一、消息队列与 Kafka 基础概念解析
一、消息队列(MQ)基础概念
-
定义 :
消息队列(Message Queue,简称 MQ)本质是一个 FIFO(先入先出)的队列,存储单元为 "消息",主要用于不同服务、进程、线程间的通信。
-
核心价值 :
解决分布式系统中服务间通信的异步处理、流量控制、解耦等问题,提升系统弹性与性能。
二、消息队列的五大核心使用场景
-
异步处理
- 场景:短信通知、用户注册、App 推送等非实时性业务。
- 优势:同步处理时各环节需依次等待(如订单流程需 50ms×4 环节),异步引入 MQ 后,核心流程可快速返回(50ms),非核心任务(如短信、统计)通过 MQ 异步处理,提升系统吞吐量。
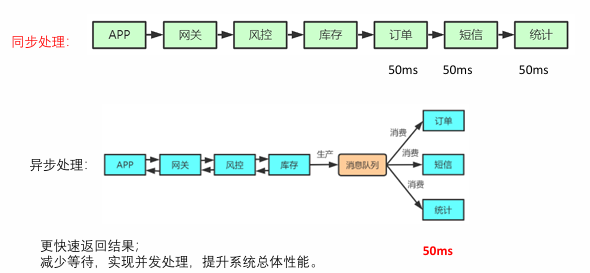
-
流量控制(削峰)
- 场景:秒杀、大促等高并发场景下的下单请求。
- 实现:通过 MQ 隔离网关与后端服务,设置队列最大容量,避免瞬时流量压垮服务(如 APP 请求→网关→MQ→秒杀服务)。
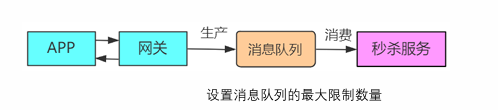
-
服务解耦
- 场景:系统间数据分发(如 A 系统产生数据,B/C/D 系统订阅消费)。
- 优势:新增系统(如 E 系统)无需修改原系统代码,直接从 MQ 消费数据,减少系统间耦合度。
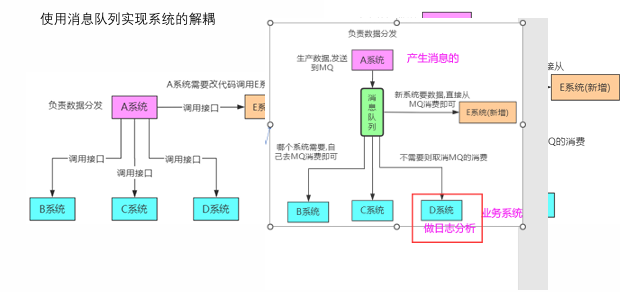
-
发布订阅
- 场景:游戏跨服广播(如剩余道具数量、玩家装备掉落通知)。
- 特点:消息发布到主题(Topic),多个订阅者可同时接收,发布者与订阅者解耦。
-
高并发缓冲
- 场景:Kafka 日志服务、监控数据上报。
- 作用:缓存高并发数据,避免后端服务直接处理海量请求导致崩溃。

三、消息队列核心概念与原理
-
Broker 与集群
- Broker 是 MQ 的服务器节点(如 Apache ActiveMQ 中的概念),可集群部署以提升可用性与性能。
-
生产者(Producer)与消费者(Consumer)
- Producer:发送消息到 MQ;Consumer:从 MQ 接收消息(支持被动推送(Push)或主动拉取(Pull)模式)。
-
消息模型
- 点对点(Queue):一条消息仅能被一个消费者接收(如线程池任务分配)。
- 发布订阅(Topic):消息发布到 Topic,多个订阅者可同时消费(如上课通知广播)。
-
关键机制
- 顺序性:基于 Queue 的 FIFO 特性保证消息顺序。
- ACK 确认机制:消费者处理消息后发送 ACK,MQ 才删除消息;若消费者宕机未发送 ACK,MQ 会重新投递消息,确保不丢失(代价:牺牲部分吞吐量)。
- 持久化:关键业务消息落地存储,MQ 宕机重启后可恢复,避免数据丢失。
- 同步与异步收发 :
- 同步:生产者发送消息后等待 MQ 确认(如 TCP 批量应答,超时重发);消费者拉取消息时若队列为空则阻塞。
- 异步:生产者发送消息后无需等待确认;消费者通过 Push 模式被动接收消息。
四、主流消息队列产品对比
| 特性 | RabbitMQ | RocketMQ | Kafka | ZeroMQ |
|---|---|---|---|---|
| 单机吞吐量 | 万级(低于 RocketMQ/Kafka) | 10 万级(高吞吐) | 10 万级(适合大数据场景) | 100 万级(股票交易系统) |
| Topic 数量影响 | - | 支持数百 / 数千 Topic,吞吐量下降小 | Topic 过多需增加机器资源 | - |
| 时效性 | 微秒级(延迟最低) | 毫秒级 | 毫秒级以内 | 微秒 / 毫秒级 |
| 可用性 | 高(主从架构) | 非常高(分布式架构) | 非常高(多副本容错) | 非独立服务,需嵌入程序 |
| 消息可靠性 | 基本不丢 | 可配置为 0 丢失 | 同 RocketMQ | - |
| 功能支持 | Erlang 开发,并发性能强 | 功能完善,支持分布式部署 | 简单 MQ 功能, |
二、Kafka 核心原理与实践深度解析
1. Kafka 解决的核心问题
Kafka 作为分布式消息队列,本质上是一个 MQ,其核心价值在于:
- 系统解耦:允许生产者与消费者独立扩展,如电商系统中订单服务与库存、短信服务解耦。
- 可恢复性:消息持久化存储,即使消费者宕机,恢复后仍可处理队列中的消息。
- 流量缓冲:平衡生产与消费速率差异,如日志收集场景中应对突发流量。
- 峰值处理能力:通过队列缓冲避免高并发请求压垮核心服务(如秒杀场景)。
- 异步通信:非实时任务(如用户注册后的积分发放)通过 MQ 异步处理,提升主流程响应速度。
2. Kafka 架构与核心术语
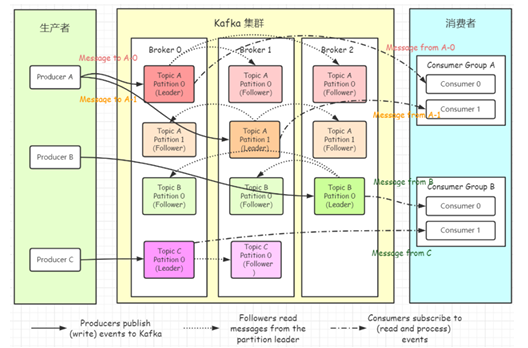
