SpringAI--RAG知识库
RAG概念
什么是RAG?
RAG(Retrieval-Augmented Genreation,检索增强生成)是一种结合信息检索技术和AI内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
RAG在大语言模型生成回答之前,会先从外部知识库中检索相关信息,然后将这些检索到的内容作为额外上下文提供给模型,引导其生成更准确、更相关的回答。
简单了解传统AI模型和RAG增强模型区别:
| 特性 | 传统AI | RAG增强模型 |
|---|---|---|
| 知识失效性 | 受训练数据截止日期限制 | 可接入最新知识库 |
| 领域专业性 | 泛华知识,专业深度有限 | 可接入专业领域知识库 |
| 响应准确性 | 可能产生幻觉 | 基于检索的事实依据 |
| 可控性 | 依赖原始训练 | 可通过知识库定制输出 |
| 资源消耗 | 较高(需要大模型参数) | 模型可更小,结合外部知识 |
RAG工作流程
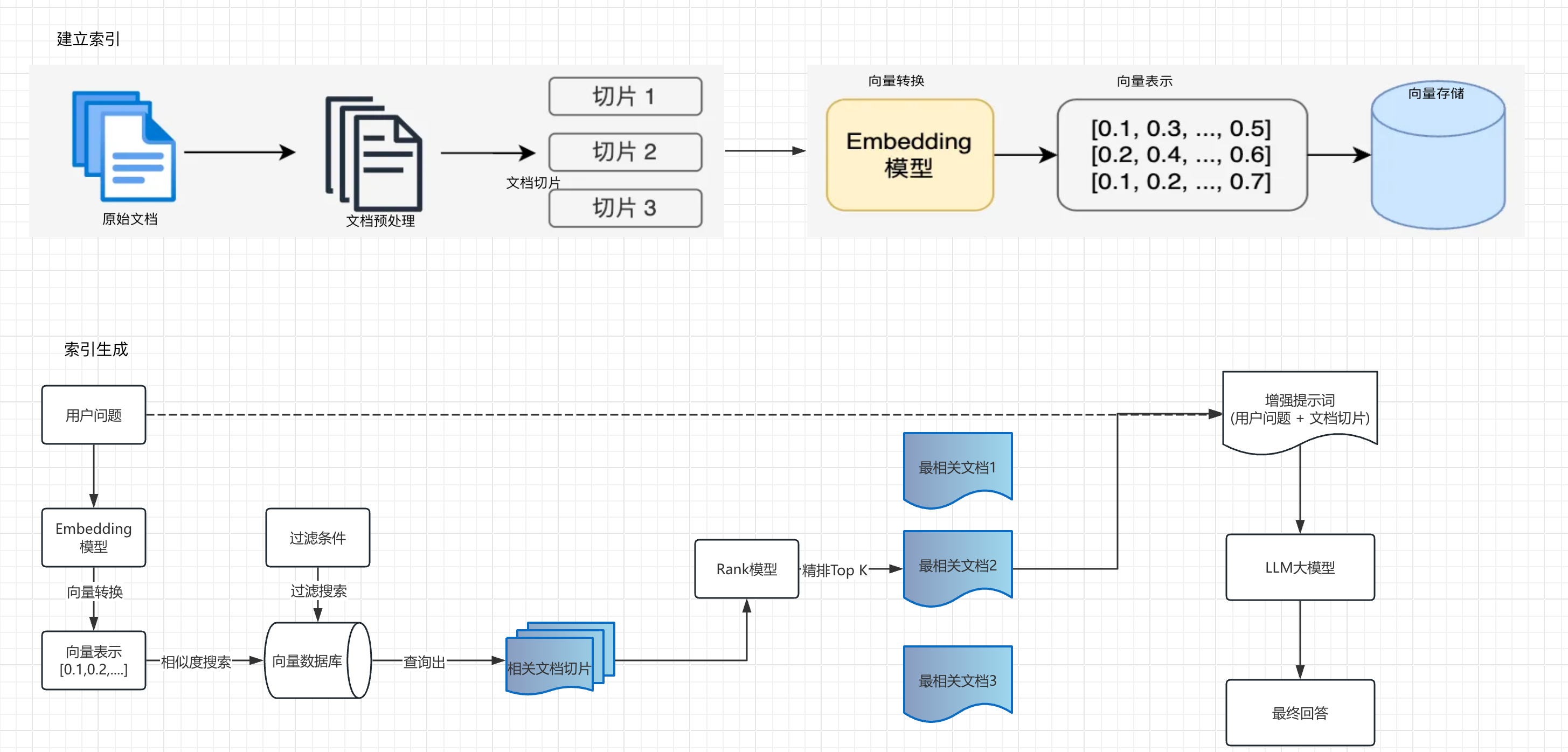
RAG技术实现主要包含以下4个核心步骤:
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
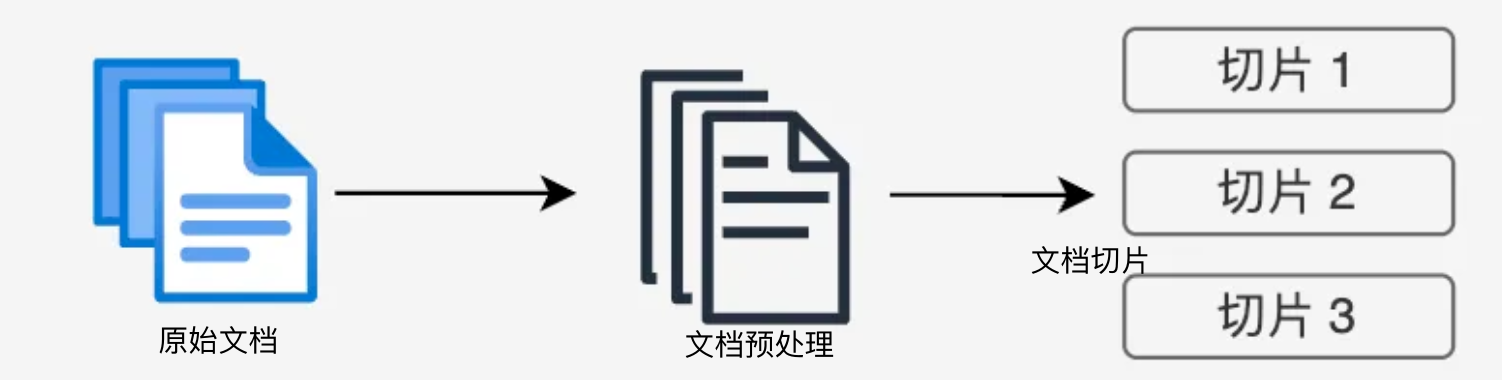
文档收集和切割
- 文档收集:从各种来源(网页、PDF、数据库等)收集原始文档。
- 文档预处理:清洗、标准化文档格式(markdown格式、docx格式等)。
