一、 数据集展示
二、随机数种子
def seed_(seed=42):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark=True # 如果可以接受轻微的不确定性,设置为 True 可以加速训练
torch.backends.cudnn.deterministic=False # 为了完全的可重复性,设置为 True,但可能会降低性能
seed_(42)
三、检测cuda
# 检查是否有可用的 CUDA 设备,并设置设备
if torch.cuda.is_available():
device=torch.device('cuda')
print('cuda') # 输出 'cuda',表明正在使用 CUDA 加速
else:
device=torch.device('cpu')
print('cpu') # 输出 'cpu',表明正在使用 CPU
四、构建数据集
# 定义训练数据的转换
train_transform=transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪到 224x224 的大小
transforms.RandomHorizontalFlip(0.5), # 以 50% 的概率水平翻转图像
transforms.CenterCrop(224), # 中心裁剪到 224x224 的大小
transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) # 使用 ImageNet 的均值和标准差进行标准化
])
# 定义验证数据的转换
val_transform=transforms.Compose([
transforms.Resize((224,224)), # 调整图像大小到 224x224
transforms.RandomHorizontalFlip(0.5), # 以 50% 的概率水平翻转图像
transforms.CenterCrop(224), # 中心裁剪到 224x224 的大小
transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) # 使用 ImageNet 的均值和标准差进行标准化
])
# 加载训练数据集,假设图像数据存储在 './dataset/train' 目录下,并应用训练数据转换
train_dataset=datasets.ImageFolder('./dataset/train',transform=train_transform)
# 加载验证数据集,假设图像数据存储在 './dataset/val' 目录下,并应用验证数据转换
val_dataset=datasets.ImageFolder('./dataset/val',transform=val_transform)
# 创建训练数据的数据加载器,设置批量大小为 16,并打乱数据
train_dataloader=DataLoader(train_dataset,batch_size=16,shuffle=True)
# 创建验证数据的数据加载器,设置批量大小为 16,不打乱数据
val_dataloader=DataLoader(val_dataset,batch_size=16,shuffle=False)
五、数据集可视化
# 可视化训练集中的前 4 张图像及其标签
for i, (img, label) in enumerate(train_dataloader):
if i >= 4:
break
plt.subplot(2, 2, i + 1)
plt.imshow(img[0].permute(1, 2, 0).cpu().numpy()) # 将张量的维度顺序调整为 (C, H, W) -> (H, W, C),并移到 CPU 上转换为 NumPy 数组以进行显示
plt.title(f'Label: {label[0].item()}') # 显示图像对应的标签
plt.axis('off') # 关闭坐标轴
plt.tight_layout() # 调整子图之间的间距,使其更紧凑
plt.show() # 显示图像
六、构建模型
# 加载预训练的 ResNet18 模型,并将其移动到指定的设备上
# model = models.resnet18(pretrained=True).to(device)
# 获取训练集中的类别数量
# num_classes = len(train_dataset.classes)
# 替换 ResNet18 的全连接层,以适应新的类别数量
# model.fc = nn.Linear(model.fc.in_features, num_classes)
# model = model.to(device) # 再次将模型移动到指定的设备上 (以防万一)
# 重新加载 ResNet18 模型,但不加载预训练权重
model = torchvision.models.resnet18(weights=None).to(device)
# 从本地文件加载预训练的权重,只加载权重参数
model.load_state_dict(torch.load('./resnet18-5c106cde.pth', weights_only=True))
# 冻结模型的所有参数,使其不参与梯度计算,实现特征提取
for param in model.parameters():
param.requires_grad = False
# 获取 ResNet18 全连接层的输入特征数量
fc_inputs = model.fc.in_features