1. 组件与数据流向
生产者(Producers):
- 左侧绿色区域,包含
Producer A/B/C,通过 实线箭头 向 Kafka 集群的 Leader 分区 写入消息(如Producer A向Topic A-Partition 0 (Leader, Broker 0)发送数据)。- 分区策略 :图中
Producer A固定写入Topic A-Partition 0(可能为按 Key 哈希或指定分区),Producer B写入Topic B-Partition 0 (Leader, Broker 2),Producer C写入Topic C-Partition 0 (Leader, Broker 0),体现不同 Topic 的 Leader 分布。Kafka 集群(Broker 0/1/2):
- Broker 角色 :每个 Broker 存储多个 Topic 的 Partition 副本(Leader/Follower)。
- Leader 分区 :红色(
Topic A-P0)、橙色(Topic A-P1)、绿色(Topic B-P0)、紫色(Topic C-P0),负责处理读写请求。- Follower 分区 :粉色(
Topic A-P0副本)、橙色(Topic A-P1副本)、绿色(Topic B-P0副本)、紫色(Topic C-P0副本),从 Leader 同步数据(虚线箭头),不对外服务,仅作冗余备份。- 副本分布 :每个 Partition 的副本分散在不同 Broker(如
Topic A-P0副本在 Broker 0/1/2,Topic A-P1副本在 Broker 0/1/2),实现 数据冗余 和 故障容错(某 Broker 宕机时,Follower 可选举为新 Leader)。消费者(Consumers):
- 右侧蓝色区域,包含
Consumer Group A/B,通过 点划线箭头 从 Leader 分区 拉取消息(如Consumer Group A消费Topic A-P0/P1,Consumer Group B消费Topic B-P0)。- 消费组负载均衡 :
Consumer Group A的Consumer 0/1分别消费Topic A-P0和Topic A-P1(每个 Partition 仅被组内一个消费者消费),体现 Range/RoundRobin 分配策略,避免重复消费。2. 核心架构原理
Topic-Partition 模型:
- 逻辑 - 物理映射:Topic 是逻辑分类(如用户行为日志),Partition 是物理分片(每个对应独立日志文件,存储消息序列及 Offset)。
- 并行性提升 :多个 Partition 允许生产者并行写入、消费者并行读取(如
Topic A含 2 个 Partition,支持更高吞吐量)。Leader-Follower 副本机制:
- 角色分工:Leader 处理读写,Follower 同步数据(依赖 ZooKeeper 监控 Leader 状态,宕机时触发选举,确保高可用)。
- ISR(同步副本集合) :图中未显式标注,但 Leader 仅与 ISR 内的 Follower 同步(如
Topic A-P0的 ISR 含 Broker 0/1/2,若某 Follower 超时未同步,会被踢出 ISR,不参与选举)。消费组与 Offset 管理:
- Offset 持久化 :消费者记录消费到的 Offset(存储于
__consumer_offsets主题或外部存储),故障恢复时从上次位置继续消费(避免数据丢失 / 重复)。- 多消费组订阅 :
Topic A可被Consumer Group A和其他组(图中未显示)同时消费,实现 发布 - 订阅 模式(如订单 Topic 被支付、物流系统分别消费)。3. 架构优势与场景
- 高可用性 :多副本 + Leader 选举,容忍 Broker 宕机(如 Broker 0 故障,
Topic A-P0的 Follower(Broker 1/2)选举新 Leader,服务不中断)。- 高吞吐量:分区并行写入 / 读取,结合顺序 IO 优化(日志文件追加写入),支持十万级每秒消息处理(适合日志采集、实时计算场景)。
- 解耦与扩展性:生产者 / 消费者与 Broker 集群解耦,新增节点(Broker / 消费者)时自动触发 Rebalance(分区重分配),无需修改业务逻辑。
2.1 架构组件
- Producer(生产者):发送消息到 Kafka 集群,始终与分区 Leader 交互。
- Consumer(消费者):从集群拉取消息,通过 Consumer Group 管理消费组内负载均衡。
- Broker:Kafka 服务器节点,集群由多个 Broker 组成,存储 Topic 的分区数据。
