Hadoop如何支持实时数据分析需求
Cloudera CMP 7.3(Cloud Data AI Platform)通过集成流处理引擎、低延迟存储系统与实时分析工具链,构建了一套端到端的实时数据分析能力体系。尽管其核心基于 Hadoop 生态,但通过组件组合与架构优化,可有效支撑金融、电信、零售等行业的毫秒至秒级实时分析需求。
以下是 CDP 7.3 支持实时数据分析的关键机制与实现细节:
一、整体架构:Lambda 架构融合批流一体
CDP 7.3 采用 " 批流融合" 架构,兼顾历史全量数据与实时增量数据:
- 批处理层:Spark / Hive(T+1 或小时级)
- 速度层(Speed Layer ):Kafka + Flink / Spark Streaming + Kudu / HBase
- 服务层:Impala / Doris / Druid(对外提供低延迟查询)
✅ 实现"一次写入、多处消费",支持实时看板、风控告警、个性化推荐等场景。
二、核心组件与实时能力详解
1. Apache Kafka (消息总线)
- 作用:作为统一的数据入口,接收来自 App、IoT、交易系统等的事件流。
- CDP 集成 :
- 内置 Streams Messaging Manager (SMM),提供可视化 Topic 管理、监控、Schema 注册(集成 Schema Registry)。
- 支持 Exactly-Once 语义 和 SSL/SASL 安全传输。
- 典型吞吐:单集群可达百万级消息/秒。
2. 流处理引擎:Flink / Spark Streaming
| 引擎 | 特点 | 适用场景 |
|---|---|---|
| Apache Flink(推荐) | 低延迟(ms级)、状态管理强、支持事件时间 | 反欺诈、实时风控、会话分析 |
| Spark Structured Streaming | 与批处理统一 API、易维护 | 实时 ETL、指标聚合 |
📌 CDP 7.3 通过 Cloudera Streams Processing (CSP) 提供 Flink 的企业级部署、监控与资源调度(基于 YARN/K8s)。
3. 实时存储层:Kudu + Impala (核心组合)
- Apache Kudu :
- 列式存储,支持 快速插入 + 快速分析;
- 兼容 HDFS 生态,但专为 实时更新场景设计(替代 HBase 在分析场景的不足)。
- Impala :
- MPP 查询引擎,直接读取 Kudu 表;
- 查询延迟通常 < 1 秒,适合交互式 BI。
- 典型用例:
Sql:
-- 实时监控大额转账
SELECT user_id, amount, timestamp
FROM kudu_transactions
WHERE amount > 50000 AND timestamp > now() - interval 5 minutes;
⚠️ 注意:在信创 ARM 环境中,Impala 不可用,常替换为 Apache Doris 或 ClickHouse。
4. HBase (高并发随机读写)
- 适用于 点查场景(如用户画像实时标签查询);
- 与 Phoenix 结合可支持 SQL 访问;
- 延迟通常在 10~100ms。
三、端到端实时分析流程示例(以银行反欺诈为例)
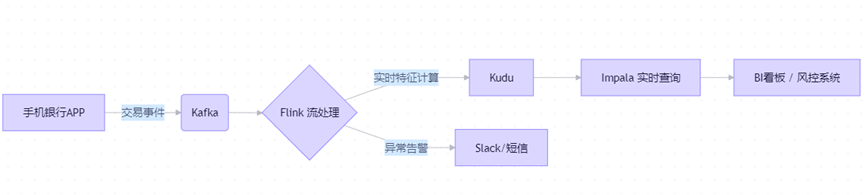
- 用户发起一笔转账 → 事件写入 Kafka;
- Flink 消费事件,结合历史行为(从 HBase 读取)计算风险分;
- 若风险分 > 阈值,立即触发拦截并告警;
- 所有交易明细写入 Kudu,供 Impala 实时分析;
- 风控人员通过 Hue 或 Superset 查看实时交易地图。
四、性能优化关键点
| 优化方向 | 措施 |
|---|---|
| Kafka | 分区数合理设置、启用压缩(snappy/lz4)、调整 linger.ms |
| Flink | Checkpoint 间隔调优、状态后端使用 RocksDB、开启背压监控 |
| Kudu | Tablet 数量匹配节点数、避免频繁 schema 变更、使用 UPSERT 而非 DELETE+INSERT |
| Impala | 启用 Admission Control、配置内存限制、使用 Parquet/Kudu 列裁剪 |
五、与 AI/ML 的实时联动(CDP 7.3 高级能力)
- MLflow + Spark ML:训练好的模型可部署为 UDF,在 Flink 或 Spark Streaming 中实时打分;
- 向量检索 :结合 Apache Doris 4.0 的 向量索引,实现"相似客户行为匹配";
- LLM 增强:通过 UDF 调用本地大模型(如 Qwen),对日志进行语义理解(如"客户投诉意图识别")。
六、局限性与应对(尤其在信创环境)
| 问题 | 应对方案 |
|---|---|
| Impala 不支持 ARM | 迁移至 Doris / ClickHouse |
| Flink 社区版监控弱 | 使用 Cloudera CSP 或自研 Flink Web UI |
| 小文件问题影响 HDFS | 实时层尽量绕过 HDFS,直写 Kudu/Doris |
| 资源竞争(YARN) | 为流任务创建专用队列,设置资源隔离 |
总结
CDP 7.3 的实时分析 = Kafka (接入) + Flink (处理) + Kudu/Impala (存储+ 查询) + CSP (运维)
它虽非纯流原生平台(如 Confluent + ksqlDB),但在企业级大数据生态中提供了高可靠、可治理、可扩展 的实时分析解决方案。在金融、电信等强监管行业,其与 Ranger、Atlas 的深度集成,更保障了实时数据的安全合规。