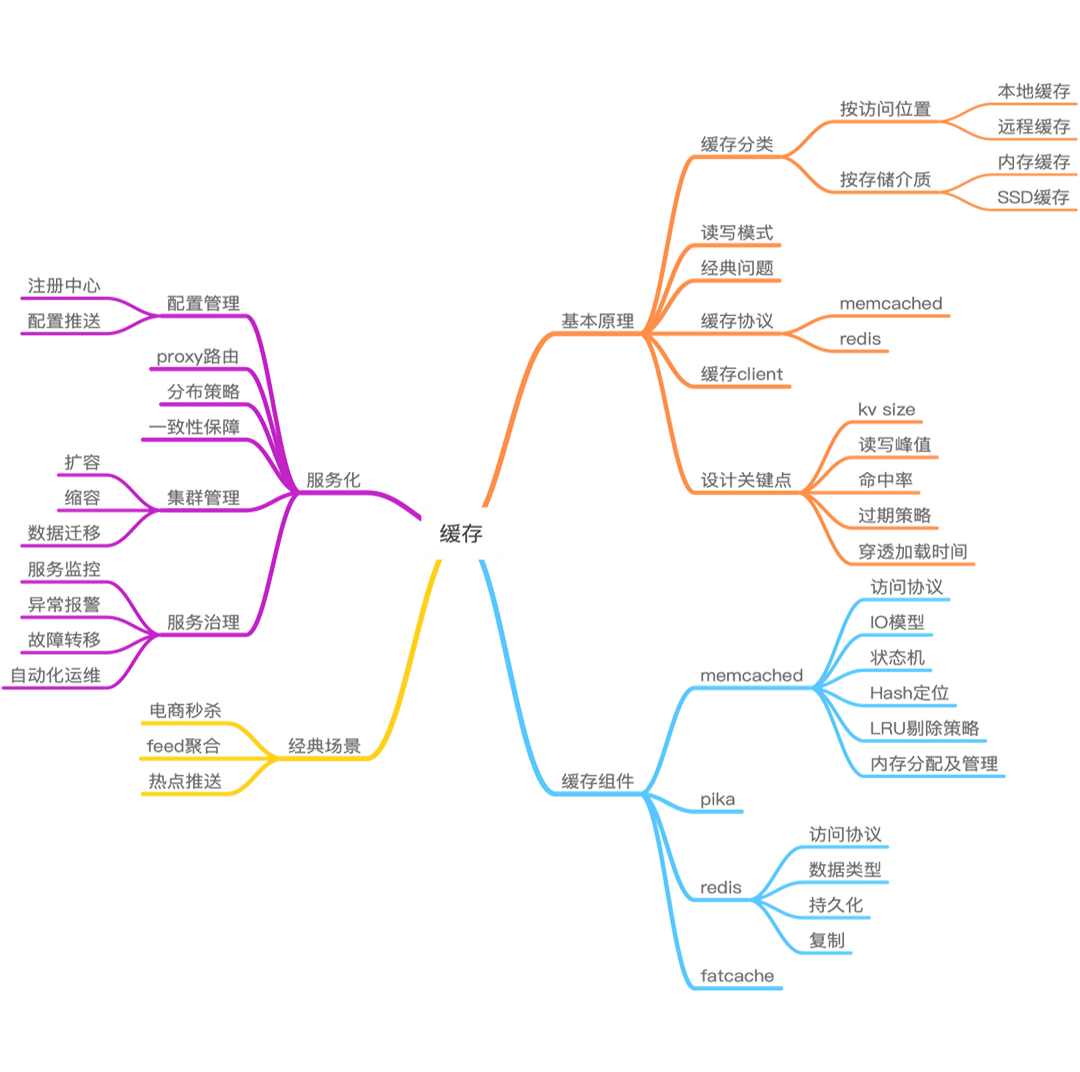
文章目录
- 缓存全景图
- Pre
- [缓存设计中的 7 大经典问题](#缓存设计中的 7 大经典问题)
- 一、缓存失效
-
- [1. 问题描述](#1. 问题描述)
- [2. 原因分析](#2. 原因分析)
- [3. 业务场景](#3. 业务场景)
- [4. 解决方案](#4. 解决方案)
- 二、缓存穿透
-
- [1. 问题描述](#1. 问题描述)
- [2. 原因分析](#2. 原因分析)
- [3. 业务场景](#3. 业务场景)
- [4. 解决方案](#4. 解决方案)
-
- 缓存空结果
- [BloomFilter 过滤](#BloomFilter 过滤)
-
- [BloomFilter 原理简述](#BloomFilter 原理简述)
- 三、缓存雪崩
-
- [1. 问题描述](#1. 问题描述)
- [2. 原因分析](#2. 原因分析)
- [3. 业务场景](#3. 业务场景)
