参考视频:数字变矩阵
上一节课,我们已经把训练样本文字转成的数字,也就是Token化

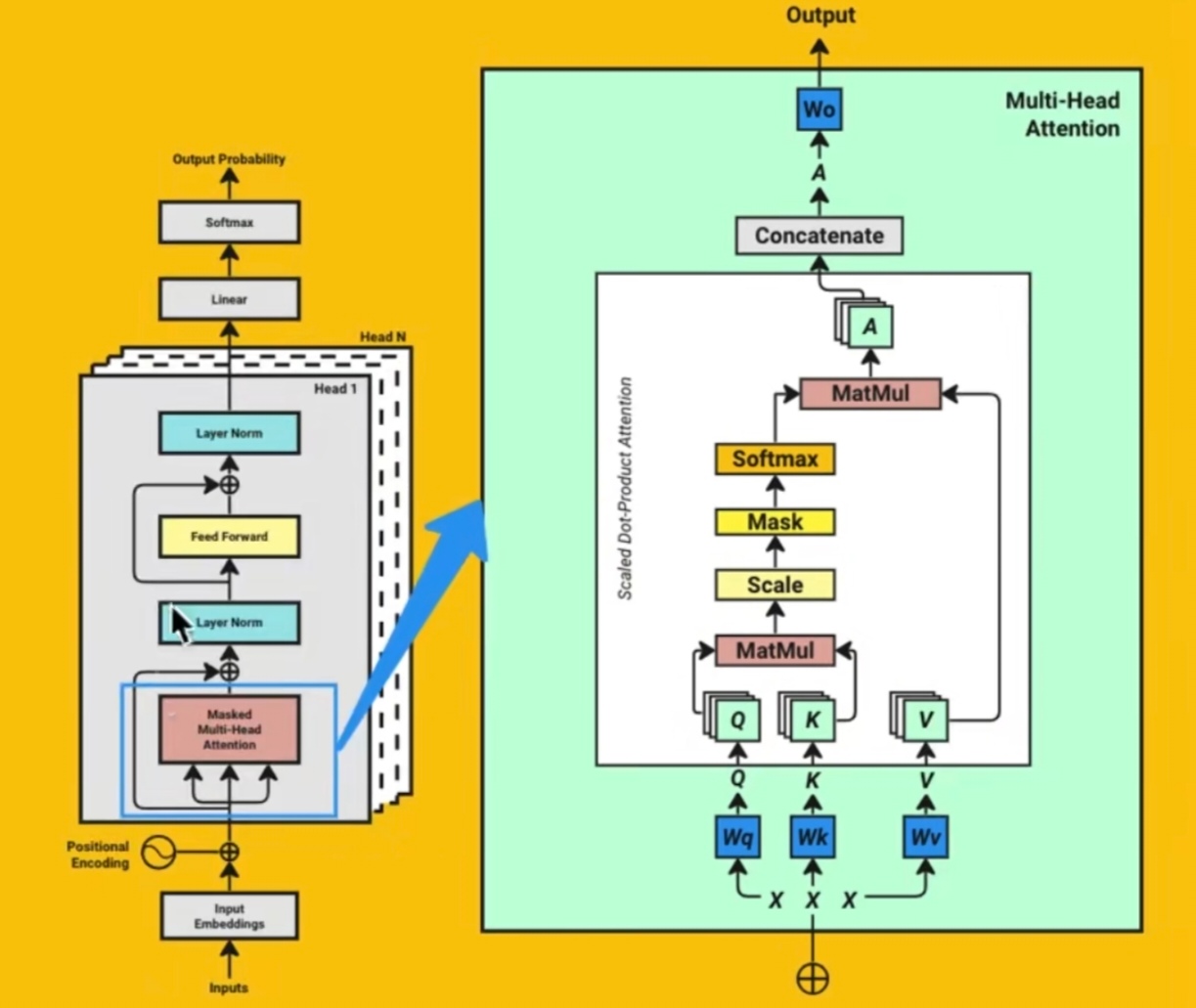
那么在下一步之前,我们要把我们转成的数字,做一次嵌入向量的变换
上一节课,我们知道我们用的的词汇表整体的量是100256,那么每一个数字,分别代表了一个文字。0代表了感叹号,一是冒号,二是引号,然后我们的1000是"好",还有其他的代表更多的,最后一个100255呢,代表是个英文单词叫Conveyor。
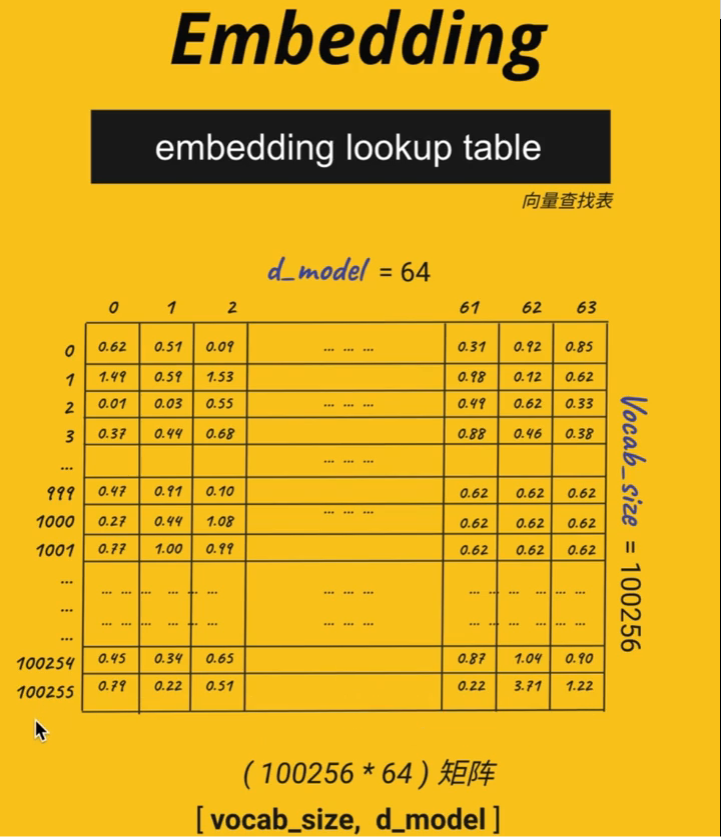
那么,我们实际上并不是把这些数字丢给模型去训练,而我们要找到一些代替这些数字的、一些更小的数字,为什么呢?因为在今后的训练当中,我们要做很多这种乘法,那么如果是数字很小、或者很大的时候,它们乘完之后,小的变得更小,大的变得更大,特别分散。所以我们要初始化一些非常小、非常集中的这些数字,来代表我们的这个token。
看到这个图之后,这个时候你就要问了,为什么你要有这么多列呢?第一列不就行了吗?找一个单独的数字代表一个单独的token,是不是就可以呢?实际上是可以的。
但是语言的魅力在于语境和语义有多种不同的关系。比如我们说意思的"思"字,比如这个1001就是意思的"思"字。那么在中文里,它有很多的不同语义,这个字,比如说"你是什么意思"、"这个没什么意思"、"那我不好意思"、"你意思意思"、"这什么意思?"... 有很多不同的语境,有的时候它是主语、有时候谓语、有的时候宾语、有的时候介词、有的时候动词、有的时候甚至是个形容词。
