简述
理解情感状态对于开发下一代人机交互界面至关重要。社交互动中的人类行为会引发受感知输入影响的心理生理过程。因此,探索大脑功能与人类行为的努力或将推动具有类人特质人工智能模型的发展。这里原作者推出一个多模态情感数据集,包含42名参与者的30通道脑电图(EEG)、音频和视频记录数据。每位参与者均参与基于线索的对话情境,诱发五种特定情绪:中性、愤怒、快乐、悲伤及平静。实验过程中,每位参与者完成200次涵盖倾听与表达的双向互动,全体参与者累计产生8,400次互动样本。采用成熟的深度神经网络(DNN)方法,对各模态的情感识别性能进行了基线评估。EEG-音频-视觉情感(EAV)数据集作为首个公开的对话情境三模态情感识别数据集,有望从基础神经科学与机器学习双重视角,为人类情感过程建模研究作出重要贡献。
情绪识别系统主要依赖于 EEG/Audio/Video 频谱中的单一主要模式。例如,Soleymani 等人 报告的一项研究。6尽管还记录了音频和视频数据,但只关注 EEG 的准确性。尽管他们同时测量了脑电图和视听数据,但他们的分析主要突出了一种模式的性能13,14 元.Koelstra 等人的研究。12还测量了脑电图和视觉数据;然而,大量使用视觉数据是不合适的,因为该范式是为观看视频剪辑等被动任务而设计的,其中视觉提示不会动态地吸引参与者。表 1 提供了使用多种模式解决情绪识别的相关论文摘要,这些论文与我们的研究相关。它包括关键信息,例如数据库标题、主要模态、音频/视频刺激的语言、受试者的启发方法和刺激类型。有趣的是,之前没有研究涉足将脑电图与面部或音频信号同时用于对话环境中的情绪识别。
Table 1 The performance of emotion recognition was evaluated in each modality (EEG, Visual, and Audio data).
From: EAV: EEG-Audio-Video Dataset for Emotion Recognition in Conversational Contexts
| Database | Primary Modalities | Language | Subjects | Elicitation Method | Types |
|---|---|---|---|---|---|
| MAHNOB-HCI6 | EEG, Face, Audio | --- | 27 subjects | Videos/Pictures | S, I |
| SEED-IV11 | EEG and EM | --- | 15 subjects | Videos | S, I |
| DREAMER10 | EEG & ECG | --- | 23 subjects | Movies | S, I |
| MPED9 | EEG, GSR, RR, ECG | --- | 23 subjects | Videos | S, I |
| ASCERTAIN8 | EEG, ECG and GSR | --- | 58 subjects | Videos | S, I |
| AMIGOS7 | EEG, GSR and ECG | --- | 40 subjects | Movies | S, I |
| DEAP12 | EEG, PS, Face | --- | 32 subjects | Music videos | S, I |
| IEMOCAP15 | Face, Speech, Head | English | 10 professional actors | Conversations | S, I |
| SEMAINE16 | Face, Speech | English | 150 subjects | Conversations | S, I |
| NNIME19 | Audio, Video, ECG | Chinese | 44 subjects | Conversations | P, N |
| RAVDESS20 | Audio, Video | English | 24 professional actors | Speech, Song | P, I |
| BAUM-121 | Face, Speech | Turkish | 31 subjects | Images/Videos | S, I |
| SAVEE26 | Face, Speech | English | 4 subjects | Videos/Texts/Pictures | S, I |
| K-EmoCon14 | Face, Speech, 1ch EEG | Korean | 32 subjects | Conversations (Debate) | S, N |
| PEGCONV13 | EEG, GSR, PPG | English | 23 subjects | Conversations | S, N |
| EAV (ours) | EEG (30ch), Audio, Video | English | 42 subjects | Conversations | S, I |
- Specifically, accuracy and AUC scores for 5 balanced classes were calculated across individual subjects.
