目录

1.摘要
本文提出了一种将蚁群优化算法(ACO)拓展至连续域的改进方法,该方法在保持ACO原有结构基本不变的基础上,实现了从组合优化到连续优化的自然过渡。
2.算法原理
蚁群优化算法(Ant Colony Optimization, ACO)起源于1990年代,是一种受自然启发的新型优化方法,最初用于解决复杂的组合优化问题,该算法的灵感来源于真实蚂蚁的觅食行为:蚂蚁在寻找食物时,会在返回巢穴的途中释放信息素,其他蚂蚁通过感知这些信息素逐渐汇聚到优质的食物路径上,从而形成最短路径的集体行为。
这一自然现象启发了人工蚁群系统的设计,使其能够模拟蚂蚁的信息素通信机制,在复杂搜索空间中高效地寻找近似最优解。ACO算法的核心在于信息素模型,通过概率采样的方式引导搜索方向,该模型可根据具体的组合优化问题进行构建和调整,为问题求解提供了灵活而强大的机制。
组合优化问题模型 P = ( S , Ω , f ) P=(S,\Omega,f) P=(S,Ω,f)包括三个核心要素:搜索空间 S S S、约束集合 Ω \Omega Ω、以及目标函数 f f f。搜索空间由一组离散变量的所有可能赋值组成,约束集合定义了解的可行性条件,而目标函数则用于评估每个解的优劣,通常目标是最小化该函数值。
每个变量赋值构成一个解组件,所有组件的集合形成了解的构造单元。在ACO算法中,每个解组件 c i j c_{ij} cij对应一个信息素值 τ i j \tau_{ij} τij,这构成了信息素模型的基础。ACO通过这些信息素值建模搜索空间中各组件的概率分布,并在搜索过程中动态更新,从而实现对最优解的引导。
ACO工作的核心思想是基于带有偏向性的(由信息素引导的)概率机制,逐步构造解的过程。在组合优化问题中应用ACO时,可用的解组件集合由问题建模所决定。在每一步构造过程中,蚂蚁会从当前可用组件集合 N ( s p ) N(s^p) N(sp)中以概率方式选择一个解组件 c i c_i ci。集合 N ( s p ) N(s^p) N(sp)中每个元素对应的概率构成一个离散概率分布,蚂蚁通过该分布采样来选择一个组件添加到当前的部分解 s p s^p sp中。
ACO R _R R (用于连续域的ACO) 的基本思想是:将这种离散概率分布的选择机制转变为连续概率分布机制,即使用概率密度函数(PDF)。在ACO R R R中,蚂蚁不再依据公式(1)从集合 N ( s p ) N(s^p) N(sp)中选择一个组件 c i j c{ij} cij,而是从一个PDF中进行采样。
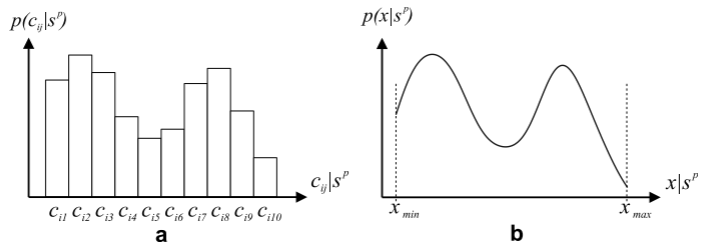
在传统的组合优化中,蚁群优化(ACO)算法通过信息素表来引导搜索过程,每次构造解时,蚂蚁根据表中记录的离散概率分布选择下一个组件。然而在连续优化中,解空间不再是有限集合,信息素无法以表格形式表示,因此需要采用新的策略。
ACO R _R R借鉴了人口基础蚁群优化(PB-ACO)的思想,不再简单丢弃历史解,而是维护一个解档案(solution archive),用于记录多个优秀解的变量值和对应的目标函数值。这些历史解不仅帮助保留搜索经验,还用于构建概率密度函数(PDF),从而实现对连续空间的引导搜索。ACO R _R R利用解档案中的解动态构造一组高斯核函数,每个变量对应一个独立的高斯分布。高斯核的三个参数------权重 ω \omega ω、均值 μ \mu μ和标准差 σ \sigma σ------由档案中的解计算得出,共同决定搜索过程中使用的PDF形状。这一机制不仅替代了离散信息素表,还提升了算法在连续优化问题上的建模能力与搜索效率。
选择第 l l l个高斯函数概率:
p l = ω l ∑ r = 1 k ω r p_l=\frac{\omega_l}{\sum_{r=1}^k\omega_r} pl=∑r=1kωrωl
matlab
function [bestx,bestf, BestCost] = ACOR(nPop, MaxIt, VarMin, VarMax, nVar, CostFunction)
%% Problem Definition
% Decision Variables Lower Bound and Upper Bound
VarSize = [1 nVar]; % Variables Matrix Size
% Sample Size and Parameters
nSample = 40; % Sample Size
q = 0.5; % Intensification Factor (Selection Pressure)
zeta = 1; % Deviation-Distance Ratio
%% Initialization
% Create Empty Individual Structure
