识别服务。
javascript
recorderManager.onFrameRecorded(res=>{
launckVoice.value.sendAudio(res.frameBuffer)
})3. 处理语音识别结果
- 监听语音识别事件 :在
SpeechTranscription(实例化的阿里云语音对象)对象上监听多个事件,包括开始、中间结果、句子结束、关闭和错误。
javascript
// 实时语音识别开始。
st.on("started",()=>{
console.log('实时语音识别开始');
})
// 实时语音识别中间结果。
st.on("changed",msg=>{
console.log('实时语音识别中间结果');
console.log(msg);
const res = JSON.parse(msg)
const queryIndex = storageArr.value.findIndex(item=>item.index === res.payload.index)
if(queryIndex >= 0){
storageArr.value[queryIndex].result = res.payload.result
}else{
storageArr.value.push(res.payload)
}
})
// 提示句子结束。
st.on("end",msg=>{
console.log('提示句子结束');
console.log(msg);
const res = JSON.parse(msg)
const queryIndex = storageArr.value.findIndex(item=>item.index === res.payload.index)
if(queryIndex >= 0){
storageArr.value[queryIndex].result = res.payload.result
}else{
storageArr.value.push(res.payload)
}
})
// 连接关闭。
st.on("closed",()=>{
console.log('连接关闭');
})
// 错误。
st.on("failed",(err)=>{
console.log('阿里云语音识别错误');
console.log(err);
uni.showToast({
icon:"none",
title:'录音出现错误'
})
})4. 结束语音录制与识别
- 手指放开停止录音 :用户放开手指,触发
touchend方法。
javascript
const touchend = ()=>{
showAudio.value = false
recorderManager.stop()
}-
隐藏语音录制区域。
-
调用
recorderManager.stop方法停止录音。 -
处理录音结束事件 :使用
recorderManager.onStop监听录音结束事件,强制关闭阿里云语音识别监听,并将识别结果拼接成字符串存储在inputContent中。
javascript
recorderManager.onStop(res=>{
console.log('录音结束了');
console.log(res);
showAudio.value = false
// 强制关闭阿里云语音识别监听
launckVoice.value.shutdown()
// 录制结束取出文字发送大模型
if(storageArr.value.length > 0){
storageArr.value.forEach(item=>{
inputContent.value += item.result
})
}
})5. 实际数据流转示例
1. changed 事件(中间结果)
阿里云返回的json数据格式
javascript
{
"payload": {
"index": 1, // 当前句子的唯一索引(同一轮录音中的句子编号)
"result": "你好,", // 中间识别结果(可能后续会补充)
"status": "partial" // 标识为中间结果
}
}
javascript
st.on("changed", msg => {
const res = JSON.parse(msg); // 解析JSON数据
const { index, result } = res.payload; // 提取索引和文本
// 查找是否已存在相同index的结果块
const queryIndex = storageArr.value.findIndex(item => item.index === index);
if (queryIndex >= 0) {
// **存在已记录的块**:更新该块的文本(中间结果可能逐次补充)
storageArr.value[queryIndex].result = result;
} else {
// **不存在记录**:新增一个结果块(处理可能的乱序返回)
storageArr.value.push({ index, result });
}
});
javascript
changed: { index: 1, result: "今天" }
changed: { index: 1, result: "今天天气" }
changed: { index: 1, result: "今天天气怎么样" }
end: { index: 1, result: "今天天气怎么样" } // 第一句结束
changed: { index: 2, result: "明天" }
changed: { index: 2, result: "明天有什么" }
changed: { index: 2, result: "明天有什么安排" }
end: { index: 2, result: "明天有什么安排" } // 第二句结束这段数组逻辑是这样的:先查找数组中有没有存在的和阿里云返回结果的index相同的index,有的话说明是同一个片段句子,覆盖就行,没有的话说明是新句子,重新push一个对象进数组
(例如返回来的index为1,数组已经存在index为1的对象,则覆盖;如果返回来的index是2,数组不存在index为2的对象,则新增一个index=2的对象去存储)
关键点:
- 增量更新:每次返回的中间结果会覆盖前一次的结果。
- 按索引管理 :通过
index区分不同的句子(若用户连续说多句话)。 - 实时展示:可用于实现 "边说边显示" 的效果(如语音输入法的逐字显示)。
2.end 事件(最终结果)
当检测到语音停顿(用户停止说话),阿里云返回完整的最终识别结果。
javascript
st.on("end", msg => {
const res = JSON.parse(msg);
const queryIndex = storageArr.value.findIndex(item => item.index === res.payload.index);
if (queryIndex >= 0) {
// 更新已有结果块(将中间结果替换为最终结果)
storageArr.value[queryIndex].result = res.payload.result;
} else {
// 添加新结果块(理论上不会触发,因为end事件前必有changed事件)
storageArr.value.push(res.payload);
}
});关键点:
- 最终确认 :
end事件的结果比changed事件更准确(经过模型后处理优化)。 - 句子边界 :一个
end事件表示一个完整句子的结束。 - 结果固化:最终结果不会再被覆盖,可直接用于后续处理。
总的来说,on事件用于实时更新识别出来的文本数据,end事件用来处理最后识别结果,纠正一些on事件中的谐音错误
用户按下按钮
↓
recorderManager.start() 开始录音
↓
每采集一帧音频数据
↓
recorderManager.onFrameRecorded() 触发
↓
launckVoice.value.sendAudio(res.frameBuffer) 发送数据到阿里云
↓
阿里云处理数据并返回识别结果
↓
st.on("changed") 或 st.on("end") 触发
↓
将识别结果存入 storageArr
↓
用户松开按钮
↓
recorderManager.onStop() 触发
↓
launckVoice.value.shutdown() 关闭连接
↓
拼接 storageArr 中的所有结果
↓
sendIng() 将文本发送给大模型
(2)后端部分
javascript
class VoiceController {
async aliToken(ctx) {
// 检查Redis缓存中是否已有Token
