一、概述
循环神经网络(Recurrent Neural Network, RNN)是一种专门设计用于处理序列数据(如文本、语音、时间序列等)的神经网络模型。其核心思想是通过引入时间上的循环连接,使网络能够保留历史信息并影响当前输出。
二、模型原理
RNN的关键特点是隐藏状态的循环传递,即当前时刻的输出不仅依赖于当前输入,还依赖于之前所有时刻的信息,这种机制使RNN能够建模序列的时序依赖性。一个隐含层神经元的结构示意图如下
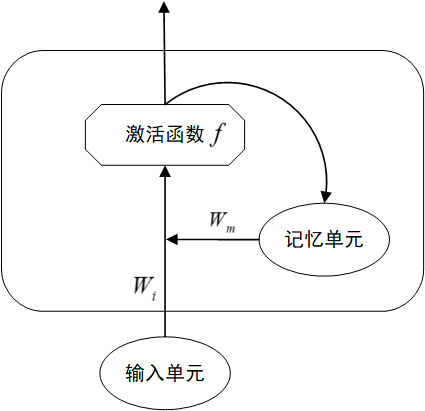
对于时间步\(t\),有
\h_t=\\left( W_xx_t+W_hh_{t-1}+b_h \\right) \\
\y_t=g\\left( W_yh_t+b_y \\right) \\
其中,\(h_t\) 是当前隐含状态,\(x_t\) 是当前输入,\(y_t\) 是当前输出,\(W_x,W_h,W_y\) 是权重矩阵,\(f,g\) 是激活函数。
RNN在时间步上展开后,可视为多个共享参数的重复模块链式连接。序列结构过程如图所示
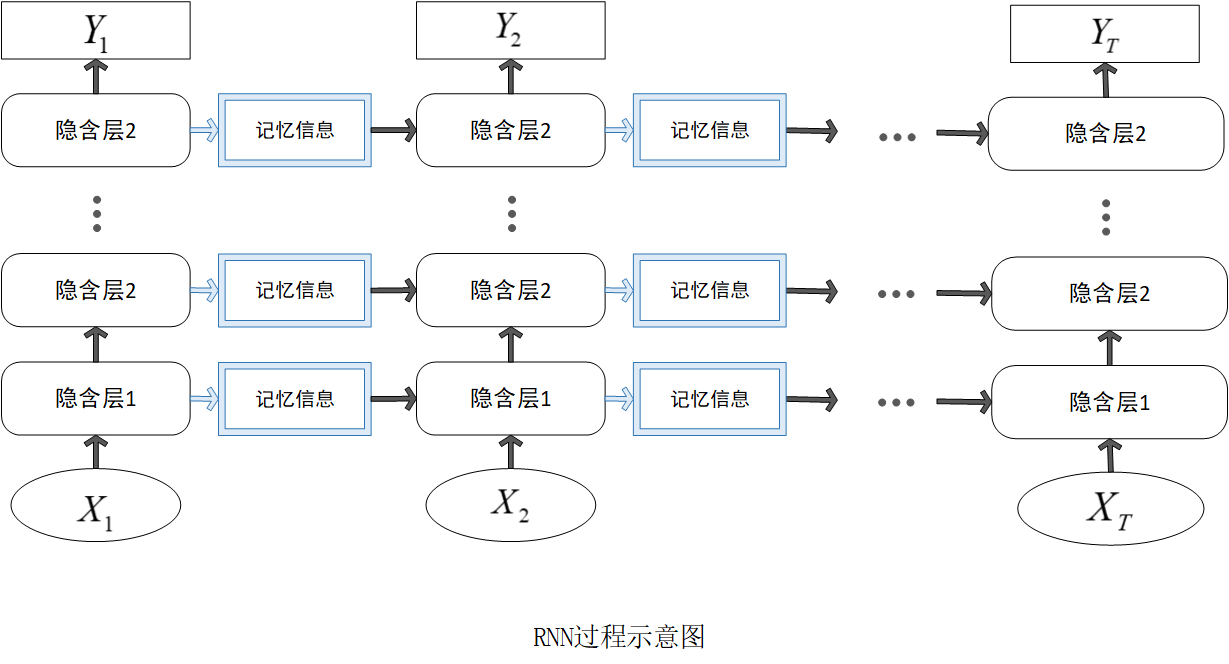
三、优势与局限性
1. 主要优势
参数共享 :所有时间步共享同一组权重,大幅减少参数量。
记忆能力 :隐藏状态能够"记忆",存储历史信息。
灵活输入输出:支持多种序列任务(如一对一、一对多、多对多)。
2. 局限性
梯度问题 :传统RNN难以训练长序列(梯度消失/爆炸)。
计算效率:无法并行处理序列(因时间步需顺序计算)。
四、应用场景
自然语言处理 :语言模型(如 GPT 早期基于 RNN)、文本生成、机器翻译、情感分析。
语音处理 :语音识别(如结合 CTC 损失函数)、语音合成。
时间序列分析 :股票价格预测、传感器数据异常检测、天气预测。
视频处理:视频内容理解(如动作识别,结合 CNN 提取空间特征)。
五、Python实现示例
(环境:Python 3.11,PyTorch 2.4.0)
python
import matplotlib
matplotlib.use('TkAgg')
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import matplotlib.pyplot as plt
# 设置matplotlib的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 'SimHei' 是黑体,也可设置 'Microsoft YaHei' 等
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
# 生成示例时间序列数据
def generate_data(n_samples=1000, seq_length=20):
"""生成简单的正弦波时间序列数据"""
x = np.linspace(0, 10 * np.pi, n_samples + seq_length)
y = np.sin(x)
# 创建序列和目标
sequences = []
targets = []
for i in range(n_samples):
sequences.append(y[i:i + seq_length])
targets.append(y[i + seq_length])
# 转换为PyTorch张量
sequences = torch.FloatTensor(sequences).unsqueeze(2) # [样本数, 序列长度, 特征数]
targets = torch.FloatTensor(targets).unsqueeze(1) # [样本数, 1]
# 分割训练集和测试集
train_size = int(0.8 * n_samples)
train_data = TensorDataset(sequences[:train_size], targets[:train_size])
test_data = TensorDataset(sequences[train_size:], targets[train_size:])
return train_data, test_data
# 定义RNN模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# RNN层
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# 全连接输出层
