欢迎大家来到企业级AI售前机器人实战系列文章: 从0到1完成一个企业级AI售前机器人的实战指南。
本篇旨在为您提供关于大模型微调(Fine-Tuning)的快捷、直观的解答。
我们尽量避免技术黑话,用简单的比喻和直白的解释,
让您快速掌握微调的核心概念,对其效果、成本和流程有一个清晰的认知,从而能更有效地与技术团队协作。
我们开始:
什么是微调
微调是指在已经训练好的大型预训练模型的基础上,进一步训练该模型以适应特定任务或特定领域的数据。
相比从零开始训练一个模型,微调所需的数据和计算资源显著减少;可以在特定任务上取得更好的性能,因为模型在微调过程中会重点学习与任务相关的特性;
可以在多种领域(如情感分析、问答系统等)上进行微调,从而快速适应不同应用场景。
简单来说:微调 = 用你自己的数据,对通用大模型进行二次训练,让它专精于你的特定任务。
需要注意的是:培训后,它主要更擅长你教的这一件事。它原有的通用知识不会被清空,但如果你教的内容太多太偏(数据量巨大或与通用知识冲突),它可能会把以前学的一些不常用的东西忘掉一点,这被称为"灾难性遗忘"。
但是这不一定是坏事,微调的目标就是在"专精于新任务"和"保留通用能力"之间找到一个最佳平衡点。
如果只是微调一个小模型让它去做一个特定的任务,就无需太关注这个问题。
LoRA
微调通常分为全量微调 和高效微调,通常我们会选择高效微调,而LoRA是高效微调的一种。
全量参数精调与 LoRA 的方式,这两种方式的主要区别为:
-
全量参数精调指利用所有可用数据来重新训练模型,以全面优化其参数。上限比较高,能够取得更好的业务指标,但是对训练数据质量、数量的要求以及计算资源的需求较高。如果训练数据质量、数量不够,全量参数精调会大幅破坏模型的原有基础任务能力。
-
LoRA 微调是一种参数高效的微调方法,旨在通过引入低秩矩阵来减少微 调时需要调整的参数数量,从而显著降低显存和计算资源的消耗。 能够较好保持原有模型的能力,需要的计算资源也较少(根据 LoRA 的 rank 超参,训练时间大约为全量参数精调的1/2-1/10)。但是模型能力的上限较低,受限于训练时选用的基座模型。
因此,当数据量比较少(低于1万),且任务类型比较单一,推荐使用 LoRA 的方式进行精调。
对于在大模型领域有经验的同学,同时拥有丰富的高质量训练数据,建议使用全量参数精调的方式。
