作业:
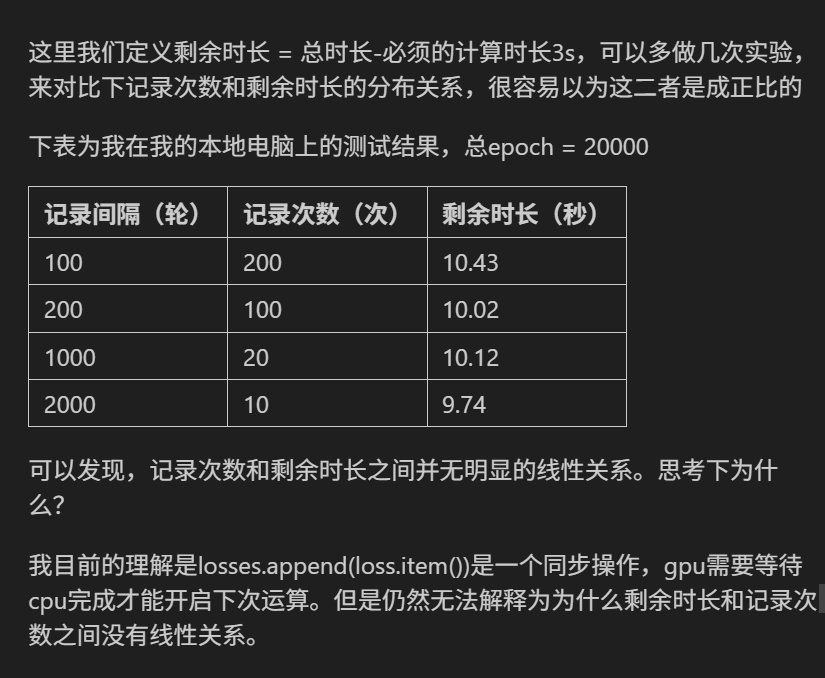
loss.item() 虽然只在 CPU 中执行,但它会触发一次 GPU → CPU 的强制同步,这是影响性能的关键!
loss.item() 做了什么?
- 数据原本在 GPU 上
-
训练时,
loss是一个 GPU 上的张量(比如torch.cuda.FloatTensor)。 -
GPU 可以高效计算,但 不能直接读取数值(就像工厂生产产品,但你要亲自去工厂拿货)。
.item()的本质
-
loss.item()做了 3 件事:-
暂停 GPU 计算:强制 GPU 停下当前所有任务(同步点)。
-
把数据从 GPU 复制到 CPU(通过 PCIe 总线,就像用卡车从工厂运货到商店)。
-
转换成 Python 数字(
float或int),因为 Python 只能处理 CPU 数据。
-
- 为什么这么慢?
-
不是
.item()本身慢,而是 GPU→CPU 的传输和同步慢! -
每次调用
.item(),GPU 都要:-
等所有并行计算完成(比如 1000 个 CUDA 核心都要停)。
-
走 PCIe 总线(带宽有限,延迟高)。
-
等 CPU 确认收到数据后才能继续计算。
-
__call__方法
在 Python 中,call 方法是一个特殊的魔术方法(双下划线方法),它允许类的实例像函数一样被调用。这种特性使得对象可以表现得像函数,同时保留对象的内部状态。
比如:
python
# 不带参数的call方法
class Counter:
def __init__(self):
self.count = 0
def __call__(self):
self.count += 1
return self.count
# 使用示例
counter = Counter()
print(counter()) # 输出: 1
print(counter()) # 输出: 2
print(counter()) # 输出: 3
print(counter.count) # 输出: 3
python
1
2
3
3
python
# 带参数的call方法
class Adder:
def __call__(self, a, b):
print("唱跳篮球rap")
return a + b
adder = Adder()
print(adder(3, 5)) # 输出: 8
python
唱跳篮球rap
8为什么 PyTorch 要用 __call__ 而不是直接暴露 forward?
-
封装性:
__call__可以统一管理forward前后的逻辑(如自动梯度、Hook 机制)。 -
安全性:防止用户直接调用
forward导致梯度丢失或计算图断裂。 -
一致性:让所有模块(
nn.Linear、nn.Conv2d、自定义模型)都能用module(x)的方式调用。