PyTorch实战(7)------生成对抗网络实践详解
0. 前言
生成对抗网络 (Generative Adversarial Network, GAN) 最早由 Ian Goodfellow 于 2014 年提出,其中"对抗"一词指的是两个神经网络之间在零和博弈框架下相互竞争的特性。生成器试图创建与真实样本无法区分的数据样本,而判别器则试图区分生成器生成的样本与真实样本。GAN 模型可以生成多种形式的内容,从几何形状和数字序列到高分辨率的彩色图像,甚至逼真的音乐作品。在本节中,我们将介绍 GAN 的理论基础。然后,介绍如何使用 PyTorch 从零开始构建 GAN,以便了解所有细节,深入理解 GAN 的内部工作原理,为后续讨论 GAN 的其他更高级内容奠定基础,比如生成高分辨率图像或逼真的音乐。
1. 生成对抗网络训练步骤
在本节中,我们将介绍训练生成对抗网络 (Generative Adversarial Network, GAN) 的一般步骤,并说明如何生成数据点来形成指数增长曲线。在此过程中,将学习如何从零开始创建生成器和判别器,以及如何训练、保存和使用 GAN。此外,还将学习如何评估 GAN 的性能,既可以通过可视化生成器网络生成的样本,也可以通过衡量生成样本分布与真实数据分布之间的差异来进行评估。
为了让示例更易于理解,假设将 1 元钱存入一个年利率为 8% 的储蓄账户,根据投资年限来计算账户余额,我们希望知道未来账户中会有多少钱。未来账户中的金额 y y y 取决于存入时间长度,用 x x x 来表示存入年数。例如,如果存入 1 年,账户余额为 1.08 1.08 1.08 元;如果存入 2 年,余额为 1.08 2 = 1.1664 1.08²=1.1664 1.082=1.1664 元, x x x 和 y y y 之间的关系为 y = 1.08 x y=1.08^x y=1.08x,函数图像为一条指数增长曲线。我们将学习如何使用生成对抗网络 (Generative Adversarial Network, GAN) 生成数据样本------数值对 (x,y),构成方程为 y = 1.08 x y = 1.08^x y=1.08x 的指数增长曲线。
训练 GAN 生成符合特定数学关系的数据点需要多个步骤。在本节中,生成数据点 (x, y),使得 y = 1.08 x y=1.08^x y=1.08x,下图展示了 GAN 的架构和生成指数增长曲线的步骤。如果需要生成其他内容,例如图像或音乐等复杂数据时,同样遵循类似的步骤。
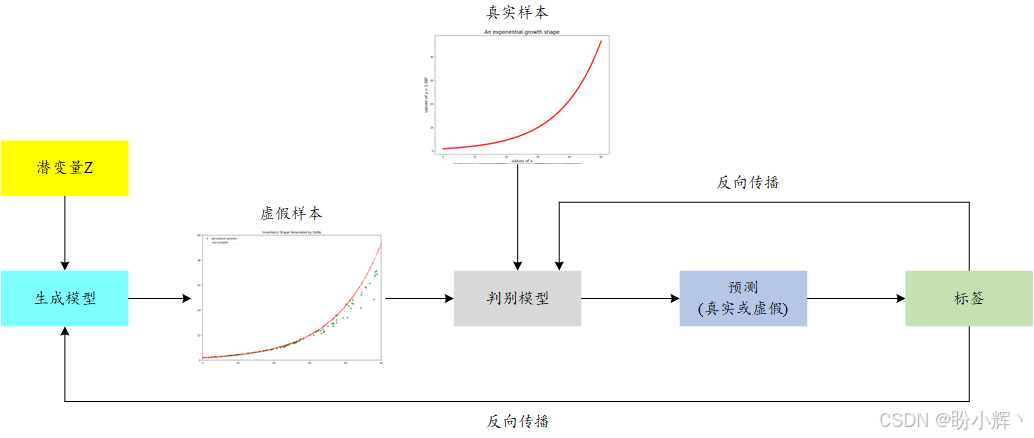
在训练模型之前,我们需要一个训练数据集来训练 GAN。在本节中,使用数学关系 y = 1.08 x y=1.08^x y=1.08x 生成 (x, y) 数据对。也可以将所学技术应用于其他曲线,如正弦曲线、余弦曲线、U形曲线等。可以选择一系列 x x x 值,并计算出相应的 y y y 值。实际样本如上图所示,呈现出指数增长曲线形状。
准备好训练集后,创建 GAN 中的两个网络:生成器和判别器。生成器接受一个随机噪声向量 Z Z Z 作为输入,生成数据点,生成器使用的随机噪声向量 Z Z Z 来自潜空间。判别器评估给定的数据点 (x, y) 是否为真实数据(来自训练数据集)或虚假数据(由生成器生成)。
GAN 中的潜空间是一个概念空间,其中每个点都可以通过生成器转化为一个真实的数据实例。潜空间代表了 GAN 能够生成的可能输出范围,并且是 GAN 生成多样化和复杂数据能力的核心。潜空间只有在与生成模型结合使用时才具备意义,可以在潜空间中的点之间进行插值,从而影响输出的属性。