本文中讲到微调相关操作、成本等,都是基于高效微调。
微调和RAG的区别
一言以蔽之:RAG解决大模型数据不足的问题,微调解决大模型任务执行能力不足问题。
也就是说:RAG是"注入最新的、外部的、私有的知识",而微调是"改变模型的内在行为模式(风格、格式、偏好)和深化其已有知识"。
例如:
我们要让大模型回复我们企业内的某些资料问题,大模型做不到,此时就需要用RAG来解决。
我们要让大模型帮我们执行某个任务,大模型做不到,此时就需要用微调来解决。
当提示词工程(Prompt Engineering)和检索增强生成(RAG)都无法让模型100%达到你的要求时,微调就是最终的解决方案:
-
风格与语气:你需要模型的输出符合你品牌的独特口吻(比如"海底捞"式的热情客服 or "苹果"式的极简文案)。
-
任务与格式:你需要模型完成非常规任务,或者输出特定结构的数据(例如,将一段混乱的会议纪要自动整理成标准的JIRA ticket格式)。
-
知识与术语:你的业务涉及大量内部知识、缩写、行业黑话,通用模型无法正确理解和使用。
微调的数据集和常用超参
明确业务场景和微调需求
-
**找到准备微调的任务:**根据自己的目标或业务需求来决定要进行的微调任务。
-
**测试大模型能力:**使用主流的大模型,对自己的准备微调的业务问题进行批量测试,评估该任务场景是否现有大模型已经做得足够好了,根据评估结果选择使用原生大模型,或者准备一批更高质量的数据集进行微调。
-
**确定微调任务场景:**针对某一种特定的任务场景,准备约几千条高质量精调数据即可让大模型学会这项能力,发挥出良好的效果。通常使用具有强烈业务属性的数据集在开源基座模型上进行精调,就能比较显著地提升模型在业务上的能力;
明确高质量训练数据的标准
- 数据集的问答需要尽可能完美的满足业务的期望(例如回答逻辑性、风格、语气等),并且答案是绝对正确的。
因为数据集是用来解决实际问题,并且这些数据是大模型学习过程中的重要依据。微调过程中大模型会去理解数据集的回答以及表达风格,如果数据存在瑕疵,大模型也会把这些瑕疵学到,从而影响最终的效果。
- 数据集的指令需要多样化,以避免大模型产生对某些短语的过拟合,而忽略了自然语言的实际含义。
