
论文地址 :https://arxiv.org/abs/2107.09428
摘要
非自回归 (NAR) 模型在语音处理中越来越受到关注。 凭借最新的基于注意力的自动语音识别 (ASR) 结构,与自回归 (AR) 模型相比,NAR 可以在仅精度略有下降的情况下实现有前景的实时因子 (RTF) 提升。 然而,识别推理需要等待完整语音话语的完成,这限制了其在低延迟场景中的应用。 为了解决这个问题,我们提出了一种新颖的端到端流式 NAR 语音识别系统,该系统结合了分块注意力和带有掩码预测 (Mask-CTC) NAR 的连接主义时间分类。 在推理过程中,输入音频被分成小的块,然后以分块流式的方式进行处理。 为了解决每个块输出边缘处的插入和删除错误,我们应用了一种带有动态映射技巧的重叠解码策略,该策略可以生成更连贯的句子。 实验结果表明,与普通的 Mask-CTC 相比,该方法在低延迟条件下提高了在线 ASR 识别率。 此外,与基于 AR 注意力的模型相比,它可以实现更快的推理速度。 我们所有的代码都将在 https://github.com/espnet/espnet 公开发布。
关键索引词:非自回归语音识别,流式 ASR,分块注意力,Mask-CTC
1、引言
在过去几年中,深度学习的进步极大地提高了端到端 (E2E) 自动语音识别 (ASR) 的性能 1, 2, 3。 大多数这些 E2E-ASR 研究都是基于自回归 (AR) 模型,并且它们取得了最先进的性能 4。 然而,AR 模型的一个缺点是推理时间随着输出长度线性增加。 近年来,非自回归 (NAR) 模型在序列到序列任务中越来越受到关注,包括机器翻译5, 6, 7、语音识别 (ASR)1, 8, 9, 10, 11和语音翻译12。 与自回归 (AR) 模型相比,NAR 模型可以同时预测输出符元,其推理速度比 AR 模型快得多。 特别是,连接时序分类 (CTC) 是一种流行且简单的 NAR 模型1, 6。 然而,CTC 对预测的符元之间作出了强烈的条件独立性假设,导致其性能不如基于 AR 注意力的模型13。
为了克服这个问题,ASR 领域提出了一些 NAR 研究。 A-FMLM14 旨在根据未掩码的符元和输入语音预测掩码符元。 然而,它需要首先预测输出长度,这很困难,并且容易导致较长的输出序列。 Imputer 8 直接使用输入特征序列的长度来解决问题并与AR模型达到可比性的性能,但是计算成本可能非常大。 ST-NAR15 使用 CTC 预测目标长度并指导解码。 它速度很快,但与 AR 模型相比,精度下降幅度很大。 与以前的方法不同,Mask-CTC16 首先使用 CTC 的贪婪解码生成输出符元,然后通过掩码预测解码器7细化置信度低的符元。 Mask-CTC 通常预测长度合理的序列,并且可以实现快速的推理速度,比基于 AR 注意力的模型快 7 倍。
除了快速推理之外,延迟也是用于实时语音接口的 ASR 系统需要考虑的重要因素。 之前已经有很多关于基于循环神经网络换能器 (RNN-T)2, 13, 17, 18 的低延迟端到端 ASR 和具有 AR 模型的在线基于注意力的编码器解码器 (AED),例如单调分块注意 (MoChA)19, 20、触发注意21和分块注意22, 23的研究。