- [4. 解决方案](#4. 解决方案)
- 四、结语

缓存全景图
Pre
实际上,在缓存系统的设计架构中,还有很多坑, 如果设计不当会导致很多严重的后果。设计不当,轻则请求变慢、性能降低,重则会数据不一致、系统可用性降低,甚至会导致缓存雪崩,整个系统无法对外提供服务。
缓存设计中的 7 大经典问题
接下来将对缓存设计中的 7 大经典问题,
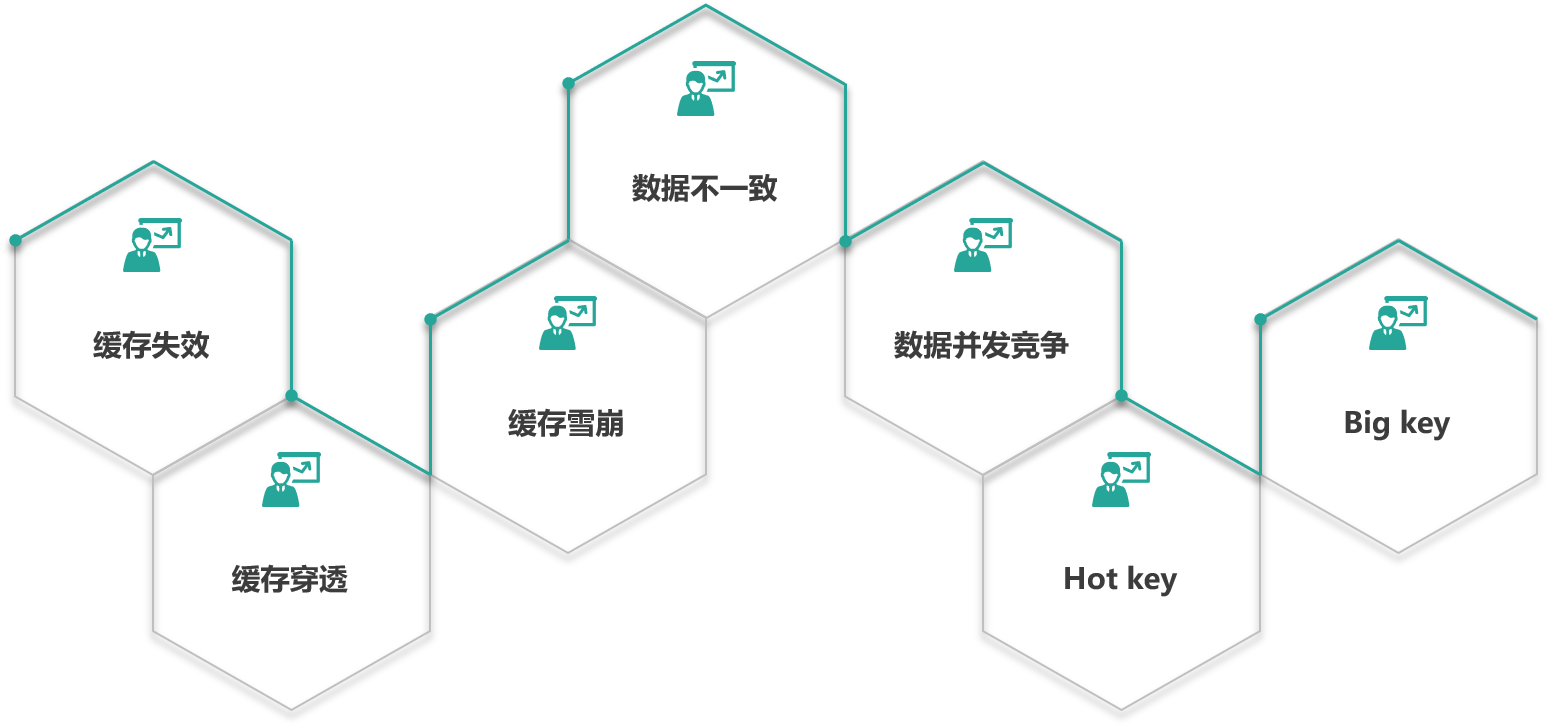
首先我们先梳理一下缓存失效、缓存穿透与缓存雪崩。
- 缓存失效:描述、原因、场景、解决方案
- 缓存穿透:描述、原因、场景、解决方案(含 BloomFilter 原理)
- 缓存雪崩:描述、原因、场景、解决方案
一、缓存失效
1. 问题描述
缓存第一个经典问题是缓存失效。上一课时讲到,服务系统查数据,首先会查缓存,如果缓存数据不存在,就进一步查 DB,最后查到数据后回种到缓存并返回。缓存的性能比 DB 高