- Topic(主题):逻辑上的消息分类,如 "user-registration""order-updates"。
- Partition(分区):Topic 的物理分片,一个 Topic 可分为多个分区,分布在不同 Broker 上,提升并发能力。
- Replication(副本):每个分区有多个副本(Leader 和 Follower),Leader 负责读写,Follower 同步数据,保障高可用。
- ZooKeeper:管理 Kafka 集群元数据(如 Broker 状态、Leader 选举),新版本 Kafka 已逐步弃用 ZooKeeper,改用自研控制器。
2.2 核心架构原理
- 逻辑 - 物理映射 :
Topic 是逻辑分类,Partition 是物理分片(如 Topic 含 3 个 Partition,分布在不同 Broker,提升并发)。 - 副本机制 :
- Leader 处理所有读写请求,Follower 仅同步数据,不对外服务。
- ISR(In-Sync Replica Set):与 Leader 同步的 Follower 集合,Leader 故障时从 ISR 中选举新 Leader。
- Offset 机制 :
消费者记录消费到的 Offset(存储于__consumer_offsets或外部存储),故障恢复时续消费。
2.3 工作流程与分区机制
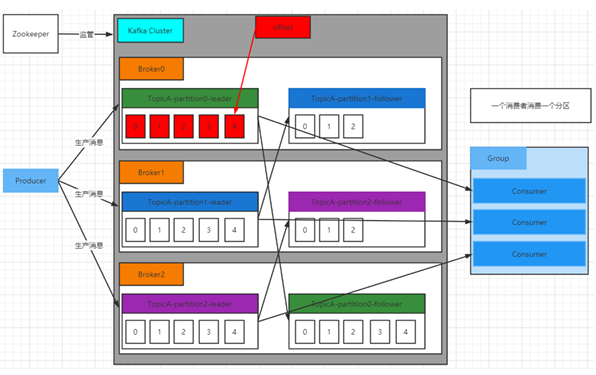
1. 核心组件与角色
Zookeeper(左侧) :
早期 Kafka 依赖 ZooKeeper 管理集群元数据(如 Broker 状态、Leader 选举、分区元数据),实现集群监控与协调(新版本逐步被 KRaft 替代,但图中仍体现其历史角色)。
Producer(左侧蓝色框) :
生产者发送消息到 Kafka 集群,始终与分区的 Leader 副本交互(图中箭头指向各 Topic 分区的 Leader,如 TopicA-partition0 的 Leader 在 Broker0),遵循 "写操作仅由 Leader 处理" 的设计。
Kafka Cluster(中间灰色框,含 Broker0/1/2):
- Broker(橙色框):Kafka 服务器节点,每个 Broker代表一台主机,存储多个 Topic 的分区副本(Leader/Follower)。
- Topic 与 Partition :
- Leader 副本(绿色、蓝色、紫色框,带红色消息块):处理读写请求,每个分区有且仅有一个 Leader(如 TopicA-partition0 的 Leader 在 Broker0,TopicB-partition0 的 Leader 在 Broker1,TopicC-partition2 的 Leader 在 Broker2)。
- Follower 副本(浅蓝色、紫色、绿色框,无红色消息块):从 Leader 异步同步数据(虚线箭头表示同步),不对外服务,仅作冗余备份(如 TopicA-partition1 的 Follower 在 Broker0,TopicA-partition0 的 Follower 在 Broker2)。
- Offset 与消息存储:每个分区的 Leader/Follower 日志文件按 Offset 顺序存储消息(如 TopicA-partition0 的 Leader 存储 Offset 0-4,Follower 同步相同 Offset 范围)。
Consumer Group(右侧蓝色框):
- Consumer(蓝色子框) :组内消费者通过 Pull 模式 从 Leader 分区拉取消息,每个分区仅被组内一个消费者消费(图中注释 "一个消费者消费一个分区",体现分区分配策略,避免重复消费)。
2. 数据流向与交互逻辑
生产端(Producer → Leader) :
生产者按分区策略(如轮询、Key 哈希)将消息发送到目标分区的 Leader(如 TopicA-partition0 的 Leader 在 Broker0,TopicB-partition0 的 Leader 在 Broker1),Leader 写入本地日志并异步同步到 Follower(更新 ISR 集合)。
消费端(Leader → Consumer) :
消费者组内的每个消费者分配到一个或多个分区(图中每个消费者对应一个分区,如 TopicA 的两个分区由组内两个消费者分别消费),从 Leader 拉取消息并记录消费 Offset(存储于
__consumer_offsets或外部存储)。副本同步(Leader → Follower) :
Follower 定期从 Leader 拉取数据(基于
