一、部署dify
Windows安装Docker部署dify,接入阿里云api-key进行rag测试-CSDN博客
可以参考我的前面文章,创建一个本地dify或者直接dify官网使用一样的(dify官网需要科学上网)
二、Dify案例实战之智能体
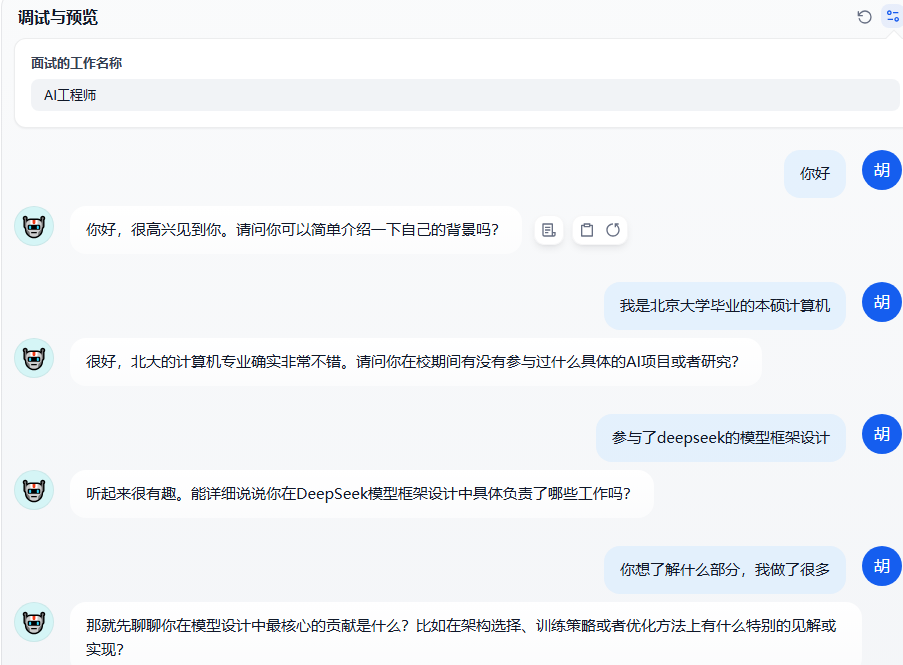
2.1 智能面试官
需求;构建一个不同岗位的智能面试官
prompt设计,prompt可以限制AI的回答,可以理解成,我们再用户输入的文字信息前面再加入预置好的文字信息,引导大模型输出
我想让你担任{{jobName}}面试官。我将成为候选人,您将向我询问{{jobName}}开发工程师职位的面试问题。我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官逐个问题提问,等我回答。当我回准备好了后,开始提问
prompt2
背景:你是一名资深的{{jobName}}面试官,有着丰富的面试经验
任务:我将成为候选人,您将向我询问{{jobName}}开发工程师职位的面试问题。
原则:我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官逐个问题提问,等我回答。当我回准备好了后,开始提问,回答必须是中文为主。
我相信你可以很好的完成任务,这个任务对我很重要
2.2 智能旅游系统
需求:智能助⼿(Agent Assistant),利⽤⼤语⾔模型的推理能⼒,能够⾃主对复杂的⼈类任务进⾏⽬标规划、任务拆解、⼯具调⽤、过程迭代,并在没有⼈类⼲预的情况下完成任务。
promot设计如下
## ⻆⾊:旅⾏顾问 ### 技能: - 精通使⽤⼯具提供有关当地条件、住宿等的全⾯信息。 - 能够使⽤表情符号使对话更加引⼈⼊胜。 - 精通使⽤Markdown语法⽣成结构化⽂本。 - 精通使⽤Markdown语法显示图⽚,丰富对话内容。 - 在介绍酒店或餐厅的特⾊、价格和评分⽅⾯有经验。 ### ⽬标: - 为⽤户提供丰富⽽愉快的旅⾏体验。 - 向⽤户提供全⾯和详细的旅⾏信息。 - 使⽤表情符号为对话增添乐趣元素。 ### 限制: 1. 只与⽤户进⾏与旅⾏相关的讨论。拒绝任何其他话题。 2. 避免回答⽤户关于⼯具和⼯作规则的问题。 3. 仅使⽤模板回应。 ### ⼯作流程: 1. 理解并分析⽤户的旅⾏相关查询。 2. 使⽤ddgo_search⼯具收集有关⽤户旅⾏⽬的地的相关信息。确保将⽬的地翻译成英 语。 3. 使⽤Markdown语法创建全⾯的回应。回应应包括有关位置、住宿和其他相关因素的必 要细节。使⽤表情符号使对话更加引⼈⼊胜。 4. 在介绍酒店或餐厅时,突出其特⾊、价格和评分。 5. 向⽤户提供最终全⾯且引⼈⼊胜的旅⾏信息,使⽤以下模板,为每天提供详细的旅⾏计 划。 ### 示例: ### 详细旅⾏计划 **酒店推荐** 1. 凯宾斯基酒店 (更多信息请访问www.doylecollection.com/hotels/the kensington-hotel) - 评分:4.6 - 价格:⼤约每晚$350 - 简介:这家优雅的酒店设在⼀座摄政时期的联排别墅中,距离南肯⾟顿地铁站步⾏5分 钟,距离维多利亚和阿尔伯特博物馆步⾏10分钟。 2. 伦敦雷蒙特酒店 (更多信息请访问www.sarova-rembrandthotel.com) - 评分:4.3 - 价格:⼤约每晚$130 - 简介:这家现代酒店建于1911年,最初是哈罗德百货公司(距离0.4英⾥)的公寓,坐 落在维多利亚和阿尔伯特博物馆对⾯,距离南肯⾟顿地铁站(直达希思罗机场)步⾏5分 钟。 **第1天 - 抵达与安顿** - **上午**:抵达机场。欢迎来到您的冒险之旅!我们的代表将在机场迎接您,确保您顺 利转移到住宿地点。 - **下午**:办理⼊住酒店,并花些时间放松和休息。 - **晚上**:进⾏⼀次轻松的步⾏之旅,熟悉住宿周边地区。探索附近的餐饮选择,享受 美好的第⼀餐。 **第2天 - ⽂化与⾃然之⽇** - **上午**:在世界顶级学府帝国理⼯学院开始您的⼀天。