例如对于一个阅读理解数据集,只包含了一种指令"根据以下已知内容,请回答问题并说明原因。已知内容:xxxxx。问题:xxxx"。大模型经过这个数据的精调后很有可能会出现这样的情况:大模型一旦看到"根据以下已知内容"这个短语作为输入,他就自然而然地在回答问题的同时说明原因。 因为大模型通过这批数据的学习,很有可能错误地认为"根据以下已知内容"与"回答时要说明原因"是等价的。这样如果用户输入"根据以下已知内容,请回答问题,要求只回复答案,不要做其他解释。已知内容:xxxxx。问题:xxxx",大模型还是会回复原因。这种针对指令的过拟合现象是需要去避免的,解决办法就是扩充数据集的指令集,做到问题与回答的类型多样、场景多样、避免重复
-
数据集的准备可以由少到多,先从少量数据开始微调,然后逐步增加数据量,直到达到预期的效果。
-
训练数据集:验证数据集:测试数据集(7: 1.5: 1.5)
-
数据集的格式,通常都是用SFT的数据格式进行微调。
SFT:通过有监督的方式精调模型,从而提升模型在特定任务上的指令遵循能力
json
[
{
"instruction": "你是一个聊天机器人,能理解并回答问题",
"input": "你知道会当凌绝顶,一览众山小,这句诗词描述的是哪座山么?",
"output": "黄山,我上周刚去爬了黄山,风景很优美。"
},
]DPO:基于成对的正负反馈数据,直接训练大模型,使其更符合人类偏好。SimPO的数据格式和DPO差不多。
json
[
{
"question": "地球为什么会自转?",
"positive_answer": "地球自转是由于形成初期的角动量守恒,原始星云坍缩时的旋转运动转化为地球的自转,周期约为24小时。",
"negative_answer": "因为地球围绕太阳公转产生了引力作用,所以导致自转。(错误:公转与自转成因不同)"
},
{
"question": "相对论的提出者是谁?",
"positive_answer": "相对论由阿尔伯特·爱因斯坦在20世纪初提出,包括狭义相对论和广义相对论。",
"negative_answer": "牛顿提出了相对论。(错误:牛顿的主要贡献是经典力学)"
}
]KTO:单条回答 + 人类反馈标签,根据人类正向或负向反馈进行模型训练,高效对齐人类行为偏好
json
[
{"instruction": "如何学英语?", "output": "每天坚持阅读英文文章。", "kto_tag": true}
