1. FC
FC全称是Fully Connect全连接层,也被称为Linear Layer线性层。
它的核心是:每个输入神经元 与 每个输出神经元 都要通过权重连接,适用于将输入特征映射到高维或者低维空间。
数学表示
对于一个输入向量
,FC的计算方式是:
代码表示
示例一:
pythonimport torch import torch.nn as nn # 定义一个全连接层(输入维度是3,输出维度是5) fc_layer=nn.Linear(in_features=10,out_features=5) # 输入数据(batch_size=3, 特征维度=10) x = torch.randn(3, 10) # 前向计算 output = fc_layer(x) # 输出形状: (3, 5)示例二:
python# 定义一个FC层(输入512维,输出2048维) fc = nn.Linear(3, 2) x = torch.randn(3, 10, 512) # (batch_size, seq_len, d_model) fc = nn.Linear(512, 2048) # 输入维度=512,输出维度=2048 output = fc(x) # 输出形状: (3, 10, 2048)注意
nn.Linear的设计会自动处理高维输入,仅对最后一个维度进行线性变换 ,而保持其他维度不变。若输入
x的形状为(D1, D2, ..., Dn, in_features),则输出形状为(D1, D2, ..., Dn, out_features)。
2. MLP
MLP全称是MultiLayer Perceptron,多层感知机。
MLP = 输入层 + 隐藏层(至少一层)+ 输出层
每一层包含多个神经元,层与层之间全连接FC(Fully Connected)。
数学表示
3层MLP,也就是单隐藏层的MLP:
输入 → FC → ReLU → FC → 输出
- x 是输入,h 是隐藏层输出,y 是最终输出。
- σ 是非线性激活函数。
代码表示
pythonClass MLP(nn.Module): def __init__(self,input_dim=10,hidden_dim=20,output_dim=5): super().__init__() self.layers=nn.Sequential( nn.Linear(input_dim,hidden_dim), # 第一层FC nn.ReLU(), # 激活函数 nn.Linear(hidden_dim.output_dim) # 第二层FC ) def forward(self,x): return self.layers(x) # 使用MLP mlp=MLP() x=torch.randn(3,10) output=mlp(x) # (3,5)
3. FFN
FFN全称是FeedForward Network,前馈神经网络,也称为多层感知器MLP(MultiLayer Perceptron)。
FFN 是一个更广义的概念,指 任何没有循环或反馈连接的神经网络,包括MLP。
Transformer中的FFN
在特Transformer中,FFN 特指一种 带有残差连接的两层全连接网络。
数学表示
- 第一层:扩展维度(通常放大4倍),使用ReLU激活。
- 第二层:压缩回原始维度。
- 残差连接:FFN的输出会与输入相加(x+FFN(x))。
代码表示
pythonimport torch import torch.nn as nn class FFN(nn.Module): def __init__(self, d_model=512, d_ff=2048, dropout=0.1): super().__init__() # 第一层:扩展维度 (d_model → d_ff) self.fc1 = nn.Linear(d_model, d_ff) # 第二层:压缩回原始维度 (d_ff → d_model) self.fc2 = nn.Linear(d_ff, d_model) # 激活函数和Dropout self.relu = nn.ReLU() self.dropout = nn.Dropout(dropout) def forward(self, x): # 残差连接保留原始输入 residual = x # 第一层 + ReLU + Dropout x = self.dropout(self.relu(self.fc1(x))) # 第二层 x = self.fc2(x) # 残差连接 + Dropout(可选) x = self.dropout(x) + residual # 原始Transformer论文中此处无Dropout return x # 使用示例 ffn = FFN(d_model=512, d_ff=2048, dropout=0.1) x = torch.randn(3, 10, 512) # (batch_size, seq_len, d_model) output = ffn(x)