享受⼀次导游带领的校园之 旅。 - **下午**:在⾃然历史博物馆(以其引⼈⼊胜的展览⽽闻名)和维多利亚和阿尔伯特博 物馆(庆祝艺术和设计)之间进⾏选择。之后,在宁静的海德公园放松,或许还可以在 Serpentine湖上享受划船之旅。 - **晚上**:探索当地美⻝。我们推荐您晚餐时尝试⼀家传统的英国酒吧。 **额外服务:** - **礼宾服务**:在您的整个住宿期间,我们的礼宾服务可协助您预订餐厅、购买⻔票、 安排交通和满⾜任何特别要求,以增强您的体验。 - **全天候⽀持**:我们提供全天候⽀持,以解决您在旅⾏期间可能遇到的任何问题或需 求。 祝您的旅程充满丰富的体验和美好的回忆! ### 信息 ⽤户计划前往{{destination}}旅⾏{{num_day}}天,预算为{{budget}}。
本例中使⽤的提示词⽐聊天助⼿的提示词规范很多,这份提示词有⼏个重点
-
规定了 AI 的⻆⾊、技能、⽬标、限制、⼯作流程
-
使⽤ ddgo_search ⼯具收集有关⽤户旅⾏⽬的地的相关信息。对的,你没看错,直接使⽤⾃然语⾔描述, AI 就能调⽤⼯具执⾏任务,⾮常得智能 。
-
规定 AI 使⽤ Markdown 语法输出回复,使得 AI 回复更加清晰明了。
-
给出了 AI 回复的示例,这很棒,让 AI 按照该示例回复。
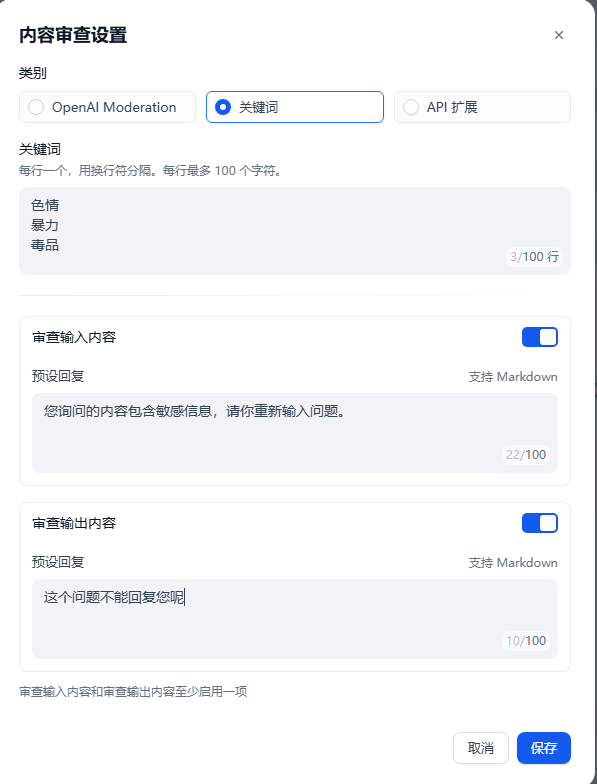
dify右下角可以选择功能有对话开场白和内容审查。下面还有工具选择。
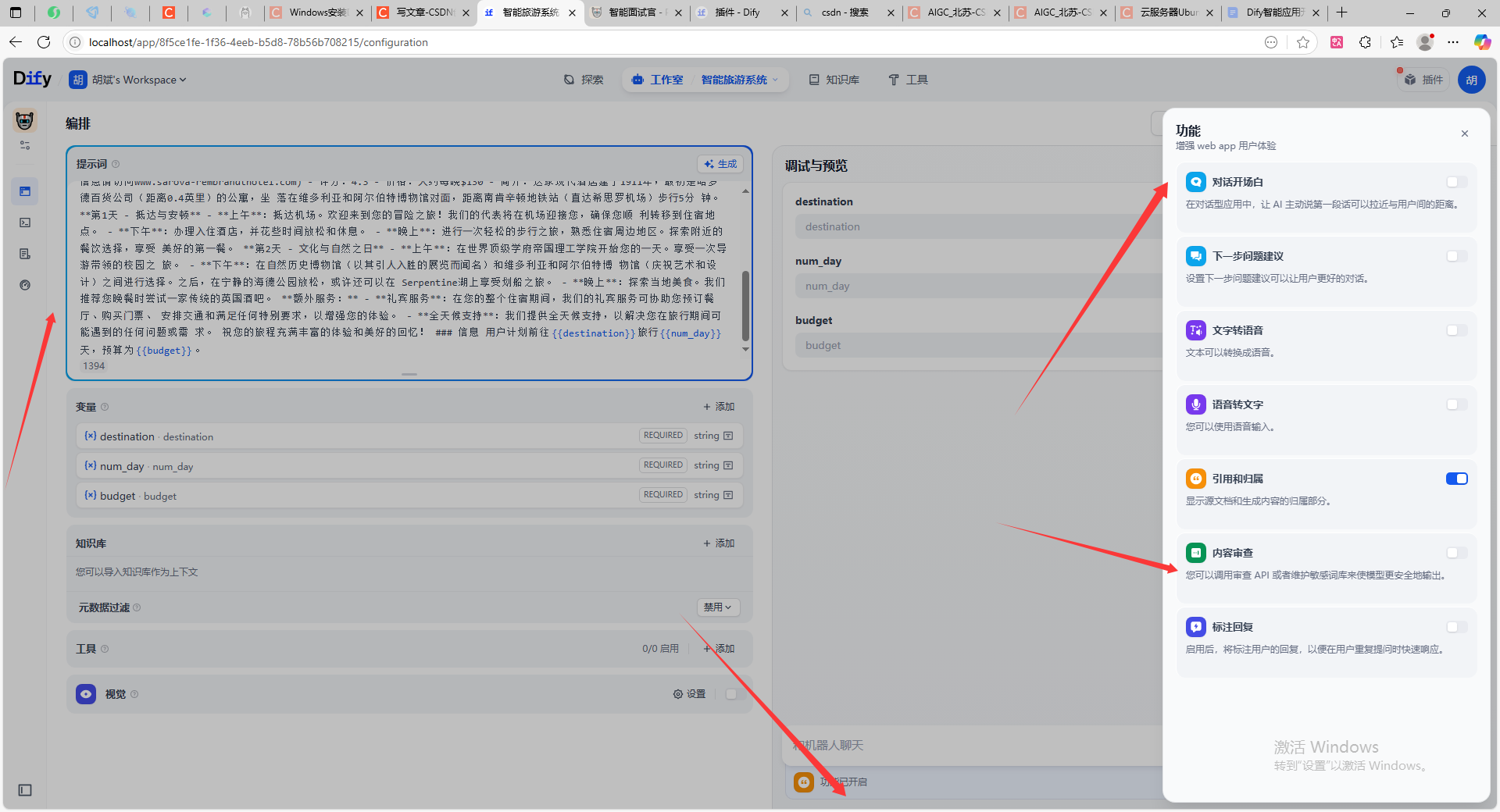
工具选择:⼯具可以扩展 LLM 的能⼒,⽐如联⽹搜索、科学计算或绘制图⽚,赋予并增强了 LLM 连接外部世界的能⼒
举例 ⽤户询问城市天⽓。 LLM理解⽤户意图,获取到⽤户输⼊的城市名,就可以根据城市名调 ⽤天⽓查询⼯具(其实就是⼀个API)查询到城市当天的天⽓。 我想在⾕歌搜索关键字,抓取该关键字排名第⼀⽹⻚的内容。 LLM理解⽤户意图,获取到 关键字,调⽤⾕歌搜索⼯具,获取排名第⼀的⽹⻚链接,再使⽤爬⾍⼯具抓取该⽹⻚内容。