]常用超参
-
epoch:迭代轮次,选择适合的轮次,太高会过拟合,过拟合会导致通用能力下降。通常数据量越多,训练轮次就越少(数据量不够就需要更多次的训练)。例如2千条数据5轮,2万条数据2轮。训练结果不好时,更推荐增加数据的多样性,提升数据量,而不是简单的多训几个 epoch。
-
批处理大小:越大就越越能加速训练。在计算资源(主要是显存)允许的条件下,尽可能提升批量大小。该批量大小和模型参数大小以及序列长度高度相关,也将很大程度上影响训练时间。同时建议在训练中要保证有足够的迭代次数(1000步以上),迭代次数由数据量、迭代轮数、批量大小来决定。在数据量较小,又不适合过多地增加迭代轮数,则可以适当减少批量大小。批次更小的情况下,泛化能力通常更好
-
学习率:它决定了每次更新时权重的调整程度,初始学习率建议选择5e-6(0.000005)至1e-5(0.00001)之间。通常问题越复杂学习率越小,数据集越大学习率越大。通常,较大的学习率可能导致模型在训练过程中波动较大,收敛困难;较小的学习率可能导致收敛速度慢。
-
序列长度:在训练代码中,会根据设置的序列长度,对训练数据进行截断。需要根据自己的训练数据的最长序列长度进行设置,以保证某些重要的数据不会被错误截断。为了提高训练效率,可以将不同长度的数据进行分批次训练(例如先训4k再训8k)。在设置序列长度时,需要对基座模型进行核对,看是否支持相应的序列长度。
-
迭代次数 = epochs × (样本数 / batch_size)。 max_steps作为迭代步数的上限,会覆盖epochs
微调租用算力和三方平台的对比
确定了微调使用SFT之后,我们就要决定如何进行微调
- 租用算力进行微调
优点:
- 算力租用费用便宜,整体的微调过程可以进行多次的微调尝试,直到最终得到效果好
- 只要是开源模型,都可以随意下载微调
缺点:
- 此方式对技术能力要求较高。
- 需要有微调的技术能力,能够对算力资源有效的控制,掌握PyTorch/TensorFlow、Linux和GPU环境配置知识,细腻的控制超参。
- 微调后的模型,长期部署,需要大量的费用
- 使用三方平台进行微调
优点是:
- 对技术能力要求不高,但是对超参的设置经验有要求。