因为有不同的语义关系,所以我们每一个token要通过不同的多个子token、或者数字来代表它们在不同语义当中的这个意思。所以呢,我们定义了模型,定义了一个叫做d model这样的一个参数,它是一个超参数。在模型训练的时候,我们可以定义,要学习每一个文字在多少重不同的语境下的这种语义关系。那么在这里,我定义的是64。在ChatGPT当中定义的是512,现在越来越更大了,你可以定义成更多的维度,比如说1024。
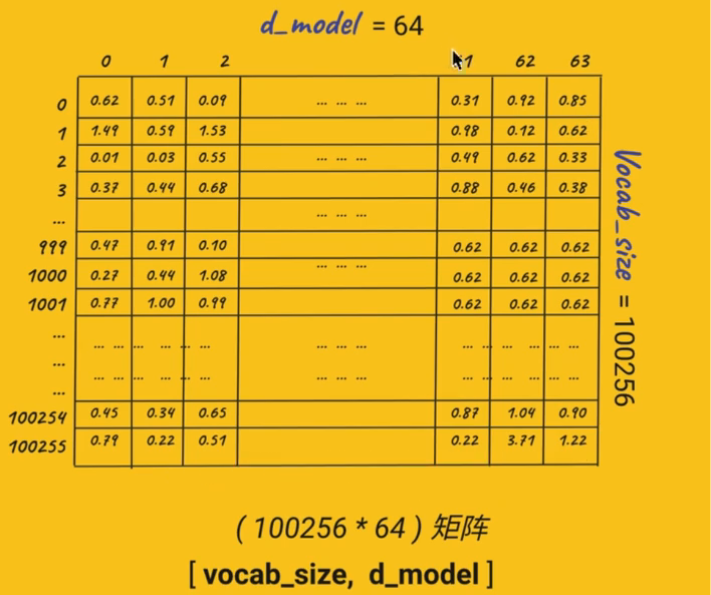
那好,我们现在就用64个维度的d model来做我们的训练的超参数。也就是说我们现在有100255个不同的token,代表了不同的文字,那么每一个文字它有64个不同的语义关系。这样我们就有了一张非常巨大的表格,是一个100256个行和64列这样的一个表格,那么它也叫做一个矩阵。
这个表,是在训练之前,我们只建立一次就可以了。在每一次抽样训练的时候,是可以复用的表格,那这个也叫向量查找表embedding lookup table。使用方法是,当我们每一次抽取样本训练的时候,比如说我们抽取了10个文字,那么10个文字可能对应了十几个不同的token。比如说0的话,我们就把这一行抽出来,我们有十几个字,那就把这十几字对应的token的行都抽出来。