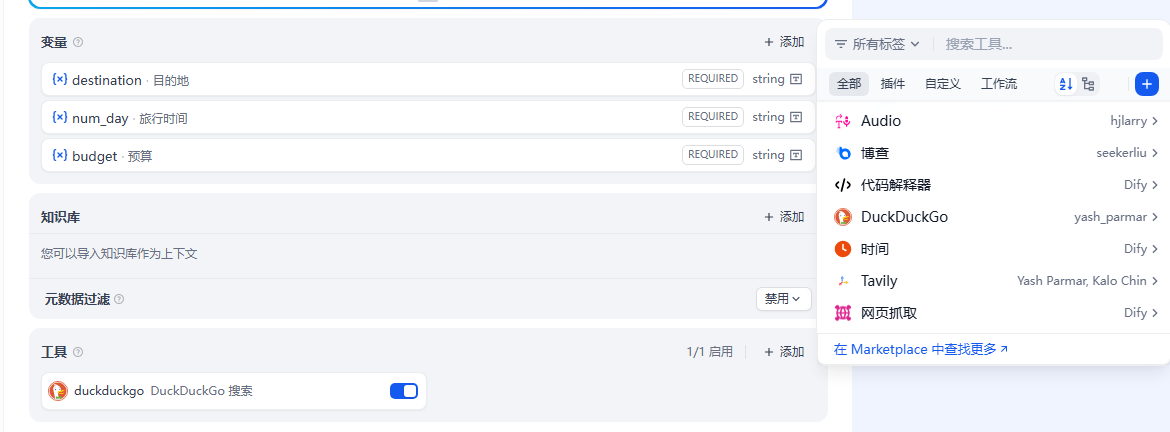
内容审查:自定义审查内容的关键字,或者自己弄API
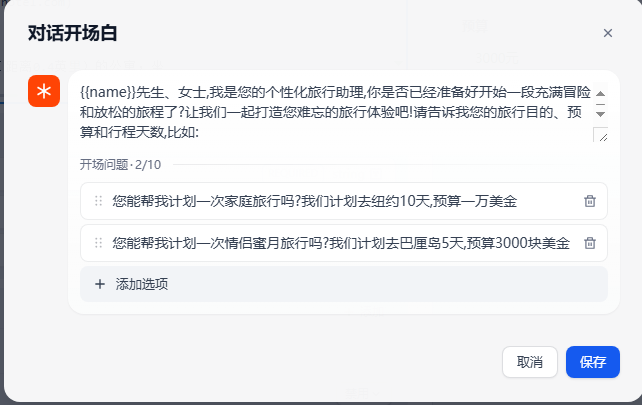
对话开场白设置
{``{name}}先生、女士,我是您的个性化旅行助理,你是否已经准备好开始一段充满冒险和放松的旅程了?让我们一起打造您难忘的旅行体验吧!请告诉我您的旅行目的、预算和行程天数,比如: 提供所有必要的细节和提示,所有这些都包裹在一个有趣而引人入胜的包装中! 您能帮我计划一次家庭旅行吗?我们计划去纽约10天,预算一万美金 您能帮我计划一次情侣蜜月旅行吗?我们计划去巴厘岛5天,预算3000块美金
设置好运行发布;
三、Dify案例实践之工作流应用构建
3.1 工作流是什么
人为的做好工作流程,类似于面向过程编程。只把LLM作为一个节点。
⼯作流提供了丰富的逻辑节点,⽐如代码节点、流程控制节点、循环控制节点等,通过这些
节点可解决⾃动化、批处理场景中的相对复杂的任务逻辑。
3.2 dify的工作流有什么
Workflow:适⽤于⾼质量翻译、数据分析、内容⽣成等⾯向⾃动化和批处理场景
Chatflow:适⽤于客户服务、语义搜索等⾯向对话类的场景

3.3 实战
智能写作大神
需求
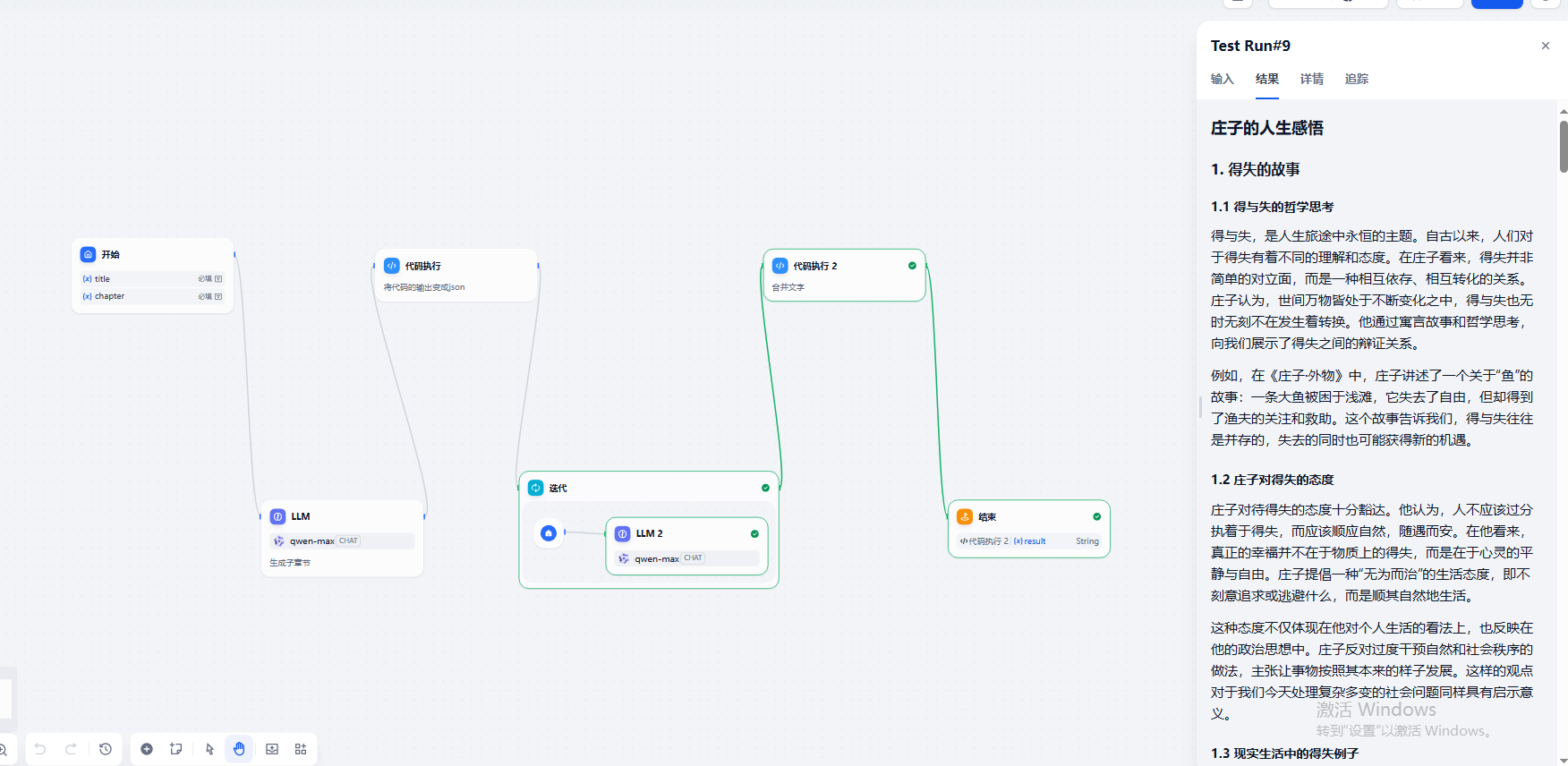
⽤户需要输⼊⽂章标题以及⼀级章节梗概,从而生成长文的文章。
# ⽂章标题 庄⼦的⼈⽣感悟 # 章节吸详情 1.得失的故事 2.困境的故事 3.选择的故事 4.评价的故事 5.⼼态的故事
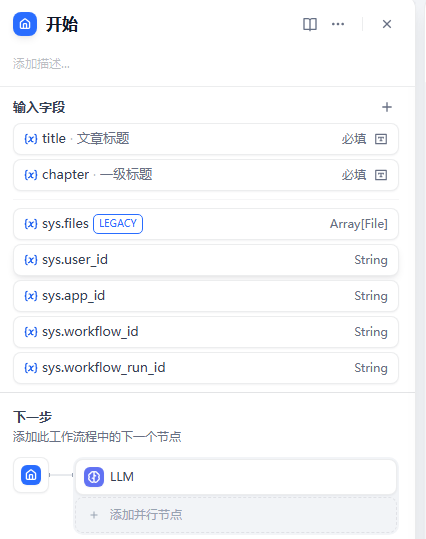
1.开始节点
在本节点,⽤户需要输⼊⽂章标题以及⼀级章节梗概
2.LLM生成节点
在本节点,接收开始节点的传递过来的参数 title 和 chapter ,并通过 提示词定义模型⾏为,提示词中定义了 ⻆⾊ 、 技能 、 ⽬标 、 限制 和 输出示例 ,让 LLM 严格按照意图来输出⽂本
