文章目录
- 分布式缓存
-
- [**Redis 持久化**](#Redis 持久化)
-
- [**一、RDB(Redis DataBase)**](#一、RDB(Redis DataBase))
- [**RDB 原理分析**](#RDB 原理分析)
- [**RDB 的优缺点**](#RDB 的优缺点)
- [**AOF (Append Only File)**](#AOF (Append Only File))
-
- **一、核心原理**
- **二、工作流程与配置**
-
- [1. **AOF 文件写入流程**](#1. AOF 文件写入流程)
- [**2. 同步策略(`appendfsync`)**](#2. 同步策略(
appendfsync)) - [3. **AOF 重写(Rewrite)**](#3. AOF 重写(Rewrite))
- [**三、AOF 的优缺点**](#三、AOF 的优缺点)
- **四、对比**
- **主从集群**
-
- **一、主从集群的核心概念**
- **二、主从复制的工作原理**
-
- **复制流程**
-
- [**一、全量同步(Full Sync)**](#一、全量同步(Full Sync))
-
- [**1. 触发条件**](#1. 触发条件)
- [**2. 流程**](#2. 流程)
- [**二、增量同步(Partial Sync)**](#二、增量同步(Partial Sync))
-
- [**1. 触发条件**](#1. 触发条件)
- [**2. 流程**](#2. 流程)
- [**复制 ID(Replication ID)**](#复制 ID(Replication ID))
-
- [**1. 定义**](#1. 定义)
- [**2. 作用**](#2. 作用)
- [**偏移量(Replication Offset)**](#偏移量(Replication Offset))
-
- [**1. 定义**](#1. 定义)
- [**2. 作用**](#2. 作用)
- [**复制积压缓冲区(Replication Backlog Buffer)**](#复制积压缓冲区(Replication Backlog Buffer))
-
- [**1. 定义**](#1. 定义)
- [**2. 作用**](#2. 作用)
- [**3. 缓冲区溢出风险**](#3. 缓冲区溢出风险)
- **redis哨兵**
-
- **一、哨兵的核心功能**
- **二、节点监控**
-
- [**1. 监控机制**](#1. 监控机制)
- [**2. 主观下线(SDOWN)与客观下线(ODOWN)**](#2. 主观下线(SDOWN)与客观下线(ODOWN))
- **三、自动故障转移**
-
- [**1. 触发条件**](#1. 触发条件)
- [**2. 故障转移流程**](#2. 故障转移流程)
- [**3. 新主选举规则**](#3. 新主选举规则)
- **四、配置中心**
-
- [**1. 动态维护集群拓扑**](#1. 动态维护集群拓扑)
- [**2. 配置信息持久化**](#2. 配置信息持久化)
- [**3. 发布/订阅机制通知变更**](#3. 发布/订阅机制通知变更)
- [**Spring Data Redis中配置Redis主从集群**](#Spring Data Redis中配置Redis主从集群)
- **分片集群(Cluster)**
-
- **一、分片集群特征**
- **二、分片集群的核心特性**
- **二、核心概念**
-
- [**1. 哈希槽(Hash Slot)**](#1. 哈希槽(Hash Slot))
- [**2. 节点角色**](#2. 节点角色)