受此类在线 AR AED 研究和新兴 NAR 研究趋势的启发,我们提出了一种新颖的端到端流式 NAR 语音识别系统,它结合了分块注意和 Mask-CTC 模型。 在推理过程中,输入音频首先被分割成带有连续块之间50%重叠的小块。CTC首先基于块级注意力编码器的输出,通过高效的贪婪前向遍历预测每个块的初步符元。为了解决CTC输出中经常出现在每个块边界处的插入和删除错误,我们应用了一种动态重叠策略24来生成连贯的句子。 然后,低置信度符元被掩盖,并由一个基于其余符元的掩码预测NAR解码器25重新预测。 贪婪CTC、动态重叠解码和掩码预测都运行速度非常快,因此可以实现非常低的实时因子(RTF)。 我们在TEDLIUM2 26和AISHELL1 27上评估了我们的方法。 与普通的全注意力Mask-CTC相比,我们的方法在低延迟条件下降低了在线ASR识别错误率,并且具有非常快的推理速度。 据我们所知,这是第一个将NAR机制扩展到流式ASR的工作。
与其他流式ASR研究的关系
最近流式ASR最重要的成功是RNN-T及其变体。 基于RNN-T的系统实现了流式应用中最先进的ASR性能,并成功部署在生产系统中17, 18, 28, 29。 然而,循环机制使用循环层根据所有之前的符元预测当前输入帧的符元,NAR难以轻松应用于此。 此外,本文中的几个想法受到了在线AR AED架构24, 22, 23的启发,因为它们与基于相似编码器-解码器框架的NAR模型具有更多技术联系。
2、Mask-CTC
Mask-CTC是一个非自回归模型,它使用CTC目标和掩码预测目标进行训练16,其中掩码预测解码器根据CTC输出符元和编码器输出预测掩码符元。 CTC基于帧之间条件独立性的假设预测帧级输入-输出对齐。 它对输出序列的概率进行建模,方法是将所有可能的对齐方式相加,其中 P(Y|X) 表示输出序列,而 Y 表示输入音频。 X 然而,由于条件独立性假设,CTC 失去了对输出符元之间相关性建模的能力,从而导致性能下降。 但是,由于有条件的独立性假设,CTC失去了产出 Token 之间建模相关性和因此失去性能的能力。
Mask-CTC旨在通过采用基于注意力的解码器作为掩盖语言模型(MLM) 7,30 来减轻此问题,并迭代完善CTC贪婪解码的输出。 在训练过程中,真实情况中的标记会被随机选择并替换为特殊的⟨mask⟩符元, 以其余未被掩码的符元为条件, 以及基于注意力的编码器输出。
其中
表示基于多头自注意力的编码器。
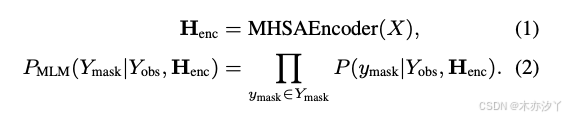
MHSAEncoder(⋅) Mask-CTC 模型通过 CTC 和 MLM 目标的加权和进行优化: Mask-CTC模型通过CTC和MLM目标的加权总和进行了优化:其中 γ 是一个可调超参数。
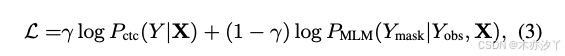
3、流式NAR
所提出的端到端流式NAR语音识别系统的整体架构如图1所示。 与Mask-CTC相比,主要区别在于用分块注意力编码器替换了公式(1)所示的基于普通多头自注意力机制的编码器(例如Transformer/Conformer),从而使模型能够进行流式处理。
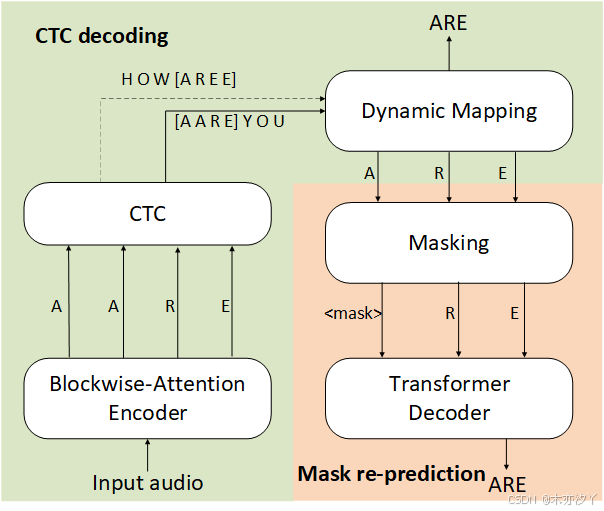 图1: 所提出的流式NAR架构
图1: 所提出的流式NAR架构
3.1、分块注意力编码器