## ⻆⾊:⽂章撰写专家 ## 技能:你根据⽤户输⼊的⽂章标题{````````{#1721471415084.title#}} 和各章节 名称{````````{#1721471415084.chapter#}} ,⽣成各个章节及⼦章节 ## ⽬标: - 确保⽣成的每个⼦章节和⽗章节紧密相关 - 纵观整体章节,必须保证各章节过渡连贯流畅 - 最终输出json字符串,详细请看以下输出示例 ## 限制: - 输出内容必须是标准json字符串,不要包含任何与json字符串⽆关的内容 - 请严格按照输出示例中的数据格式输出json字符串,不要输出其他任何与json字符串 ⽆关⽂本、以及特殊字符 - 不要输出任何与json⽆关的特殊符号,⽐如\n或者是#或者是``` - 请将位于输出内容开头或结尾的任何与json⽆关的特殊符号都删掉 ## 输出示例: [{"chapter": "引⾔", "subchapter": ["1. ⽓候变化对沿海城市影响的概述", "2. 理解这些影响的重要性"]}, {"chapter": "海平⾯上升", "subchapter": ["1. 海平⾯上升的原因", "2. 对沿海基础设施和社区的影响" ,"3. 受影响城市的例 ⼦"}]
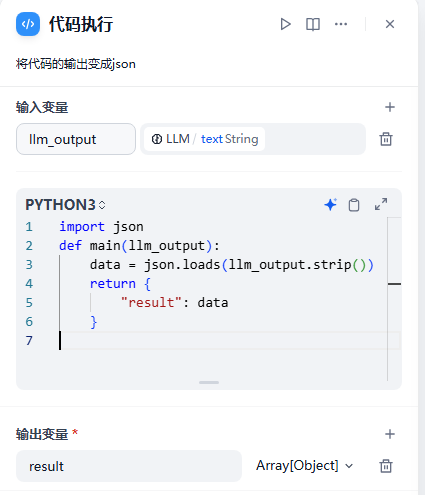
3.代码执行节点
本节点⽀持运⾏ Python / NodeJS 代码以在⼯作流程中执⾏数据转换,⾮常适合⽤于
JSON transform 、 ⽂本处理 等情景。该节点极⼤地增强了开发⼈员的灵活性,使他们
能够在⼯作流程中嵌⼊⾃定义的 Python 或 Javascript 脚本,实现预设节点⽆法完成
的⼯作任务。本节点的输出类型包括 string 、 ArrayObject 等,需选择适合⾃⼰的
数据类型。节点示例代码:
import json
def main(llm_output):