# 定义一个新的全连接层序列,用于分类任务
model.fc = nn.Sequential(
nn.Linear(fc_inputs, 256), # 线性层,将输入特征映射到 256 个输出特征
nn.ReLU(), # ReLU 激活函数
nn.Dropout(0.4), # Dropout 层,以 0.4 的概率随机将一部分神经元的输出置为 0,防止过拟合
nn.Linear(256, 10), # 线性层,将 256 个特征映射到 10 个类别 (假设有 10 个类别)
nn.LogSoftmax(dim=1), # LogSoftmax 激活函数,将输出转换为对数概率,常用于多分类任务
).to(device) # 将新的全连接层移动到指定的设备上
七、 损失函数优化器
# 定义损失函数为交叉熵损失,常用于多分类任务
criterion = nn.CrossEntropyLoss()
# 定义优化器为 Adam,使用 0.001 的学习率
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
八、训练模型
# 设置训练的轮数
num_epoch = 5
# 开始训练循环
for epoch in range(num_epoch):
model.train() # 将模型设置为训练模式,启用 dropout 和 batch normalization
total_loss = 0
# 遍历训练数据加载器中的每个批次
for i, (images, labels) in enumerate(train_dataloader):
images = images.to(device) # 将输入图像移动到指定的设备
labels = labels.to(device) # 将标签移动到指定的设备
optimizer.zero_grad() # 清除之前的梯度
outputs = model(images) # 通过模型进行前向传播,得到输出
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
total_loss += loss.item() # 累加批次损失
# 打印每个批次的训练信息
print(f'Epoch [{epoch + 1}/{num_epoch}] Batch [{i + 1}/{len(train_dataloader)}] Loss {loss.item():.4f}')
# 计算每个 epoch 的平均损失
avg_loss = total_loss / len(train_dataloader)
# 打印每个 epoch 的平均损失
if (epoch + 1) % 1 == 0:
print(f'Epoch [{epoch + 1}/{num_epoch}] Loss {avg_loss:.4f}')
九、验证模型
# 模型评估阶段
model.eval() # 将模型设置为评估模式,禁用 dropout 和 batch normalization
correct = 0
total = 0
predicted_labels = []
true_labels = []
# 在评估阶段不需要计算梯度
with torch.no_grad():
# 遍历验证数据加载器中的每个批次
for images, labels in val_dataloader:
images = images.to(device) # 将输入图像移动到指定的设备
labels = labels.to(device) # 将标签移动到指定的设备
outputs = model(images) # 通过模型进行前向传播,得到输出
_, predicted = torch.max(outputs.data, 1) # 获取每个样本的最大概率对应的类别标签
total += labels.size(0) # 累加样本总数
correct += (predicted == labels).sum().item() # 累加预测正确的样本数
predicted_labels.extend(predicted.cpu().numpy()) # 将预测的标签添加到列表中
true_labels.extend(labels.cpu().numpy()) # 将真实的标签添加到列表中
# 打印模型在验证集上的准确率
print(f'Accuracy of the model on test images: {100 * correct / total:.2f}%')
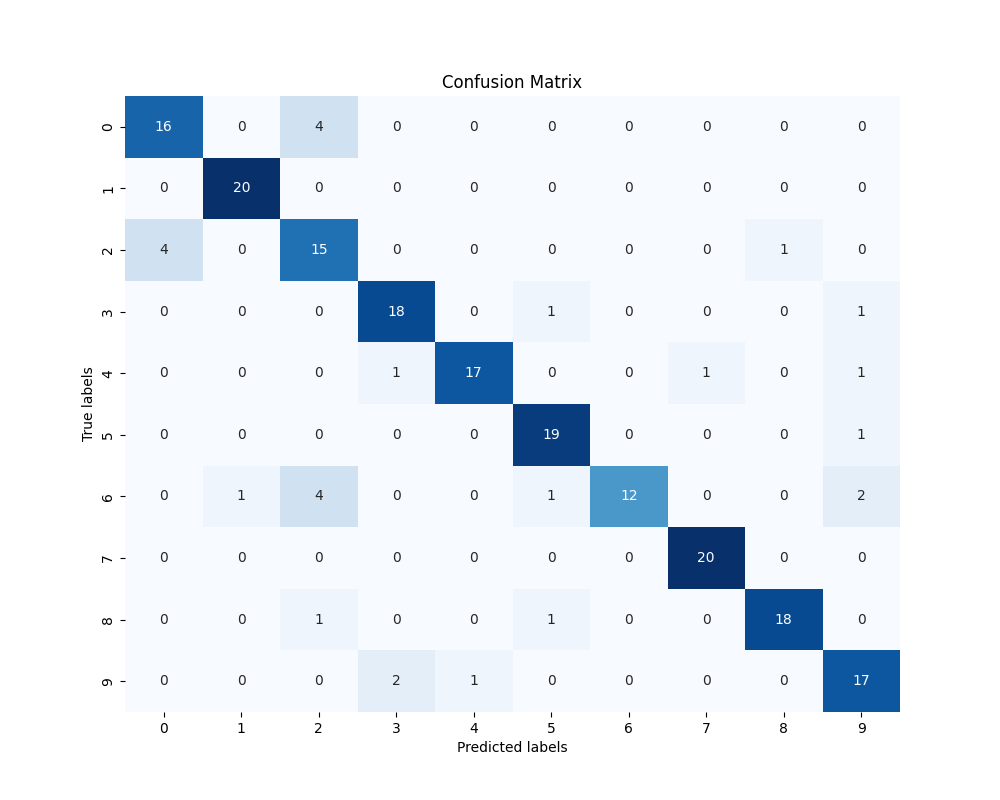
# 可视化,绘制混淆矩阵
conf_matrix = confusion_matrix(true_labels, predicted_labels)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False) # 使用 seaborn 绘制热力图形式的混淆矩阵
plt.xlabel('Predicted labels') # 设置 x 轴标签为 'Predicted labels' (预测标签)
plt.ylabel('True labels') # 设置 y 轴标签为 'True labels' (真实标签)
plt.title('Confusion Matrix') # 设置图标题为 'Confusion Matrix' (混淆矩阵)
plt.show() # 显示混淆矩阵图
十、完整代码
import numpy as np
import torch
import torch.nn as nn
import random
import os
import seaborn as sns
