摘要
在大数据时代,房地产市场的分析对于市场研究、政策制定以及用户决策具有重要意义。本文提出了一种基于Scrapy框架爬虫技术、Flask+MySQL和Hadoop的链家合肥二手房数据分析可视化系统。
首先,利用Scrapy框架爬虫技术从链家网高效、可靠地抓取合肥地区二手房的详细数据,包括房屋价格、面积、户型、楼层、朝向等信息。Scrapy框架以其高性能、模块化和易用性,能够快速、简单地抓取和提取网页中的数据,特别适合抓取动态生成或复杂结构化的网页数据,实现高性能的并发爬取。
然后,通过Flask框架结合MySQL数据库构建后端服务,实现数据的存储与管理。Flask作为一个轻量级的Python Web框架,能够快速构建Web应用程序,而MySQL作为一款成熟且广泛使用的开源关系型数据库管理系统,能够高效地存储和检索数据。我们使用Flask-SQLAlchemy扩展来简化数据库操作,通过定义数据模型和创建数据库表,实现了对爬取数据的高效存储和管理。
为了进一步提升数据处理效率,引入Hadoop分布式计算框架,对大规模数据进行清洗、整合与分析。Hadoop基于分布式文件系统(HDFS)和MapReduce编程模型,能够高效地处理海量数据。我们利用Hadoop生态系统中的工具,如Hive和Spark,对数据进行预处理、特征工程和建模分析,挖掘出合肥二手房市场的潜在规律和趋势。
最后,通过可视化工具将分析结果以直观的图表形式展示,包括房价趋势图、区域分布热力图、户型占比饼图等,为用户提供了一个易于理解和使用的数据分析可视化界面。这些图表不仅能够帮助用户快速了解合肥二手房市场的整体情况,还能为他们的购房决策提供有力支持。
论文结果表明,该系统能够高效采集、存储和分析链家合肥二手房数据,并通过可视化界面为用户提供一个全面、深入的市场洞察。本研究不仅为房地产市场分析提供了技术手段,也为相关领域的数据处理与可视化研究提供了参考。
**关键词:**合肥二手房;Flask;数据分析;爬虫;分布式计算
- 数据可视化展示系统设计与实现
4.1****系统分析
4.1.1****需求分析
系统需求分析
- 用户管理功能
用户注册:新用户可以通过输入基本信息(如用户名、密码、邮箱等)创建账户。系统需要验证用户输入的信息是否符合格式要求,并确保密码的安全性。