- 三方提供微调功能,可以直接使用,不需要处理环境等问题,准备好数据就可以直接微调。
- 模型微调完成后,支持在平台一键部署,费用和基础模型的费用是一致的,没有额外的部署费用。
缺点:
- 不同的平台数据格式要求不一样,需要把自备的SFT数据格式修改成所用平台需要的
- 模型通常只能选择平台自己的模型进行微调。例如百炼能微调Qwen,火山能微调豆包等
- 微调是按照tokens收费的,模型越大费用越高,例如:百炼的Qwen3 8B是0.006 元/千Token,而32B则是 0.04 元/千Token
由于三方平台按照每次微调的tokens收费,而租用算力后期的部署又很贵。
那么根据二者的优缺点,我们可以做这样的一个选择:二者结合使用。
例如我们想微调Qwen模型,我们可以先租用算力,下载Qwen进行微调测试,当微调需要的超参调整好后,我们可以直接用这些超参和我们的微调数据去百炼平台进行微调。
微调成功后,就可以直接部署到百炼,提供给业务使用。
算力租用和三方平台介绍
算力租用我们通常会选择autodl平台进行租用,价格非常便宜。4090 2.09/小时,H20 7.35/小时。
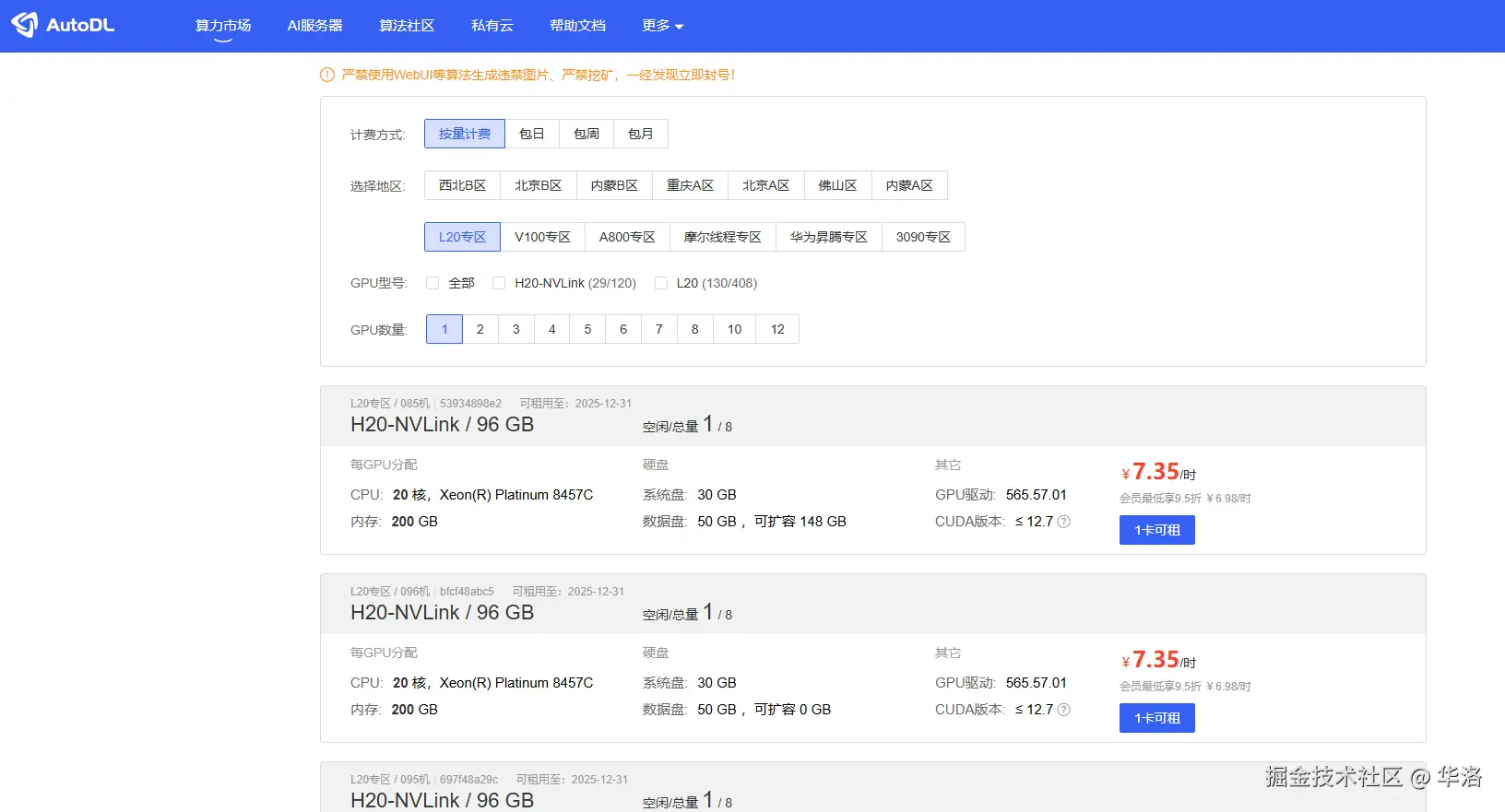
三方平台:
-
阿里的百炼可以微调Qwen系列模型
-
字节的火山可以微调豆包系列模型
-
百度的千帆可以微调文心系列模型
-
讯飞星火、智谱清言也可以对微调自有的模型
微调的成本
微调的成本我们按照时间成本和金钱成本分开来看:
时间成本:
可能有读者在其他地方看到过,微调需要的数据2千条左右就足够了,
但实际上,这所谓的2千条数据必须是一个质量非常好的数据集才行。
我们的数据人员要整理质量很高的数据,通常能做到200-300条/人/天,这就需要大约两人做一周的时间。
拿到数据之后,我们要开始进行微调的超参设置和调整,已达到最好的效果。
根据不同的算力、不同的数据大小,微调的时间是不一样的,大约2-3天能够完成第一次微调任务。
金钱成本:
这里之谈微调算力需要的金钱成本,不谈其他
如果是开源模型,可以选择先在autoDL上进行微调,得到好结果之后,再去平台微调部署,这样可以节约成本。
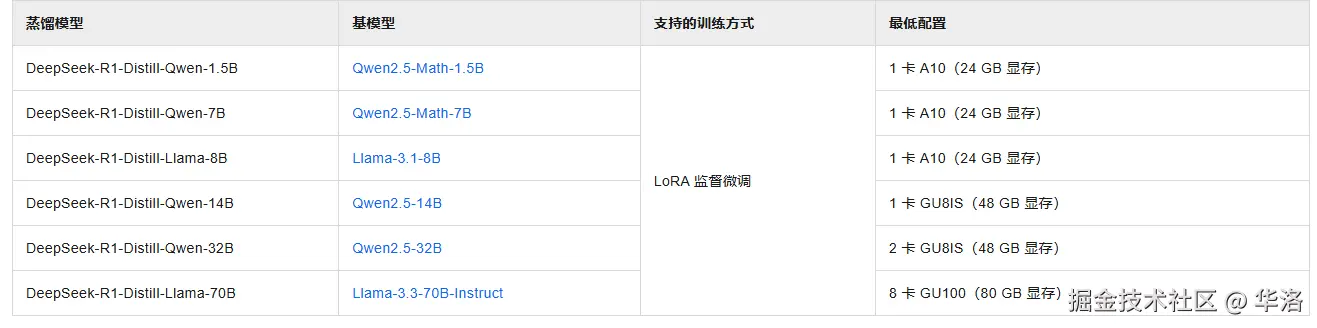
算力和部署所需要的资源放到下图, 算力单价 * 卡数 * 时长可以大概估算出自身微调所需的费用。
