目录
[1 Sqoop概述与大数据生态定位](#1 Sqoop概述与大数据生态定位)
[2 Sqoop与HDFS的深度集成](#2 Sqoop与HDFS的深度集成)
[2.1 技术实现原理](#2.1 技术实现原理)
[2.2 详细工作流程](#2.2 详细工作流程)
[2.3 性能优化实践](#2.3 性能优化实践)
[3 Sqoop与Hive的高效协同](#3 Sqoop与Hive的高效协同)
[3.1 集成架构设计](#3.1 集成架构设计)
[3.2 数据类型映射处理](#3.2 数据类型映射处理)
[3.3 案例演示](#3.3 案例演示)
[4 Sqoop与HBase的实时集成](#4 Sqoop与HBase的实时集成)
[4.1 数据模型转换挑战](#4.1 数据模型转换挑战)
[4.2 详细集成流程](#4.2 详细集成流程)
[4.3 高级特性应用](#4.3 高级特性应用)
[5 Sqoop在数据仓库中的典型应用](#5 Sqoop在数据仓库中的典型应用)
[5.1 增量数据同步方案](#5.1 增量数据同步方案)
[5.2 数据质量保障措施](#5.2 数据质量保障措施)
[6 总结](#6 总结)
1 Sqoop概述与大数据生态定位
Apache Sqoop(SQL-to-Hadoop)作为大数据生态系统中至关重要的数据迁移工具,在关系型数据库与Hadoop生态系统之间架起了高效的数据桥梁。随着企业数据量的爆炸式增长,传统ETL工具在处理海量数据时面临性能瓶颈,而Sqoop凭借其分布式架构和并行处理能力,成为大数据平台数据集成的事实标准。
核心特性:
- 双向数据传输:支持从RDBMS到Hadoop的导入(import)和从Hadoop到RDBMS的导出(export)
- 并行处理机制:基于MapReduce框架实现数据并行传输
- 数据类型映射:自动处理JDBC数据类型与Hadoop数据类型的转换
- 增量加载:支持基于时间戳或自增ID的增量数据同步
在大数据架构中,Sqoop通常位于数据采集层,与Flume、Kafka等工具共同构成完整的数据接入体系。
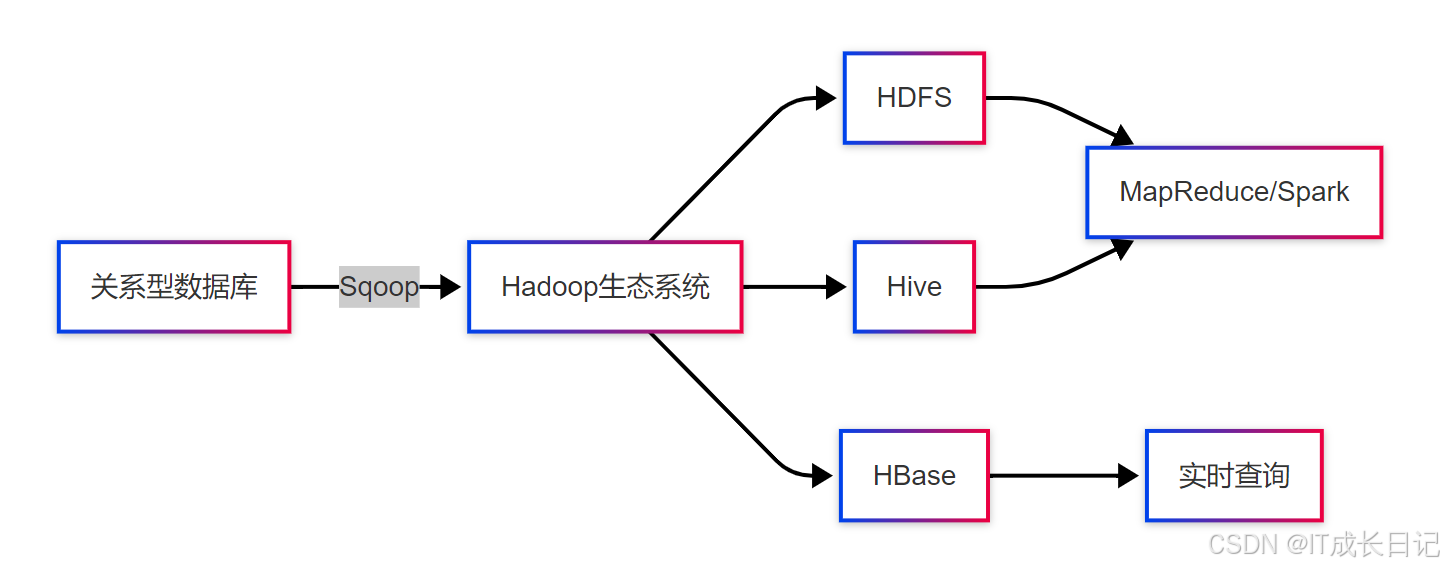
2 Sqoop与HDFS的深度集成
2.1 技术实现原理
Sqoop与HDFS的集成是最基础也是最核心的功能。当执行导入操作时,Sqoop会将关系型数据库中的表数据转换为HDFS上的文件存储。这个过程涉及几个关键技术点:
- 分片策略:Sqoop通过--split-by参数指定分片列,将数据划分为多个逻辑块
- 并行度控制:通过-m参数设置Map任务数量,每个任务处理一部分数据
