
文章目录
- 一、前言
- 二、分割模型的前向推理
-
- [1. 检测结果:来自Detect类的输出](#1. 检测结果:来自Detect类的输出)
- [2. 分割结果(最终)](#2. 分割结果(最终))
- [3. 与Detect的主要区别](#3. 与Detect的主要区别)
- [4. 工作流程](#4. 工作流程)
- 三、后处理
-
- [1. 非极大值抑制(NMS)过滤检测框](#1. 非极大值抑制(NMS)过滤检测框)
- [2. 分割原型(Mask Prototypes)提取](#2. 分割原型(Mask Prototypes)提取)
- [3. 掩码生成](#3. 掩码生成)
一、前言
这篇文章主要分享yolov8模型用于图像分割时,模型输出和后处理。彻底理了下,可以总结为以下3点:
- 分割继承检测,前向推理时也会调用检测的方法把目标框检测出来;
- 但是前向推理分割和检测是各自进行的,训练也是分别去计算loss;
- 在后处理时为了提精度,在有目标处才去分割,然后为了提速掩膜才去系数和乘以原始掩膜的方法,系数和原始掩膜都是分割模型的前向推理输出;
yolov8官方代码路径:https://github.com/ultralytics/ultralytics
二、分割模型的前向推理
代码位置:yolo/ultralytics/nn/modules/head.py
解释:
- 继承关系:
- Segment继承了Detect的所有基础功能,包括目标检测的能力
- 它扩展了Detect的功能,增加了实例分割的能力
- 主要组件:
py
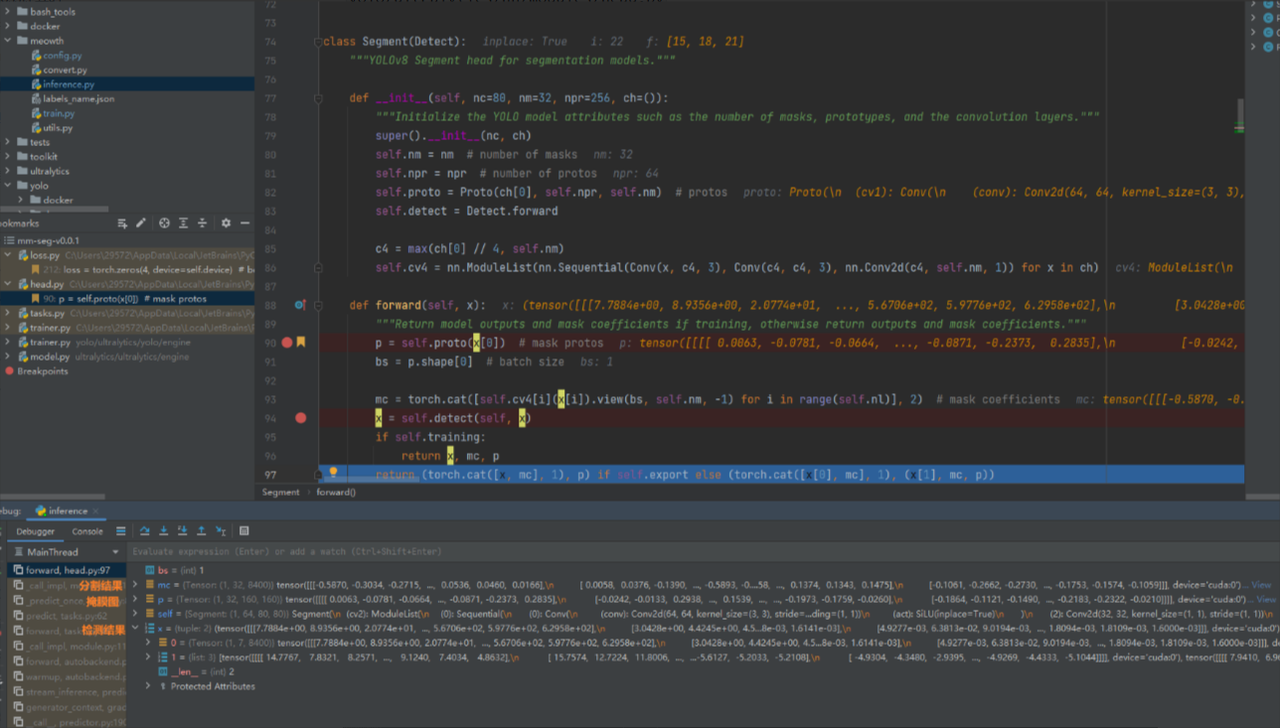
def __init__(self, nc=80, nm=32, npr=256, ch=()):
super().__init__(nc, ch)
self.nm = nm # 掩码数量
self.npr = npr # 原型数量
self.proto = Proto(ch[0], self.npr, self.nm) # 原型网络
self.detect = Detect.forward # 保留检测功能- 推理输出:
从forward方法可以看出,Segment模型在推理时返回两个主要部分:
py
def forward(self, x):
p = self.proto(x[0]) # 生成掩码原型
bs = p.shape[0] # batch size
# 生成掩码系数
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2)
x = self.detect(self, x) # 调用检测功能
if self.training:
return x, mc, p
return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))推理时返回的内容包括:
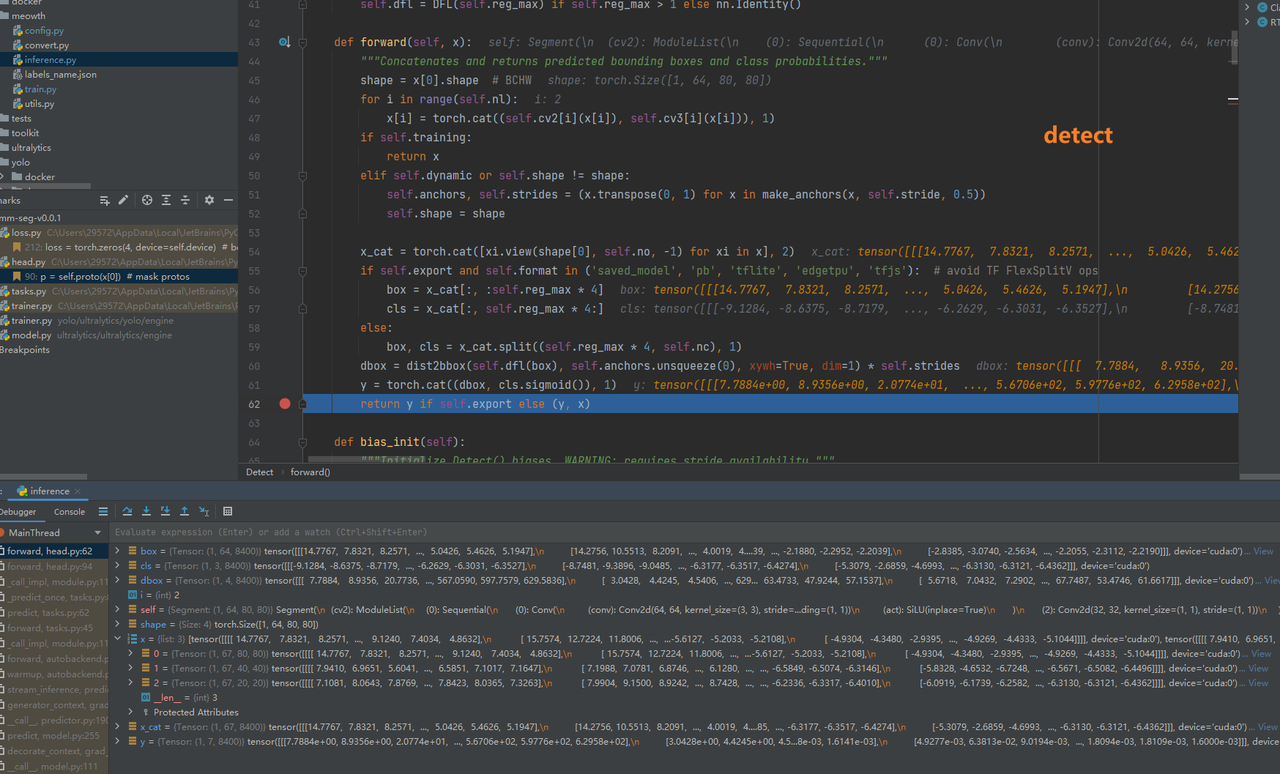
1. 检测结果:来自Detect类的输出
变量解释:
-
x:分别为3个head输出的特征图(大中小)
shape为:(bs, 4+类别数,特征图宽,特征图高)
-
y: 边界框坐标+类别预测(经过sigmoid)------纵向拼接
shape为:(bs, 4+类别数,框的个数)
-
训练模式,则输出x;
-
推理模式:
export为onnx时则输出:y
否则输出一个元组:(y, x)
2. 分割结果(最终)
变量解释:
- 掩码系数mc(mask coefficients)
shape为:(bs, 32(系数个数),框的个数) - 原型掩码p(prototype masks)
shape为:(bs, 32(系数个数),mask图宽,mask图高)
训练模式,输出三个元素:x(detect的输出,对应x),mc,p
推理模式:
export为onnx时输出元组包含2个元素:
- 第一个元素:纵向(第1维)拼接x(这里对应detect输出的y)和mc
shape为:(bs, 4+类别数+32(系数个数),框的个数) - 第二个元素:p
否则也是输出元组包含2个元素:
- 第一个元素只有1个元素:纵向拼接x0和mc
可以理解为:目标检测的结果+掩码系数
shape为 (bs, 4+类别数+32,mask(或框)的个数)
-->(4后处理的输入0 - 第二个元素是个元组有3个元素:(x1, mc, p)