为了调整模型参数,必须选择正确的损失函数。需要为生成器和判别器定义损失函数,损失函数鼓励生成器生成与训练数据集中的数据相似的数据,使得判别器将它们分类为真实数据,同时损失函数也鼓励判别器正确分类真实数据和生成数据。
在每次训练迭代中,交替训练判别器和生成器。在每次训练迭代中,从训练数据集中采样一批真实的 (x, y) 数据和一批由生成器生成的虚假数据。当训练判别器时,将判别器的预测与真实标签进行比较,判别器预测的是该样本来自训练集的概率,真实标签是 1 表示样本为真实数据,0 表示样本为虚假数据。调整判别器中的权重,以便在下一次迭代中,预测的概率更接近真实标签。
训练生成器时,我们将虚假样本输入判别器,并获得该样本为真实样本的概率。然后调整生成器中的权重,使得在下一次迭代中,判别器预测的概率更接近 1 (因为生成器希望生成样本来欺骗判别器,使其认为这些样本是真实的)。多次重复以上过程,使得生成器生成更逼真的数据点。
为了判断何时停止训练 GAN,通过生成一组虚假数据点并将其与训练数据集中的真实数据点进行比较来评估 GAN 的性能。在大多数情况下,使用可视化技术来评估生成的数据与期望关系的符合程度。然而,在本节中,由于我们知道训练数据的分布,因此可以计算生成数据和真实数据分布之间的均方误差 (Mean Squared Error, MSE)。当生成的样本在经过一定次数的训练后,质量不再有所提升时,就停止训练 GAN。
模型训练完毕后,丢弃判别器,保留生成器。为了生成一个指数增长曲线,将随机噪声向量 Z Z Z 输入到训练好的生成器中,并获得多个 (x, y) 数据点来形成所需形状。
2. 准备训练数据
在本节中,创建训练数据集用于训练生成对抗网络 (Generative Adversarial Network, GAN) 模型。具体来说,创建多个符合指数增长形状的 (x, y) 数据点,并将构建批数据形式,以便可以输入到深度神经网络中进行训练。
2.1 创建训练数据集
(1) 创建数据集,其中包含多个数据对 (x, y),其中 x x x 均匀分布在区间 [0, 50] 内, y y y 基于公式 y = 1.08 x y = 1.08^x y=1.08x。
python
import torch
observations = 2048
train_data = torch.zeros((observations, 2))
train_data[:,0]=50*torch.rand(observations)
train_data[:,1]=1.08**train_data[:,0]创建一个 PyTorch 张量 train_data,包含 2,048 行和 2 列, x x x 值放置在张量 train_data 的第一列中。PyTorch 的 rand() 方法生成 0.0 到 1.0 之间的随机值,通过将值乘以 50,生成的 x x x 值介于 0.0 和 50.0 之间。然后,将 train_data 的第二列填充为 y = 1.08 x y = 1.08^x y=1.08x。
(2) 绘制 x x x 和 y y y 之间的曲线图,可以得到下图所示指数增长曲线形状:
python
import matplotlib.pyplot as plt
fig=plt.figure(dpi=100,figsize=(8,6))
# 绘制 x 和 y 之间的关系
plt.plot(train_data[:,0],train_data[:,1],".",c="r")
plt.xlabel("values of x",fontsize=15)
plt.ylabel("values of $y=1.08^x$",fontsize=15)
plt.title("An exponential growth shape",fontsize=20)