- 格式转换:支持文本文件、Avro、Parquet等多种存储格式
2.2 详细工作流程

关键步骤解析:
- 元数据获取:Sqoop首先通过JDBC连接获取表结构和统计信息
- 查询生成:根据分片列生成分页查询语句,如SELECT * FROM table WHERE id >= ? AND id < ?
- 任务分配:Hadoop YARN资源管理器分配Map任务容器
- 并行执行:每个Map任务独立连接数据库并获取分配的数据块
- 数据写入:转换后的数据以指定格式写入HDFS
2.3 性能优化实践
-
分区导入示例:
sqoop import
--connect jdbc:mysql://mysqlserver:3306/db
--username user
--password pass
--table sales
--target-dir /data/sales
--split-by sale_id
--m 8
--fields-terminated-by '\t'
--compress
--direct
关键参数说明:
- --direct:使用数据库原生导出工具(如mysqldump)提升性能
- --compress:启用压缩减少存储空间和IO开销
- --fields-terminated-by:指定字段分隔符,便于后续处理
3 Sqoop与Hive的高效协同
3.1 集成架构设计
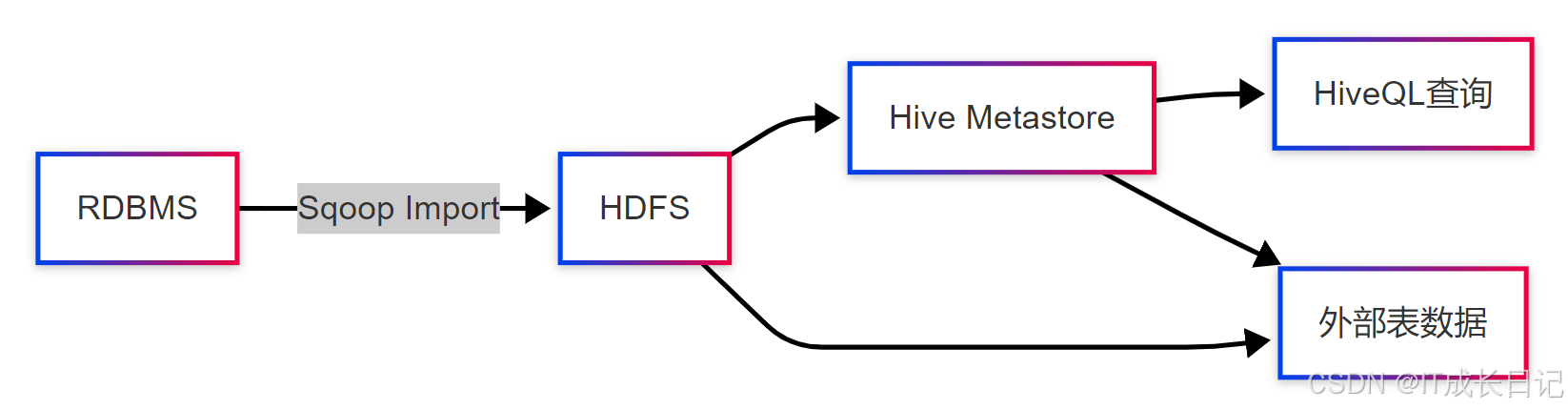
Sqoop与Hive的集成实现了从关系型数据库到数据仓库的无缝对接。这种集成主要通过两种方式实现:
- 直接模式:Sqoop自动创建Hive表并将数据加载到Hive仓库目录
- 间接模式:先导入HDFS,再通过Hive外部表关联数据文件
3.2 数据类型映射处理
Sqoop在Hive集成中需要处理复杂的数据类型转换:
|---------|---------|------|
| SQL类型 | Hive类型 | 处理方式 |
| INTEGER | INT | 直接映射 |
| VARCHAR | STRING | 自动转换 |
| DATE | STRING | 格式转换 |
| DECIMAL | DECIMAL | 精度保持 |
| BLOB | BINARY | 特殊处理 |
3.3 案例演示
-
自动创建Hive表示例:
sqoop import
--connect jdbc:oracle:thin:@//oracleserver:1521/ORCL
--username scott
--password tiger
--table customers
--hive-import
