2025深度学习发论文&模型涨点之------光学工程+神经网络
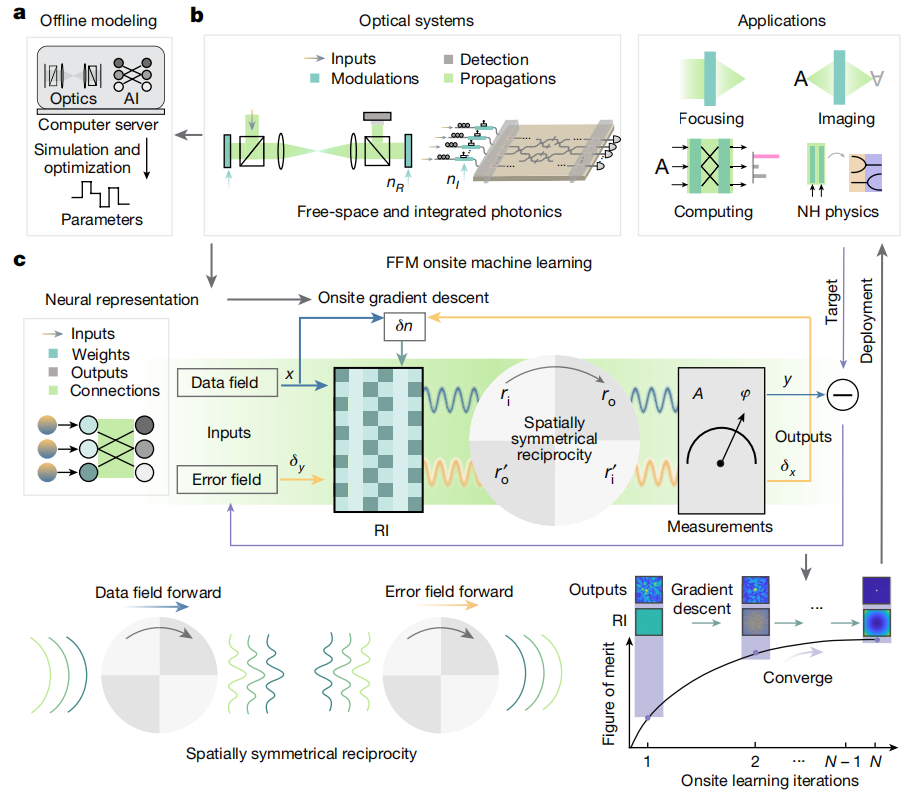
清华大学的一项开创性研究成果在《Nature》上发表,为光学神经网络的发展注入了强劲动力。该研究团队巧妙地提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法,这一方法在物理光学系统中直接执行训练过程,彻底摆脱了传统依赖数字计算机模拟的诸多限制。
清华大学的一项开创性研究成果在《Nature》上发表,为光学神经网络的发展注入了强劲动力。该研究团队巧妙地提出了一种全前向模式(Fully Forward Mode,FFM)的训练方法,这一方法在物理光学系统中直接执行训练过程,彻底摆脱了传统依赖数字计算机模拟的诸多限制。
我整理了一些光学神经网络【**论文+代码】**合集,需要的同学公众号【AI创新工场】发525自取。
论文精选
论文1:
Nature Fully forward mode training for optical neural networks
全前向模式训练光学神经网络
方法
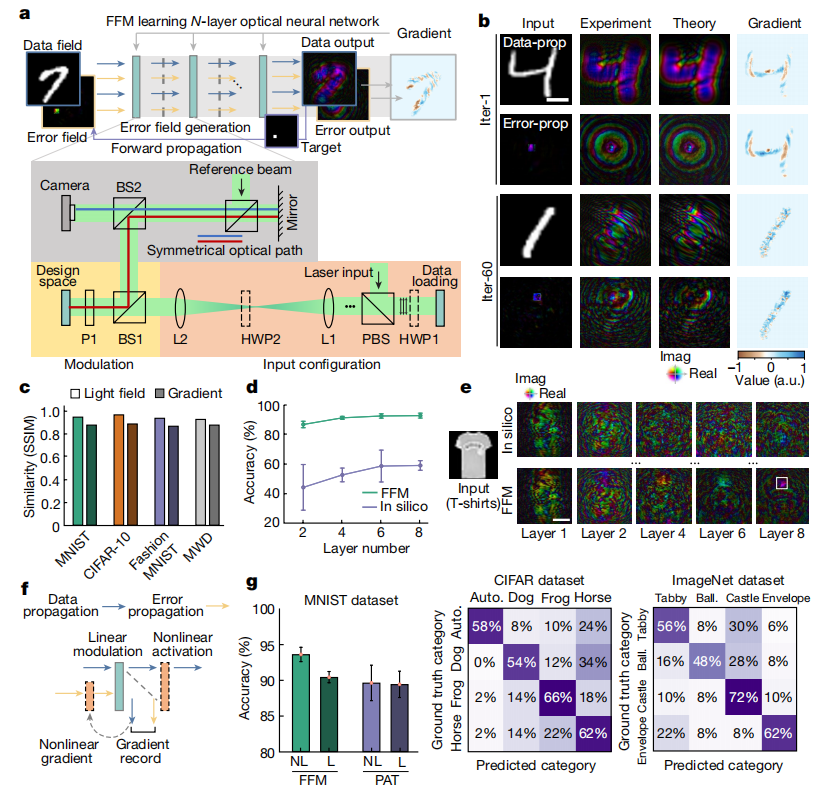
全前向模式(FFM)学习:通过在物理系统上实施计算密集型训练过程,利用空间对称性和洛伦兹互易性,消除了梯度下降训练中对反向传播的需求。
光学系统映射:将光学系统映射到参数化的现场神经网络,通过测量输出光场来计算梯度,并使用梯度下降算法更新参数。
