Redis 高可用
- Redis的高可用机制有持久化、复制、哨兵和集群。其主要的作用和解决的问题分别是:
- 持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
- 主从架构:主从复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份 ,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
- 哨兵:哨兵实现了主从复制中故障的自动化恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
- 集群:通过集群,解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
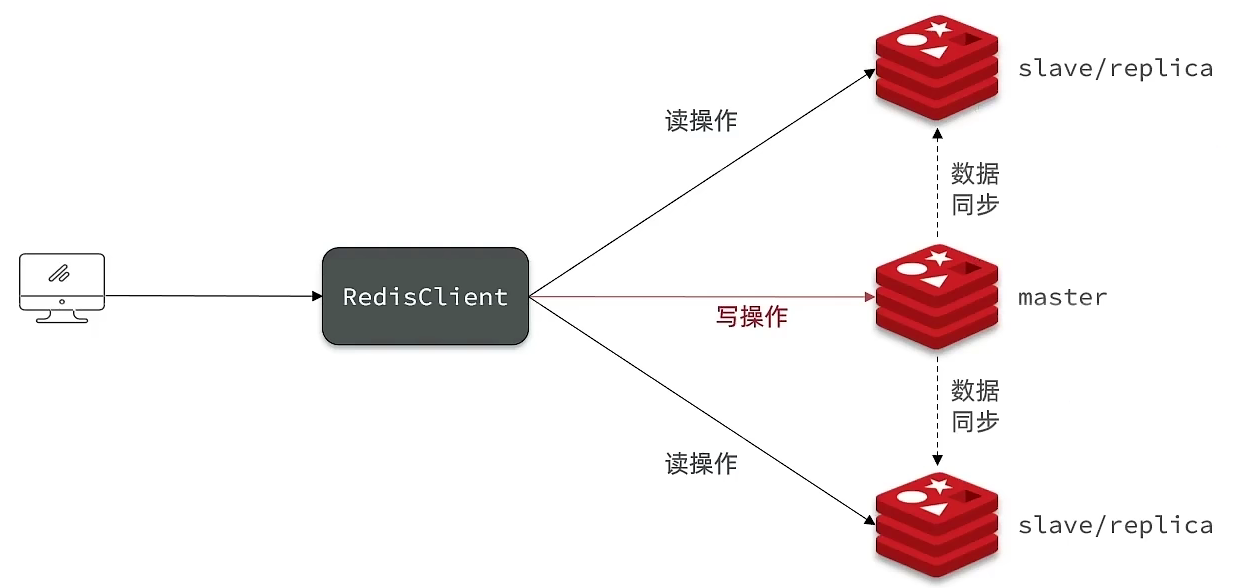
Redis 主从架构
- 单节点 Redis 的并发能力是有上限的,要进一步提高 Redis 的并发能力,就需要搭建主从集群,实现读写分离。
- 所有的从节点都从主节点进行数据同步,这样会导致主节点的同步处理压力过大而成为瓶颈。为了解决这个问题,redis还支持了从slave节点分发的能力,也就是从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个主从链 。这样可以分摊主服务器压力。
全量同步
- 何时执行?
- slave 节点第一次连接 master 节点时。
- slave 节点断开时间太久,repl_baklog中的 offset 已经被覆盖时。
- master 如何判断 slave 是不是第一次来同步数据?
Replication ld:简称 replid,是数据集的标记,id 一致则说明是同一数据集。每一个master都有唯一的 replid,slave 则会继承 master 节点的 replid。offset:偏移量,随着记录在 repl_baklog 中的数据增多而逐渐增大。slave 完成同步时也会记录当前同步的 offset。如果 slave 的 offset 小于 master 的 offset,说明 slave 数据落后于 master,需要更新。因此slave做数据同步,必须向master声明自己的replication Id 和 offset,master才可以判断到底需要同步哪些数据。
- 流程:
- slave 节点请求增量同步。
- master 节点判断 replid,发现不一致,拒绝增量同步。
- master 将完整内存数据生成 RDB,发送 RDB 到 slave。
- slave 先清空当前本地数据,加载 master 的 RDB。
- master 将 RDB 期间的命令记录在 repl_baklog,并持续将 log 中的命令发送给 slave。
- slave 执行接收到的命令,保持与 master 之间的同步。

- 主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接,这个TCP连接是长连接。之后就会基于这个长连接进行命令传播。通过这种方式来保证第一次同步后的主从服务器的数据一致性。
增量同步
- 何时执行?
- slave 节点断开又恢复,并且在 repl_baklog 中能找到 offset 时。

- slave 节点断开又恢复,并且在 repl_baklog 中能找到 offset 时。
- repl_baklog 大小有上限,写满后会覆盖最早的数据。如果 slave 断开时间过久,导致尚未备份的数据被覆盖,则无法基于 log 做增量同步,只能再次全量同步。
主从复制存在的问题
- Redis 的主从模式重点在于解决整体的承压能力,利用从节点分担读取操作的压力。但是其在容错恢复 等可靠性层面欠缺明显,不具备自动的故障转移与恢复能力
Redis 哨兵机制(Redis Sentinel)
- 为了支持自动的故障恢复能力,Redis在主从模式的基础上进行优化增强,提供了哨兵(Sentinel)架构模式。
- Redis的哨兵模式,就是在主从模式的基础上,额外部署若干独立的哨兵进程,通过哨兵进程去监视Redis主从节点的状态,一旦发现主节点宕机,则哨兵可以重新从剩余slave节点中推选一个新的节点并将其升级为master节点,以此保证整个系统功能可以正常使用。
哨兵负责三个任务:监控、选主、通知。
- 监控:Sentinel会不断检查您的master和slave是否按预期工作。
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主。
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端。
服务状态监控
- Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
- 哨兵误判:主库实际没有下线,但是哨兵以为它下线了。误判产生原因:比如集群网络压力较大,出现网络拥塞,或者主库本身压力较大,导致主节点没有在规定时间内响应哨兵的 PING 命令。
选举新的master
- 一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据如下:
- 首先判断每个slave节点与master节点断开时间长短,如果超过指定值(down-after-miliseconds*10),则会排除该slave节点。
- 然后判断每个slave节点的slave-priority值,优先选择值小(优先级最高)的,如果是0则永不参与选举。
- 如果slave-prority一样,则判断slave节点的offset值,优先选择值大(复制进度最大)的,越大说明数据越新。
- 最后是判断slave节点的运行id大小,优先选择值小的。
通知
- 在选举出从节点为新主节点后后,哨兵向被选中的从节点发送 SLAVEOF no one 命令,让这个从节点解除从节点的身份,将其变为新主节点。
- sentinel给所有其它slave发送slaveof xxxxx 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后只能自动成为新的master的slave节点。
哨兵缺陷
- 哨兵仍然没有解决写操作无法负载均衡、存储能力受到单机限制的问题。