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# 前向传播RNN
out, _ = self.rnn(x, h0)
# 我们只需要最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
# 训练函数
def train_model(model, train_loader, criterion, optimizer, device, epochs=100):
model.train()
for epoch in range(epochs):
total_loss = 0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {total_loss / len(train_loader):.4f}')
# 评估函数
def evaluate_model(model, test_loader, device):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
predictions.extend(outputs.cpu().numpy())
actuals.extend(targets.cpu().numpy())
return np.array(predictions), np.array(actuals)
# 主函数
def main():
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 超参数
input_size = 1 # 输入特征维度
hidden_size = 64 # 隐藏层维度
num_layers = 1 # RNN层数
output_size = 1 # 输出维度
seq_length = 20 # 序列长度
batch_size = 32 # 批次大小
learning_rate = 0.001 # 学习率
# 生成数据
train_data, test_data = generate_data(seq_length=seq_length)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size)
# 初始化模型
model = SimpleRNN(input_size, hidden_size, num_layers, output_size).to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
print("开始训练模型...")
train_model(model, train_loader, criterion, optimizer, device)
# 评估模型
print("评估模型...")
predictions, actuals = evaluate_model(model, test_loader, device)
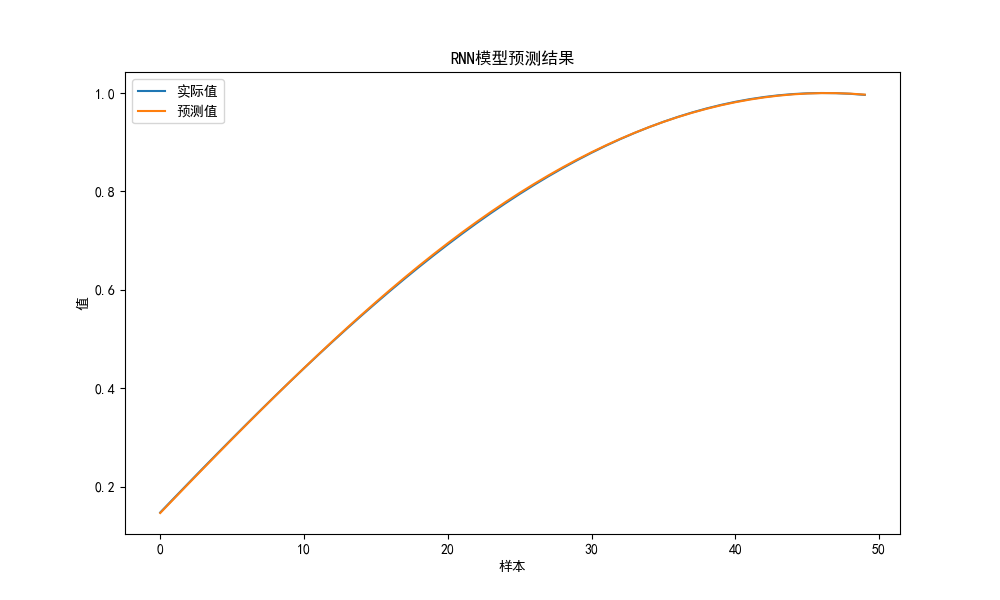
# 可视化结果
plt.figure(figsize=(10, 6))
plt.plot(actuals[:50], label='实际值')
plt.plot(predictions[:50], label='预测值')
plt.title('RNN模型预测结果')
plt.xlabel('样本')
plt.ylabel('值')
plt.legend()
plt.show()
if __name__ == "__main__":
main()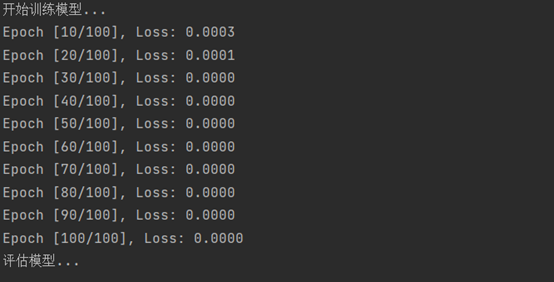
示例实现过程包括以下几个部分:
数据生成 :创建了一个简单的正弦波时间序列数据集,用于训练和测试模型。
模型架构 :定义了一个简单的 RNN 模型,包含一个 RNN 层处理序列输入、一个全连接层将 RNN 的输出映射到预测值
训练流程 :实现了完整的训练循环,包括前向传播、计算损失、反向传播和参数更新。
评估和可视化:训练完成后,模型在测试数据上进行评估,并可视化预测结果与实际值的对比。
示例展示了 RNN 在时间序列预测任务中的基本用法。可以通过调整超参数(如隐藏层大小、学习率、RNN 层数等)来优化模型性能,也可将此框架应用到其他序列数据相关的预测任务中。
End.