- **三、哈希槽的实践问题与优化**
-
- [**1. 多键操作限制**](#1. 多键操作限制)
- [**2. 数据倾斜**](#2. 数据倾斜)
- [**3. 槽迁移对性能的影响**](#3. 槽迁移对性能的影响)
- **三、自动故障转移流程**
- **四、客户端路由机制**
- **五、分片集群(Cluster)的核心优势**
- [**六、分片集群 vs 主从集群对比表**](#六、分片集群 vs 主从集群对比表)
分布式缓存
单机的Redis存在四大问题:
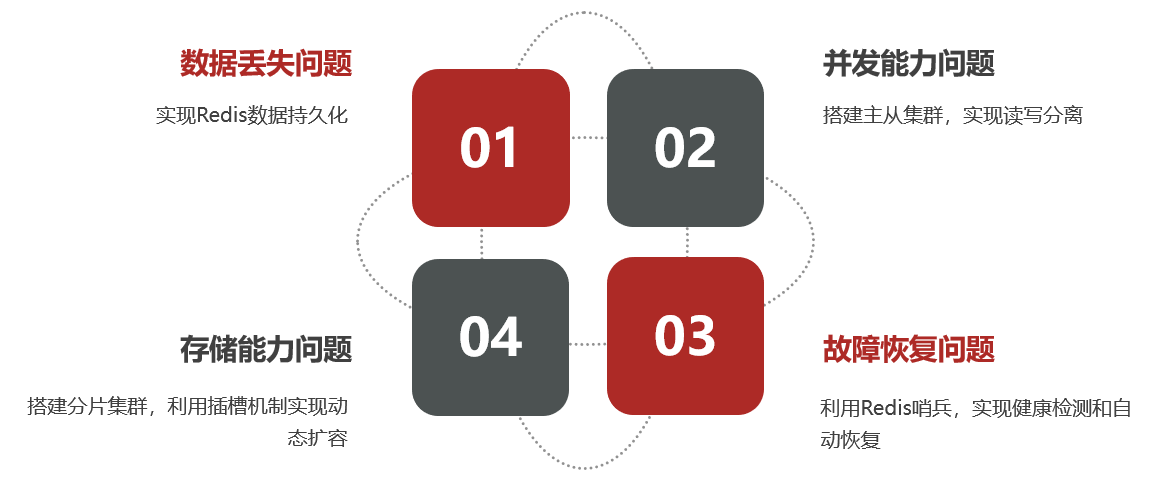
基于Redis集群来解决Redis存在的问题
Redis 持久化
Redis 持久化是将内存中的数据保存到磁盘,防止服务重启或故障时数据丢失的核心机制。Redis 提供了两种主要的持久化方式:RDB(快照) 和 AOF(追加日志),以及两者的混合模式。
一、RDB(Redis DataBase)
原理 :定期生成数据快照(二进制文件dump.rdb),保存当前数据库状态。
触发方式:
- 手动触发 :
SAVE:阻塞主进程,直到快照完成(生产环境慎用)。BGSAVE:后台 fork 子进程生成fork瞬间的快照,主进程继续响应请求。
- 自动触发 :
- 配置
save <seconds> <changes>,例如save 900 1表示 900 秒内至少 1 次修改则触发。 - Redis停机时会执行一次save命令。
- 主从复制时,从节点全量同步会触发主节点生成 RDB。
- 配置
RDB 原理分析
核心流程
bgsave触发
当执行BGSAVE命令或满足配置的自动触发条件(如save 900 1)时,Redis 主进程会调用fork()系统调用创建子进程。- fork 与内存共享
- 子进程与父进程(主进程)共享内存数据 ,此时两者的页表指向相同的物理内存页。
- 页表是操作系统管理 虚拟内存 与 物理内存 映射关系的核心数据结构。每个进程的虚拟内存地址通过页表转换为物理地址,其核心特点:
- 分页机制:内存按固定大小(如 4KB)划分成页,页表记录每个虚拟页对应的物理页。
- 写时复制(COW, Copy-On-Write):当进程 fork 时,子进程共享父进程的页表,仅在实际修改内存时复制物理页。
- 页表是操作系统管理 虚拟内存 与 物理内存 映射关系的核心数据结构。每个进程的虚拟内存地址通过页表转换为物理地址,其核心特点:
- 操作系统通过 写时复制(Copy-On-Write, COW) 机制管理内存修改,确保子进程的内存视图是 fork 瞬间的一致性快照。
- 子进程与父进程(主进程)共享内存数据 ,此时两者的页表指向相同的物理内存页。
- 子进程生成 RDB 文件
- 子进程遍历数据库,将内存数据按二进制格式写入临时 RDB 文件(如
temp-1234.rdb)。 - 写入完成后,用临时文件原子替换旧的
dump.rdb文件。
- 子进程遍历数据库,将内存数据按二进制格式写入临时 RDB 文件(如
- 主进程继续处理请求
- 主进程在子进程生成 RDB 期间仍可处理客户端请求,所有写操作触发 COW 机制,不影响子进程的快照一致性。
RDB 的优缺点
优点
- 恢复速度快:二进制文件直接载入内存,适合大数据量快速恢复。
- 文件紧凑:体积小,便于备份和传输(如灾备场景)。
- 对性能影响小:后台异步生成快照,主进程无阻塞。
缺点
- 数据丢失风险:两次快照之间的数据可能丢失(依赖触发频率)。
- fork 内存开销:大数据量时,fork 子进程可能导致短暂阻塞和内存翻倍(COW 机制)。
- 版本兼容性:高版本生成的 RDB 文件可能无法兼容低版本 Redis。
AOF (Append Only File)
一、核心原理