plt.show()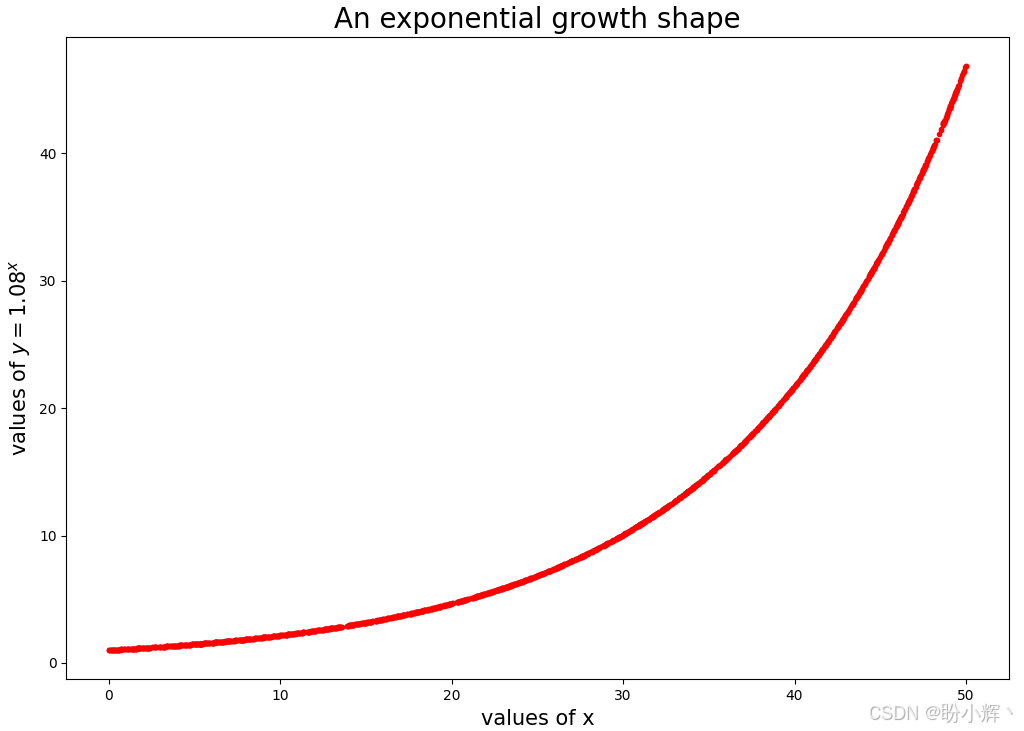
2.2 准备训练数据集
接下来,将刚刚创建的数据样本分成批数据,以便将其输入到判别器中。
(1) 使用 PyTorch 中的 DataLoader() 类将训练数据集封装成一个可迭代对象,从而在训练过程中方便地访问样本:
python
from torch.utils.data import DataLoader
batch_size=128
train_loader=DataLoader(
train_data,
batch_size=batch_size,
shuffle=True)使用 2,048 个数据样本,批大小为 128。因此,有 2,048/128 = 16 个批次。DataLoader() 中的 shuffle 参数为 True 时会在将样本分成批数据之前,随机打乱数据样本。打乱操作可以确保数据样本均匀分布,避免在一个批次内的样本之间有相关性,从而使得训练过程更加稳定。
(2) 可以通过 next() 和 iter() 方法来访问一个批数据:
python
batch0=next(iter(train_loader))
print(batch0)3. 构建生成对抗网络
现在,训练数据集准备完毕后,创建生成器网络和判别器网络。判别器网络是一个二分类器,任务是将样本分类为真实或虚假。而生成器网络则试图创建与训练集中的数据点 (x, y) 相似的样本,以便判别器将其分类为真实。
3.1 判别器网络
使用 PyTorch 创建判别器神经网络。使用全连接层,并应用 ReLU 激活函数,为了防止过拟合,使用 Dropout 层:
python
import torch.nn as nn
device="cuda" if torch.cuda.is_available() else "cpu"
D=nn.Sequential(
nn.Linear(2,256),
nn.ReLU(),
# Dropout 层防止过拟合
nn.Dropout(0.3),
nn.Linear(256,128),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(128,64),
nn.ReLU(),
nn.Dropout(0.3),
# 最后一层的输出特征数量是 1,将其压缩为一个介于 0 和 1 之间的值
nn.Linear(64,1),
nn.Sigmoid()).to(device)在第一层中,输入形状为 2,因为在本节中,每个数据实例包含两个值: x x x 和 y y y。第一层中的输入数量应始终与输入数据的大小匹配。此外,确保最后一层中的输出特征数量为 1,判别器网络的输出是一个单一值。使用 sigmoid 激活函数将输出压缩到 [0, 1] 范围内,可以解释为样本为真实样本的概率 p p p, 1 − p 1 - p 1−p 表示样本是虚假样本的概率。
隐藏层分别有 256、128 和 64 个神经元,如果隐藏层中的神经元数量过多,可能会导致模型过拟合;如果数量过少,可能会导致欠拟合。神经元的数量可以通过超参数调整,利用验证集进行优化。
Dropout 层会随机"丢弃"层中一定比例的神经元,丢弃的神经元在训练过程中不会参与前向传播或反向传播。过拟合会导致模型不仅学到了训练数据中的模式,还学到了噪声和随机波动,导致在未见过的数据上的表现较差,Dropout 是一种有效的防止过拟合的方法。
3.2 生成器网络
生成器的任务是创建数据点 (x, y),使其能够通过判别器的筛选。也就是说,生成器试图创建一对数字,以最大化判别器认为这些数字来自训练数据集的概率(即它们满足方程 y = 1.08 x y = 1.08^x y=1.08x):
python
G=nn.Sequential(