用户登录:已注册用户可以通过输入用户名和密码登录系统。系统需要验证用户凭证的有效性,并在验证成功后授予用户访问权限。登录过程需要确保安全,防止未经授权的访问。
- 房屋信息可视化
房屋信息展示:系统提供直观的可视化界面,展示房屋信息,包括价格趋势、户型占比、区域分布等。用户可以通过图表快速了解市场动态。
交互式图表:支持用户与图表进行交互,如悬停查看详细信息、缩放查看特定区域等,提高用户体验。
- 房屋信息管理
房屋信息添加:用户可以添加新的房屋信息,包括房屋价格、面积、户型、朝向、楼层、装修情况、小区名称、地区板块等。系统需要验证输入数据的完整性和准确性。
房屋信息编辑:用户可以编辑已有的房屋信息,更新房屋的详细信息。系统需要确保编辑操作的便捷性和数据的一致性。
房屋信息删除:用户可以删除不再需要的房屋信息。系统需要提供确认机制,防止误删重要数据。
- 房屋信息分析
市场趋势分析:系统对房屋数据进行分析,提供市场趋势报告,包括价格变化、供需关系等。分析结果以图表和报告形式展示,帮助用户做出明智决策。
价格变化分析:分析房屋价格的历史变化趋势,预测未来价格走势。系统提供详细的统计分析,帮助用户了解价格波动的原因。
- 房屋价格预测
价格预测功能:基于历史数据和机器学习算法,系统能够预测房屋的未来价格。用户可以输入房屋的详细信息,系统返回预测结果。
预测记录查看:系统记录用户的预测历史,用户可以查看过去的预测结果,分析预测的准确性和趋势。
- 信息词云分析
信息词云生成:系统从房屋信息中提取关键词,生成词云图。词云图直观展示市场热点和趋势,帮助用户快速了解市场关注点。
系统框架图如图4-1所示:
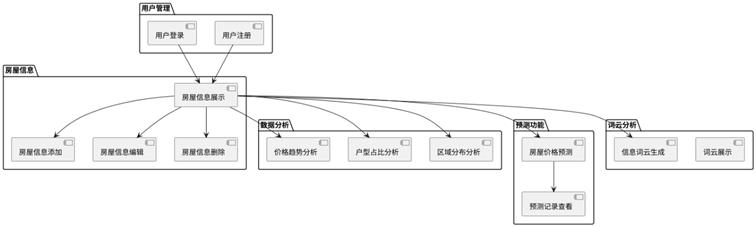 图4-1 系统框架图
图4-1 系统框架图
4.1.2****数据流分析
数据流分析如图4-2所示。
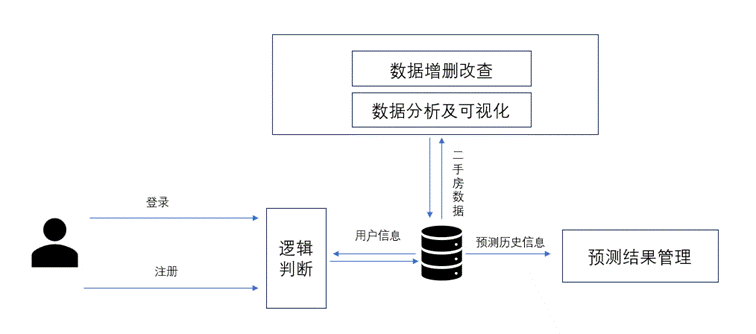
图4-2 数据流程图
用户通过登录或注册进入系统,系统验证用户身份并管理会话。用户可以请求对二手房数据进行增删改查操作,系统处理后将数据存储在数据库中。存储的数据用于数据分析和可视化,以图表形式展示给用户。用户还可以请求房屋价格预测,系统生成预测结果并存储,用户可查看预测历史信息以辅助决策。整个流程确保了数据的准确性和用户体验的流畅性。
-
- 数据库设计
4.2.1数据库设计说明