fetch请求),更新本地日志,确保与 Leader 数据一致。若 Follower 超时未同步(超过replica.lag.time.max.ms),会被踢出 ISR,不参与 Leader 选举。3. 架构设计亮点
高可用性(副本机制) :
每个分区的副本分布在不同 Broker(如 TopicA-partition0 的 Leader 在 Broker0,Follower 在 Broker2;TopicA-partition1 的 Leader 在 Broker1,Follower 在 Broker0),实现 数据冗余。当 Leader 宕机(如 Broker0 故障),ISR 内的 Follower(如 Broker2 的 TopicA-partition0 Follower)会选举为新 Leader,保证服务不中断。
并行性与扩展性(分区机制):
- 水平扩展:新增 Broker 时,分区副本自动重分配(图中 Broker0/1/2 均承载不同 Topic 的 Leader/Follower,体现负载均衡)。
- 吞吐量提升:多个分区允许生产者并行写入、消费者并行读取(如 TopicA 含 2 个分区,支持更高并发)。
消费模型(Consumer Group):
- 单播与广播支持 :同一 Topic 可被多个消费组订阅(图中未显示多组,实际支持),实现 发布 - 订阅 模式;组内消费者共享 Offset,实现 点对点 队列模型(如秒杀订单 Topic 被支付系统单组消费)。
4. 与 Redis 架构的对比(图中隐含逻辑)
- Redis 主从:从节点可处理读请求(分担主节点压力),写仅主节点处理。
- Kafka 副本:Follower 不处理读请求(读全由 Leader 处理),仅作备份(图中 Follower 无客户端连接,仅同步数据),与 Redis 从节点的 "读分担" 功能完全不同。
5. 实际场景映射
- 日志采集 :Producer 发送应用日志到 Topic,多个消费组(如 ELK 组、监控组)分别消费,实现 多对多解耦。
- 实时计算:Flink 消费者组从 Kafka 拉取数据,按分区并行处理(图中每个消费者对应一个分区,模拟并行计算单元)。
- 分区的独立性 :
不同 Partition 的 Offset 独立,同一 Topic 的消息按分区存储,每个分区是有序的日志流。 - 分区的作用 :
- 水平扩展:分区可分布在不同 Broker,支持吞吐量线性增长(如添加 Broker 时自动重分配分区)。
- 负载均衡:Producer 按策略将消息写入分区,Consumer Group 按策略分配分区消费。
- 分区策略(Producer 端) :
- 轮询(Round-Robin):顺序分配分区,保证消息均匀分布(默认策略)。
- 按 Key 哈希:相同 Key 的消息进入同一分区,保证有序性(如用户 ID 对应分区)。
- 指定分区:Producer 显式指定 Partition,直接写入目标分区。
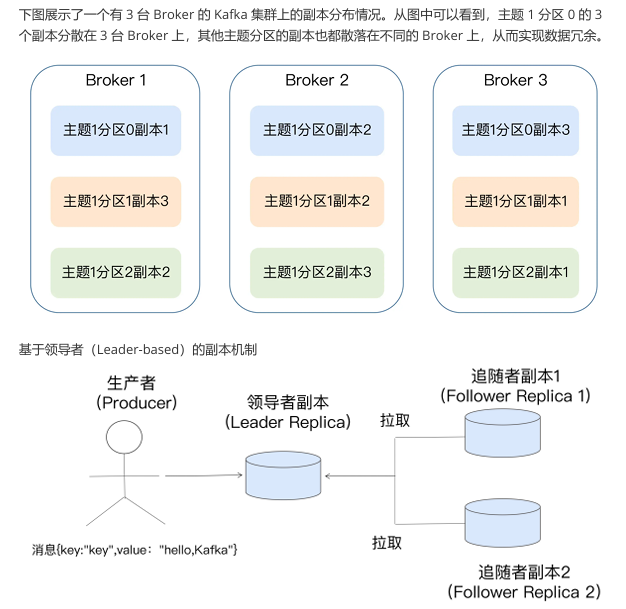
2.4 副本原理与高可用性
- 副本的核心价值 :
- 数据冗余:多副本分布在不同 Broker,单节点宕机时数据不丢失。
- 高可用性:Leader 故障时,ISR 内的 Follower 选举新 Leader,服务不中断。
- Leader-Follower 模型 :
- Follower 不处理读写请求,仅异步复制 Leader 数据,避免数据不一致。
- 若 Follower 长时间未同步(超过
replica.lag.time.max.ms),会被踢出 ISR,不参与选举。
- 与其他系统的区别 :
不同于 Redis 从节点可读,Kafka Follower 仅作备份,不分担读压力(读请求全部由 Leader 处理)。
2.5 分区和主题的关系
一个分区只能属于一个主题
一个主题可以有多个分区
同一主题的不同分区内容不一样,每个分区有自己独立的offset
同一主题不同的分区能够被放置到不同节点的broker
分区规则设置得当可以使得同一主题的消息均匀落在不同的分区
2.6 生产者
producer就是生产者,是数据的入口。Producer在写入数据的时候永远的找leader,不会直接将数据 写入follower。
2.6.1 为什么分区-可以水平扩展
Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某一个分区 中,而不会在多个分区中被保存多份。如下所示:
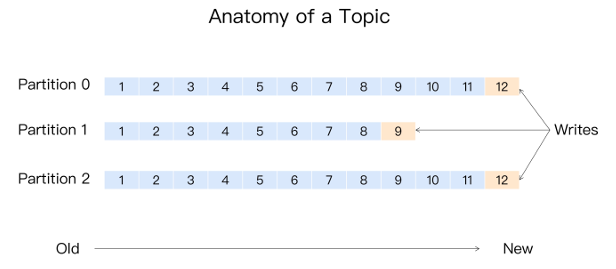
分区的作用主要提供负载均衡的能力,能够实现系统的高伸缩性(Scalability)。不同的分区能够被放置 到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能 独立地执行各自分区的读写请求处理。这样,当性能不足的时候可以通过添加新的节点机器来增加整体 系统的吞吐量。