--hive-table cust_analysis
--create-hive-table
--hive-overwrite
--m 4
执行过程说明:
- 检查Hive中是否已存在目标表
- 根据RDBMS表结构生成Hive DDL语句
- 将数据导入HDFS的Hive仓库目录(通常为/user/hive/warehouse)
- 在Hive Metastore中注册表结构信息
4 Sqoop与HBase的实时集成
4.1 数据模型转换挑战
关系型数据库的二维表结构需要转换为HBase的稀疏多维映射模型,这是集成过程中的主要挑战:
- 行键设计:确定合适的ROWKEY生成策略
- 列族规划:将关系型列合理分组到列族中
- 版本控制:处理时间序列数据的版本管理
4.2 详细集成流程

关键配置参数:
- --hbase-table:指定目标HBase表名
- --column-family:设置列族名称
- --hbase-row-key:定义行键生成规则(支持多列组合)
4.3 高级特性应用
-
复合行键示例:
sqoop import
--connect jdbc:postgresql://pgsqlserver/db
--table transactions
--hbase-table tx_records
--column-family cf
--hbase-row-key "cust_id,date"
--split-by cust_id
--m 6
性能优化建议:
- 预分区:根据ROWKEY分布预先创建HBase分区
- 批量写入:调整hbase.client.write.buffer参数
- 压缩配置:启用列族压缩减少存储开销
5 Sqoop在数据仓库中的典型应用
5.1 增量数据同步方案
-
基于时间戳的CDC实现:
sqoop import
--connect jdbc:sqlserver://dbserver
--table orders
--target-dir /data/orders/incremental
--incremental lastmodified
--check-column update_time
--last-value "2023-01-01 00:00:00"
--m 4 -
增量同步架构:

5.2 数据质量保障措施
校验机制:
- 记录计数验证(--validate)
- 抽样数据比对
错误处理:- 设置--relaxed-isolation解决脏读问题
- 使用--staging-table确保事务一致性
6 总结
Sqoop作为大数据生态系统的关键组件,通过与HDFS、Hive、HBase的深度集成,构建了完整的数据管道解决方案。