# 第一层的输入特征数量是 2,和潜空间中随机噪声向量的维度相同
nn.Linear(2,16),
nn.ReLU(),
nn.Linear(16,32),
nn.ReLU(),
# 最后一层的输出特征数量是 2,和数据样本的维度相同,数据样本包含两个值 (x, y)
nn.Linear(32,2)).to(device)将来自二维潜空间的随机噪声向量 (z1, z2) 输入到生成器中。然后,生成器基于潜空间的输入生成一对 (x, y) 值。
3.3 模型训练
由于判别器网络本质上执行的是一个二分类任务(识别数据样本是真实还是虚假),为判别器网络使用二元交叉熵损失,这是二分类任务中常用的损失函数。判别器试图最大化二分类的准确率,将真实样本识别为真实,将虚假样本识别为虚假。判别器网络中的权重根据损失函数相对于权重的梯度进行更新。
生成器试图最小化虚假样本被识别为虚假的概率。因此,生成器网络同样使用二元交叉熵损失,生成器更新其网络权重,以便生成的样本会被判别器在二分类问题中识别为真实。
(1) 使用 Adam 优化器,并将学习率设置为 0.0005:
python
loss_fn=nn.BCELoss()
lr=0.0005
optimD=torch.optim.Adam(D.parameters(),lr=lr)
optimG=torch.optim.Adam(G.parameters(),lr=lr)(2) 在开始实际训练之前,还有一个问题需要解决,即应该训练 GAN 多少epoch。换句话说,我们如何知道模型已经能够生成可以模拟指数增长曲线形状的样本。在监督学习模型中,我们将训练集进一步分为训练集和验证集。然后使用验证集中的损失来判断模型的参数是否已经收敛,从而决定是否停止训练。然而,GAN 的训练方法与传统的监督学习模型(如分类模型)不同。由于生成的样本质量随着训练的进行不断提高,判别器的任务变得越来越困难(某种程度上,GAN 中的判别器是在一个不断变化的目标上进行预测)。因此,判别器网络的损失并不是一个能够满足需求的模型质量评估指标。
评估 GAN 性能的一个常用方法是通过视觉检查。可以通过简单地观察生成的数据样本来评估它们的质量和真实性,这是一种定性的方法。但在本节中,由于我们知道训练数据集的确切分布,因此可以计算生成样本与训练集中的样本之间的均方误差 (Mean Squared Error, MSE),并将其作为生成器性能的衡量标准:
python
mse=nn.MSELoss()
def performance(fake_samples):
# 真实分布
real=1.08**fake_samples[:,0]
# 将生成分布与真实分布进行比较,并计算 MSE
mseloss=mse(fake_samples[:,1],real)
return mseloss(3) 如果生成器的性能在数个(例如 100) epoch 后没有改善,就停止训练模型。因此,我们定义一个提前停止类,用于决定什么时候停止训练模型:
python
class EarlyStop:
def __init__(self, patience=100): # 将 patience 的默认值设置为 100
self.patience = patience
self.steps = 0
self.min_gdif = float('inf')
def stop(self, gdif): # 定义 stop() 方法
# 如果生成分布与真实分布之间的新差异大于当前最小差异,则更新 min_gdif 的值
if gdif < self.min_gdif:
self.min_gdif = gdif
self.steps = 0
elif gdif >= self.min_gdif:
self.steps += 1