实验验证:在自由空间和集成光子学中展示了该方法在深度光学神经网络训练中的有效性。
创新点
无需离线建模:首次提出了一种完全在光学系统上进行训练的方法,无需数字计算机进行离线建模。
性能提升:在自由空间和集成光子学中展示了该方法在深度光学神经网络训练中的有效性,实现了与理想模型相当的准确率。
能效提升:通过利用光学系统的并行性,实现了高分辨率散射成像和动态非视距成像,提高了系统的能效和性能。
论文2:
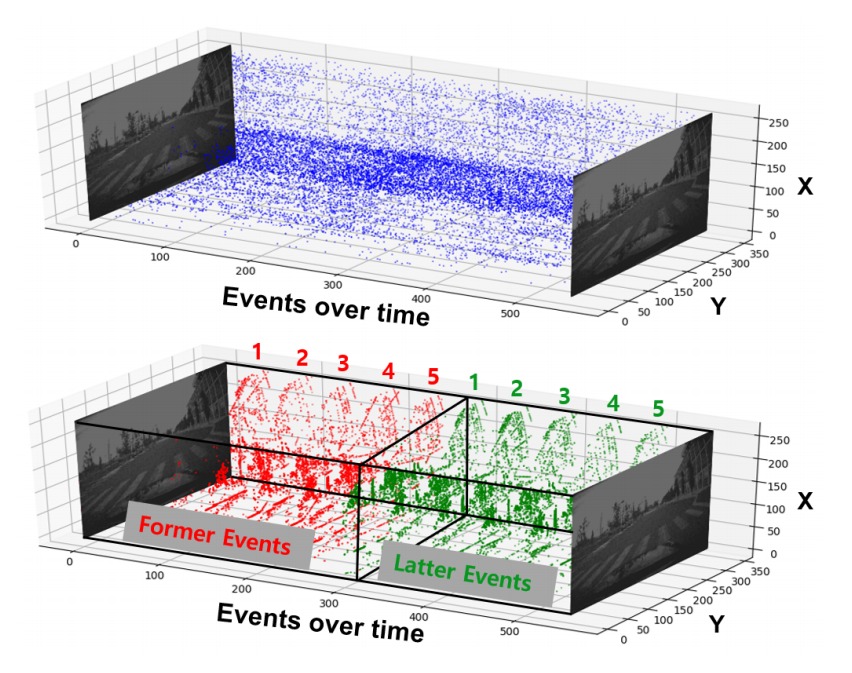
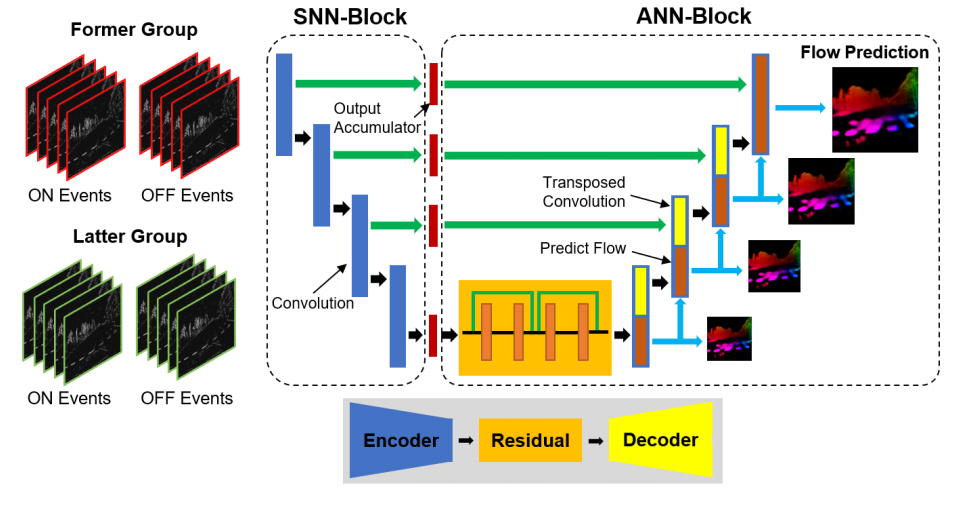
Spike-FlowNet Event-based Optical Flow Estimation with Energy-Efficient Hybrid Neural Networks
Spike-FlowNet:基于事件的光流估计与能效混合神经网络
方法
混合神经网络架构:提出了一种深度混合神经网络架构,将脉冲神经网络(SNN)和模拟神经网络(ANN)集成在一起,用于从稀疏的事件相机输出中高效估计光流。
自监督学习:通过自监督学习在多车辆立体事件相机(MVSEC)数据集上进行端到端训练。
输入表示:提出了一种新的输入表示方法,能够高效地编码事件相机的稀疏输出序列,保留事件的时空特性。
创新点
性能提升:在MVSEC数据集上,Spike-FlowNet在平均端点误差(AEE)方面优于EV-FlowNet,显示出更高的光流估计精度。