为了构建基于AED的流式ASR系统,编码器只能访问有限的未来上下文。 我们使用基于分块注意力(BA)的编码器22, 23,而不是普通的多头自注意力(MHSA)。 在基于BA的编码器中,输入序列X被分成固定长度的块 ,其中
。 这里 b 是块索引, B 是整个输入中最后一个块的索引,并且 l 是块长度。 在分块注意力的计算中,每个块只关注当前块和前一个块中前一层网络的输出。 第 b 个块定义如下:
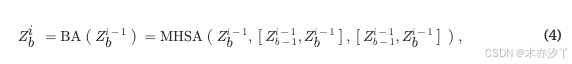
其中 是编码器第 i 个块的输出, b-th block,
的三个参数 MHSA(⋅) 分别是查询、键和值矩阵变量。 同样,Conformer编码器中的分块深度卷积(BDC)定义如下:
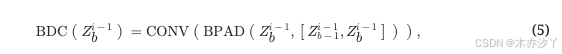
其中 CONV(⋅) 是1D深度卷积,并且 BPAD(⋅) 指的是分块填充,它在右侧边缘填充零,并在 的左侧边缘填充
以保持输入/输出维度相同。 其余操作,例如逐点卷积和激活函数,与Conformer31中的相同。
3.2、分块掩码-CTC
如图1所示,提出的端到端流式NAR语音识别系统由基于分块注意力的编码器、CTC、动态映射过程和MLM解码器组成。 为方便起见,训练过程中我们使用完整的音频作为输入。 但由于编码器的计算是分块进行的,因此一个块内的 CTC 输出仅取决于当前块和前一个块的输入。 本文遵循 NAR 方法,对 CTC 应用贪婪解码,该方法在每个时间步选择概率最高的符元。 贪婪解码 CTC 的每个块的输出为:
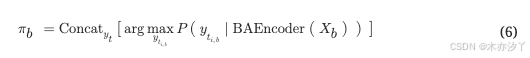
其中 ,
表示第 i 个时间步属于第 b 个块,
BAEncoder 指的是第 3.1节中提到的分块注意力编码器,
在计算过程中被设置为与
大小相同的零矩阵。 同时,真实目标符元被随机掩蔽,并由 MLM 解码器重新预测。
在推理过程中,输入在线分割成具有 50% 重叠的固定长度块,并以流式方式馈送到编码器。 编码器前向传递和 CTC 解码与训练过程相同。 如图 1 所示,虚线表示 CTC 输出 对应于输入块
,实线表示 CTC 输出
的
。 在
和
之间重叠的符元上应用了一种动态映射技巧,以生成连贯的输出。 更多细节将在第3.3节中展示。 然后,来自 CTC 解码输出的置信度分数低的符元,
,被屏蔽并由 MLM 解码器重新预测。 预测过程分多个迭代进行。 在每次迭代中,将具有较高预测概率的符元填充到被屏蔽的位置,并将重新填充的序列用作下一迭代的输入。
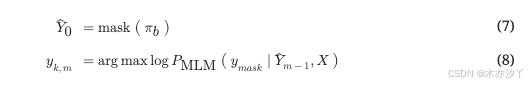
其中 Y0^ 表示来自 CTC 输出的被屏蔽的符元序列, m 表示重新预测的迭代次数, yk,m 表示 k 第 mth 次迭代中重预测的符元, yk,m 然后被填充到预测的序列中 Y^m−1 在相应的掩蔽位置以形成 mth 预言 Y^m. Y^N 将是最终输N 是迭代的总数。
3.3、用于重叠推断的动态映射
尽管将输入音频分为固定长度是一种直接形成流式ASR的方法,但它将在块边界处导致可怕的性能退化。 一个段边界可能出现在 Token 的中间,导致一个 Token 可能在两个连续的块中具有重复识别或不认可。 基于VAD的细分方法是解决问题的一种方法,但它对阈值敏感并可能导致较大的延迟。