users 表用于存储用户的基本信息和登录凭证。通过 user_id 字段作为主键,保证每个用户的唯一性。username设置为唯一字段,确保用户登录时的标识唯一性。
House_info 表用于存储二手房的详细信息。表中的信息包括房屋的价格、面积、装修情况、开发商信息、以及相关的时间字段等。通过 house_id 字段作为主键,确保每个房屋的唯一性。由于房屋信息可能涉及到多种复杂结构(如 JSON 数据类型),我们使用 JSON 类型存储字段,如 rooms_desc、area_range、tags 等,以提高灵活性和扩展性。
history 表记录每次用户对房屋的预测历史,包括用户ID、房屋ID、预测结果以及查询时间等信息。通过 user_id 和 house_id 字段建立外键关系,确保能够追溯用户对特定房屋的查询和预测。
每个表都设定了适当的主键和外键约束,确保数据的唯一性和关联性。
系统ER图如下:
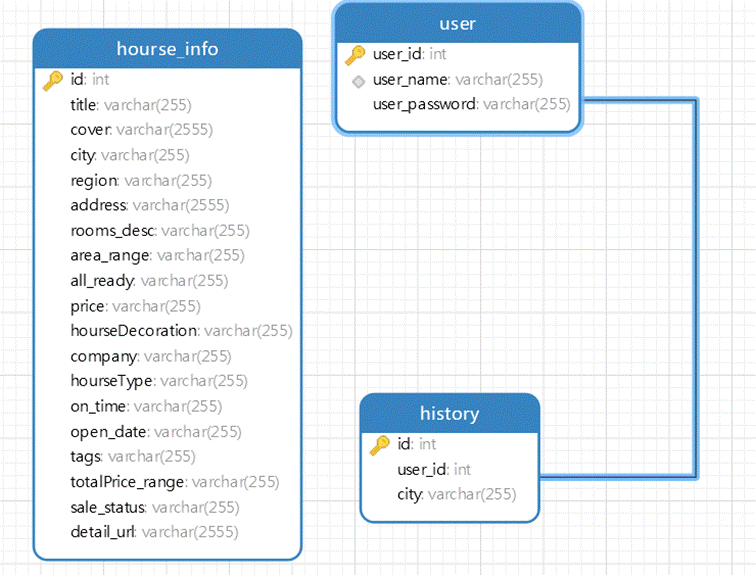
图4-5 ER图
-
-
- 数据库表设计
-
(1) 用户表(users)
描述: 存储用户的基本信息,包含用户的登录凭证等信息。
表
| 字段名 | 数据类型 | 描述 | 约束 |
|---|---|---|---|
| user_id | INT | 用户ID | 主键,自增长 |
| username | VARCHAR(255) | 用户名 | 唯一,非空 |
| password | VARCHAR(255) | 用户密码 | 非空,存储加密后的密码 |
(2)二手房数据表(house_info)
描述: 存储二手房的详细信息,包括房屋的标题、价格、地区等属性。
| 字段名 | 数据类型 | 描述 | 约束 |
|---|---|---|---|
| house_id | INT | 房屋ID | 主键,自增长 |
| title | VARCHAR(255) | 房屋标题 | 非空 |
| cover_pic | VARCHAR(255) | 封面图片 | 非空 |
| region | VARCHAR(255) | 房屋所在地区 | 非空 |
| address | VARCHAR(255) | 房屋具体地址 | 非空 |
| rooms_desc | JSON | 户型描述 | 非空 |