50~100倍以上,所以我们希望数据查询尽可能命中缓存,这样系统负荷最小,性能最佳。缓存里的数据存储基本上都是以 key 为索引进行存储和获取的。业务访问时,如果大量的 key 同时过期,很多缓存数据访问都会 miss,进而穿透到 DB,DB 的压力就会明显上升,由于 DB 的性能较差,只在缓存的 1%~2% 以下,这样请求的慢查率会明显上升。这就是缓存失效的问题。
当大量缓存 key 在同一时刻过期,被同时淘汰后,打到 DB 的请求骤增,数据库压力急剧上升,导致请求变慢甚至服务不可用。
2. 原因分析
- 缓存在写入时通常带上固定过期时间。
- 一批数据一次性加载到缓存,且使用相同的过期时间,必然在该时间点集中失效。
3. 业务场景
- 火车票、机票开售时批量预加载缓存。
- 微博后台离线计算完热门 Feed,一次性回写缓存。
- 新业务上线或多IDC部署时的缓存预热。
4. 解决方案
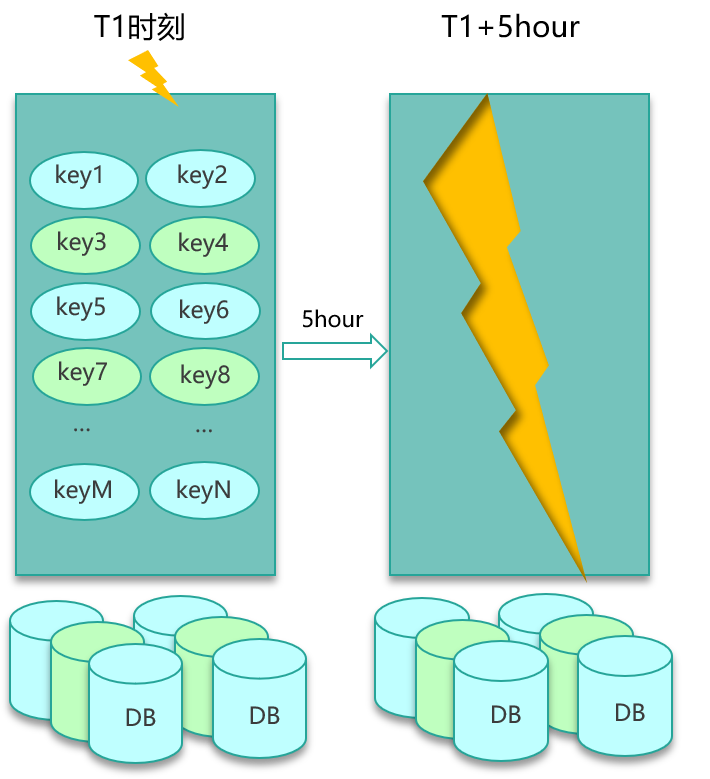
- 过期时间随机化 :
实际过期 = 基础过期 + 随机值,让同类数据分散在一个窗口内逐步过期,避免雪崩式淘汰。
text
基础过期:3600s
随机范围:0--300s
