热点探测使用场景
- MySQL 中被频繁访问的数据 ,如热门商品的主键 Id
- Redis 缓存中被密集访问的 Key,如热门商品的详情需要 get goods$Id
- 恶意攻击或机器人爬虫的请求信息,如特定标识的 userId、机器 IP
- 频繁被访问的接口地址,如获取用户信息接口 /userInfo/ + userId
使用热点探测的好处
提升性能,规避风险
对于无预期的热数据(即突发场景下形成的热 Key),可能会对业务系统带来极大的风险,可将风险分为两个层次:
- 对数据层的风险
正常情况下,Redis 缓存单机就可支持十万左右 QPS,并能通过集群部署提高整体负载能力。对于并发量一般的系统,用 Redis 做缓存就足够了。但是对于瞬时过高并发的请求,因为 Redis 单线程原因会导致正常请求排队,或者因为热点集中导致分片集群压力过载而瘫痪,从而击穿到 DB 引起服务器雪崩。 - 对应用服务的风险
每个应用在单位时间所能接受和处理的请求量是有限的,如果受到恶意请求的攻击,让恶意用户独自占用了大量请求处理资源,就会导致其他人畜无害的正常用户的请求无法及时响应。
因此,需要一套动态热 Key 检测机制,通过对需要检测的热 Key 规则进行配置,实时监听统计热 Key 数据,当无预期的热点数据出现时,第一时间发现他,并针对这些数据进行特殊处理。如本地缓存、拒绝恶意用户、接口限流 / 降级等
京东热点探测