分区原则:我们需要将 Producer 发送的数据封装成一个 ProducerRecord对象。
该对象需要指定一些参数:
topic:string 类型,NotNull。
partition:int 类型,可选。 timestamp:long 类型,可选。
key:string 类型,可选。
value:string 类型,可选。
headers:array 类型,Nullable
2.6.2 分区策略
1. 分区策略的核心作用
Kafka 的分区策略决定生产者(Producer)将消息发送到哪个分区(Partition),直接影响消息分布、消费并行性和系统吞吐量。以下是四种策略的详细说明:
2. 轮询策略(Round-robin)
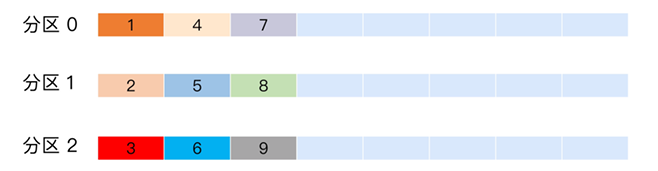
- 原理 :
按顺序循环分配消息到每个分区。例如,3 个分区(0、1、2)时,消息依次分配为:1→0,2→1,3→2,4→0,5→1,...(图中分区 0 含1、4、7,分区 1 含2、5、8,分区 2 含3、6、9,体现均匀分布)。 - 优势 :
- 负载均衡 :确保消息均匀分布,无数据倾斜,是 默认策略。
- 高吞吐:适合无 Key 或 Key 无顺序要求的场景(如日志采集、监控数据)。
- 示例 :
系统日志(每条消息独立,无需按用户 / 业务分组),轮询策略保证各分区负载均衡,提升整体写入吞吐量。
3. 随机策略(Randomness)
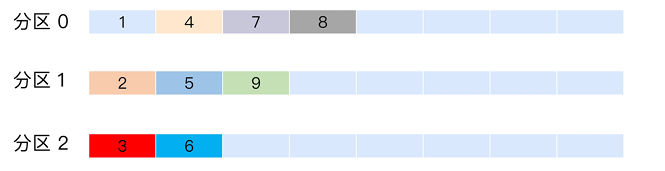
- 原理 :
早期版本策略,随机选择分区(图中分区 0 含1、4、7、8,分布不均),现已被轮询策略取代。 - 缺点 :
无法保证负载均衡,新版本不再推荐使用,仅作历史对比。
4. 按消息键保序策略(Key-ordering)
- 原理 :
对消息 Key 哈希后取模(partition = hash(key) % numPartitions),相同 Key 的消息固定到同一分区(如key1始终在分区 0,key2始终在分区 1),保证 分区内消息顺序性(Offset 递增)。 - 业务价值 :
- 顺序性保证:同 Key 消息(如用户订单、会话日志)在同一分区,消费时自然有序(如电商订单需按创建顺序处理)。
- 数据关联:通过 Key 分组,实现业务逻辑(如按用户 ID 聚合操作日志)。
- 注意事项 :
若 Key 分布不均(如少数用户产生大量消息),会导致 分区倾斜(某分区消息过多),需优化 Key 设计(如哈希加盐、分桶)。
5. 默认分区规则(综合策略)
- 优先级规则 :
- 指定 Partition :显式指定分区(如
producer.send(new ProducerRecord(topic, 1, key, value)),直接写入分区 1)。 - 有 Key 无指定:Key 哈希取模(同 Key-ordering 策略)。
- 无 Key 无指定:轮询策略(首次随机起始,后续递增取模,保证均匀分布)。
- 指定 Partition :显式指定分区(如
- 代码实现 :
Kafka 客户端通过DefaultPartitioner类实现,用户可自定义Partitioner接口(如按时间戳、地域等规则分配分区)。
2.7 消费者
1. 传统消息模型的缺陷与 Kafka 解决方案
- 点对点模型(如 ZeroMQ) :
消息消费后删除,仅单消费者处理,伸缩性差(多消费者竞争,负载不均)。- 发布 - 订阅模型 :
多消费者订阅,但需全量接收主题分区(不灵活,如只需部分分区时仍需处理全量)。- Kafka 消费者组(Consumer Group) :
- 组内分工:每个消费者处理部分分区(非全量),组间独立(可共享主题,互不干扰)。
- 双模型支持 :
- 单组多消费者:实现点对点(如秒杀订单,组内消费者瓜分分区,避免重复消费)。
- 多组多消费者:实现发布 - 订阅(如日志主题被监控、分析组同时消费)。
2. 消费方式(Pull 模式)
- 原理 :消费者主动拉取消息,通过
timeout(如fetch.max.wait.ms)控制长轮询(无数据时等待,避免空循环)。- 优势 :
- 按消费能力调节速率(高性能消费者拉取快,低性能拉取慢)。
- 避免 Push 模式的 "消费者过载"(Broker 不强制推送,消费者自主控制)。
3. 分区分配策略(核心机制)
Kafka 通过
partition.assignment.strategy配置四种策略,解决 "分区如何分配给消费者":3.1 RangeAssignor(范围分配)
- 原理 :
- 按主题(Topic)独立处理,消费者字典序排序,分区按