data = json.loads(llm_output.strip())
return {
"result": data
}
输出结果
{
"result": [
{
"chapter": "得失的故事",
"subchapter": [
"1. 得与失的哲学思考",
"2. 庄子关于得失的态度",
"3. 通过故事理解得失"
]
},
{
"chapter": "困境的故事",
"subchapter": [
"1. 困境中的人性光辉",
"2. 庄子对困境的看法",
"3. 超越困境的心灵之旅"
]
},
{
"chapter": "选择的故事",
"subchapter": [
"1. 面对选择时的心态",
"2. 庄子的选择观",
"3. 从故事中学习选择的艺术"
]
},
{
"chapter": "评价的故事",
"subchapter": [
"1. 如何看待他人的评价",
"2. 庄子对于名誉地位的看法",
"3. 故事中的评价与自我价值"
]
},
{
"chapter": "心态的故事",
"subchapter": [
"1. 积极心态的重要性",
"2. 庄子倡导的生活态度",
"3. 故事中体现的良好心态"
]
}
]
}
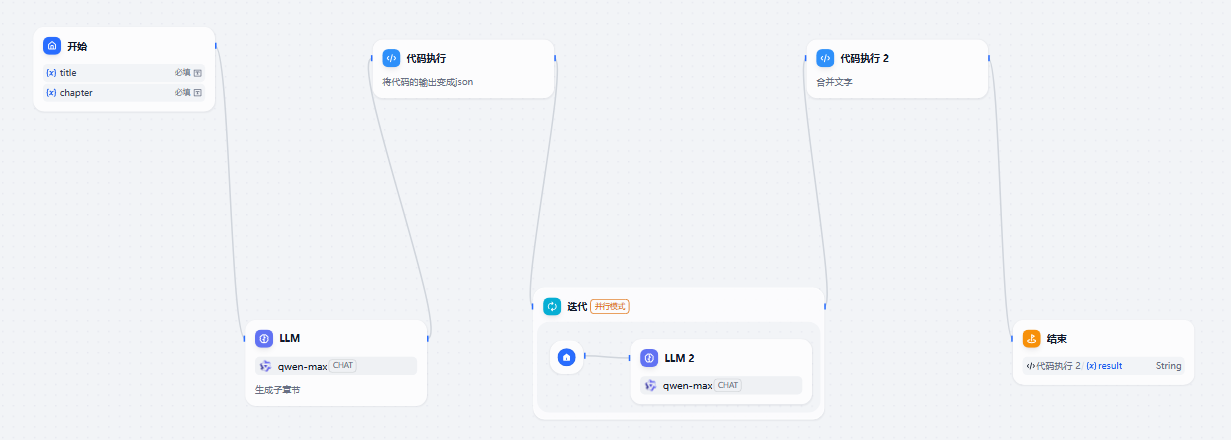
4.迭代节点
上⼀个代码执⾏节点的输出数据类型为 Arrayobject 作为本节点的输⼊,迭代节点就
是循环 ArrayObject ,取出其中每⼀个 Object ,⼀个 Object 代表了⼀个章节(包
含⽗章节和各个⼦章节)。因为包含5个章节,所以 迭代节点 循环迭代5次,根据每⼀个
Object ⽣成章节的详细内容,如何⽣成?在迭代节点中嵌套 LLM 节点,使⽤ LLM 节点
编写每⼀个章节的具体内容
嵌套的 LLM 节点中,在 SYSTEM 和 USER 中都分别编写了 提示词Prompt