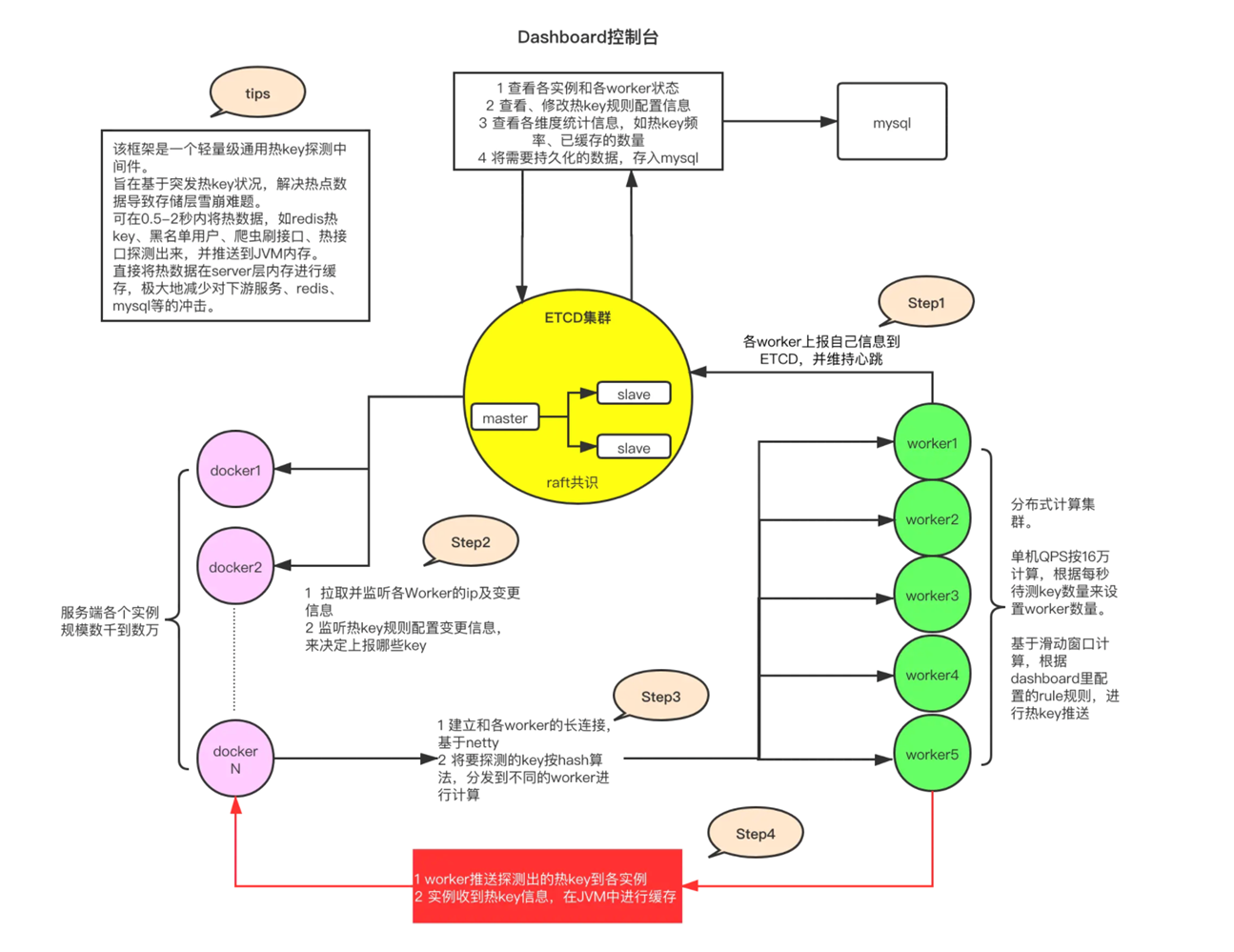
- 热点规则:配置热 Key 的上报规则,圈出需要重点监测的 Key
- 热点上报:应用服务将自己的热 Key 访问情况上报给集中计算单元
- 热点统计:收集各应用实例上报的信息,使用滑动窗口算法计算 Key 的热度
- 热点推送:当 Key 的热度达到设定值时,推送热 Key 信息至所有应用实例
- 热点缓存:各应用实例收到热 Key 信息后,对 Key 值进行本地缓存

client
热key上报 ,key的访问次数积攒起来,等待每半秒发送一次。
为了防止阻塞IKeyCollector使用两个ConcurrentHashMap切换,实现轮流提供读写、暂存key的操作。上报时譬如采用定时器,每隔0.5秒调度一次push方法 。在上报过程中,不应阻塞写入操作。所以计划采用2个HashMap加一个atomicLong,如奇数时写入map0,为1写入map1,上传后会清空该map。
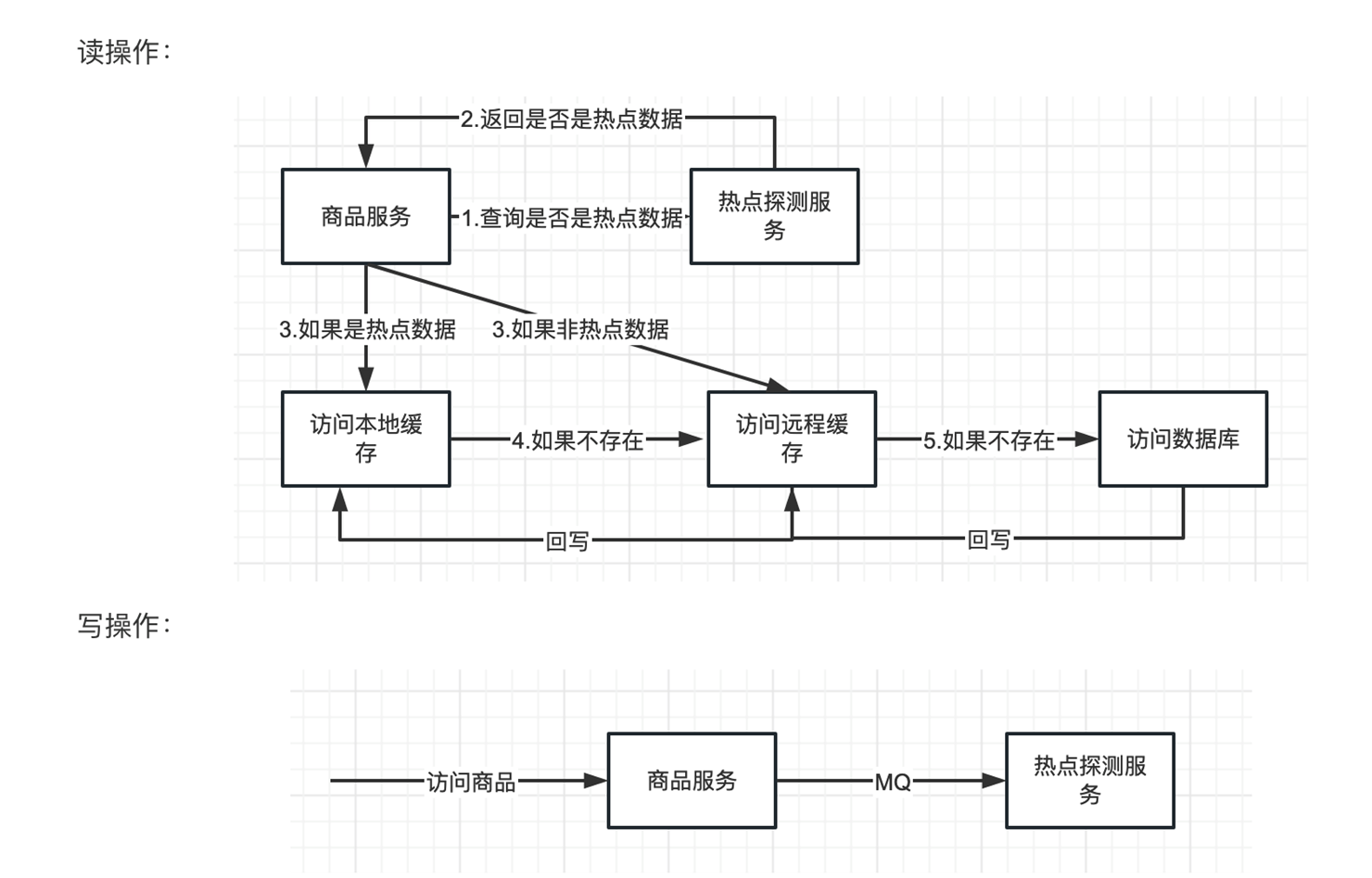
热key新增/删除,监听有新key推送事件,收到来自于worker的新增key
worker
收集各应用实例上报的信息,使用滑动窗口算法计算 Key 的热度。当 Key 的热度达到设定值时,推送热 Key 信息至所有应用实例。和dashboard那边的推送主要区别在于,给app 推送每10ms一次 ,dashboard 那边1s一次。