| area_range | JSON | 面积范围 | 非空 |
| permit_all_ready | BOOLEAN | 是否具备预售证 | 非空 |
| price | INT | 房屋价格 | 非空 |
| decoration | VARCHAR(255) | 装修情况 | 非空 |
| developer_company | JSON | 开发商信息 | 非空 |
| house_type | VARCHAR(255) | 房屋类型 | 非空 |
| on_time | DATE | 上架时间 | 非空 |
| open_date | DATE | 开盘时间 | 非空 |
| tags | JSON | 房屋标签 | 非空 |
| totalPrice_range | JSON | 总价范围 | 非空 |
| sale_status | VARCHAR(255) | 销售状态 | 非空 |
| detail_url | VARCHAR(255) | 房屋详情页面URL | 非空 |
2.3 历史查询表(Prediction_History)
表名: Prediction_History
描述: 存储用户对房屋的历史预测结果,记录查询时间和预测结果。
| 字段名 | 数据类型 | 描述 | 约束 |
|---|---|---|---|
| history_id | INT | 历史ID | 主键,自增长 |
| user_id | INT | 用户ID | 外键,关联Users表 |
| house_id | INT | 房屋ID | 外键,关联House_info表 |
| prediction_result | JSON | 预测结果 | 非空 |
| query_time | TIMESTAMP | 查询时间 | 非空 |
-
系统实现
### 登录注册模块
在基于Python技术的链家合肥二手房数据分析与可视化系统中,注册和登录功能是用户访问系统的基础。以下是注册和登录功能实现的详细流程:
1、注册功能实现流程
(1)填写注册信息
用户需要填写一些基本的注册信息,如用户名、密码、邮箱等。用户名和邮箱通常需要进行唯一性校验,密码则应遵循一定的安全标准(如最小长度、包含字符等)。
(2)点击注册按钮
完成信息填写后,用户点击注册按钮,提交注册请求。
(3)调用服务端接口