在本文中,我们像 24 中的动态映射技巧一起应用了重叠的推断,以恢复边界处的错误输出,如算法1所示。 在推理期间,我们使用 50% 分割输入音频时重叠,这可以确保由编码器和CTC预测输入音频的任何框架。 通过定位符元索引在 最接近于中心点的位置,
我们动态搜索(
和
). 正规化指的是从CTC输出中去除重复和空白符元
。遵循评分函数:
,我们选择最佳对齐路径上符元对中的一个符元作为重叠段的输出。 这里
指的是 j-th个符元在 b-th 块中,而 l 是块长度。
 算法1 、CTC重叠解码和动态映射
算法1 、CTC重叠解码和动态映射
4、实验
4.1、实验设置和数据集
我们评估了有关中文和英语语音语料库的提议模型:tedlium2 26 和aishell1 27 。 对于所有实验,输入特征为80维对数梅尔滤波器组,并包含基于25毫秒帧长和10毫秒帧移计算的基音特征。我们使用Kaldi Toolkit 32 进行特征提取。 我们还应用速度扰动(速度= 0.9、1.0、1.1)和频谱增强 33 用于数据增强。 通过全文解码和流解码来评估模型。
所有实验均使用开源,E2E语音处理工具包ESPNET 34,35,31 进行。 编码器首先包含2个CNN块,将输入简单采样至 1/4,然后是12个基于MHSA的层。 在流NAR中,基于BA的层(等式4, 5)在编码器中用于替换MHSA。 解码器具有类似的堆叠块结构,具有6层,只有全注意 Transformer 块。 对于本文中的任何自我发挥作用,我们都会使用 h=4 平行注意力头,尺寸 . 对于馈送层,我们使用维度
并将其应用于激活功能。 在自我注意事项中,在输入 36 中增强了相对位置嵌入。 我们使用 15 作为构象卷积的内核大小。 TEDLIUM2上的模型经过200个时期的训练,Aishell1上的模型接受了150个时期的训练。 评估是在最佳10个检查站的平均模型上进行的。 在解码过程中,我们不整合语言模型。
4.2、结果
表1显示了TEDLIUM2结果,包括DEV/测试集,平均延迟和实时因子(RTF)上的单词错误率(WER)。 在CPU平台(Intel(r)Xeon(R)CPU E5-2686 V4 @ 2.3GHz)上测量了潜伏期和RTF。 我们设置了块长度 l=16,对应于 640MS在子采样之前。 全文评估是在话语级别上完成的,而流式评估是在每个说话者的未分段流音频上完成的。 由于很难用长期未分段的音频来定义延迟,因此我们用Dev计算了平均每条话的平均延迟:

最后一个 Token 发射的时间是模型预测最后一个 Token 的时间戳,语音的结束是通过强迫与外部模型对齐来确定的。 该延迟视为既延迟延迟又是计算时间。 为了进行比较,我们还通过测量每个发音的平均解码时间来报告全文解码的延迟,因为在全文中,在整个音频喂食之前无法启动。
与Mask-CTC相比,所提出的流式NAR模型在流模式下的性能要好得多。 使用构象异构器编码器,Mask-CTC开发的WER为23.5,平均延迟为310ms,而流NAR的延迟为12.1,平均延迟为140ms。 RTF的速度分别比基于AR注意力的模型的速度分别= 1/10 = 1/10。 Mask-CTC模型接受了完整的上下文输入培训,并通过完整的将来的信息更好地工作。 我们可以在流解码模式下观察到显着的降解,这是由于训练和解码过程中的输入不匹配。 另一方面,提出的流媒体NAR只能以较小的未来上下文识别当前框架,因此与流推断非常吻合。 但是,在提出的模型中,WERS从完整上下文模式(从10.4/9.4到12.1/11.7)增加。 原因是在段边界上列出的错误。 从我们的观察结果来看,这些错误可以缓解,但不能完全通过动态映射来解决,即使有较大的块长度也存在。