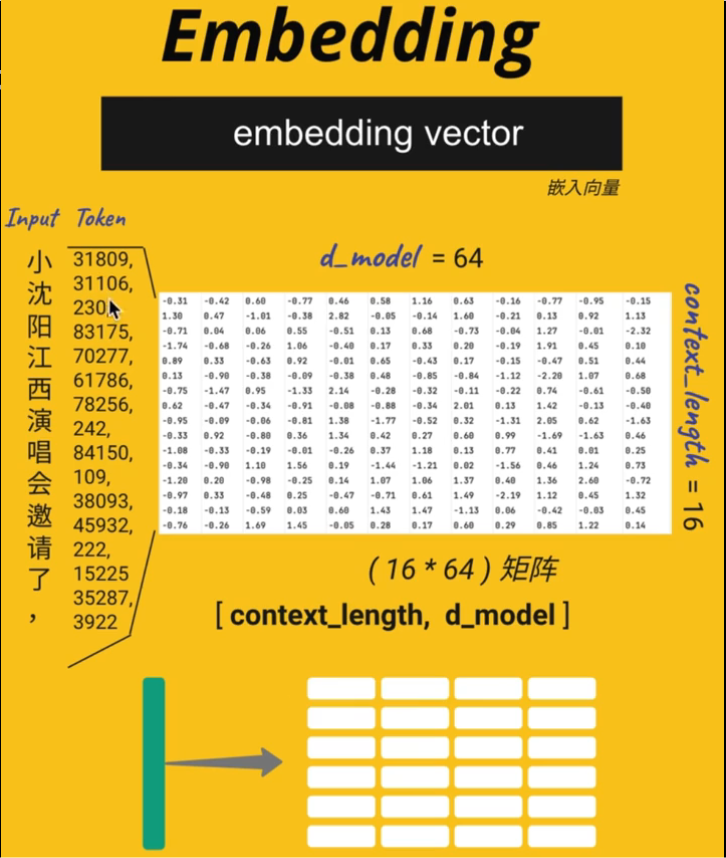
回到例子当中,那我们的input训练的样本数据是"小沈阳江西演唱会邀请了,"这几个字。那么它转换成token之后,一共是有16个token,这个就是我们所谓的context length=16。也就是说,我们在刚才的那个向量查找表里面,把31809的那一行给抽出来,然后把31106那行也给抽出来,一共我们抽了16行,那我们把这个16行给它拼成了一张表,那么它的维度呢,或者说它的列数呢,仍然是我们向量查找表里面的d model是64列,也就是说现在我们这个样本文字,已经转换成了一个16乘以64的一个矩阵,16行每一行都代表了一个token,64列每一列都代表了这个token在一个不同语义下的语境学习的数字。那么也叫做context_length by d_model这样的一个矩阵。
其实我们在做什么呢?其实我们就是把样本文字数字化之后,把我们的token向量转换成了一个矩阵,那么这个就叫做embedding vector。之后,我们要把这个矩阵里面这些数字,丢给我模型去做计算,那么有的人会问,那你这些数字是哪来的?那我可以告诉大家,这些数字都是随机初始化的。在我们有了这个input embedding vector矩阵之后,我们就要把它丢到模型训练了。
那么在扔进模型之前,我们还要做一步,就是加入位置信息编码。请看下一节!!!