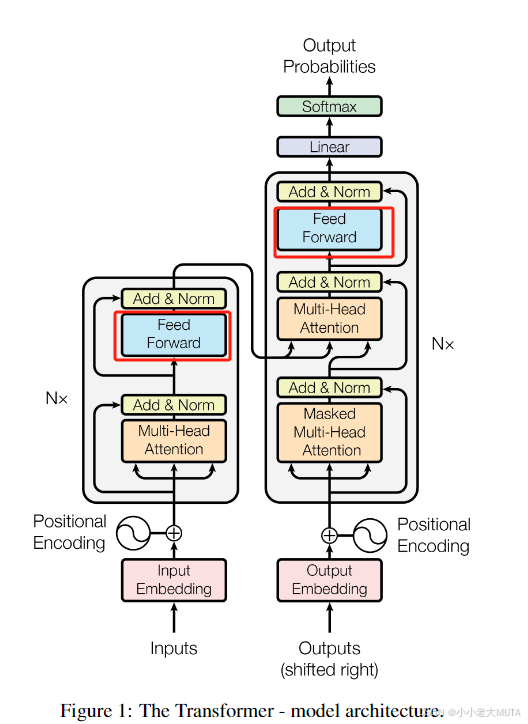


4、MLP 与 MLP的区别
在机器学习和深度学习中,MLP(多层感知机)和 FFN(前馈神经网络)在很大程度上可以视为同义词,都指代了一个具有多个层的前馈神经网络结构。
- MLP(多层感知机)更偏向于表达 网络结构(多个全连接层)
- FFN(前馈神经网络)更偏向于表达 数据以前馈的方式流动
MLP 和 FFN 通常指的是只包含全连接层 和激活函数的神经网络结构。这两者都是基本的前馈神经网络类型,没有包含卷积层或其他复杂的结构。
5、Logit
Logit 通常指 神经网络中最后一个隐藏层的输出,经过激活函数之前的值,例如:
- 对于二分类问题,logit是指网络输出的未经过sigmoid函数处理的数据;
- 对于多分类问题,logit是指网络输出的未经过softmax函数处理的数据。
数学表示
在分类任务中,假设模型有
C个类别,Logit 是模型最后一层(通常是全连接层)的输出:
i个类别的原始预测值(未归一化)。- 这些值可以是任意实数(正、负或零),范围不受限制。
Logit 与 概率的关系
多分类任务
Logit 本身不是概率,但可以通过 Softmax 函数 转换为概率:
Softmax 的作用:
- 将 Logit 转换为概率分布(所有 pi之和为 1)。
- 放大较大的 Logit,抑制较小的 Logit(指数运算的影响)。
代码表示
pythonimport torch logits = torch.tensor([2.0, 1.0, 0.1]) # 模型输出的原始分数 probs = torch.softmax(logits, dim=0) # 转换为概率 print("Logits:", logits) # tensor([2.0000, 1.0000, 0.1000]) print("Probs:", probs) # tensor([0.6590, 0.2424, 0.0986])二分类任务
在二分类 任务中:Logit 是单个标量 z(不是向量)。通过 Sigmoid 转换为概率:
代码表示
pythonlogit = torch.tensor([0.8]) # 模型输出的 Logit prob = torch.sigmoid(logit) # 转换为概率 print("Logit:", logit.item()) # 0.8 print("Prob:", prob.item()) # 0.6899
6. NLL
NLL 全称是Negative Log_Likelihood 负对数似然,是机器学习中常用的损失i函数,主要用于分类任务。
核心思想:
- 惩罚模型 预测的概率分布 与 真实标签 的 差异。
- 越小越好(NLL 越小,模型预测越准)。
数学定义
给定:
- 真实标签(one-hot 或类别索引):y;
- 模型预测的概率分布(Softmax 输出):p NLL 的计算公式:
代码表示
pythonimport torch import torch.nn as nn # 模型预测的 Logit(未归一化) logits = torch.tensor([[2.0, 1.0, 0.1]]) # 1个样本,3个类别 # 真实标签(类别索引,假设是第0类) target = torch.tensor([0]) # 真实类别是第0类 # 计算 Softmax 概率 probs = torch.softmax(logits, dim=1) # tensor([[0.6590, 0.2424, 0.0986]]) # 计算 NLL nll_loss = -torch.log(probs[0, target]) # -log(0.6590) ≈ 0.417 print("NLL Loss:", nll_loss.item()) # 输出: 0.417
与交叉熵损失关系
在分类问题中,NLL 通常与交叉熵损失(Cross-Entropy Loss)等价使用。
7. 感受野
感受野receptive field 是卷积神经网络输出特征图上的像素点在原始图像上所能看到的(映射的)区域的大小,它决定了该像素对输入图像的感知范围(获取信息的范围)。
较小的感受野可以捕捉到更细节的特征,较大的感受野可以捕捉到更全局的特征。
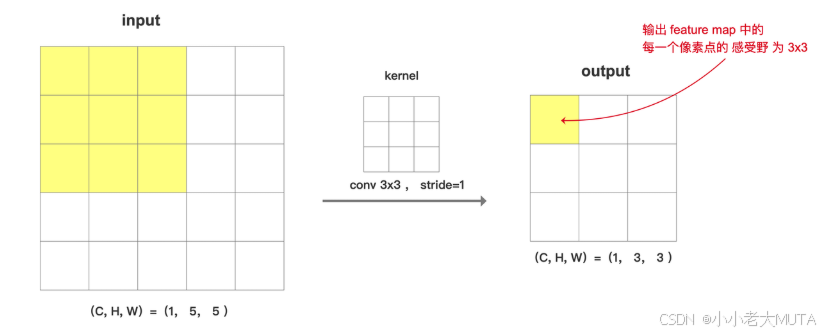
计算公式