表2显示了Aishell1上的结果。 由于用于构象异构体和面罩的超参数需要仔细调整,并且在我们的初步实验中很容易拟合模型,因此我们仅在AISHELL1任务上报告 Transformer 结果。 当在流媒体NAR时提供全文时,香草蒙版-CTC在流媒体解码过程中提供了更好的效果,但是在流媒体解码方面更好,但是好处小于TEDLIUM2中的收益。 一个可能的原因是,Aishell1中的训练话语比Tedlium2短得多。 全文的关注还可以获得仅在未来的短暂上下文中识别的能力。
为了了解在不同延迟下流媒体NAR的性能,在表3中,我们比较了teDlium2上的块意见 Transformer (BA-TF)和块关注构象异构体(BA-CF)的WERS。 我们观察到,随着块长度变短,延迟变小,而RTF上升时,由于较短的块需要更多的迭代才能转发整个输入音频。 此外,当块长度从5120ms降低到1280ms时,结果很少会改变。 它表明在流媒体ASR中,更接近的未来上下文比遥远的播放器更活跃。
表1:TEDLIUM2:在dev/test上的WERs、平均延迟和RTF被报告。所有流式解码模式使用640ms输入段。基于注意力的AR和Mask-CTC模型使用传统注意力进行训练,而提出的流式NAR使用块状注意力,块长度为640ms。
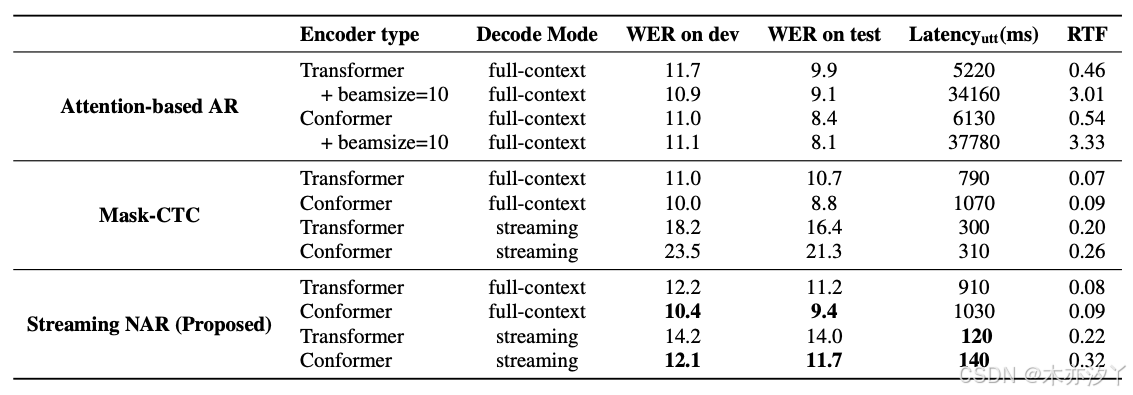
表2:AISHELL1:报告了WERs、平均延迟和RTF。所有流式推理使用1280ms输入段。基于注意力的AR和Mask-CTC模型使用传统注意力,而提出的流式NAR使用块状注意力,块长度为1280ms。
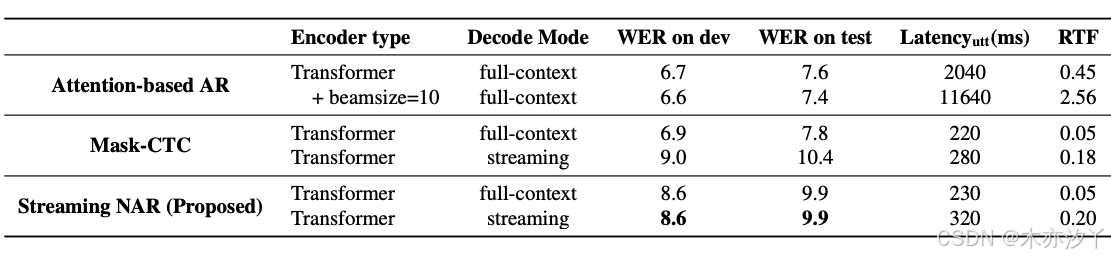
表3:在TEDLIUM2上对提出的具有不同块长度(BL)的流式NAR模型进行的WERs和RTF,所有实验都是在流式模式下进行的。
5、结论
在这篇论文中,我们提出了一种新颖的端到端流式NAR语音识别系统。具体来说,我们结合了基于块状注意力的编码器(Encoder)和Mask-CTC。此外,我们应用了动态重叠推理来减轻边界处的错误。与传统的掩码CTC相比,所提出的流式NAR模型在全文解码方面实现了具有竞争力的性能,并且与传统的掩码CTC流式解码相比,具有非常低的语音延迟。此外,在束宽(beam size)分别为1和10时,所提出模型的解码速度比基于AR注意力的模型分别快约2倍和10倍。我们的未来计划是开发更好的边界定位方法来替代重叠推理,并在解码过程中集成外部语言模型。
6、确认
我们想感谢早稻田大学的Higuch Yusuke先生关于Mask-CTC的有价值信息。
参考
- 1A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, "Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks," in Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369--376.