可以理解为:目标检测的head特征,掩码系数,原型掩码
-->(4后处理的输入1
3. 与Detect的主要区别
- Detect只输出检测结果(边界框和类别)
- Segment在Detect的基础上增加了分割能力,可以输出实例掩码
- Segment使用原型网络(Proto)来生成掩码,这是分割特有的组件
4. 工作流程
- 首先通过原型网络生成基础掩码
- 同时进行目标检测
- 将检测结果和掩码系数结合,生成最终的实例分割结果
这种设计使得Segment模型能够同时完成目标检测和实例分割任务,是一个多任务的模型架构。
三、后处理
代码位置:yolo/ultralytics/yolo/v8/segment/predict.py
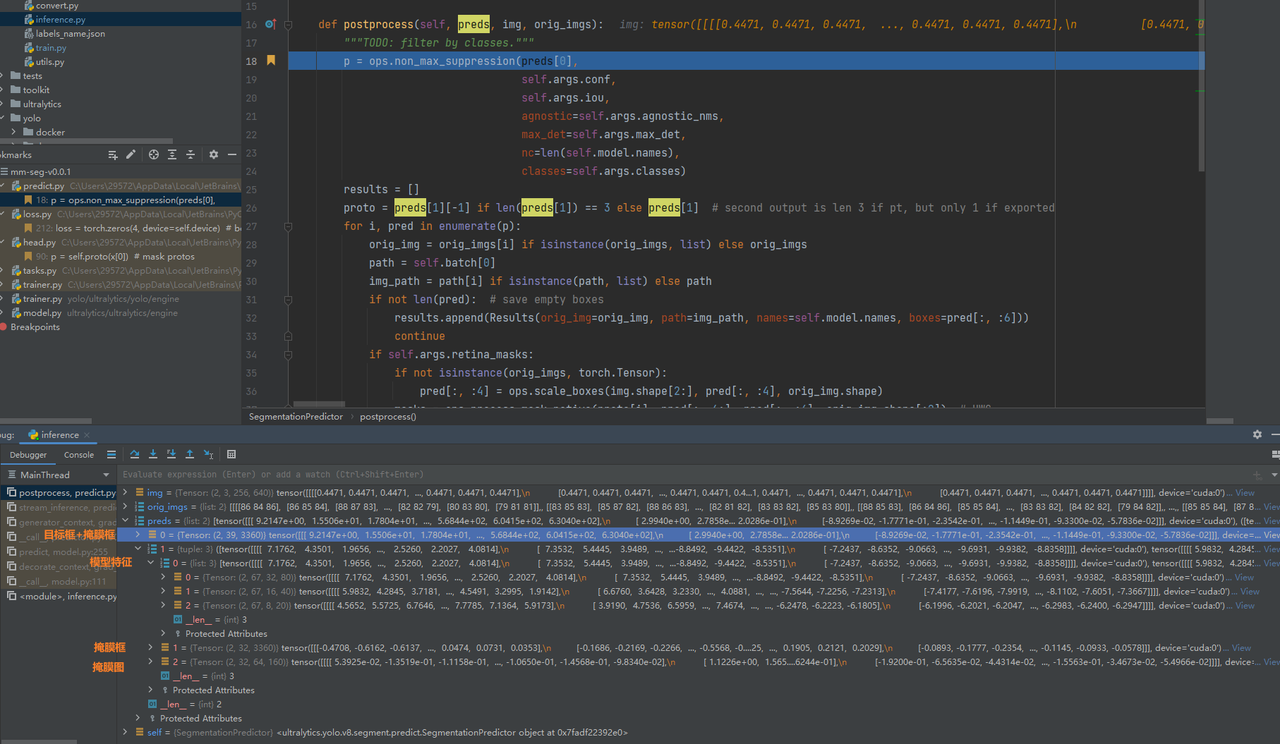
其中:
pred0实际上就是:纵向拼接x0和mc
pred1实际上就是:(x1, mc, p)
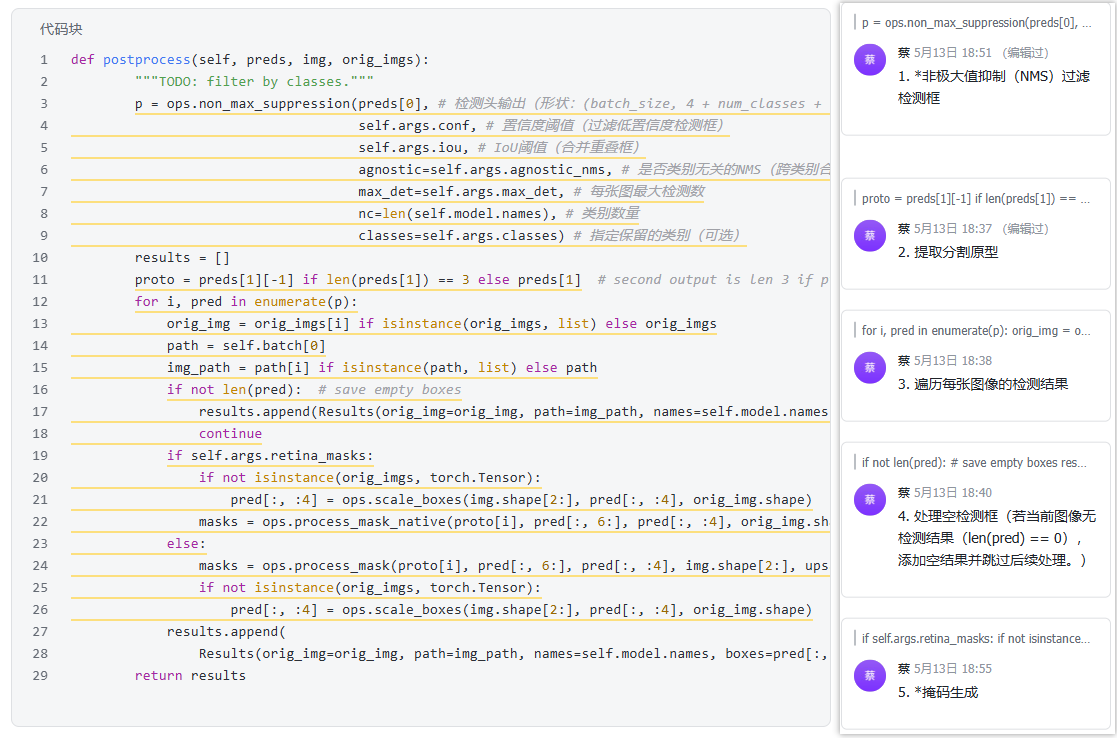
1. 非极大值抑制(NMS)过滤检测框
- 功能:
- 过滤掉低置信度(< conf)的检测框。
- 合并IoU超过阈值(iou)的重叠框。
- 若启用agnostic_nms,不同类别的框也会被合并(适用于类别无关任务)。
- 输出p为一个列表,每个元素对应一张图像的检测结果(形状:(num_boxes, 6 + num_masks),其中num_boxes为保留的检测框数,6包含x1,y1,x2,y2,conf,cls,mask1系数,mask2系数,...32个系数)。
- 注意:
- preds0形状为(batch_size, 4 + num_classes + num_masks, num_boxes)
- num_masks 为 mask系数数量,通常是32个
- mask_coeffs用于和原型掩码线性组合生成实例分割
- 原型掩码是由模型预测出来的,对应output1
2. 分割原型(Mask Prototypes)提取
- 背景:
- preds1是分割头的输出,包含掩码原型。
- 若模型为PyTorch格式(未导出),preds1可能有3个元素(如不同尺度的原型),需取最后一个(最高分辨率)。