AOF(Append Only File)通过记录所有 写操作命令 (文本格式)实现持久化,重启时重放命令恢复数据。
核心流程:
- 命令追加:每个写命令执行后,追加到 AOF 缓冲区。
- 文件同步 :根据配置策略(
appendfsync)将缓冲区数据同步到磁盘文件。 - 文件重写:定期压缩 AOF 文件体积,移除冗余命令(如多次修改同一 key 的命令)。
二、工作流程与配置
1. AOF 文件写入流程
客户端写请求 Redis 主进程 执行写操作 将命令追加到AOF缓冲区 AOF缓冲区 根据appendfsync策略同步到磁盘
2. 同步策略(appendfsync)
| 策略 | 行为 | 特点 |
|---|---|---|
| always | 每条命令执行后立即同步到磁盘。 | 数据安全性最高(无丢失),但性能最差(频繁磁盘 I/O)。 |
| everysec | 每秒同步一次缓冲区数据到磁盘(默认配置)。 | 平衡选择,最多丢失 1 秒数据。适合大多数场景。 |
| no | 由操作系统决定同步时机(通常累积到一定量或周期触发)。 | 性能最高,但可能丢失大量数据(如系统崩溃时缓冲区未刷盘)。 |
3. AOF 重写(Rewrite)
目的 :解决 AOF 文件膨胀问题,生成更紧凑的新 AOF 文件(等效当前数据库状态的最小命令集合)。
触发方式:
- 手动触发 :执行
BGREWRITEAOF命令。 - 自动触发 :根据配置
auto-aof-rewrite-percentage和auto-aof-rewrite-min-size(例如,文件大小增长超过 100% 且至少 64MB 时触发)。
重写流程:
- fork 子进程 :基于当前数据库状态生成新 AOF 文件(与 RDB 的
BGSAVE类似)。 - 双缓冲区机制:重写期间的新写命令同时追加到原 AOF 缓冲区和新 AOF 重写缓冲区。
- 替换文件:重写完成后,用新文件替换旧文件,并追加重写缓冲区的命令。
三、AOF 的优缺点
| 优点 | 缺点 |
|---|---|
| 1. 数据安全性高:默认最多丢失 1 秒数据。 | 1. 文件体积大:长期运行可能膨胀至数倍于 RDB。 |
| 2. 可读性强:文本格式便于人工分析或修复。 | 2. 恢复速度慢:重放命令比 RDB 载入慢。 |
| 3. 支持混合持久化(Redis 4.0+)。 | 3. 写性能依赖磁盘速度(建议 SSD)。 |
四、对比
| 维度 | RDB | AOF |
|---|---|---|
| 持久化原理 | 定期生成内存快照(二进制文件)。 | 记录所有写操作命令(文本文件)。 |
| 数据安全性 | 可能丢失最后一次快照后的所有修改(分钟级)。 | 默认最多丢失 1 秒数据(appendfsync everysec)。 |
| 恢复速度 | 极快(直接加载二进制文件到内存)。 | 较慢(需逐条重放命令)。 |
| 文件体积 | 小(二进制压缩,适合备份)。 | 大(文本命令累积,需定期重写压缩)。 |
| 性能影响 | 低(后台异步生成,主进程无阻塞)。 | 较高(依赖同步策略,频繁磁盘 I/O)。 |
| 可读性 | 不可读(二进制格式)。 | 可读(文本命令,便于人工分析或修复)。 |
| 配置复杂度 | 简单(仅需设置触发频率)。 | 较高(需管理同步策略、重写规则等)。 |
| 适用场景 | 允许数据丢失、追求快速恢复的场景(如缓存)。 | 对数据一致性要求高的场景(如金融交易)。 |
主从集群
一、主从集群的核心概念
- 角色定义 :
- 主节点(Master) :负责处理写请求(
SET,DEL等),并将数据变更同步到从节点。 - 从节点(Slave/Replica):复制主节点的数据,默认处理读请求(可配置为只读或允许写入)。