能效提升:通过结合SNN和ANN的优势,解决了深度SNN中脉冲消失的问题,同时保持了网络性能,显著提高了计算效率。
首次应用:首次在事件相机的光流估计任务中实现了与全ANN架构相当的性能,同时显著提高了计算效率。
论文3:
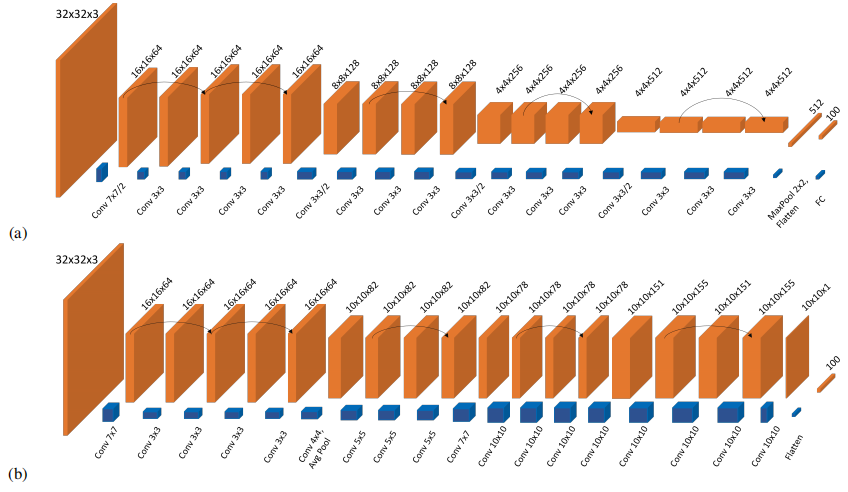
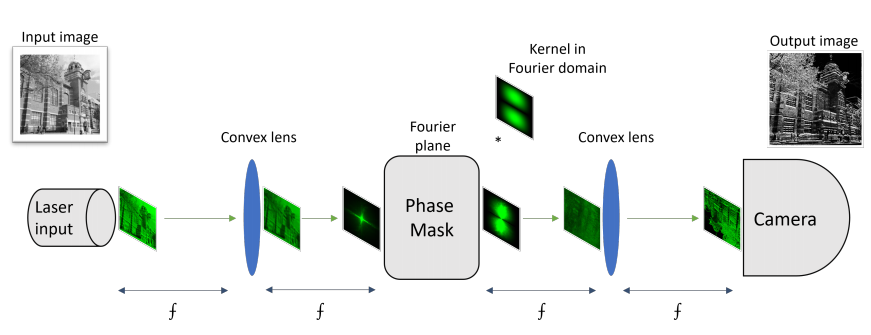
FatNet High Resolution Kernels for Classification Using Fully Convolutional Optical Neural Networks
FatNet:使用全卷积光学神经网络进行分类的高分辨率核
方法
全卷积网络架构:提出了一种全卷积光学神经网络架构,通过减少通道数量和增加分辨率,充分利用了4f系统的并行性。
高分辨率核:在4f自由空间系统中使用高分辨率特征图和核,提高了神经网络的推理速度。
光学模拟:通过模拟4f系统的光传播,验证了FatNet在光学设备中的有效性。
创新点
性能提升:与ResNet-18相比,FatNet减少了8.2倍的卷积操作,仅损失了6%的准确率。
能效提升:通过减少光学-电子转换的次数,提高了训练过程的能效,特别是在大批次大小下,FatNet在光学设备中的推理速度显著快于GPU。
首次应用:首次提出了一种适用于4f自由空间系统的全卷积网络架构,为未来光学计算时代的深度学习训练提供了一种新的方向。