- 若模型已导出(如ONNX),preds1直接为原型张量。
- 形状:
- proto的典型形状为batch, K, H, W,其中:
- K:原型数量(如32)。
- H, W:原型的分辨率(如输入图像的1/4大小)
- proto的典型形状为batch, K, H, W,其中:
3. 掩码生成

注意:每一个框对应一组掩码系数。
分为两个模式:
有四个尺寸:特征图尺寸(框对应);input尺寸;mask尺寸;原图尺寸
(1) 视网膜掩码:(标蓝是一个过程)
精度更高
放大box坐标到原图->生成mask(小图)->裁剪mask图(因为输入的时候为了保持图像不变形,会在两侧添加填充)->resize mask到原图->裁切mask对齐框(保留检测框内的区域,框外区域置为0)
(2) 普通掩码:(标蓝是一个过程)-- 推理默认
性能更好
生成mask(小图)->把坐标缩放到mask->裁切mask对齐框(保留检测框内的区域,框外区域置为0)->resize mask到input尺寸->把坐标放大到原图
注意:这个时候resize mask跟box坐标不在同一个尺寸标准下,画图的时候会把mask缩放到原图大小。
代码位置:yolo/ultralytics/yolo/utils/plotting.py
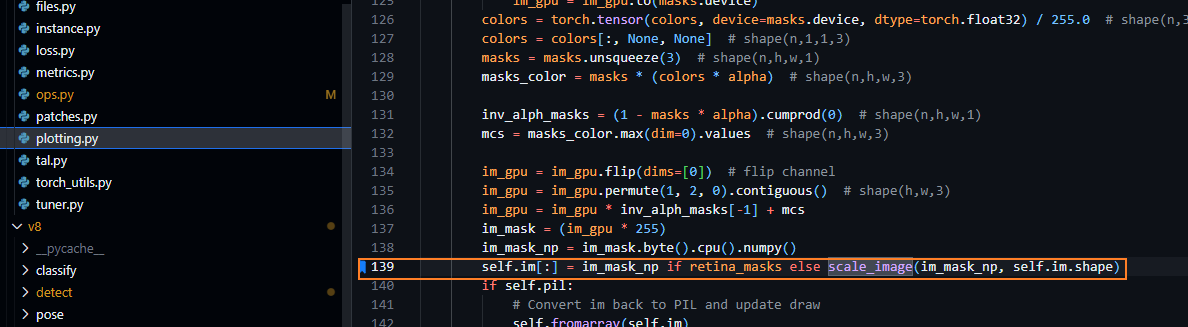
(3) 这两个模式都包括了两个操作:
(a) 缩放坐标
- 将检测框坐标从模型输入尺寸(img.shape2:)缩放到原始图像尺寸(orig_img.shape),处理填充(padding)和缩放比例,确保框位置正确映射。
- 拆切超出图像边缘部分的框。
(b) 生成掩码
代码位置:yolo/ultralytics/yolo/utils/ops.py
如果是视网膜掩码,则使用process_mask_native
- 输入参数:
py
def process_mask_native(protos, masks_in, bboxes, shape):
"""
protos: 原型掩码 [mask_dim, mask_h, mask_w]
masks_in: 预测的掩码系数 [n, mask_dim]
bboxes: 检测框 [n, 4]