点击注册按钮后,前端会通过HTTP请求调用服务端的注册用户接口,传递用户填写的信息。
(4)信息校验
服务端接收到请求后,首先会对注册信息进行正则校验,确保填写的信息符合格式要求。例如,邮箱的格式应为标准的邮箱格式,密码应符合最低长度要求等。
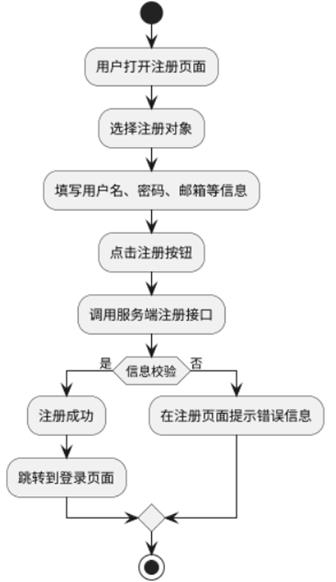
(5)注册结果反馈
成功:如果信息校验通过,用户账户注册成功,系统会提示"注册成功",并跳转到登录页面。失败:如果信息校验失败,系统会在注册页面显示具体的错误信息,提示用户哪些信息填写有误,如"用户名格式不正确"或"密码长度不足"等。
2、登录功能实现流程
(1)输入账号和密码
用户在登录页面输入已注册的账号和密码。
(2)点击登录按钮
完成信息输入后,用户点击登录按钮,系统将开始验证用户的登录信息。
(3)调用服务端接口
用户点击登录按钮后,前端通过HTTP请求调用服务端的登录接口,传递账号和密码进行验证。
(4)账户存在性检查
服务端首先检查输入的账号是否存在。如果账号不存在,系统会提示跳转eorr页面。
(5)密码验证
正确:如果账号存在,系统会对输入的密码进行验证。如果密码正确,用户登录成功,系统会跳转到系统首页。错误:如果密码验证失败,系统会提示跳转eorr页面。
登录注册流程图如下:
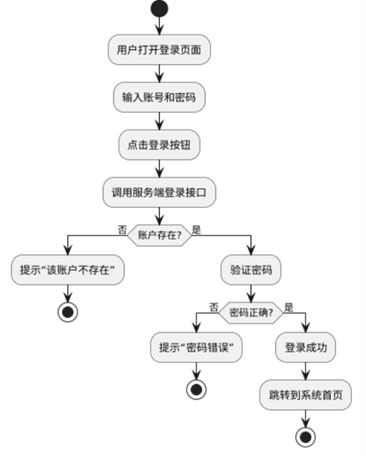
图4-6 登录注册流程图,(注册左,登录右)
模块界面展示
(1)登录注册界面展示:
下图为用户注册页面,该页面包含用户名、密码、确认密码。还有一些条款和条件需要用户去同意,不同意的话是无法进行注册操作的,在所有条件符合就可以进行完成注册。如图4-7所示。
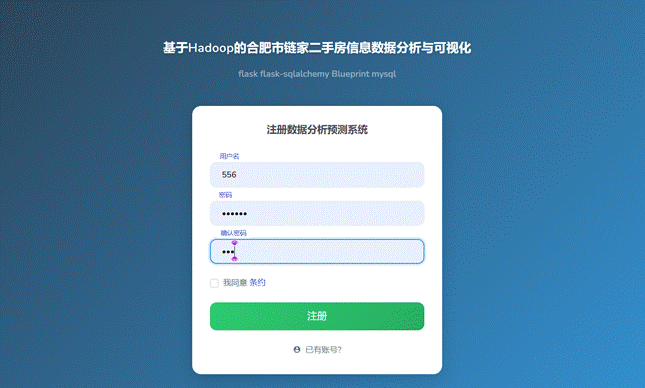
图4-7 注册图
下图为登录界面图,里面有用户名,密码,记住我这几个选项,用户输入对应的账户名称和正确的密码才能进行登录,如果用户忘记密码,可以点击下面忘记密码进行找回,或者点击注册进行重新注册。如图4-8所示。
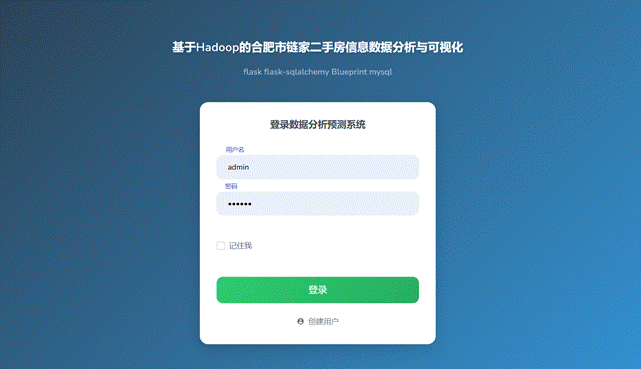
图4-8 登录图
(2)系统主页界面展示:
下图为系统主页的信息图,会包含用户预测记录等信息,如图4-9所示。
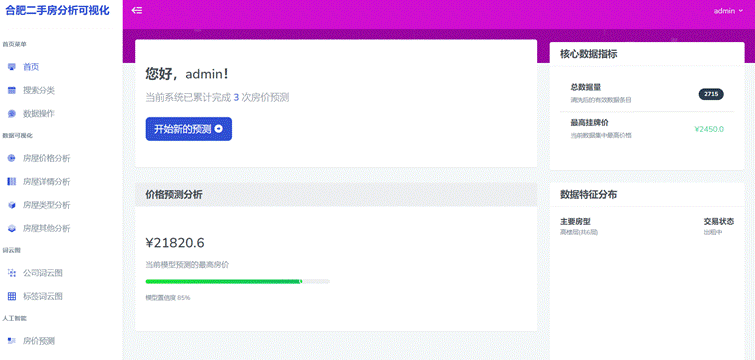