# 如果模型在 100 个 epoch 内没有改进,则停止训练
if self.steps >= self.patience:
return True
else:
return False
stopper=EarlyStop()(4) 现在我们已经有了训练数据和 GAN 模型,接下来开始训练模型。
首先为真实样本和虚假样本创建标签。具体来说,将所有真实样本标注为 1,将所有虚假样本标注为 0。在训练过程中,判别器将其预测结果与标签进行比较,获得反馈,从而调整模型参数,以便在下一次迭代中做出更好的预测。定义两个张量,real_labels 和 fake_labels:
python
real_labels=torch.ones((batch_size,1))
real_labels=real_labels.to(device)
fake_labels=torch.zeros((batch_size,1))
fake_labels=fake_labels.to(device)real_labels 是一个二维张量,形状为 (batch_size, 1),将一批 128 个真实样本传递给判别器网络,以获得 128 个预测值。同样,fake_labels 也是一个二维张量,形状为 (batch_size, 1)。
(5) 定义函数 train_D_on_real() 用一批真实样本训练判别器网络:
python
def train_D_on_real(real_samples):
real_samples=real_samples.to(device)
optimD.zero_grad()
out_D=D(real_samples) # 对真实样本进行预测
loss_D=loss_fn(out_D,real_labels) # 计算损失
loss_D.backward()
optimD.step() # 反向传播
return loss_D判别器网络 D 对该批样本进行预测。然后,模型将判别器的预测 out_D 与真实标签 real_labels 进行比较,并相应地计算预测的损失。backward() 方法根据损失函数相对于模型参数的梯度进行计算,step() 方法调整模型参数。zero_grad() 方法表示在反向传播之前明确将梯度设为 0,否则,每次调用 backward() 时,会使用累积的梯度,而不是增量梯度。
(6) 定义函数 train_D_on_fake() 用一批虚假样本训练判别器网络:
python
def train_D_on_fake():
noise=torch.randn((batch_size,2))
noise=noise.to(device)
fake_samples=G(noise) # 生成一批虚假样本
optimD.zero_grad()
out_D=D(fake_samples) # 对虚假样本进行预测
loss_D=loss_fn(out_D,fake_labels) # 计算损失
loss_D.backward()
optimD.step() # 反向传播
return loss_Dtrain_D_on_fake() 函数首先将从潜空间中随机生成的噪声向量传递给生成器,以获得一批虚假样本。然后,该函数将虚假样本传递给判别器,以获得预测值。该函数将判别器的预测 out_D 与真实标签 fake_labels 进行比较,并相应地计算损失。最后,函数根据损失函数相对于模型权重的梯度调整模型参数。
(7) 定义函数 train_G() 用一批虚假样本训练生成器网络:
python
def train_G():
noise=torch.randn((batch_size,2))
noise=noise.to(device)
optimG.zero_grad()