import torchvision
from sklearn.metrics import confusion_matrix
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from torchvision import models
# 设置随机种子,以保证实验的可重复性
def seed_(seed=42):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark=True # 如果可以接受轻微的不确定性,设置为 True 可以加速训练
torch.backends.cudnn.deterministic=False # 为了完全的可重复性,设置为 True,但可能会降低性能
seed_(42)
# 检查是否有可用的 CUDA 设备,并设置设备
if torch.cuda.is_available():
device=torch.device('cuda')
print('cuda') # 输出 'cuda',表明正在使用 CUDA 加速
else:
device=torch.device('cpu')
print('cpu') # 输出 'cpu',表明正在使用 CPU
# 定义训练数据的转换
train_transform=transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪到 224x224 的大小
transforms.RandomHorizontalFlip(0.5), # 以 50% 的概率水平翻转图像
transforms.CenterCrop(224), # 中心裁剪到 224x224 的大小
transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) # 使用 ImageNet 的均值和标准差进行标准化
])
# 定义验证数据的转换
val_transform=transforms.Compose([
transforms.Resize((224,224)), # 调整图像大小到 224x224
transforms.RandomHorizontalFlip(0.5), # 以 50% 的概率水平翻转图像
transforms.CenterCrop(224), # 中心裁剪到 224x224 的大小
transforms.ToTensor(), # 将 PIL 图像或 NumPy 数组转换为 PyTorch 张量
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) # 使用 ImageNet 的均值和标准差进行标准化
])
# 加载训练数据集,假设图像数据存储在 './dataset/train' 目录下,并应用训练数据转换
train_dataset=datasets.ImageFolder('./dataset/train',transform=train_transform)
# 加载验证数据集,假设图像数据存储在 './dataset/val' 目录下,并应用验证数据转换
val_dataset=datasets.ImageFolder('./dataset/val',transform=val_transform)
# 创建训练数据的数据加载器,设置批量大小为 16,并打乱数据
train_dataloader=DataLoader(train_dataset,batch_size=16,shuffle=True)
# 创建验证数据的数据加载器,设置批量大小为 16,不打乱数据
val_dataloader=DataLoader(val_dataset,batch_size=16,shuffle=False)
# 可视化训练集中的前 4 张图像及其标签
for i, (img, label) in enumerate(train_dataloader):
if i >= 4:
break
plt.subplot(2, 2, i + 1)
plt.imshow(img[0].permute(1, 2, 0).cpu().numpy()) # 将张量的维度顺序调整为 (C, H, W) -> (H, W, C),并移到 CPU 上转换为 NumPy 数组以进行显示
plt.title(f'Label: {label[0].item()}') # 显示图像对应的标签
plt.axis('off') # 关闭坐标轴
plt.tight_layout() # 调整子图之间的间距,使其更紧凑
plt.show() # 显示图像
# 加载预训练的 ResNet18 模型,并将其移动到指定的设备上
# model = models.resnet18(pretrained=True).to(device)
# 获取训练集中的类别数量
# num_classes = len(train_dataset.classes)
# 替换 ResNet18 的全连接层,以适应新的类别数量
# model.fc = nn.Linear(model.fc.in_features, num_classes)
# model = model.to(device) # 再次将模型移动到指定的设备上 (以防万一)
# 重新加载 ResNet18 模型,但不加载预训练权重
model = torchvision.models.resnet18(weights=None).to(device)
# 从本地文件加载预训练的权重,只加载权重参数
model.load_state_dict(torch.load('./resnet18-5c106cde.pth', weights_only=True))