empty_individual.Position = [];
empty_individual.Cost = [];
% Create Population Matrix
pop = repmat(empty_individual, nPop, 1);
% Initialize Population Members
for i = 1:nPop
% Create Random Solution
pop(i).Position = unifrnd(VarMin,VarMax,VarSize);
% Evaluation
pop(i).Cost = CostFunction(pop(i).Position);
end
% Sort Population
[~, SortOrder] = sort([pop.Cost]);
pop = pop(SortOrder);
% Update Best Solution Ever Found
BestSol = pop(1);
% Array to Hold Best Cost Values
BestCost = zeros(MaxIt, 1);
% Solution Weights
w = 1 / (sqrt(2*pi) * q * nPop) * exp(-0.5 * (((1:nPop) - 1) / (q * nPop)).^2);
% Selection Probabilities
p = w / sum(w);
%% ACOR Main Loop
for it = 1:MaxIt
% Means
s = zeros(nPop, nVar);
for l = 1:nPop
s(l, :) = pop(l).Position;
end
% Standard Deviations
sigma = zeros(nPop, nVar);
for l = 1:nPop
D = 0;
for r = 1:nPop
D = D + abs(s(l, :) - s(r, :));
end
sigma(l, :) = zeta * D / (nPop - 1);
end
% Create New Population Array
newpop = repmat(empty_individual, nSample, 1);
for t = 1:nSample
% Initialize Position Matrix
newpop(t).Position = zeros(VarSize);
% Solution Construction
for i = 1:nVar
% Select Gaussian Kernel
l = RouletteWheelSelection(p);
% Generate Gaussian Random Variable
newpop(t).Position(i) = s(l, i) + sigma(l, i) * randn;
end
% Evaluation
newpop(t).Cost = CostFunction(newpop(t).Position);
end
% Merge Main Population (Archive) and New Population (Samples)
pop = [pop; newpop];
% Sort Population
[~, SortOrder] = sort([pop.Cost]);
pop = pop(SortOrder);
% Delete Extra Members
pop = pop(1:nPop);
% Update Best Solution Ever Found
BestSol = pop(1);
% Store Best Cost
BestCost(it) = BestSol.Cost;
end
%% Results
bestf = BestCost(end);
bestx = BestSol.Position;
[~,bestx] = sort(bestx);
end
function j = RouletteWheelSelection(P)
r = rand;
C = cumsum(P);
j = find(r <= C, 1, 'first');
end3.结果展示
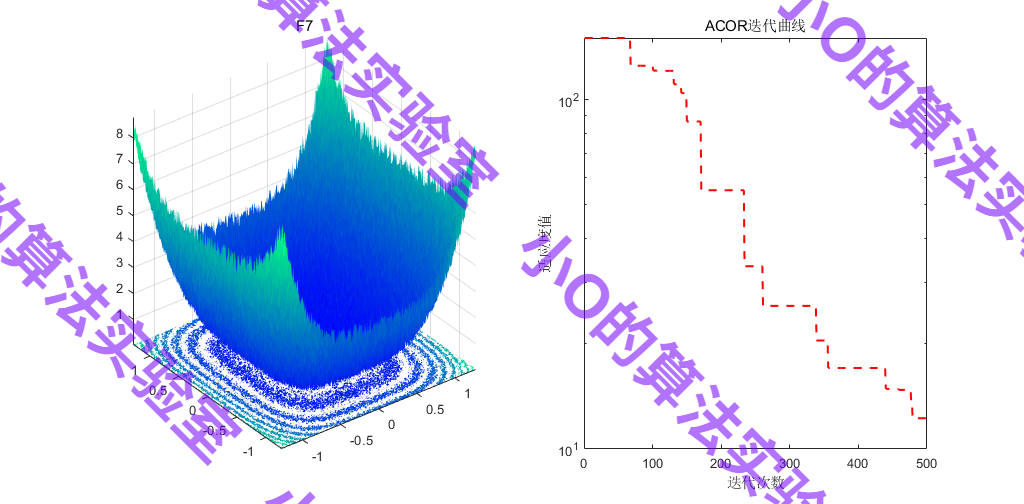
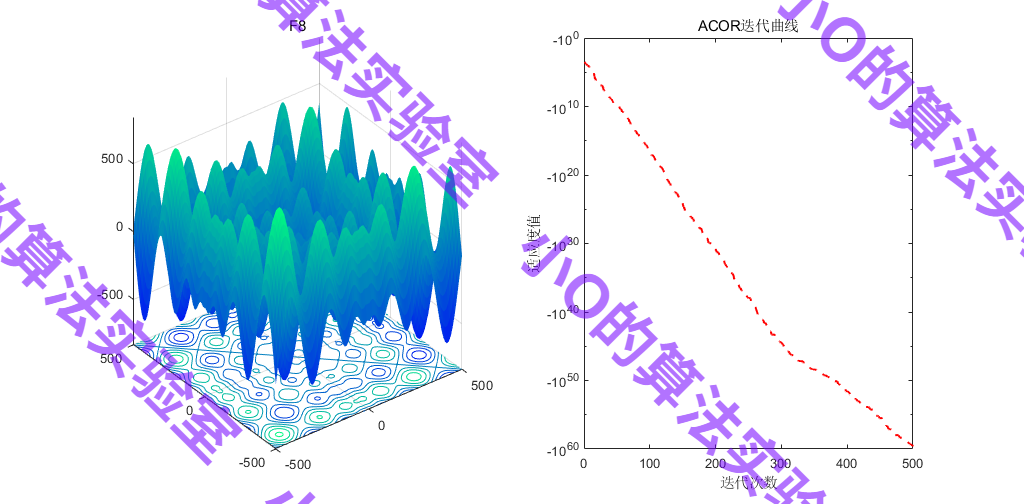
4.参考文献
1 Socha K, Dorigo M. Ant colony optimization for continuous domainsJ. European journal of operational research, 2008, 185(3): 1155-1173.