- 2A. Graves, "Sequence transduction with recurrent neural networks," arXiv preprint arXiv:1211.3711, 2012.
- 3J. Chorowski, D. Bahdanau, K. Cho, and Y. Bengio, "End-to-end continuous speech recognition using attention-based recurrent nn: First results," arXiv preprint arXiv:1412.1602, 2014.
- 4A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu et al. , "Conformer: Convolution-augmented transformer for speech recognition," arXiv preprint arXiv:2005.08100, 2020.
- 5J. Gu, J. Bradbury, C. Xiong, V. O. Li, and R. Socher, "Non-autoregressive neural machine translation," arXiv preprint arXiv:1711.02281, 2017.
- 6J. Libovickỳ and J. Helcl, "End-to-end non-autoregressive neural machine translation with connectionist temporal classification," arXiv preprint arXiv:1811.04719, 2018.
- 7M. Ghazvininejad, O. Levy, Y. Liu, and L. Zettlemoyer, "Mask-predict: Parallel decoding of conditional masked language models," in in Proc. EMNLP-IJCNLP, 2019, pp. 6114--6123.
- 8W. Chan, C. Saharia, G. Hinton, M. Norouzi, and N. Jaitly, "Imputer: Sequence modelling via imputation and dynamic programming," in International Conference on Machine Learning. PMLR, 2020, pp. 1403--1413.
- 9Y. Fujita, S. Watanabe, M. Omachi, and X. Chang, "Insertion-based modeling for end-to-end automatic speech recognition," Proc. Interspeech 2020, pp. 3660--3664, 2020.
- 10E. A. Chi, J. Salazar, and K. Kirchhoff, "Align-refine: Non-autoregressive speech recognition via iterative realignment," arXiv preprint arXiv:2010.14233, 2020.
- 11R. Fan, W. Chu, P. Chang, and J. Xiao, "Cass-nat: Ctc alignment-based single step non-autoregressive transformer for speech recognition," arXiv preprint arXiv:2010.14725, 2020.
- 12H. Inaguma, Y. Higuchi, K. Duh, T. Kawahara, and S. Watanabe, "Orthros: Non-autoregressive end-to-end speech translation with dual-decoder," arXiv preprint arXiv:2010.13047, 2020.
- 13E. Battenberg, J. Chen, R. Child, A. Coates, Y. G. Y. Li, H. Liu, S. Satheesh, A. Sriram, and Z. Zhu, "Exploring neural transducers for end-to-end speech recognition," in 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 206--213.
- 14N. Chen, S. Watanabe, J. Villalba, and N. Dehak, "Listen and fill in the missing letters: Non-autoregressive transformer for speech recognition," arXiv preprint arXiv:1911.04908, 2019.
- 15Z. Tian, J. Yi, J. Tao, Y. Bai, S. Zhang, and Z. Wen, "Spike-triggered non-autoregressive transformer for end-to-end speech recognition," arXiv preprint arXiv:2005.07903, 2020.
- 16Y. Higuchi, S. Watanabe, N. Chen, T. Ogawa, and T. Kobayashi, "Mask ctc: Non-autoregressive end-to-end asr with ctc and mask predict," arXiv preprint arXiv:2005.08700, 2020.