shape: 原始图像尺寸 (h,w)
"""- 掩码生成:
py
c, mh, mw = protos.shape # 获取原型掩码的维度
# 将掩码系数与原型掩码相乘,得到最终掩码
masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)- 将原型掩码展平为2D矩阵
- 与掩码系数进行矩阵乘法
- 应用sigmoid激活函数
- 重塑为3D张量
- 计算缩放和填充:
py
# 计算缩放比例
gain = min(mh / shape[0], mw / shape[1]) # gain = 旧尺寸/新尺寸
# 计算填充值
pad = (mw - shape[1] * gain) / 2, (mh - shape[0] * gain) / 2 # wh padding
top, left = int(pad[1]), int(pad[0]) # y, x
bottom, right = int(mh - pad[1]), int(mw - pad[0])- 计算保持宽高比的缩放比例
- 计算图像两侧的填充值
- 确定裁剪区域
- 裁剪掩码:
py
# 裁剪掉填充区域
masks = masks[:, top:bottom, left:right]- 移除填充区域
- 保持有效区域
- 调整大小:
py
# 将掩码调整到原始图像大小
masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0]- 使用双线性插值
- 调整到原始图像尺寸
- 保持掩码质量
- 根据检测框裁剪(保留检测框内的区域,框外区域置为0):
py
# 根据检测框裁剪掩码
masks = crop_mask(masks, bboxes)- 将掩码裁剪到检测框区域
- 确保掩码与检测框对齐
- 二值化处理:
py
# 将掩码二值化
return masks.gt_(0.5)- 使用0.5作为阈值
- 将掩码转换为二值图像
如果是普通掩码,则使用process_mask
- 生成mask
- 将检测框坐标从图像尺寸缩放到掩码尺寸
- 使用缩放后的检测框裁剪掩码,确保掩码与检测框对齐
- mask上采样要原图