- 文档切割:将长文档分割成适当大小的片段(俗称chunks)。
- 基于固定大小(如512个token)
- 基于语义边界(如段落、章节)
- 基于递归分割策略(如递归字符n-gram切割)
向量转换和存储
- 向量转换:使用Embedding模型将文本块转换为高维向量表示,可以捕获到文档的语义特征。
- 向量存储:将生成的向量和对应文本存储向量数据库,支持高效的相似性搜索。

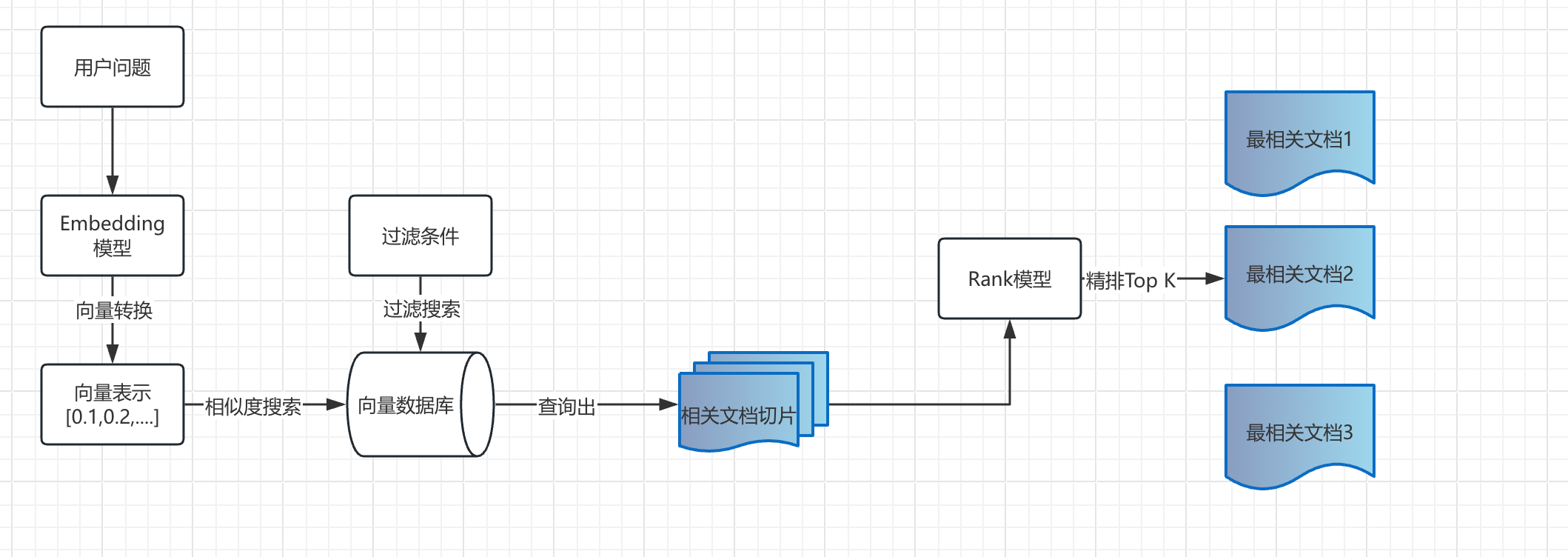
文档过滤和检索
- 查询处理:将用户问题也转换为向量表示。
- 过滤机制:基于元数据、关键词或自定义规则进行过滤。
- 相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离等。
- 上下文组装:将检索到的多个文档块组装成连贯的上下文。
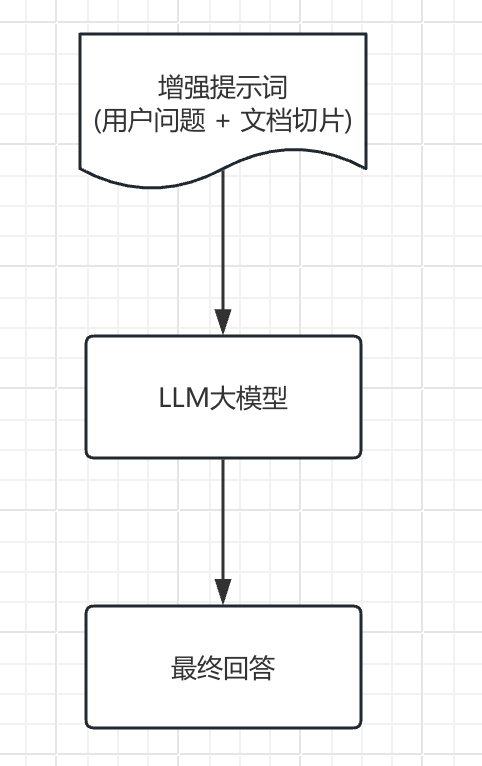
查询增强和关联
- 提示词组装:将检索到的相关文档与用户问题组合成增强提示。
- 上下文融合:大模型基于增强提示生成回答。
- 源引用:在回答中添加信息来源引用。
- 后处理:格式化、摘要或其他处理以优化最终输出。
完整工作流程
RAG相关技术
Embedding和Embedding模型
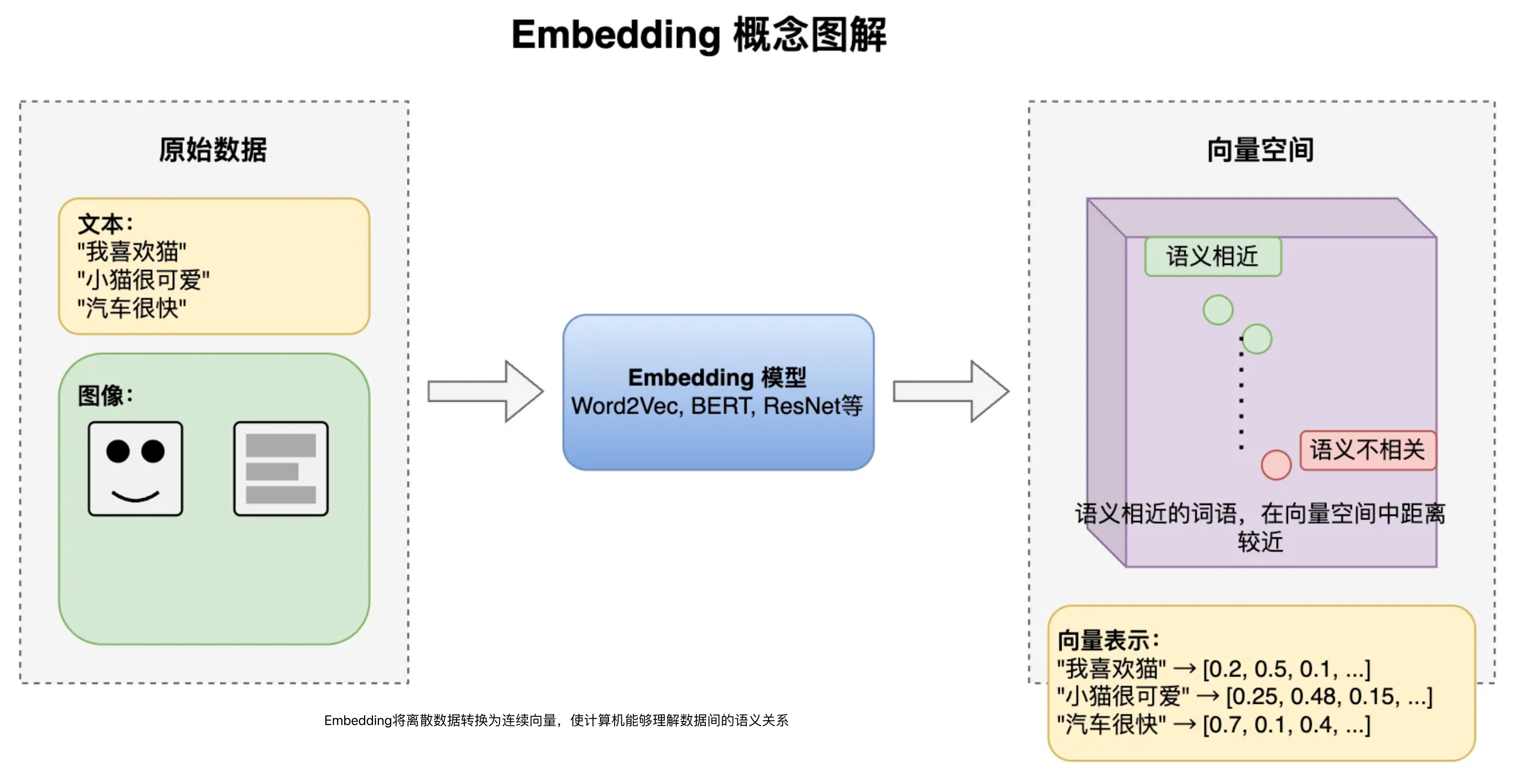
Embedding嵌入是将高维离散数据(如文字、图片)转换为低维连续向量的过程。这些向量能在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性。