const alitoken = await ctx.redis.get("aliToken")
if (alitoken) {
ctx.send(alitoken)
return false
}
// 调用阿里云API生成新Token
const result = await client.request('CreateToken')
console.log(result)
// 处理返回结果并缓存
if (result.Token && result.Token.Id) {
// 计算Token过期时间
const expires_in = result.Token.ExpireTime - dayjs().unix()
// 缓存到Redis并设置过期时间
await ctx.redis.set('aliToken', result.Token.Id, 'EX', expires_in)
ctx.send(result.Token.Id)
} else {
ctx.send(null, 500, "获取阿里云token失败", result)
}
}
}- 缓存优先策略:首先检查 Redis 中是否有缓存的 Token,如果有则直接返回
- Token 生成 :调用
CreateToken接口生成新 Token - 缓存处理:将 Token 存入 Redis 并设置与阿里云一致的过期时间,避免频繁调用 API
三、用户登录
(1)前端部分
- 获取登陆码
javascript
uni.login({
success:async(res)=>{
await userData().isNotLoggedIn(
userInfo.nickname,
fileurl,
res.code
)
loading.value = false
}
})使用 uni.login 方法获取用户的登录码 code
- 调用后端wxLogin接口
javascript
// 未登录获取用户信息
async isNotLoggedIn(nickName, avatar, code){
// 请求接口
const result = await wxLogin({nickName, avatar, code})
// console.log(result);
// 存储本地缓存
uni.setStorageSync('userInfo',result.data)
this.userInfo = result.data
// 请求聊天列表
const chatListData = await userChatList()
this.chatList = chatListData.data
this.isLogin = true
}调用后端接口,将用户昵称、头像、获取到的code传给后端,后端返回结果,将其保存在本地缓存,其中后端返回的结果如下:
javascript
{
"data": {
"token": "生成的 JWT 令牌",
"nickName": "用户昵称",
"avatar": "用户头像地址"
},
"msg": "SUCCESS",
"error": null,
"serviceCode": 200
}(2)后端部分
javascript
class UserController {
//用户登录
async wxLogin(ctx) {
const { nickName, avatar, code } = ctx.request.body
await Validate.nullCheck(nickName, '请输入昵称', 'name')
await Validate.nullCheck(avatar, '请上传头像', 'avatar')
await Validate.nullCheck(code, '缺少code', 'avatar')
//获取openid
const openid = await new UserService().getOpenid(code)
//查询数据库是否已存在用户信息
// console.log(nickName, avatar, openid)
const userInfo = await User.findOne({ where: { openid } })
if (!userInfo) {
await User.create({ nickName, avatar, openid })
}
ctx.send({ token: generateToken(openid), nickName, avatar })
}
}将code换为openid的service部分:
javascript
const { appid, secret, code2session } = require("@/config/default").weixin
const qs = require("querystring")
const axios = require("axios")
class UserService {
// 获取openid
async getOpenid(code) {
const query = qs.stringify({
appid,
secret,
js_code: code,
grant_type: "authorization_code"
})
const res = await axios.get(`${code2session}?${query}`)
console.log(res)
if (res.data.errcode) {
throw { msg: "获取code出错", code: 400, error: res.data }
} else {
return res.data.openid
}
}
}- 用途:实现微信登录流程中的「code 换取 openid」环节,这是微信小程序 / 公众号登录的核心步骤。
- 技术栈 :
- 使用
axios发起 HTTP 请求,调用微信官方接口。 - 通过
querystring处理 URL 查询参数。 - 配置信息(如
appid、secret)从项目配置文件中读取。
- 使用
微信登录流程关联
这段代码是微信登录流程中的关键环节,整体流程如下:
- 前端获取
code:
前端调用微信登录接口(如小程序的wx.login),获取临时登录凭证code,并传递给后端。 - 后端换取
openid:
后端通过code、appid、secret向微信服务器发起请求,验证code的有效性并获取openid(用户在微信体系内的唯一标识)。 - 业务逻辑处理 :
后端使用openid进行用户注册 / 登录(如查询数据库是否存在该用户),并生成自定义令牌(如 JWT)返回给前端。
四、用户鉴权
生成 JWT Token
在wxLogin方法中,用户登录时会获取openid,然后后端调用generateToken方法生成 JWT Token,并将其返回给前端。
存储 Token
前端收到 Token 后,将其存储到本地缓存中。在后续的请求中,前端需要在请求头中携带这个 Token。
验证 JWT Token
在每个需要鉴权的接口中,会对请求头中的 Token 进行验证。
javascript
const basicAuth = require("basic-auth");
var jwt = require("jsonwebtoken");
const { secretkey } = require("./default").userToken;
const authority = async (ctx, next) => {
const token = basicAuth(ctx.req);
if (!token || !token.name) {
throw { msg: "没有登陆,没有访问权限", code: 401 };
}
try {
var authcode = jwt.verify(token.name, secretkey); //解密token为openid
} catch (error) {
if (error.name == "TokenExpiredError") {
throw { msg: "登录过期,重新登陆", code: 401 };
}
throw { msg: "没有访问权限", code: 401 };
}
ctx.auth = {
uid: authcode.uid,
};
await next();
};
module.exports = authority;在authority中间件中,首先从请求头中获取 Token,然后使用jwt.verify方法对 Token 进行验证。如果验证通过,将openid存储在ctx.auth中,并继续执行后续的中间件或路由处理函数;如果验证失败,抛出相应的错误信息。
应用鉴权中间件
在路由中,为需要鉴权的接口应用authority中间件。
jwt.verify 是如何验证 Token 的有效性的?