最终过期:3600s + rand(0,300s)二、缓存穿透
1. 问题描述
请求一个不存在的 key,每次都会 Miss 并打到 DB,若恶意或大量无效请求持续触发,DB 压力陡增,影响正常服务。
2. 原因分析
设计时只考虑了正常访问流程(Cache → DB → 回种),未对"查询空"场景做保护:对 DB 查询到的空结果不回写缓存,导致每次都要访问 DB。
3. 业务场景
- 通过不存在的用户 ID、车次 ID 访问系统。
- 恶意或误操作客户端批量请求非法 key。
4. 解决方案
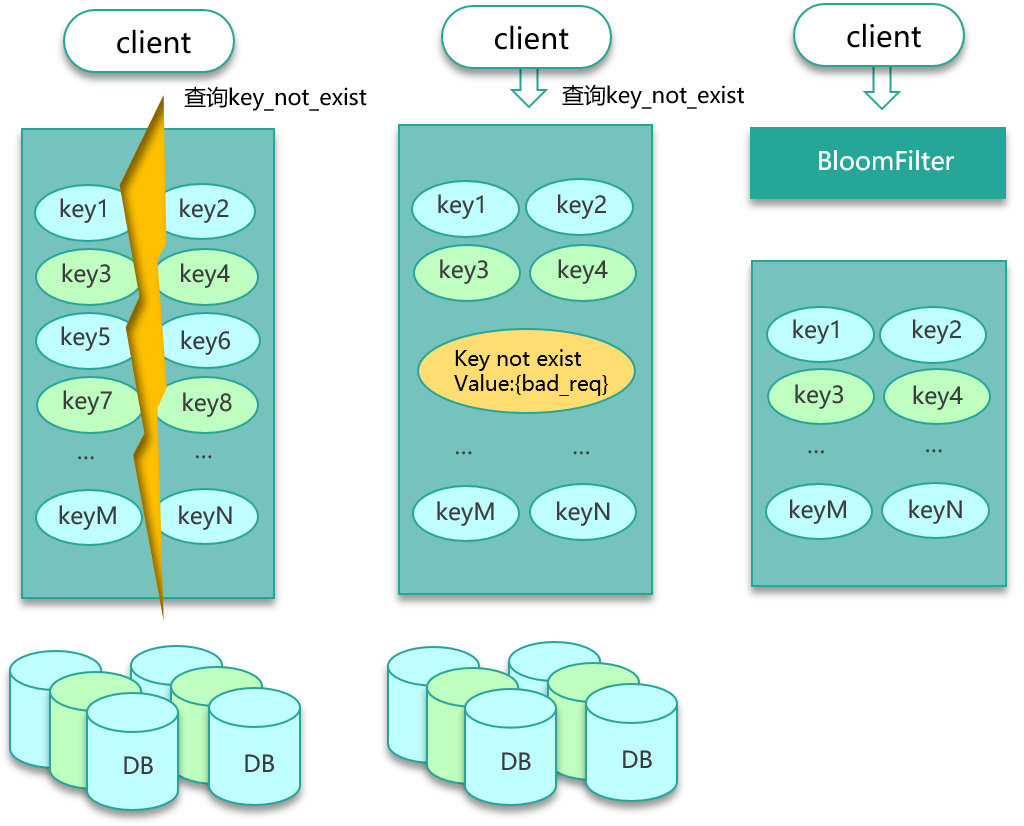
缓存空结果
- 第一次查询 DB 未命中时,回写一个特殊空值到缓存,并设置短过期时间;
- 若后续仍查询该 key,则直接命中空值缓存,避免再次穿透。
BloomFilter 过滤
- 预先用 BloomFilter 记录所有合法 key;
- 查询时先检查 BloomFilter,不存在则直接返回,无需查 Cache/DB。