- 主节点(Master) :负责处理写请求(
- 核心特性 :
- 数据冗余:从节点保存主节点完整数据,提升容灾能力。
- 读写分离:主节点处理写操作,从节点分担读负载,提高吞吐量。
- 故障恢复:主节点宕机后,可手动或通过哨兵(Sentinel)自动切换从节点为主节点。
二、主从复制的工作原理
复制流程
当从节点连接主节点时,触发全量或增量同步:
首次连接或复制ID不匹配 已有部分数据 从节点启动 发送SYNC命令 主节点判断 全量同步: 生成RDB快照 增量同步: 发送缓冲区命令 从节点加载RDB 从节点执行增量命令 持续接收新命令
一、全量同步(Full Sync)
1. 触发条件
从节点在以下场景会触发全量同步:
- 首次连接主节点:从节点初次建立主从关系。
- 复制 ID 不匹配:主节点因故障切换或重启导致复制 ID 变更。
- 复制偏移量(Offset)失效:从节点的偏移量不在主节点的**复制积压缓冲区(Replication Backlog)**范围内。
2. 流程
从节点 主节点 发送 PSYNC 命令(携带复制ID和偏移量) 判断需全量同步 执行 BGSAVE,生成 RDB 快照 发送 RDB 文件 清空旧数据,加载 RDB 发送缓冲区中的新写命令(同步期间的增量数据) 持续接收并执行增量命令 从节点 主节点
二、增量同步(Partial Sync)
1. 触发条件
从节点满足以下条件时触发增量同步:
- 复制 ID 匹配:主节点未发生切换,复制 ID 一致。
- 复制偏移量有效 :从节点的偏移量仍存在于主节点的复制积压缓冲区中。
2. 流程
从节点 主节点 发送 PSYNC 命令(携带复制ID和偏移量) 判断可增量同步,回复 +CONTINUE 发送积压缓冲区中缺失的写命令 执行增量命令,追赶主节点状态 持续接收并执行新写命令 从节点 主节点
复制 ID(Replication ID)
1. 定义
- 复制 ID 是一个全局唯一的 40 字节字符串,标识主节点的 数据版本历史。
- 每个主节点在启动时生成一个 主复制 ID(main ID) ,并在故障切换(如 Sentinel 自动切换)时生成一个 辅助复制 ID(secondary ID)。
2. 作用
- 标识数据流:用于判断主从节点的数据是否属于同一复制流(即是否共享同一数据历史)。
- 触发全量同步 :
- 当从节点携带的复制 ID 与主节点不匹配时(例如主节点重启或切换),触发全量同步。
- 示例:主节点故障切换后,新主节点生成新的复制 ID,从节点需全量同步。
偏移量(Replication Offset)
1. 定义
- 偏移量 是一个 64 位整数,表示主节点已传播给从节点的数据总量。
- 主节点和从节点各自维护一个偏移量:
- 主节点 :
master_repl_offset,记录已生成的所有写命令的数据总量。 - 从节点 :
slave_repl_offset,记录已接收并执行的写命令的数据总量。
- 主节点 :
2. 作用
- 判断数据一致性 :通过比较主从节点的偏移量,可确定从节点是否与主节点数据同步。
- 若
slave_repl_offset == master_repl_offset,表示数据完全一致。 - 若
slave_repl_offset < master_repl_offset,表示从节点数据滞后。
- 若
- 增量同步依据 :从节点断线重连时,若其偏移量仍在主节点的 复制积压缓冲区 范围内,则触发增量同步。
复制积压缓冲区(Replication Backlog Buffer)
1. 定义
- 复制积压缓冲区 是主节点维护的一个 固定大小的环形内存缓冲区,用于保存最近传播的写命令。
2. 作用
- 支持增量同步:当从节点断线重连时,若其偏移量仍在缓冲区范围内,主节点直接发送缺失的写命令(增量同步)。