Embedding模型是执行这种转换算法的机器学习模型,如Word2Vec(文本)、ResNet(图像)等。不同的Embedding模型产生的向量表示和维度数不同,一般维度越高表达能力越强,可以捕获更丰富的语义信息和更细微的差别,但同样占用更多存储空间。
向量数据库
向量数据库是专门存储和检索向量数据的数据库系统。通过高效索引算法实现快速相似性搜索,支持K近邻查询等操作。
注意,并不是只有向量数据库才能存储向量数据,只不过与传统数据库不同,向量数据库优化了高维向量的存储和检索。
AI的流行带火了一波向量数据库和向量存储,比如Milvus、Pinecone等,此外,一些传统数据库也可以通过安装插件实现向量存储和检索,比如PGVector、Redis Stack的RediSearch等。
召回
召回是信息检索中的第一阶段,目标是从大规模数据集中快速筛选出可能相关的候选项子集。强调速度和广度,而非精确度。
精排和Rank模型
精排(精确排序)是搜索/推荐系统的最后阶段,使用计算复杂度更高的算法,考虑更多特征和业务规则,对少量候选项进行更复杂、精细的排序。
Rank模型(排序模型)负责对召回阶段筛选出的候选集进行精确排序,考虑多种特征评估相关性。
现代Rank模型通常基于深度学习,如BERT、LambdaMART等,综合考虑查询与候选项的相关性、 用户历史行为等因素。
混合检索策略
混合检索策略结合多种检索方法的优势,提高搜索效果。常见组合包括关键词检索、语义检索、知识图谱等。