研究的目的是引入一个多模态数据集,旨在促进对人类情绪行为的更全面理解。这是通过分析通过脑电图 (EEG) 的直接神经元信号和从视听来源获得的间接线索来实现的。为了创建这个数据集,建立了一个对话设置,参与者在筛选过程中自愿选择与目标情绪显著相关的脚本。随后,这些参与者与基于提示的对话系统进行交互,通过面部提示和语音调节来表达他们的情绪。总共有 42 名参与者参与了这项研究,他们的反应是使用 30 通道脑电图和视听记录捕获的。每种情绪的试验都经过深思熟虑的平衡,以确保在广泛的情绪范围内得到精确表示。
数据集信息
EAV (EEG-Audio-Video) 数据集是一个用于情绪识别的多模态数据集,涵盖了 30 通道脑电图(EEG)、音频和视频记录数据。该数据集来自 42 名参与者,他们在实验中参与了基于提示的对话场景,旨在引发五种不同的情绪:中性(Neutral)、愤怒(Anger)、快乐(Happiness)、悲伤(Sadness)和平静(Calmness)。每位参与者参与了 200 次互动,包括听取和回应对话的场景,整个数据集包含 8,400 次互动记录。研究还通过深度神经网络(DNN)方法,基于每种模态评估了情绪识别的基线性能。
EAV 数据集是首个在对话情境中结合 EEG、大脑活动、音频及视频信号的公开情绪识别数据集,旨在帮助理解人类情绪过程,并推动神经科学和机器学习领域的研究。
实验设计
实验包括两部分:
-
筛选阶段
:参与者根据提示选择最能引发情绪的对话脚本,筛选出适合自身情绪反应的对话。
-
主要实验
:参与者观看预先录制的视频,并根据提示进行对话,每次对话持续 20 秒。每轮实验包括 20 次互动,分别对应不同的情绪类别。
数据集基本信息
| 任务类型 | 语言 | EEG 采样率 | 数据格式 | EEG 格式 |
|---|---|---|---|---|
| 情绪识别 | 英语 | 500 Hz | .wav, .mp4 | .mat |
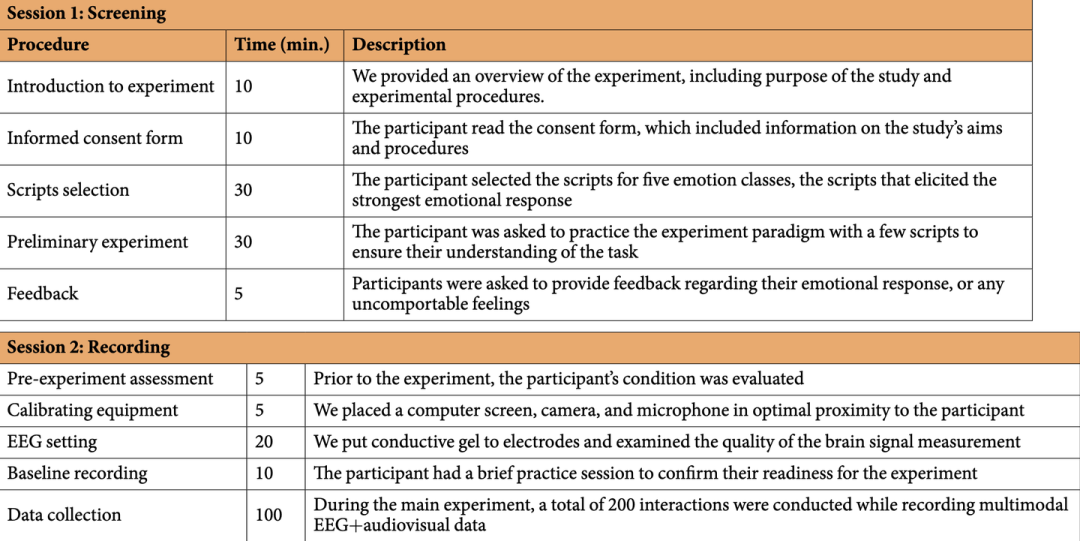
根文件夹 EVA 包含标记为 subject{SUBNUM} 的参与者文件夹,其中 {SUBNUM} 的范围为 1 到 42。每个参与者文件夹包括三个单峰数据文件夹:视频、音频和脑电图(见图 D)。6).