分区数/消费者数整除分配,余数前的消费者多分配 1 个。- 公式:
n = 分区数 ÷ 消费者数,m = 分区数 % 消费者数,前m个消费者分n+1个,后消费者数-m个分n个。- 示例 :
- 均匀场景 :2 消费者,2 主题各 4 分区(共 8 分区),每人分 4 个(
8÷2=4,无余数,均分)。- 倾斜场景 :2 消费者,2 主题各 3 分区(共 6 分区,
6%2=1),前 1 消费者分 3 个(3+1?错误,实际应为6÷2=3,均分。原例描述有误,正确逻辑为:若 3 分区 2 消费者,3%2=1,前 1 个分 2 个,后 1 个分 1 个,导致倾斜)。
- 缺陷:多主题时易倾斜(每个主题独立计算,消费者在不同主题中累积多分配,导致负载不均)。
3.2 RoundRobinAssignor(轮询分配)
- 原理 :
- 全局排序所有主题的分区和消费者(字典序),轮询分配每个分区给消费者。
- 优势 :
- 跨主题均匀分配(如消费者订阅相同主题时,分区分布更均衡,见示例中 2 消费者分 3 分区 ×2 主题,每人分 3 个)。
- 缺陷 :
- 消费者订阅主题不同时,分配不均(如 C0 只订阅 t0,C1 订阅 t0/t1,C0 仅能分到 t0 分区,负载倾斜)。
- 适用场景:消费者订阅完全相同的主题集合(如所有消费者都订阅 t0、t1、t2)。
3.3 StickyAssignor(黏性分配,0.11+ 引入)
- 核心目标 :
- 均衡性:分区尽量均匀分配。
- 黏性:重平衡时尽量保留上次分配(减少分区移动,降低消费者状态重置开销,如事务处理、缓存预热)。
- 示例 :
- 初始分配:3 消费者分 8 分区(4 主题 ×2 分区),每人分 2-3 个,尽量均匀。
- 重平衡(C1 宕机):RoundRobin 重新轮询(分区全部分配给剩余 2 消费者,每人 4 个),而 Sticky 保留 C0/C2 原有分区,仅分配 C1 的分区(每人多 2 个,仍均衡,且减少状态重置)。
- 优势 :
- 减少重平衡时的分区移动(如消费者短暂宕机后,快速恢复原有分区,避免重复处理)。
- 订阅不同主题时更优(如 C0 只订阅 t0,Sticky 确保其仅处理 t0 分区,避免跨主题分配错误)。
- 实现:代码复杂,需维护分区分配的黏性状态,优先保证均衡性。
3.4 CooperativeStickyAssignor(协作黏性,增量重平衡)
- 原理 :
基于 Sticky 策略,支持 增量重平衡(消费者无需停止消费,逐步调整分区分配),减少重平衡对业务的影响。- 缺陷:短期可能不均衡(但长期仍保证黏性和均衡)。
4. 策略对比与选择
策略 优势 缺陷 适用场景 RangeAssignor 主题内局部均衡 多主题易倾斜 单主题或主题数少的场景 RoundRobinAssignor 跨主题全局均衡(同订阅) 订阅不同主题时倾斜 消费者订阅完全相同主题 StickyAssignor 黏性 + 均衡,减少重平衡开销 实现复杂 需重平衡优化(如长事务消费) CooperativeSticky 增量重平衡,不中断消费 短期可能不均衡 高可用场景(消费者频繁上下线) 5. 重平衡(Rebalance)触发条件
- 消费者加入 / 离开、主题分区数变化、订阅主题变化。
- 影响:重平衡期间消费暂停,分区重新分配(Sticky/CooperativeSticky 可减少影响)。
6. 实践建议
- 默认策略 :使用
Range + CooperativeSticky(Kafka 2.4+ 默认),兼顾均衡性和重平衡优化。- 订阅一致性:组内消费者尽量订阅相同主题(避免 RoundRobin 倾斜)。
- 性能优化 :
- 减少重平衡频率(固定消费者数量,避免动态上下线)。
- 启用 Sticky 策略(降低重平衡时的分区移动,提升消费连续性)。


2.8 数据可靠性保证
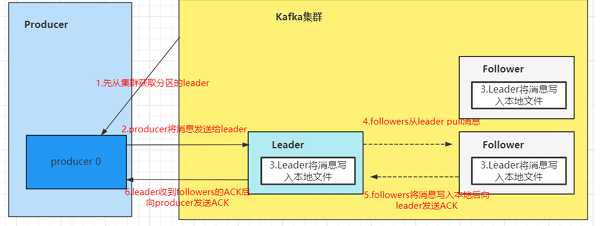
为保证 Producer 发送的数据,能可靠地发送到指定的 topic,topic 的每个 Partition 收到 Producer 发 送的数据后,都需要向 Producer 发送 ACK(ACKnowledge 确认收到)。 如果 Producer 收到 ACK,就会进行下一轮的发送,否则重新发送数据。
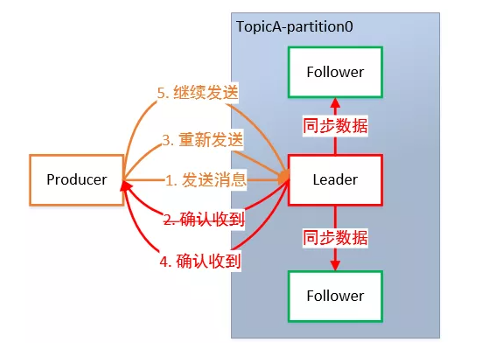
2.8.1 副本数据同步策略
何时发送 ACK?确保有 Follower 与 Leader 同步完成,Leader 再发送 ACK,这样才能保证 Leader 挂 掉之后,能在 Follower 中选举出新的 Leader 而不丢数据。
多少个 Follower 同步完成后发送 ACK?全部 Follower 同步完成,再发送 ACK。