1. 生成 Token
首先,假设我们要为一个用户生成一个 Token,该用户的 openid 为 "user123"。在 AIGC - backend/config/jwt.js 中,生成 Token 的代码如下:
javascript
const jwt = require('jsonwebtoken');
const { secretkey, expiresIn } = require('./default').userToken;
// 生成token
function generateToken(uid) {
return jwt.sign({ uid }, secretkey, { expiresIn }); //uid是openid,密钥是自己定义的
}
// 示例:生成一个openid为user123的token
const openid = "user123";
const token = generateToken(openid);
console.log("生成的Token:", token);假设 secretkey 为 "mysecretkey",expiresIn 为 "1h"(表示 Token 在 1 小时后过期),生成的 Token 可能如下(实际生成的 Token 会有所不同):
javascript
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1aWQiOiJ1c2Vy123IiwiaWF0IjoxNjk4NjM2MDAwLCJleHAiOjE2OTg2Mzk2MDB9.abcdef1234567890这个 Token 由三部分组成,用点号 . 分隔:
- 头部(Header) :
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9,它通常包含了令牌的类型(JWT)和使用的签名算法(这里是 HMAC SHA256,即HS256)。 - 负载(Payload) :
eyJ1aWQiOiJ1c2Vy123IiwiaWF0IjoxNjk4NjM2MDAwLCJleHAiOjE2OTg2Mzk2MDB9,包含了我们存储的用户openid(uid)、签发时间(iat)和过期时间(exp)。 - 签名(Signature) :
abcdef1234567890,用于验证消息在传输过程中没有被更改。
2. 验证 Token
当用户发起请求时,服务器会从请求头中获取 Token,并使用 jwt.verify 方法进行验证。在 AIGC - backend/config/auth.js 中,验证 Token 的代码如下:
javascript
const basicAuth = require("basic-auth");
var jwt = require("jsonwebtoken");
const { secretkey } = require("./default").userToken;
const authority = async (ctx, next) => {
const token = basicAuth(ctx.req);
if (!token || !token.name) {
throw { msg: "没有登陆,没有访问权限", code: 401 };
}
try {
var authcode = jwt.verify(token.name, secretkey); //解密token为openid
} catch (error) {
if (error.name == "TokenExpiredError") {
throw { msg: "登录过期,重新登陆", code: 401 };
}
throw { msg: "没有访问权限", code: 401 };
}
ctx.auth = {
uid: authcode.uid,
};
await next();
};
module.exports = authority;- 获取 Token :假设客户端在请求头中携带了上面生成的 Token,服务器通过
basicAuth(ctx.req)获取到该 Token。 - 签名验证 :
jwt.verify方法会根据 Token 的头部指定的签名算法(HS256),使用相同的密钥(mysecretkey)重新计算签名。具体步骤如下:- 将头部和负载部分用点号
.连接起来,得到一个字符串。 - 使用
HS256算法和mysecretkey对这个字符串进行签名。 - 将计算得到的签名与 Token 中的签名部分进行比对。如果两者一致,说明 Token 没有被篡改。
- 将头部和负载部分用点号
- 过期时间验证 :
jwt.verify方法会检查当前时间是否超过了 Token 的过期时间。假设当前时间是1698638000,而 Token 的过期时间是1698639600,当前时间小于过期时间,说明 Token 未过期。 - 返回结果 :如果签名验证和过期时间验证都通过,
jwt.verify方法会返回 Token 中包含的信息,即:
javascript
{
"uid": "user123",
"iat": 1698636000,
"exp": 1698639600
}服务器把 openid 存储在 ctx.auth 中,在后续存储和获取聊天对应用户聊天记录起到关键作用