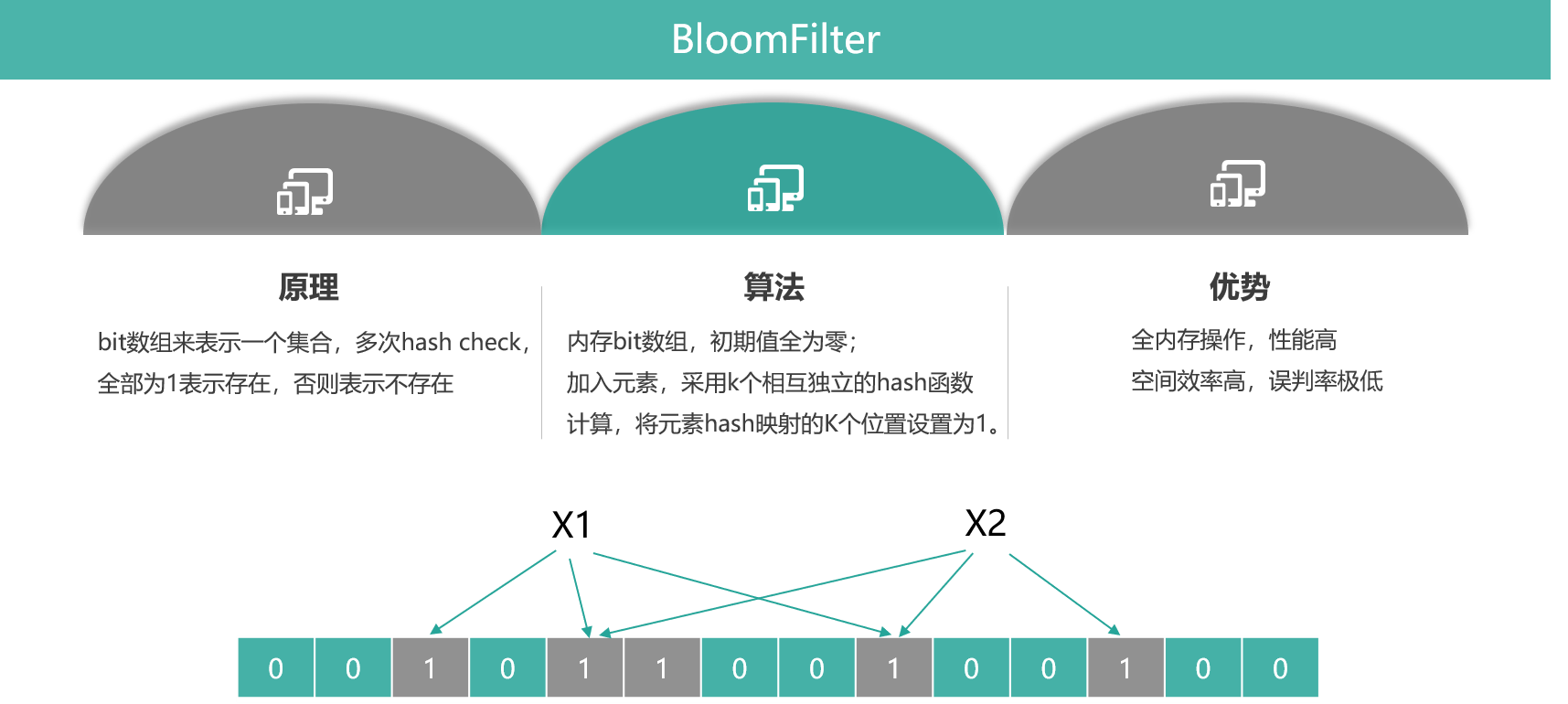
BloomFilter 原理简述
-
数据结构:一个位数组和 k 个独立 Hash 函数。
-
添加元素:对 key 做 k 次 Hash,设置对应 bit 位为 1。
-
检查存在:若 k 个位置都为 1,则"可能存在";任一位置为 0,则"必定不存在"。
-
特性:
- 空否定 100% 准确;
- 存在判断有一定误判率(可通过增加位数组和 Hash 函数数量降至可接受范围,如 1%→0.1%)。
- 空值缓存与 BloomFilter 可结合使用,兼顾空间与准确率。
三、缓存雪崩
1. 问题描述
部分或大量缓存节点不可用,导致请求集中打到 DB 或重分布时过载,最终引发系统不可用。
- 不支持 Rehash:节点故障后,客户端访问失败→穿透到 DB,DB 过载。
- 支持 Rehash:节点故障后,流量重分发到健康节点,瞬间过载 → 多节点连锁宕机。
2. 原因分析
- 单点或少量节点故障:未做好副本或限流保护。
- 流量洪峰:热点 key 在少数节点集中,导致节点崩溃并连锁扩散。