比如在AI大模型开发平台Dify中,就为用户提供了"基于全文检索的关键词搜索+基于向量检索的语义检索"的混合检索策略,用户还可以自己设置不同检索方式的权重。
RAG实战:SpringAI + 本地知识库
我们要对自己准备好的知识库文档进行处理,然后保存到向量数据库中。这个过程俗称ETL(抽取、转换、加载),SpringAI提供了对ETL的支持。
ETL的3大核心组件,按照顺序执行:
- DocumentReader:读取文档,得到文档列表。
- DocumentTransformer:转换文档,得到处理后的文档列表。
- DocumentWriter:将文档列表保存到存储中(可以是向量数据库,也可以是其他存储)。
文档准备
文档读取
读取markdown文档
demo文档读取
向量存储和转换
为了实现方便,先使用SpringAI内置的基于内存读写的向量数据库SimpleVectorStore来保存文档。
SimpleVectorStore实现了VectorStore接口,而VectorStore接口集成了DocumentWriter,所以具备文档写入能力。
通过下面SimpleVectorStore的源码可以了解到,在将文档写入到数据库前,会先调用Embedding大模型将文档转换为向量,实际保存到数据库中的是向量类型的数据。
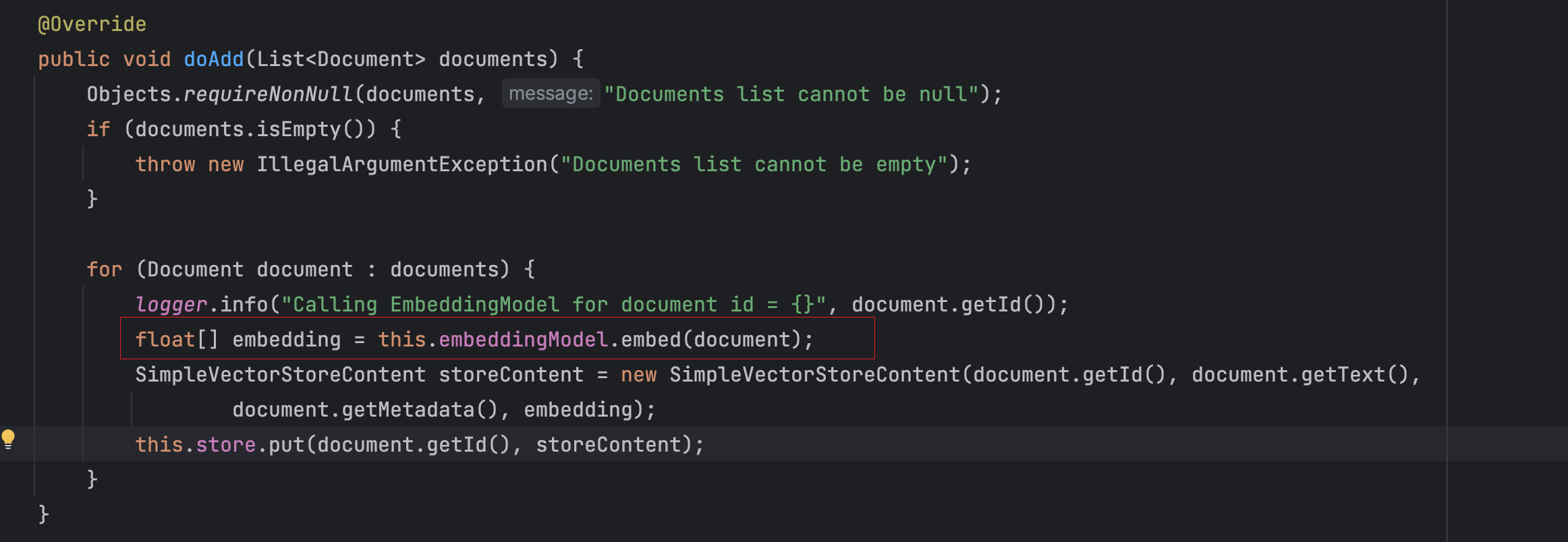
实现初始化向量数据库并保存文档的方法:
文档存入向量数据库(内存实现)
查询增强
SpringAI通过Advisor特性提供了开箱即用的RAG功能。主要是QuestionAnswerAdvisor问答拦截器和RetrievalAugmentationAdvisor检索增强拦截器,前者更简单易用,后者更灵活强大。
测试
基于PGVector实现向量存储
java
/**
* 向量检索
* 查询增强原理:
* 向量数据库存储着AI模型本身不知道的数据,当用户问题发送给AI模型时,
* QuestionAnswerAdvisor会查询向量数据库,获取与用户问题相关的文档。
* 然后从向量数据库返回的响应会被附加到用户文本中,为AI模型提供上下文,帮助AI模型生成回答
* 存储在pgVector向量数据库中
*/
public String doChat4RagPgVector(String message, String chatId) {
ChatResponse chatResponse = chatClient.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 5))
// QuestionAnswerAdvisor 查询增强,在调用大模型前会检索pgVectorStore中的数据,拼接到用户的Prompt中
.advisors(new QuestionAnswerAdvisor(pgVectorStore))
// MySQL存储对话记忆
.advisors(new MessageChatMemoryAdvisor(chatMemory))
.call()
.chatResponse();
return chatResponse.getResult().getOutput().getText();
}