当采用第二种方案时,所有 Follower 完成同步,Producer 才能继续发送数据,设想有一个 Follower 因 为某种原因出现故障,那 Leader 就要一直等到它完成同步。这个问题怎么解决?
-
Leader维护了一个动态的** in-sync replica set(ISR)**:和 Leader 保持同步的 Follower 集 合。
-
当 ISR 集合中的 Follower 完成数据的同步之后,Leader 就会给 Follower 发送 ACK。
-
如果 Follower 长时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由 replica.lag.t1me.max.ms 参数设定。Leader 发生故障后,就会从 ISR 中选举出新的 Leader。
2.8.2 ACK应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 Follower 全部接受成功。 所以 Kafka 为用户提供了三种可靠性级别,用户根据可靠性和延迟的要求进行权衡,选择以下的配置。
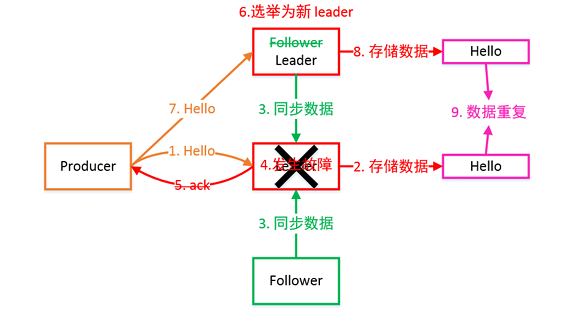
ACK 参数配置
- 0:Producer 不等待 Broker 的 ACK,这提供了最低延迟,Broker 一收到数据还没有写入磁盘就已经返回,当 Broker 故障时有可能丢失数据。
- 1:Producer 等待 Broker 的 ACK,Partition 的 Leader 落盘成功后返回 ACK,如果在 Follower 同步成功之前 Leader 故障,那么将会丢失数据。
- -1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
2.8.3 可靠性指标
没有一个中间件能够做到百分之百的完全可靠,可靠性更多的还是基于几个 9 的衡量指标(如 4 个 9、5 个 9)。软件系统的可靠性只能够无限接近 100%,但无法达到。Kafka 实现高可靠性的方式如下:
-
分区副本:
- 可通过增加副本数提升可靠性(如 3 副本满足多数场景,容忍 1 节点故障),但过多副本会增加性能开销(同步延迟、存储成本)。
-
ACK 机制(生产者端):
- 配置
acks确保消息在 Broker 多副本持久化(如acks=-1要求 ISR 内所有副本落盘,最大化数据冗余)。
- 配置
-
消费者端保证:
- 自动提交 Offset(默认
true) :批量提交(如auto.commit.interval.ms),存在 重复消费 (提交后消费失败,宕机后重消费)或 Offset 丢失(消费前提交,宕机后跳过未消费消息)风险。 - 手动提交 Offset(
false) :消费成功后调用commitSync()/commitAsync(),保证 至少一次消费(允许重复,避免丢失),适用于高可靠场景(如金融交易,需幂等处理重复消息)。
- 自动提交 Offset(默认
三、 Kafka开发环境的搭建
一、Java 环境安装
1.1 下载 Linux 安装包
- 访问 Oracle 官网下载 JDK 8:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads2133151.html
选择对应 Linux 版本(如jdk-8u202-linux-x64.tar.gz)。 - 下载后默认存储在
~/Downloads或~/下载目录,可通过cd ~/Downloads进入查看。
1.2 解压安装包
-
执行解压命令:
tar -zxvf jdk-8u291-linux-x64.tar.gz -
解压后生成
jdk1.8.0_291文件夹,进入查看:cd jdk1.8.0_291 ls # 输出包含bin、jre、lib等目录
1.3 移动文件到系统目录
-
创建系统 JDK 目录:
sudo mkdir /usr/lib/jdk -
移动解压后的 JDK 文件夹:
sudo mv jdk1.8.0_291 /usr/lib/jdk/
1.4 配置环境变量
-
编辑全局配置文件:
sudo vim /etc/profile -
在文件末尾添加:
# set java env export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_291 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
1.5 生效配置
source /etc/profile 1.6 测试安装
java -version