# 冻结模型的所有参数,使其不参与梯度计算,实现特征提取
for param in model.parameters():
param.requires_grad = False
# 获取 ResNet18 全连接层的输入特征数量
fc_inputs = model.fc.in_features
# 定义一个新的全连接层序列,用于分类任务
model.fc = nn.Sequential(
nn.Linear(fc_inputs, 256), # 线性层,将输入特征映射到 256 个输出特征
nn.ReLU(), # ReLU 激活函数
nn.Dropout(0.4), # Dropout 层,以 0.4 的概率随机将一部分神经元的输出置为 0,防止过拟合
nn.Linear(256, 10), # 线性层,将 256 个特征映射到 10 个类别 (假设有 10 个类别)
nn.LogSoftmax(dim=1), # LogSoftmax 激活函数,将输出转换为对数概率,常用于多分类任务
).to(device) # 将新的全连接层移动到指定的设备上
# 定义损失函数为交叉熵损失,常用于多分类任务
criterion = nn.CrossEntropyLoss()
# 定义优化器为 Adam,使用 0.001 的学习率
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 设置训练的轮数
num_epoch = 5
# 开始训练循环
for epoch in range(num_epoch):
model.train() # 将模型设置为训练模式,启用 dropout 和 batch normalization
total_loss = 0
# 遍历训练数据加载器中的每个批次
for i, (images, labels) in enumerate(train_dataloader):
images = images.to(device) # 将输入图像移动到指定的设备
labels = labels.to(device) # 将标签移动到指定的设备
optimizer.zero_grad() # 清除之前的梯度
outputs = model(images) # 通过模型进行前向传播,得到输出
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
total_loss += loss.item() # 累加批次损失
# 打印每个批次的训练信息
print(f'Epoch [{epoch + 1}/{num_epoch}] Batch [{i + 1}/{len(train_dataloader)}] Loss {loss.item():.4f}')
# 计算每个 epoch 的平均损失
avg_loss = total_loss / len(train_dataloader)
# 打印每个 epoch 的平均损失
if (epoch + 1) % 1 == 0:
print(f'Epoch [{epoch + 1}/{num_epoch}] Loss {avg_loss:.4f}')
# 模型评估阶段
model.eval() # 将模型设置为评估模式,禁用 dropout 和 batch normalization
correct = 0
total = 0
predicted_labels = []
true_labels = []
# 在评估阶段不需要计算梯度
with torch.no_grad():
# 遍历验证数据加载器中的每个批次
for images, labels in val_dataloader:
images = images.to(device) # 将输入图像移动到指定的设备
labels = labels.to(device) # 将标签移动到指定的设备
outputs = model(images) # 通过模型进行前向传播,得到输出
_, predicted = torch.max(outputs.data, 1) # 获取每个样本的最大概率对应的类别标签
total += labels.size(0) # 累加样本总数
correct += (predicted == labels).sum().item() # 累加预测正确的样本数
predicted_labels.extend(predicted.cpu().numpy()) # 将预测的标签添加到列表中
true_labels.extend(labels.cpu().numpy()) # 将真实的标签添加到列表中
# 打印模型在验证集上的准确率
print(f'Accuracy of the model on test images: {100 * correct / total:.2f}%')
# 可视化,绘制混淆矩阵
conf_matrix = confusion_matrix(true_labels, predicted_labels)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False) # 使用 seaborn 绘制热力图形式的混淆矩阵
plt.xlabel('Predicted labels') # 设置 x 轴标签为 'Predicted labels' (预测标签)
plt.ylabel('True labels') # 设置 y 轴标签为 'True labels' (真实标签)
plt.title('Confusion Matrix') # 设置图标题为 'Confusion Matrix' (混淆矩阵)
plt.show() # 显示混淆矩阵图