fake_samples=G(noise) # 生成一批虚假样本
out_G=D(fake_samples) # 将虚假样本输入到判别器以获得预测
loss_G=loss_fn(out_G,real_labels) # 计算损失
loss_G.backward()
optimG.step() # 反向传播
return loss_G, fake_samples为了训练生成器,首先将一批来自潜空间的随机噪声向量传递给生成器,从而获得一批虚假样本。接着,将这些虚假样本输入到判别器网络,获得一批预测值。将判别器的预测与 real_labels 进行比较,并计算损失。需要注意的是,在计算损失时我们使用的是全是 1 的张量,而不是全是 0 的张量,因为生成器的目标是欺骗判别器,使其认为虚假样本是真实的。最后,根据损失函数相对于模型权重的梯度来调整模型参数,以便在下一次迭代时,生成器能够生成更为真实的样本。
(8) 接下来,定义函数 test_epoch(),该函数用于打印判别器和生成器的损失,并绘制生成器生成的数据点,和训练集中的数据点进行对比:
python
import os
os.makedirs("files", exist_ok=True) # 创建文件夹用于保存生成结果
def test_epoch(epoch,gloss,dloss,n,fake_samples):
if epoch==0 or (epoch+1)%25==0:
g=gloss.item()/n
d=dloss.item()/n
print(f"at epoch {epoch+1}, G loss: {g}, D loss {d}") # 定期打印损失值
fake=fake_samples.detach().cpu().numpy()
plt.figure(dpi=200)
plt.plot(fake[:,0],fake[:,1],"*",c="g",
label="generated samples") # 将生成数据点绘制为 *
plt.plot(train_data[:,0],train_data[:,1],".",c="r",
alpha=0.1,label="real samples") # 将训练数据绘制为 .
plt.title(f"epoch {epoch+1}")
plt.xlim(0,50)
plt.ylim(0,50)
plt.legend()
plt.savefig(f"files/p{epoch+1}.png")每经过 25 个 epoch,函数会打印出该 epoch 中生成器和判别器的平均损失。此外,绘制由生成器生成的虚假数据点(以星号表示),并与训练集中的数据点(以圆点表示)进行比较。
(9) 接下来,训练模型。遍历训练数据集中的所有批数据,对于每一批数据,首先使用真实样本训练判别器;然后,生成器生成一批虚假样本,使用这些虚假样本训练判别器;最后,生成器再次生成一批虚假样本,使用这些虚假样本训练生成器。训练模型直到满足停止条件:
python
# 开始训练循环
for epoch in range(10000):
gloss=0
dloss=0
for n, real_samples in enumerate(train_loader): # 遍历训练数据集中的所有批次
loss_D=train_D_on_real(real_samples)
dloss+=loss_D
loss_D=train_D_on_fake()
dloss+=loss_D
loss_G,fake_samples=train_G()
gloss+=loss_G
test_epoch(epoch,gloss,dloss,n,fake_samples) # 定期显示生成的样本
gdif=performance(fake_samples).item()
