使用modelscope上的图像文本行检测和文本识别模型进行本地部署并转为API服务。
本地部署时把代码中的检测和识别模型路径改为本地模型的路径。
关于模型和代码原理可以参见modelscope上这两个模型相关的页面:
iic/cv_resnet18_ocr-detection-db-line-level_damo
iic/cv_convnextTiny_ocr-recognition-handwritten_damo
部署测试ocr模型的图片:

算力卡信息:
python
ixsmi
Timestamp Wed May 28 17:28:09 2025
+-----------------------------------------------------------------------------+
| IX-ML: 4.1.3 Driver Version: 4.1.3 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------|
| GPU Name | Bus-Id | Clock-SM Clock-Mem |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Iluvatar MR-V50A | 00000000:11:00.0 | 1000MHz 1600MHz |
| 15% 45C P0 19W / 75W | 12290MiB / 16384MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Process name Usage(MiB) |
|=============================================================================|
| 0 2505472 /usr/local/bin/python3 -c from multipro... 864 |
| 0 2503897 python3 ocr_api.py 256 |
| 0 1688541 /usr/local/bin/python3 -c from multipro... 10992 |
+-----------------------------------------------------------------------------+注意:以下ocr模型服务代码与硬件平台无关,只要把依赖软件安装了都能运行,即使cpu也能运行。部署测试过程中可能会报缺软件包的问题,根据提示pip install安装后即可运行。
python
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import JSONResponse
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import uvicorn
import numpy as np
import cv2
import math
from typing import List
from io import BytesIO
# 初始化OCR模型
ocr_detection = pipeline(Tasks.ocr_detection, model='iic/cv_resnet18_ocr-detection-db-line-level_damo')
ocr_recognition = pipeline(Tasks.ocr_recognition, model='iic/cv_convnextTiny_ocr-recognition-handwritten_damo')
app = FastAPI(title="OCR API")
# 工具函数
def crop_image(img, position):
def distance(x1, y1, x2, y2):
return math.sqrt((x1 - x2)**2 + (y1 - y2)**2)
position = position.tolist()
for i in range(4):
for j in range(i + 1, 4):
if position[i][0] > position[j][0]:
position[i], position[j] = position[j], position[i]
if position[0][1] > position[1][1]:
position[0], position[1] = position[1], position[0]
if position[2][1] > position[3][1]:
position[2], position[3] = position[3], position[2]
x1, y1 = position[0]
x2, y2 = position[2]
x3, y3 = position[3]
x4, y4 = position[1]
corners = np.array([[x1, y1], [x2, y2], [x4, y4], [x3, y3]], dtype=np.float32)
width = distance((x1 + x4)/2, (y1 + y4)/2, (x2 + x3)/2, (y2 + y3)/2)
height = distance((x1 + x2)/2, (y1 + y2)/2, (x4 + x3)/2, (y4 + y3)/2)
dst_corners = np.array([[0, 0], [width-1, 0], [0, height-1], [width-1, height-1]], dtype=np.float32)
transform = cv2.getPerspectiveTransform(corners, dst_corners)
dst = cv2.warpPerspective(img, transform, (int(width), int(height)))
return dst
def order_point(coor):
arr = np.array(coor).reshape([4, 2])
centroid = np.mean(arr, axis=0)
theta = np.arctan2(arr[:, 1] - centroid[1], arr[:, 0] - centroid[0])
sort_points = arr[np.argsort(theta)]
if sort_points[0][0] > centroid[0]:
sort_points = np.concatenate([sort_points[3:], sort_points[:3]])
return sort_points.astype('float32')
def sort_boxes(boxes):
def box_center(box):
x = np.mean([p[0] for p in box])
y = np.mean([p[1] for p in box])
return x, y
centers = [box_center(box) for box in boxes]
boxes_with_center = list(zip(boxes, centers))
boxes_with_center.sort(key=lambda x: (x[1][1], x[1][0]))
return [b[0] for b in boxes_with_center]
# 主OCR函数
def ocr_from_bytes(image_bytes: bytes) -> str:
image = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)
det_result = ocr_detection(image)['polygons']
boxes = [order_point(box) for box in det_result]
boxes = sort_boxes(boxes)
lines: List[str] = []
for pts in boxes:
crop = crop_image(image, pts)
text_result = ocr_recognition(crop)
text = text_result['text'] if isinstance(text_result['text'], str) else ''.join(text_result['text'])
lines.append(text)
return '\n'.join(lines)
# FastAPI 路由
@app.post("/ocr")
async def ocr_api(file: UploadFile = File(...)):
try:
image_bytes = await file.read()
result = ocr_from_bytes(image_bytes)
return JSONResponse(content={"text": result})
except Exception as e:
return JSONResponse(content={"error": str(e)}, status_code=500)
# 启动方式(仅用于本地运行时)
# uvicorn ocr_api:app --reload
if __name__ == "__main__":
uvicorn.run("ocr_api:app", host="0.0.0.0", port=8005, reload=True)测试:
python
import requests
# === 1. API 地址 ===
url = "http://localhost:8005/ocr" # 改成你的 API 地址
# === 2. 图片路径 ===
image_path = "ocr_img.jpg" # 本地图片路径
# === 3. 构造请求 ===
with open(image_path, "rb") as f:
files = {'file': f}
response = requests.post(url, files=files)
# === 4. 输出结果 === if response.status_code == 200:
result = response.json()
print("识别结果:", result.get("text")) else:
print(f"请求失败,状态码: {response.status_code}")
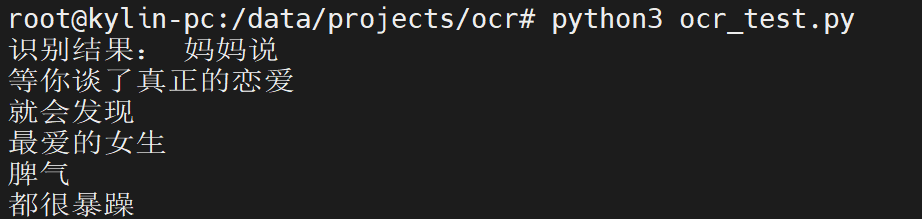
print(response.text)测试结果:
图片:
上面那个"妈妈说..."
测试返回:
约1秒