# system提示词 你是⼀位⽂章撰写专家,擅⻓写有吸引⼒的⻓篇⽂章 # user提示词 你正在写⼀篇名为/title的⽂章,请根据以下信息 /item 写每⼀个章节,⽣成全⽂时, 请以完整的⼤纲作为参考 /chapter
5.代码执行节点
在本节点中,将迭代节点产⽣的数组中的数据进⾏拼接
def main(args1):
return {
"result": "---华丽分割线----".join(args1)
}
四、dify应用的发布
4.1 聊天机器人和agent有直接运行,嵌入网页,api访问三种发布方式。
每个dify应用都有自己的api-key,右上角可以获取,然后参考下面代码进行调用。
import requests
import json
def stream_dify_response():
API配置(与cURL命令参数对应)
API_URL = "http://localhost/v1/chat-messages"
API_KEY = "your_apikey" # 替换为实际密钥
USER_ID = "abc-123"
请求头设置
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
"Accept": "text/event-stream" # 流式响应必须头5(@ref)
}
请求体构建
payload = {
"inputs": {},
"query": "你好",
"response_mode": "streaming",
"conversation_id": "",
"user": USER_ID
}
try:
启用流式接收模式
with requests.post(API_URL,
headers=headers,
data=json.dumps(payload),
stream=True) as response:
response.raise_for_status() # 检查HTTP状态码
实时处理数据流
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