视频数据:"Video"子文件夹包含分段的视频剪辑,每个剪辑的长度为 20 秒。这些剪辑的命名约定为:
-
NUM_INTS:表示实例索引号,范围为 200。
-
NUM_TRIAL:表示每个对话中的试用指数,范围从 1 到 10,对应于 5 次交互。
-
任务:指定正在执行的活动,可以是"正在收听"或"正在说话"。
-
*CLASSNAME:*表示关联的情感类。
一个主题文件夹总共包含 200 个视频剪辑,这些视频剪辑源自 5 个情绪类× 2 个任务× 20 次迭代。
**音频数据:**在"Audio"文件夹中,音频文件遵循与视频文件相同的命名格式,但我们在文件名末尾附加了"_aud"。请务必注意,音频文件只关注 'speaking' 任务,而忽略了 'listening' 任务。这种设计选择是由于录音仅捕获了女演员的声音。总的来说,这个类别的每个主题都有 100 个音频文件,从 5 个类× 1 个任务× 20 个对话 中推断出来。
为了提供直观的理解,单个迭代通常包含后续的三个视频/音频文件:
-
"001_Trial_01_Listening_Neutral.MP4"
-
"002_Trial_02_Speaking_Neutral.MP4"
-
"002_Trial_02_Speaking_Neutral_Aud.WAV"
**脑电图数据:**脑电图数据最初以 Time × Channels 维度连续记录。对于预处理,我们使用五阶 Butter-worth 滤波器和以 50 Hz 进行带通滤波,应用了设置为 0.5Hz 以上的高通滤波器,以减轻面部噪声和电线噪声。随后,使用每个事件(触发器)的时间标记对数据进行分段,从而形成 实例×时间×通道 的结构。
给定 500 Hz 的初始采样率,我们处理后的脑电图数据采用以下结构:200 个实例× 10,000 个时间点(20 秒× 500 Hz)× 30 个通道。
此数据的标签使用 one-hot 编码格式,结构为 200 次试验乘以 10 个类(5 种情绪乘以 2 个任务)。这些文件遵循以下命名约定:
请注意,标签信息可以应用于所有模态,因为所有录音(无论模态如何)都是同步进行的。这可确保整个数据集的注释一致。
缺失数据
在实验过程中,我们遇到了一些挑战,包括设备的技术故障、意外中断以及参与者错过任务的情况等问题。这些缺失的片段,特别是它们发生的迭代,被认真记录下来。随后,在初始实验完成后,这些特定的迭代被重新审视并再次进行。
采用这种方法是为了保持数据完整性,并且重新定位的迭代按正确的顺序放置。因此,整个数据集保持一致的类标签和格式。值得强调的是,所有参与者都有一个平衡的数据集,确保任何参与者的数据格式都没有差异。
数据集统计信息
实验涵盖以下五种情绪类别:
| 标签 | 标签全称 | 中文 |
|---|---|---|
| A | Anger | 愤怒 |
| H | Happiness | 快乐 |
| S | Sadness | 悲伤 |
| C | Calmness | 平静 |
| N | Neutral | 中性 |

参与者和实验者之间情绪评分的比较分析:对四种情绪状态(快乐、悲伤、平静和愤怒)的唤醒和效价水平的研究。N - 所有参与者的评级数据点总数。
数据示例
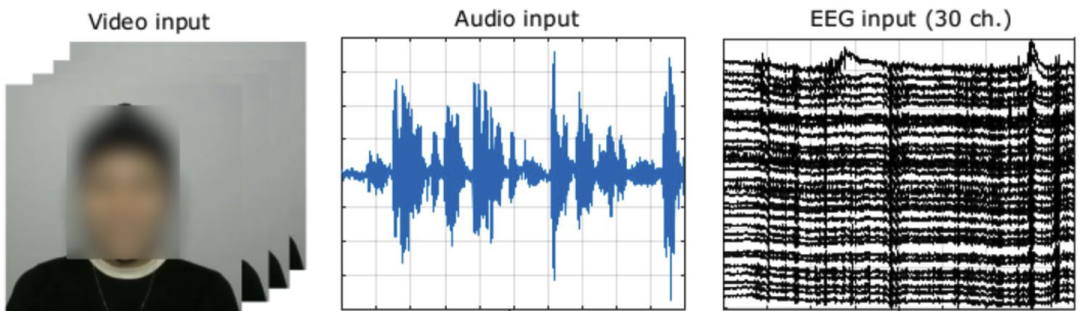
用于情感分类的多模态输入数据及其相应的处理管道。单次试用的持续时间为 5 秒。音频数据经过预处理以创建输入图像,同时将原始视频/EEG 数据馈送到每个 CNN 模型。这些 CNN 模型的结果输出为五种情绪状态提供了 softmax 预测:中性 (N)、快乐 (H)、平静 (C)、愤怒 (A) 和悲伤 (S)。此图中描述的个人提供了公开发布其图像的知情同意。
文件结构
这里使用零样本学习的 EEG 和 Audio-Vision 的多模态联合表示:
自适应多模态瓶颈转换器 (AMBT) 的实现,这是一种新颖的架构,旨在在情绪识别任务中高效地实现 EEG、音频和视觉数据的多模态融合。AMBT 包括两个版本:AMBT-Mean,它应用基于均值的瓶颈标记融合进行多模态集成,以及 AMBT-Concat,它利用基于串联的融合。每种模态(EEG、Audio 和 Vision)都由其自己的专用 Transformer 模型处理,确保最佳特征提取。通过跨模态学习,AMBT 维护了单模态处理管道,同时使较强的模态能够使用隐式对比学习从较弱的模态中提取有意义的信号。对 EAV (EEG-Audio-Vision) 基准数据集的广泛实验证明了多模态融合中最先进的性能。
下载数据
点击此链接获取下载数据集的说明:🔗 https://github.com/nubcico/EAV
如果您想运行可执行代码,请点击此链接(它还包含来自 'pretrained_models' 的大文件):🔗 https://drive.google.com/drive/folders/data_input
项目框架结构(代码)
├── Zero_shot/ # 零样本脑电图(EEG)分类设置│ ├── Transformer_Audio.py # 用于处理音频模态的Transformer模型│ ├── Transformer_EEG.py # 用于处理脑电图(EEG)模态的Transformer模型│ ├── Transformer_Video.py # 用于处理视频模态的Transformer模型│ ├── Zeroshot_setting.py # 零样本学习实验的配置和设置│ ├── main_classwise.py # 用于按类别评估零样本学习的脚本│ ├── main_classwise_visualization.py # 用于可视化按类别零样本学习结果的脚本│ ├── main.py # 运行零样本学习实验的主可执行脚本│ ├── results # 存储模型输出、日志和评估结果的目录├── EAV_Fusion/ # 自适应多模态瓶颈Transformer(AMBT)模型│ ├── Transformer_Audio_mean.py # 音频模态的Transformer模型(AMBT-Mean)│ ├── Transformer_EEG_mean.py # 脑电图(EEG)模态的Transformer模型(AMBT-Mean)│ ├── Transformer_Video_mean.py # 视频模态的Transformer模型(AMBT-Mean)│ ├── Transformer_Audio_concat.py # 音频模态的Transformer模型(AMBT-Concat)│ ├── Transformer_EEG_concat.py # 脑电图(EEG)模态的Transformer模型(AMBT-Concat)│ ├── Transformer_Video_concat.py # 视频模态的Transformer模型(AMBT-Concat)│ ├── AMBT_mean.py # AMBT-Mean融合架构的实现│ ├── AMBT_concat.py # AMBT-Concat融合架构的实现├── pretrained_models # 用于存储预训练模型检查点的目录│ ├── ast-finetuned-audioset # 音频的预处理器配置(请通过上面的链接下载大文件)│ ├── Finetuned_models # 音频、视频和视听数据的微调模型(请通过上面的链接下载大文件)├── data_processing # 用于预处理脑电图 - 音频 - 视觉(EAV)数据集的脚本├── requirements.txt # 项目所需依赖项的列表├── README.md # 项目文档和使用说明└── LICENSE # 存储库的许可信息运行模型安装所需的依赖项:
pip install -r requirements.txt对于 Zero-Shot Learning,请执行主脚本:python Zero_shot/main.py对于 EAV Fusion,您可以从两个版本中进行选择:python Fusion_bottleneck/AMBT_mean.pypython Fusion_bottleneck/AMBT_concat.py
python
import os
import cv2
import numpy as np
import EAV_datasplit
from facenet_pytorch import MTCNN
import torch
class DataLoadVision:
def __init__(self, subject='all', parent_directory=r'C:\Users\minho.lee\Dropbox\EAV', face_detection=False,
image_size=224):
self.IMG_HEIGHT, self.IMG_WIDTH = 480, 640
self.subject = subject
self.parent_directory = parent_directory
self.file_path = list()
self.file_emotion = list()
self.images = list()
self.image_label = list() # actual class name
self.image_label_idx = list()
self.face_detection = face_detection
self.image_size = image_size
self.face_image_size = 56 #
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.mtcnn = MTCNN(
image_size=self.face_image_size, margin=0, min_face_size=20,
thresholds=[0.6, 0.7, 0.7], factor=0.709, post_process=True,
device=self.device
)
def data_files(self):
subject = f'subject{self.subject:02d}'
print(subject, " Loading")
file_emotion = []
subjects = []
path = os.path.join(self.parent_directory, subject, 'Video')
for i in os.listdir(path):
emotion = i.split('_')[4]
self.file_emotion.append(emotion)
self.file_path.append(os.path.join(path, i))
def data_load(self):
for idx, file in enumerate(self.file_path):
nm_class = file.split("_")[-1].split(".")[0] # we extract the class label from the file
if "Speaking" in file and file.endswith(".mp4"):
print(idx)
cap = cv2.VideoCapture(file)
# total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # ~600
# frame_rate = cap.get(cv2.CAP_PROP_FPS) # 30 frame
a1 = []
if cap.isOpened():
frame_index = 1
while True:
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# (30 framerate * 20s) * 100 Speaking, Select every 6th frame from the first 600 frames
# face detection, we converted it into 0-255 again from the [-1 - 1] tensor, you can directly return the tensor
if (frame_index - 1) % 6 == 0 and frame_index <= 600:
if self.face_detection:
with torch.no_grad():
x_aligned, prob = self.mtcnn(frame, return_prob=True)
if prob > 0.3:
x_aligned = (x_aligned + 1) / 2
x_aligned = np.clip(x_aligned * 255, 0, 255)
x_aligned = np.transpose(x_aligned.numpy().astype('uint8'), (1, 2, 0))
a1.append(x_aligned)
else:
print("Face is not detected, original is saved")
a1.append(x_aligned) # incase that face has not been detected, add previous one
pass
else:
resizedImg = cv2.resize(frame, (self.image_size, self.image_size))
a1.append(resizedImg) # sabina: dlkfjefoie
if len(a1) == 25: # 25 frame is 5s each
self.images.append(a1) # this will contain 400 samples [400, 25, (225, 225, 3)]
a1 = []
self.image_label.append(nm_class)
frame_index += 1
cap.release()
else:
print(f"Error opening video file: {file}")
emotion_to_index = {
'Neutral': 0,
'Happiness': 3,
'Sadness': 1,
'Anger': 2,
'Calmness': 4
}
self.image_label_idx = [emotion_to_index[emotion] for emotion in self.image_label]
def process(self):
self.data_files()
self.data_load()
return self.images, self.image_label_idx
if __name__ == '__main__':
for sub in range(1, 20):
print(sub)
file_path = "C:/Users/minho.lee/Dropbox/Datasets/EAV/Input_images/Vision/"
file_name = f"subject_{sub:02d}_vis.pkl"
file_ = os.path.join(file_path, file_name)
#if not os.path.exists(file_):
vis_loader = DataLoadVision(subject=sub, parent_directory=r'C:\Users\minho.lee\Dropbox\Datasets\EAV', face_detection=True)
[data_vis, data_vis_y] = vis_loader.process()
eav_loader = EAV_datasplit.EAVDataSplit(data_vis, data_vis_y)
#each class contains 80 trials, 5/5 radio (h_idx=40), 7/3 ratio (h_dix=56)
[tr_x_vis, tr_y_vis, te_x_vis, te_y_vis] = eav_loader.get_split(h_idx=56) # output(list): train, trlabel, test, telabel
data = [tr_x_vis, tr_y_vis, te_x_vis, te_y_vis]
'''
# Here you can write / load vision features tr:{280}(25, 56, 56, 3), te:{120}(25, 56, 56, 3): trials, frames, height, weight, channel
import pickle
Vis_list = [tr_x_vis, tr_y_vis, te_x_vis, te_y_vis]
with open(file_, 'wb') as f:
pickle.dump(Vis_list, f)
# You can directly work from here
with open(file_, 'rb') as f:
Vis_list = pickle.load(f)
tr_x_vis, tr_y_vis, te_x_vis, te_y_vis = Vis_list
data = [tr_x_vis, tr_y_vis, te_x_vis, te_y_vis]
'''
# Transformer for Vision
from Transformer_torch import Transformer_Vision