# 输出示例:
# java version "1.8.0_291"
# Java(TM) SE Runtime Environment (build 1.8.0_291-b10) 二、Kafka 安装部署
2.1 下载 Kafka
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz 2.2 解压安装
-
解压命令:
tar -zxvf kafka_2.11-2.0.0.tgz -
进入 Kafka 目录查看结构:
cd kafka_2.11-2.0.0 ls # 输出包含bin(执行脚本)、config(配置文件)、libs(依赖库)等
2.3 配置与启动 Zookeeper
-
Zookeeper 说明 :Kafka 自带 Zookeeper,启动脚本为
bin/zookeeper-server-start.sh。 -
启动方式 :
-
前台运行:
sh zookeeper-server-start.sh ../config/zookeeper.properties -
后台运行:
sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
-
-
验证启动 :
lsof -i:2181 # 查看2181端口是否被Zookeeper占用
2.4 启动与停止 Kafka
-
修改配置文件 :
编辑config/server.properties,确保 Zookeeper 连接配置:zookeeper.connect=localhost:2181 -
启动 Kafka :
sh kafka-server-start.sh -daemon ../config/server.properties -
验证启动 :
lsof -i:9092 # 查看9092端口是否被Kafka占用 -
停止 Kafka :
sh kafka-server-stop.sh -daemon ../config/server.properties
三、Kafka 基本操作
3.1 创建主题(Topic)
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
# 成功输出:Created topic "test". 参数说明:
--replication-factor:副本数量(需≤Broker 节点数)。--partitions:分区数量。
3.2 查看主题列表
sh kafka-topics.sh --list --zookeeper localhost:2181
# 输出示例:test 3.3 查看主题详情
sh kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
# 输出示例:
# Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
# Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0 3.4 消费消息
sh kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning 3.5 发送消息
sh kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
# 输入消息(如darren、king、mark),消费端将显示消息内容。 四、kafka-topics.sh 工具详解
4.1 查看帮助
sh kafka-topics.sh --help 4.2 关键参数与注意事项
-
副本数量限制 :
副本数不能超过 Broker 数量,否则报错:
sh kafka-topics.sh --create ... --replication-factor 2 ... # 错误示例:Replication factor: 2 larger than available brokers: 1. -
创建主题(必填参数):
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1- 可选参数:
--if-not-exists(主题不存在时创建)。
- 可选参数:
-
修改主题(仅支持增加分区):
sh kafka-topics.sh --zookeeper localhost:2181 --topic test1 --alter --partitions 2注意:不能减少分区数量,需删除主题后重建。
-
删除主题:
-
默认为标记删除,需修改
server.properties:delete.topic.enable=true -
重启 Kafka 后执行删除:
sh kafka-topics.sh --zookeeper localhost:2181 --delete --topic test1
-