- 避免全量同步:缓冲区保存了足够的历史命令,减少因短时断线触发的全量同步。
3. 缓冲区溢出风险
- 场景:若从节点断开时间过长,或主节点写入速度过快,缓冲区可能被新数据覆盖。
- 后果:从节点的偏移量不在缓冲区范围内,触发全量同步。
redis哨兵
一、哨兵的核心功能
- 节点监控
- 持续检查主节点和从节点的健康状态(是否可达、是否正常响应)。
- 自动故障转移(Failover)
- 主节点宕机时,自动选举新的主节点并通知客户端。
- 配置中心(通知客户端)
- 维护集群拓扑信息,客户端通过哨兵获取最新的主节点地址。
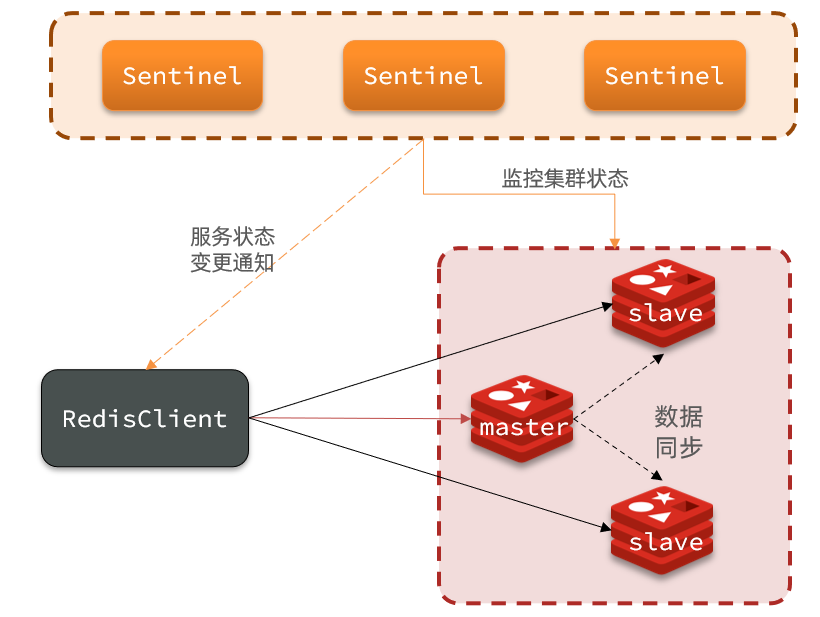
- 维护集群拓扑信息,客户端通过哨兵获取最新的主节点地址。
二、节点监控
1. 监控机制
哨兵通过周期性执行以下操作监控节点健康状态:
- PING 检测 :每 1 秒向所有主从节点发送
PING命令。 - 响应超时判断 :若节点在
down-after-milliseconds(默认 30 秒)内未响应,标记为 主观下线(SDOWN)。
2. 主观下线(SDOWN)与客观下线(ODOWN)
| 类型 | 触发条件 | 后续动作 |
|---|---|---|
| 主观下线 | 单个哨兵实例检测到节点无响应。 | 向其他哨兵发起投票,确认是否客观下线。 |
| 客观下线 | 超过指定数量哨兵(sentinel.conf配置)确认节点不可达。 | 触发故障转移流程。 |
示例配置:
bash
sentinel monitor mymaster 192.168.1.100 6379 2 # quorum=2,需至少2个哨兵确认
sentinel down-after-milliseconds mymaster 5000 # 5秒无响应标记为主观下线三、自动故障转移
1. 触发条件
- 主节点被标记为 客观下线(ODOWN)。
- 且从节点健康状态良好。
2. 故障转移流程
LeaderSentinel Slave1 Slave2 Client 选举新主(优先级最高、偏移量最新) SLAVEOF NO ONE SLAVEOF <新主IP> <端口> 发布 +switch-master 事件 将请求切换到新主节点 LeaderSentinel Slave1 Slave2 Client
3. 新主选举规则
- 优先级(
slave-priority):从节点配置文件中设置的优先级,值越小优先级越高。 - 复制偏移量(
repl_offset):选择偏移量最大的从节点(数据最新)。 - 运行 ID:若优先级和偏移量相同,选择运行 ID 最小的从节点。
四、配置中心
1. 动态维护集群拓扑
- 功能 :
哨兵持续监控主从节点的健康状态,并在主节点故障时更新集群拓扑信息(如新主节点的地址)。 - 客户端透明访问 :
客户端无需硬编码主节点 IP,而是通过查询哨兵获取当前有效的主节点地址,实现动态切换。
2. 配置信息持久化
- 自动更新配置 :
哨兵将最新的主节点信息持久化到sentinel.conf文件中,确保重启后仍能恢复集群状态。
3. 发布/订阅机制通知变更
- 事件通知 :
哨兵通过 Redis 的发布/订阅(Pub/Sub)机制,向客户端推送主节点切换事件。
Spring Data Redis中配置Redis主从集群
1.引入依赖
在项目的pom文件中引入依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2.配置Redis地址
然后在配置文件application.yml中指定redis的sentinel相关信息:
java
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:270033.配置读写分离