- 17A. Tripathi, J. Kim, Q. Zhang, H. Lu, and H. Sak, "Transformer transducer: One model unifying streaming and non-streaming speech recognition," arXiv preprint arXiv:2010.03192, 2020.
- 18M. Jain, K. Schubert, J. Mahadeokar, C.-F. Yeh, K. Kalgaonkar, A. Sriram, C. Fuegen, and M. L. Seltzer, "Rnn-t for latency controlled asr with improved beam search," arXiv preprint arXiv:1911.01629, 2019.
- 19C.-C. Chiu and C. Raffel, "Monotonic chunkwise attention," arXiv preprint arXiv:1712.05382, 2017.
- 20H. Inaguma, M. Mimura, and T. Kawahara, "Enhancing monotonic multihead attention for streaming asr," arXiv preprint arXiv:2005.09394, 2020.
- 21N. Moritz, T. Hori, and J. Le, "Streaming automatic speech recognition with the transformer model," in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6074--6078.
- 22H. Miao, G. Cheng, C. Gao, P. Zhang, and Y. Yan, "Transformer-based online ctc/attention end-to-end speech recognition architecture," in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6084--6088.
- 23E. Tsunoo, Y. Kashiwagi1, and S. Watanabe, "Streaming transformer asr with blockwise synchronous beam search," in Proc. SLT, 2021, pp. 22--29.
- 24C.-C. Chiu, W. Han, Y. Zhang, R. Pang, S. Kishchenko, P. Nguyen, A. Narayanan, H. Liao, S. Zhang, A. Kannan et al. , "A comparison of end-to-end models for long-form speech recognition," in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 889--896.
- 25Y. Higuchi, H. Inaguma, S. Watanabe, T. Ogawa, and T. Kobayashi, "Improved mask-ctc for non-autoregressive end-to-end asr," arXiv preprint arXiv:2010.13270, 2020.
- 26A. Rousseau, P. Deléglise, Y. Esteve et al. , "Enhancing the ted-lium corpus with selected data for language modeling and more ted talks." in LREC, 2014, pp. 3935--3939.
- 27H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, "Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline," in 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA). IEEE, 2017, pp. 1--5.
- 28B. Li, S.-y. Chang, T. N. Sainath, R. Pang, Y. He, T. Strohman, and Y. Wu, "Towards fast and accurate streaming end-to-end asr," in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6069--6073.
- 29J. Mahadeokar, Y. Shangguan, D. Le, G. Keren, H. Su, T. Le, C.-F. Yeh, C. Fuegen, and M. L. Seltzer, "Alignment restricted streaming recurrent neural network transducer," in 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 52--59.
- 30N. Chen, S. Watanabe, J. Villalba, and N. Dehak, "Nonautoregressive transformer automatic speech recognition," arXiv preprint arXiv:1911.04908, 2019.
- 31P. Guo, F. Boyer, X. Chang, T. Hayashi, Y. Higuchi, H. Inaguma, N. Kamo, C. Li, D. Garcia-Romero, J. Shi et al. , "Recent developments on espnet toolkit boosted by conformer," arXiv preprint arXiv:2010.13956, 2020.
- 32D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely, "The kaldi speech recognition toolkit," in IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, Dec. 2011, iEEE Catalog No.: CFP11SRW-USB.
- 33D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V. Le, "Specaugment: A simple data augmentation method for automatic speech recognition," arXiv preprint arXiv:1904.08779, 2019.
- 34S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y. Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, "ESPnet: End-to-end speech processing toolkit," in Proceedings of Interspeech, 2018, pp. 2207--2211. Online. Available: http://dx.doi.org/10.21437/Interspeech.2018-1456
- 35S. Karita, N. Chen, T. Hayashi, T. Hori, H. Inaguma, Z. Jiang, M. Someki, N. E. Y. Soplin, R. Yamamoto, X. Wang et al. , "A comparative study on transformer vs rnn in speech applications," in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 449--456.
- 36Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. V. Le, and R. Salakhutdinov, "Transformer-xl: Attentive language models beyond a fixed-length context," arXiv preprint arXiv:1901.02860, 2019.