3. 业务场景
- 部分节点宕机并波及全池。
- 机架断电引发大量节点脱机,瞬间请求涌向 DB。
4. 解决方案
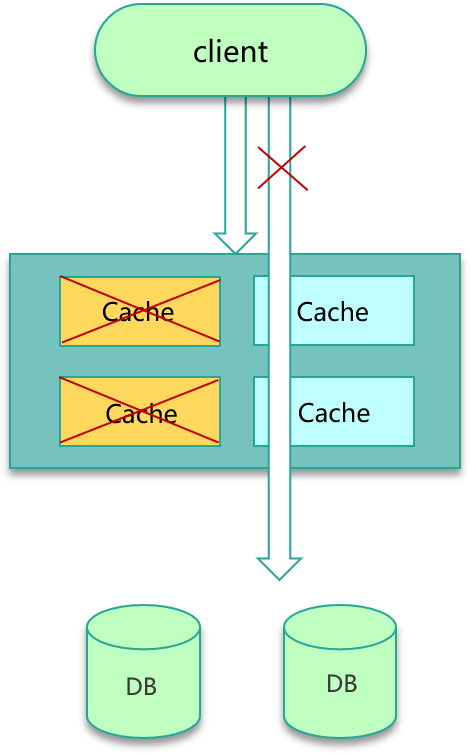
-
DB 读写降级开关
- 监控到 DB 慢查询率或阻塞率过高时,Failfast 部分/全部读请求,保护 DB 可用;
- 写请求保证优先处理,读请求可根据业务容忍度返回旧值或降级信息。
-
多副本部署
- 同一数据在多副本(机架隔离)上缓存,任一副本失效可从其他副本读取;
- 副本数根据热点程度,热点可配 6--10+ 副本,冷数据可少量双副本。
-
实时监控与自动故障转移
- 缓存节点健康、命中率、慢请求比等指标告警;
- 自动剔除异常节点、启动备用节点、限流降级,确保核心请求稳定处理。
四、结语
缓存系统的 稳定与高效 离不开对这些经典问题的深入理解与预防设计。
- 失效雪崩:随机化过期、分散淘汰
- 穿透攻防:空值回写、BloomFilter 过滤
- 雪崩防护:限流降级、多副本、监控与自动化运维