在项目的启动类中,添加一个新的bean:
java
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}分片集群(Cluster)
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
Redis 分片集群(Cluster)是 Redis 官方提供的 分布式解决方案,通过数据分片、节点自治和高可用机制,实现水平扩展和高并发场景下的高性能服务。
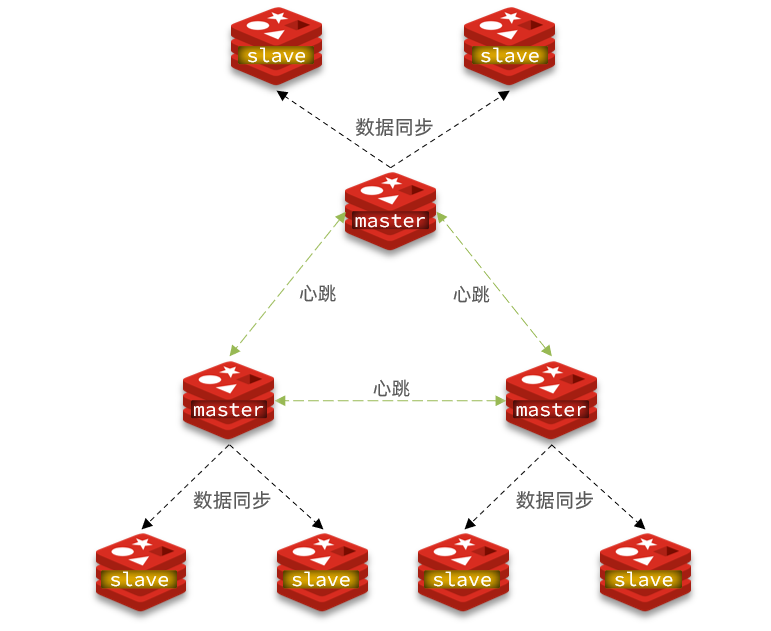
一、分片集群特征
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
二、分片集群的核心特性
| 特性 | 说明 |
|---|---|
| 数据分片 | 数据按哈希槽(Hash Slot)分布在多个节点,支持水平扩展。 |
| 高可用性 | 每个分片(主节点)至少有一个从节点,自动故障转移。 |
| 去中心化架构 | 节点间通过 Gossip 协议通信,无需依赖外部协调服务(如哨兵)。 |
| 客户端路由 | 客户端直接与集群交互,支持自动重定向(MOVED/ASK 响应)。 |
二、核心概念
1. 哈希槽(Hash Slot)
-
分片单位 :Redis Cluster 将数据划分为 16384 个哈希槽,每个键通过 CRC16 算法计算哈希值后取模确定所属槽。
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且"{}"中至少包含1个字符,"{}"中的部分是有效部分
- key中不包含"{}",整个key都是有效部分。
-
槽分配
- 初始化分配:集群创建时,槽均匀分配给所有主节点(如 3 主节点时,每个节点约 5461 个槽)。
- 动态调整 :支持运行时迁移槽(如扩容/缩容),通过命令
CLUSTER ADDSLOTS或工具redis-cli --cluster reshard实现。
2. 节点角色
- 主节点(Master):负责处理读写请求,管理分配的哈希槽。
- 从节点(Replica):复制主节点数据,主节点故障时通过选举成为新主。
三、哈希槽的实践问题与优化
1. 多键操作限制
- 问题:事务、Lua 脚本等要求所有操作的键必须位于同一槽。
- 解决方案 :
- 使用哈希标签:确保相关键映射到同一槽。
- 设计键结构 :将逻辑关联的数据绑定到同一业务ID(如
order:{123}:items和order:{123}:status)。
2. 数据倾斜
- 原因:某些槽的键过多(如热点数据或未使用哈希标签)。
- 优化方法 :
- 监控槽分布 :定期执行
CLUSTER SLOTS查看槽负载。 - 手动均衡:迁移高负载槽到空闲节点。
- 监控槽分布 :定期执行
3. 槽迁移对性能的影响
- 影响:迁移过程中,涉及槽的读写可能短暂阻塞。
- 缓解措施 :
- 低峰期操作:在业务低峰期执行槽迁移。
- 增量迁移:分批迁移槽,避免一次性大量数据移动。
三、自动故障转移流程
- 故障检测
- 节点心跳:集群节点间通过 Gossip 协议定期发送 PING/PONG 消息。
- 主观下线(PFail) :若某节点在
cluster-node-timeout(默认 15 秒)内未响应,其他节点将其标记为 PFail。 - 客观下线(Fail):超过半数主节点确认 PFail 后,触发故障转移流程。
- 从节点选举
- 资格检查 :从节点需满足以下条件:
- 主节点已确认为 Fail 状态。
- 从节点与主节点的复制偏移量(
repl_offset)最新。
- Raft 算法:从节点发起选举请求,获得多数主节点投票后晋升为新主。
- 资格检查 :从节点需满足以下条件:
- 槽所有权转移
- 更新拓扑:新主节点接管原主节点的所有槽,通过 Gossip 协议广播新配置。
- 数据同步:其他从节点与新主节点建立复制关系,同步数据。
示例命令:
# 查看集群节点状态(故障转移后)
redis-cli -h 192.168.1.101 -p 6379 CLUSTER NODES四、客户端路由机制
-
初始路由表
-
启动时获取 :客户端首次连接集群时,随机选择一个节点获取完整的槽分布信息(
CLUSTER SLOTS)。 -
缓存槽映射:客户端本地维护槽到节点的映射表,如:
json{ "0-5460": "192.168.1.100:6379", "5461-10922": "192.168.1.101:6379", "10923-16383": "192.168.1.102:6379" }
-
-
请求路由逻辑
- 计算哈希槽:客户端对键执行 CRC16 % 16384 计算槽号。
- 直接发送请求:根据本地路由表,将请求发送到对应节点。
-
处理重定向响应
- MOVED 响应 :节点返回
MOVED <slot> <ip>:<port>,指示槽已永久迁移。- 客户端动作:更新本地路由表,重试请求到新节点。
- ASK 响应 :节点返回
ASK <slot> <ip>:<port>,指示槽正在迁移中(临时重定向)。- 客户端动作 :向新节点发送
ASKING命令后重试,不更新本地路由表。
- 客户端动作 :向新节点发送
Client NodeA NodeB SET key1 value MOVED 1234 NodeB:6379 SET key1 value OK Client NodeA NodeB
- MOVED 响应 :节点返回
-
自适应刷新策略
- 定时刷新:客户端定期(如每分钟)重新拉取集群槽分布,更新路由表。
- 触发刷新:累计收到多次 MOVED 响应后,主动刷新路由表。
五、分片集群(Cluster)的核心优势
- 水平扩展能力
- 数据分片:将数据分散到多个节点,突破单机内存和性能瓶颈,支持 TB 级数据。
- 吞吐量提升:并行处理读写请求,适合高并发场景(如电商秒杀、社交平台热点数据)。
- 高可用性
- 自动故障转移:每个分片(主节点)至少有一个从节点,主节点宕机时自动切换。
- 节点自治:无需依赖外部哨兵,通过 Gossip 协议和 Raft 算法实现自管理。
- 去中心化架构
- 无单点故障:所有节点对等,任一节点宕机不影响整体服务(除非多个节点同时故障)。
- 动态扩缩容
- 在线迁移槽:支持运行时添加或移除节点,数据自动重新平衡。
六、分片集群 vs 主从集群对比表
| 维度 | 分片集群(Cluster) | 主从集群(Replication + Sentinel) |
|---|---|---|
| 数据分布 | 数据分片到多个节点,支持水平扩展。 | 数据集中在主节点,从节点为副本。 |
| 扩展性 | 水平扩展:通过增加节点提升容量和吞吐量。 | 垂直扩展:受限于单机性能,只能提升主节点配置。 |
| 高可用性 | 每个分片主从自动切换,无需外部组件。 | 依赖哨兵实现故障转移,需额外部署哨兵实例。 |
| 写性能 | 高(多主节点并行写入)。 | 低(单主节点写入,存在瓶颈)。 |
| 多键操作 | 限制跨槽操作(需使用哈希标签)。 | 无限制,支持事务、Lua 脚本。 |
| 复杂度 | 高(需管理分片、槽迁移、客户端路由)。 | 低(配置简单,客户端透明)。 |
| 适用场景 | 大数据量(>16GB)、高并发读写(如社交平台、实时分析)。 | 中小数据量、读多写少(如博客系统、配置中心)。 |
| 客户端支持 | 需支持集群协议(如 JedisCluster、Lettuce)。 | 普通客户端即可(如 Jedis、Lettuce)。 |