图4-9 系统主页图
下图是数据库信息的Web展示和修改图:
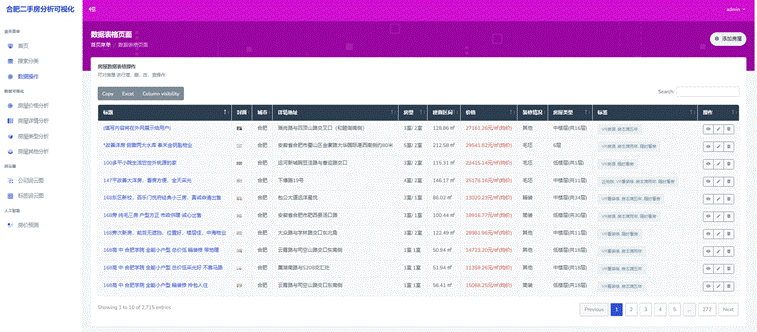
图4-10数据Web图
(3)可视化界面展示:
房价分析:
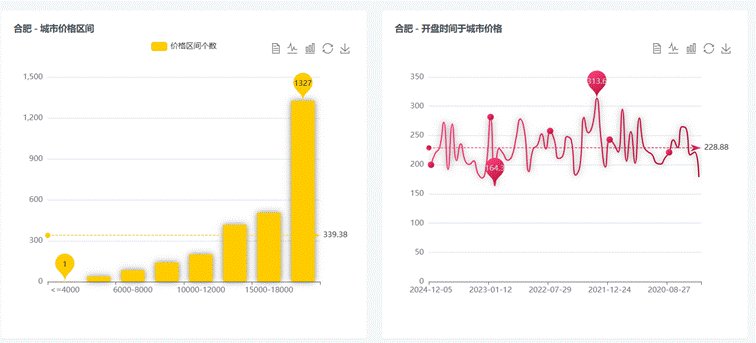
图4-11 房价数据可视化展示图
(4)房屋出售情况和房屋标签分析:
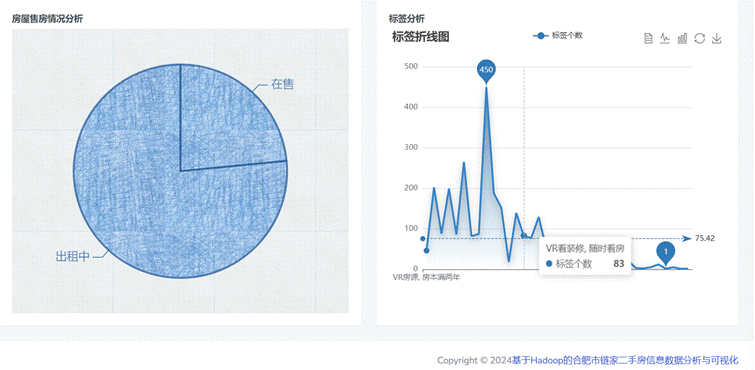
图4-11 房屋销售和标签数据统计分析可视化
(5)房屋户型和面积统计分析:
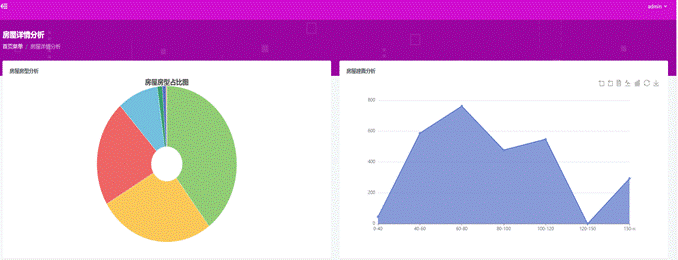
图4-12 房屋类型和面积分析可视化图
(6)房屋装修情况和楼层介绍分析:
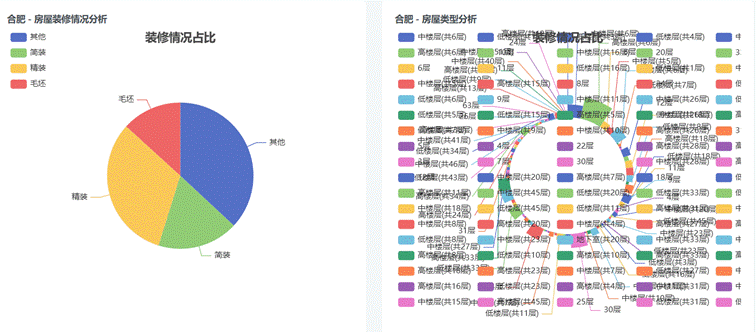
图4-12 房屋装修和楼层介绍可视化图
(7)开发商词云和房屋标签展示:


图4-12 开发商词云(左)和房屋标签词云(右)
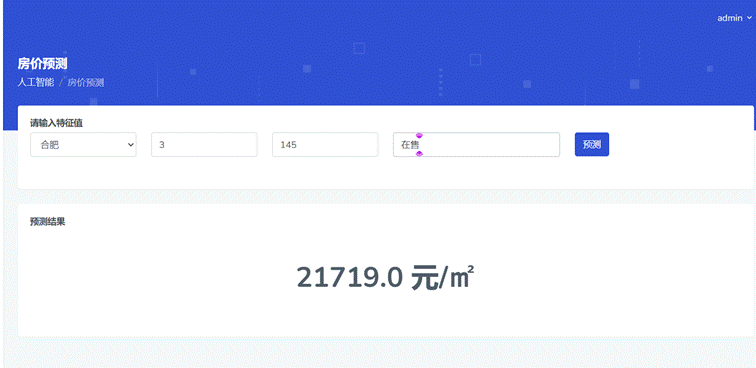
(8)房价预测页面:
如下图所示,用户通过输入卧室数量、房屋面积、销售状态信息,即可预测一个房屋价格信息。
本章小结
本章详细介绍了基于Python技术的链家合肥二手房数据分析与可视化系统的分析、设计与实现过程。首先,通过需求分析明确了系统的功能模块,包括用户管理、房屋信息可视化、房屋信息管理、房屋信息分析、房屋价格预测和信息词云分析等功能。数据流分析展示了用户如何通过登录或注册进入系统,以及系统如何处理和存储数据,确保数据的准确性和用户体验的流畅性。
在数据库设计部分,详细描述了用户表、二手房数据表和历史查询表的结构,确保数据的唯一性和关联性。系统框架图和ER图进一步展示了系统的整体架构和数据关系。
系统实现部分详细描述了登录注册模块的实现流程,包括用户注册和登录的具体步骤。模块界面展示部分通过多个界面图展示了系统的各个功能模块,包括登录注册界面、系统主页、数据库信息展示、可视化界面(如房价分析、房屋出售情况、房屋标签分析、房屋户型和面积统计分析、房屋装修情况和楼层介绍分析、开发商词云和房屋标签展示)以及房价预测页面。
通过这些功能模块的实现,系统为用户提供了一个全面的链家合肥二手房数据分析与可视化平台,帮助用户更好地理解和利用数据,做出明智的决策。