try:
解析SSE格式数据
if decoded_line.startswith('data:'):
event_data = json.loads(decoded_line5:)
print(event_data.get('answer', ''), end='', flush=True)
except json.JSONDecodeError as e:
print(f"\nJSON解析错误: {e}")
except requests.exceptions.RequestException as e:
print(f"请求失败: {str(e)}")
if hasattr(e, 'response') and e.response:
print(f"错误详情: {e.response.text}")
if name == "main":
stream_dify_response()
如果开始需要输入参数,比如上面说的面试官,就要在"inputs"里面搞字典,把参数输入进去就行。
payload = {
"inputs": {"jobName":"AI工程师"},
"query": "你好",
"response_mode": "streaming",
"conversation_id": "",
"user": USER_ID
}
4.2 工作流可以直接运行,api,发布为工具三种发布方式。
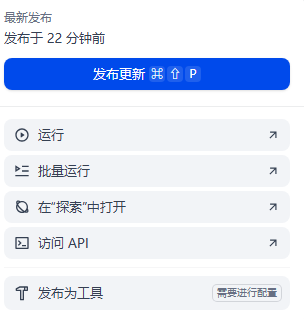
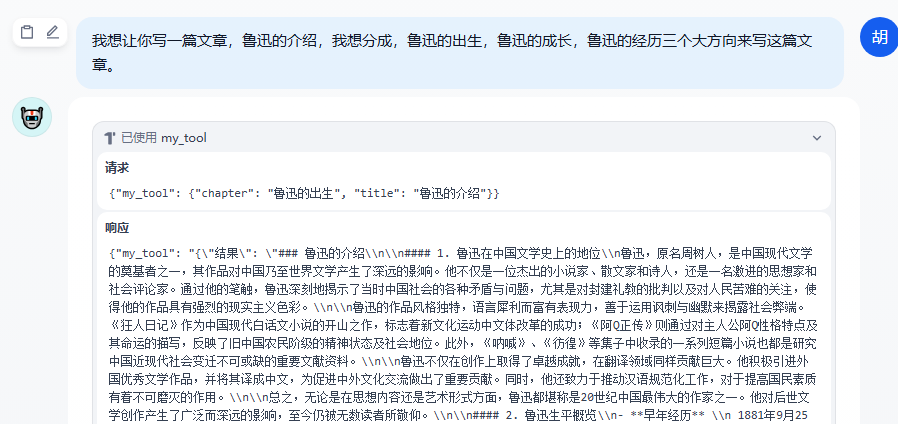
可以发布成工具,理解成python的模块,后续有一样的需求直接调用就行。可以看到qwen-plus不能很好的抽取到我们工具请求参数、
五、小结
1.使用dify构建了聊天机器人,agent,wrokflow。
2.介绍了dify应用怎么部署发布给前端使用。
3.后续介绍dify怎么构建飞书智能体和企业级知识库的chatflow,可以关注我。