mod_path = os.path.join('C:\\Users\\minho.lee\\Dropbox\\Projects\\EAV', 'facial_emotions_image_detection')
trainer = Transformer_Vision.ImageClassifierTrainer(data,
model_path=mod_path, sub=f"subject_{sub:02d}",
num_labels=5, lr=5e-5, batch_size=128)
trainer.train(epochs=10, lr=5e-4, freeze=True)
trainer.train(epochs=5, lr=5e-6, freeze=False)
trainer.outputs_test
# CNN for Vision
from CNN_torch.CNN_Vision import ImageClassifierTrainer
trainer = ImageClassifierTrainer(data, num_labels=5, lr=5e-5, batch_size=32)
trainer.train(epochs=3, lr=5e-4, freeze=True)
trainer.train(epochs=3, lr=5e-6, freeze=False)
trainer._delete_dataloader()
trainer.outputs_test代码主要用于处理脑电图(EEG)、音频和视频数据的多模态融合任务,包含零样本学习和自适应多模态瓶颈 Transformer(AMBT)模型两部分,下面详细介绍:
零样本学习(Zero-Shot Learning)部分
- 模型结构
-
Zero_shot/Transformer_Audio.py
:定义了一个用于处理音频数据的视觉 Transformer(ViT)编码器
ViT_Encoder,包含多个模块,如LayerScale、DropPath、Attention、Block、EEG_decoder和PatchEmbed。该编码器可以对音频数据进行特征提取,若开启embed_eeg选项,还能处理 EEG 数据。 -
Zero_shot/Transformer_EEG.py
(未提供完整代码,但推测与
EAV_fusion中的 EEG 编码器结构类似):用于处理 EEG 数据,可能包含卷积层、Transformer 层和全连接层,将 EEG 数据转换为特征表示并进行分类。 -
Zero_shot/Transformer_Video.py
(未提供代码):预计用于处理视频数据,可能采用类似的 Transformer 架构对视频特征进行提取和处理。
-
运行脚本
-
Zero_shot/main.py
:主脚本,提供了下载数据的选项,并允许用户选择全类训练(在所有可用类别上进行训练和测试)或零样本测试(在一个未见过的类别上进行测试)。
自适应多模态瓶颈 Transformer(AMBT)模型部分
EEG 编码器
- EAV_fusion/Transformer_EEG_mean.py 和 EAV_fusion/Transformer_EEG_concat.py
-
这两个文件定义了用于处理 EEG 数据的编码器
EEG_Encoder,结构基本相同,仅在TransformerLayer中的endsample层有所差异。 -
包含
PatchEmbedding模块,将输入的 EEG 数据进行嵌入处理;MultiHeadAttention模块,实现多头注意力机制;FeedForwardBlock模块,包含全连接层和激活函数;TransformerLayer模块,将注意力机制和前馈网络结合,并添加残差连接和层归一化。 -
在
forward方法中,先通过卷积层对输入数据进行处理,再经过嵌入和多个 Transformer 层,最后通过池化、归一化、平方、对数等操作,将特征展平并通过全连接层进行分类。
音频编码器
- EAV_fusion/Transformer_Audio_mean.py 和 EAV_fusion/Transformer_Audio_concat.py
-
定义了用于处理音频数据的视觉 Transformer 编码器
ViT_Encoder_Audio,同样包含多个模块,如LayerScale、DropPath、Attention、Block、EEG_decoder和PatchEmbed。 -
两个文件的主要区别在于
Block模块中is_fusion为True时的midsample和endsample层的定义。 -
在
forward方法中,先对输入数据进行嵌入处理,添加分类令牌,再经过多个 Transformer 层,最后通过归一化层。若开启分类器,则通过全连接层进行分类。
预训练模型配置
-
EAV_lab/pretrained_models/ast-finetuned-audioset/config.json:包含音频分类的标签信息,如牙刷、电动牙刷、吸尘器等,这些标签可用于音频数据的分类任务。
整体流程
-
安装依赖
:运行
pip install -r requirements.txt安装项目所需的所有依赖项。 -
零样本学习
:运行
python Zero_shot/main.py,根据提示选择下载数据、训练模式(全类训练或零样本测试)。 -
EAV 融合
:可选择运行
python Fusion_bottleneck/AMBT_mean.py或python Fusion_bottleneck/AMBT_concat.py,对 EEG、音频和视频数据进行融合处理和分类。
综上所述,段代码实现了多模态数据的处理和分类任务,支持零样本学习和自适应多模态瓶颈 Transformer 模型,可用于情感识别等相关领域的研究和应用。
到这里前期的阅读研究笔记就记录完了,觉得有用记得支持一下点赞支持一下,谢谢