if stopper.stop(gdif)==True: #D 判断是否应该停止训练
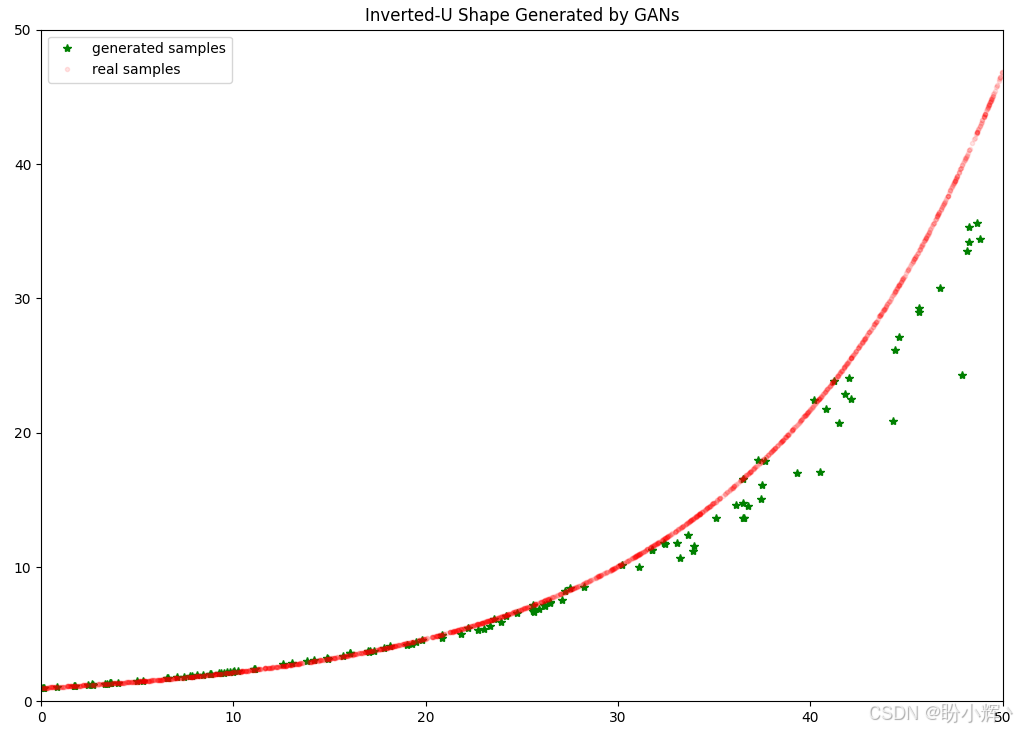
break经过 1,025 个 epoch 后,生成的数据点与指数增长曲线非常吻合,这表明训练的 GAN 表现良好,生成器能够生成数据点,形成所需的形状。
3.4 生成器的保存与加载
(1) GAN 模型训练完成后,丢弃判别器网络,并将训练好的生成器网络保存到本地文件夹中:
python
import os
os.makedirs("files", exist_ok=True)
scripted = torch.jit.script(G)
scripted.save('files/exponential.pt') torch.jit.script() 方法通过 TorchScript 编译器将函数或 nn.Module 类转化为 TorchScript 代码。使用该方法将训练好的生成器网络保存为文件 exponential.pt。
(2) 要使用该生成器,不需要重新定义模型,只需加载保存的文件,并使用它来生成数据点:
python
new_G=torch.jit.load('files/exponential.pt',
map_location=device)
new_G.eval()加载训练好的生成器到设备上,这个设备可以是 CPU,也可以是 CUDA 设备,map_location 参数在 torch.jit.load() 中指定了加载生成器的位置。
(3) 从潜空间中获取一批随机噪声向量,将这些向量输入到生成器中,生成数据并绘制:
python
noise=torch.randn((batch_size,2)).to(device)
new_data=new_G(noise)
fig=plt.figure(dpi=100)
# 将生成的数据样本绘制为 *
plt.plot(new_data.detach().cpu().numpy()[:,0],
new_data.detach().cpu().numpy()[:,1],"*",c="g",
label="generated samples")
# 将训练数据绘制为 .
plt.plot(train_data[:,0],train_data[:,1],".",c="r",
alpha=0.1,label="real samples")
plt.title("Inverted-U Shape Generated by GANs")
plt.xlim(0,50)
plt.ylim(0,50)
plt.legend()
plt.show()可视化结果如下所示,可以看到生成的数据样本与指数增长曲线非常相似。
小结
了解了生成对抗网络 (Generative Adversarial Network, GAN) 的工作原理后,能够将 GAN 的概念扩展到其他格式,包括高分辨率图像和逼真的音乐:
GAN由两个网络组成:判别器用于区分虚假样本和真实样本,生成器用于创建与训练集中的真实样本无法区分的虚假样本GAN的训练过程包括准备训练数据、创建判别器和生成器、训练模型并决定何时停止训练,最后使用训练好的生成器生成新样本
系列链接
PyTorch生成式人工智能实战:从零打造创意引擎
PyTorch实战(1)------神经网络与模型训练过程详解
PyTorch实战(2)------PyTorch基础
PyTorch实战(3)------使用PyTorch构建神经网络
PyTorch实战(4)------卷积神经网络详解
PyTorch实战(5)------分类任务详解
PyTorch实战(6)------生成模型(Generative Model)详解