微调所需算力资源
部署所需算力资源
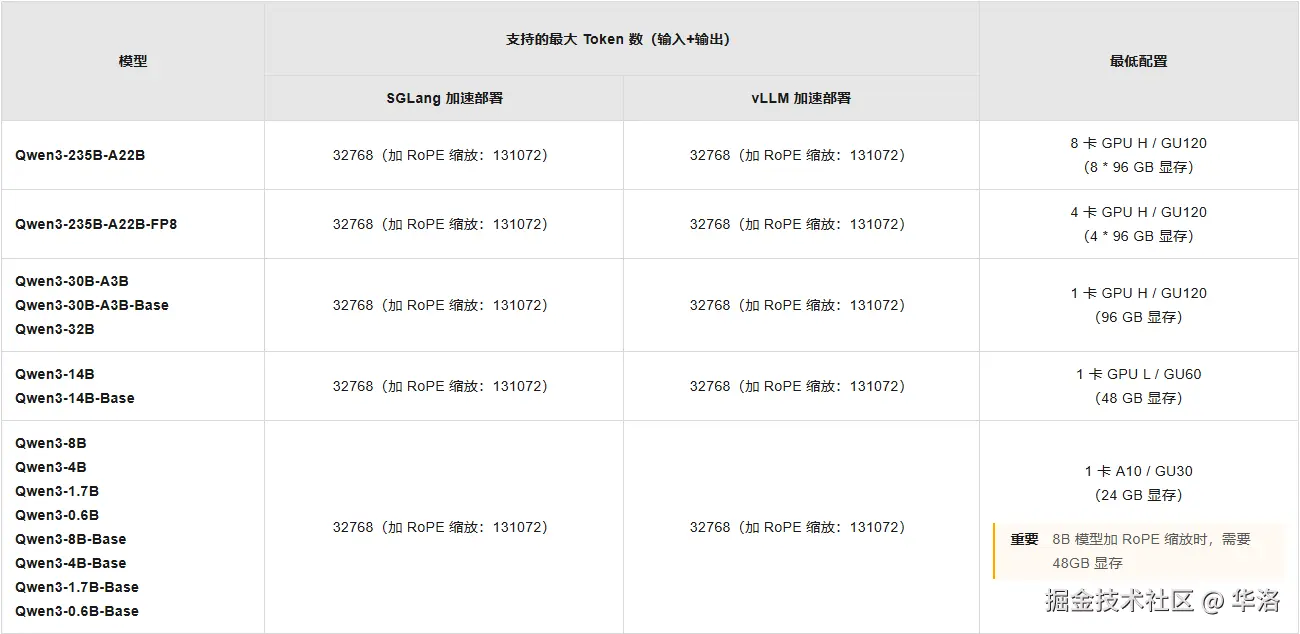
如果不是开源模型,就只能在三方平台进行微调,费用会按照tokens收费,给大家两个平台的收费标准:
-
百炼训练费用 8B是0.006 元/千Token、32B是 0.04 元/千Token;训练费用 =(训练数据tokens + 混合训练数据tokens)✖ 循环次数 ✖ 训练单价。
-
火山训练费用 0.03 元/千Token;训练费用 = 数据集总 tokens ✖ 精调单价 ✖ 迭代轮次;若 tokens 数小于 1000,将会上取整为 1000 tokens 计算
综合来说,我们要得到有效果的微调通常前后要花费千元以上。微调次数越多,花费越多。
微调的弊端
抛开整理数据集、微调测试的时间成本和金钱成本,微调还有一个非常大的弊端:
随着模型能力提升可能会造成基础模型的能力会覆盖微调后的模型,导致微调后的模型失去价值。
这篇文章发出之前,这件事情恰好应验到我身上了:
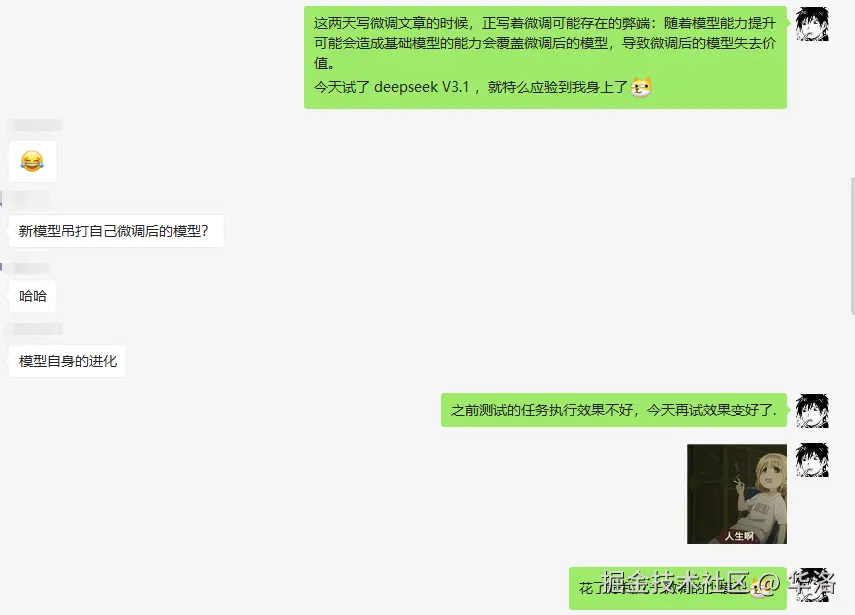
结语
微调是让AI大模型真正在你这片土壤"落地生根"的最后一步,但不是必须的一步。
建议大家优先选择依然是靠工程能力来解决问题,当确实出现瓶颈之后再去考虑微调。
同时,如果有以下三种情况,也不建议微调:
-
任务非常简单,通过精心设计提示词(Prompt Engineering)就能解决。
-
需求变动非常频繁,微调模型的迭代速度跟不上业务变化。
-
没有足够高质量的数据预算或资源。
希望这份指南能让你在面对"是否需要微调"、"微调大概要多少成本"、"微调该怎么进行"这些问题时,
做到心中有数,能更高效地与技术团队沟通协作,共同推动AI产品的成功落地。
加油,共勉!
☺️你好,我是华洛,如果你对程序员转型AI产品负责人感兴趣,请给我点个赞。
你可以在这里联系我👉www.yuque.com/hualuo-fztn...
已入驻公众号【华洛AI转型纪实】,欢迎大家围观,后续会分享大量最近三年来的经验和踩过的坑。
专栏文章
# 从0到1打造企业级AI售前机器人------实战指南三:RAG工程的超级优化
# 从0到1打造企业级AI售前机器人------实战指南二:RAG工程落地之数据处理篇🧐