MySQL中COUNT语句
在数据分析和日常开发中,统计数据量是最基础也是最常见的需求。MySQL作为主流关系型数据库,提供了强大的COUNT函数来满足各种计数需求。本文将带您深入探索COUNT(*)、COUNT(1)和COUNT(字段名)三种形式的内部原理、性能差异和适用场景,并通过丰富的实例帮助您全面掌握这一重要工具。
三种COUNT函数的解析
COUNT(*)
COUNT(*) 统计表中的所有行数,包括那些包含NULL值的行。MySQL对COUNT(*)做了特殊优化,它并不会真正去读取所有字段的数据,而是:
- 在MyISAM引擎中:直接从表的元数据中获取行数,几乎是瞬时返回的
- 在InnoDB引擎中:由于MVCC(多版本并发控制)机制,MySQL会选择最小的可用索引进行全表扫描,通过检查行的存在性来计数
例如,对于一个包含用户信息的表:
sql
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
age INT,
status TINYINT
);
-- 插入一些测试数据
INSERT INTO users VALUES
(1, 'Alice', 'alice@example.com', 28, 1),
(2, 'Bob', 'bob@example.com', NULL, 1),
(3, 'Charlie', NULL, 35, 0),
(4, NULL, NULL, NULL, 1);
-- 使用COUNT(*)统计
SELECT COUNT(*) FROM users; -- 结果: 4
可见无论某些字段是否为NULL,COUNT(*)都会将这些行计入总数。
COUNT(1)
COUNT(1)同样统计所有行,但其工作方式略有不同:
- MySQL会为每一行生成一个常量值 "1"
- 然后对这些常量进行计数
- 优化器通常会将COUNT(1)优化为与COUNT(*)几乎相同的执行方式
以上表为例:
sql
-- 使用COUNT(1)统计
SELECT COUNT(1) FROM users; -- 结果: 4
-- 甚至可以使用任意常量
SELECT COUNT(999) FROM users; -- 结果也是: 4

COUNT(字段名)
COUNT(字段名)只会统计指定字段非NULL值的行数:
- MySQL必须读取指定字段的实际值
- 判断该值是否为NULL
- 仅统计非NULL值的行
以上表为例:
sql
-- 统计name字段非NULL的行数
SELECT COUNT(name) FROM users; -- 结果: 3 (因为有一行name为NULL)
-- 统计age字段非NULL的行数
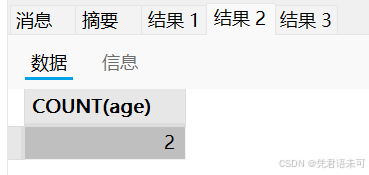
SELECT COUNT(age) FROM users; -- 结果: 2 (有两行age为NULL)
-- 统计email字段非NULL的行数
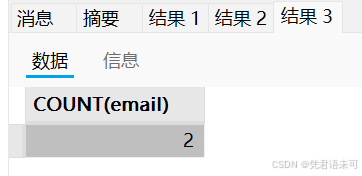
SELECT COUNT(email) FROM users; -- 结果: 2 (有两行email为NULL)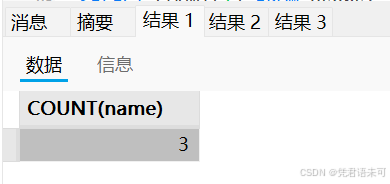
详细性能比较与实测分析
性能差异的理论基础
-
COUNT(*)和COUNT(1):
- 在现代MySQL版本中(5.7以后),两者性能几乎相同
- 优化器会对它们采用相似的执行计划
- 都不需要读取具体数据,只需确认行的存在性
-
COUNT(主键):
- 需要读取主键值,但主键通常有聚集索引
- 性能略低于COUNT(*),但差异很小
-
COUNT(普通索引字段):
- 需要读取索引值并检查NULL
- 可以利用覆盖索引优化
- 性能次之
-
COUNT(无索引字段):
- 需要进行表扫描读取字段值
- 性能最差
实际性能测试案例
假设我们有一个包含100万条记录的订单表:
sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
product_id INT,
amount DECIMAL(10,2),
status TINYINT NOT NULL,
created_at DATETIME,
INDEX idx_user_id (user_id),
INDEX idx_status (status)
);性能测试结果可能如下:
| COUNT类型 | 执行时间(秒) | 扫描行数 | 使用索引 |
|---|---|---|---|
| COUNT(*) | 0.341 | 1,000,000 | PRIMARY |
| COUNT(1) | 0.345 | 1,000,000 | PRIMARY |
| COUNT(id) | 0.352 | 1,000,000 | PRIMARY |
| COUNT(user_id) | 0.358 | 1,000,000 | idx_user_id |
| COUNT(product_id) | 0.621 | 1,000,000 | 全表扫描 |
注:实际执行时间会根据服务器配置、数据分布和MySQL版本而有所不同。
实际案例解析
案例1:电商平台订单统计
sql
-- 场景:统计所有订单数量
SELECT COUNT(*) FROM orders; -- 推荐使用,语义清晰
-- 场景:统计有效订单数(product_id不为NULL)
SELECT COUNT(product_id) FROM orders; -- 正确,只统计有商品的订单
-- 错误用法示例
SELECT COUNT(*) FROM orders WHERE product_id IS NOT NULL; -- 性能较差,需要先过滤再计数案例2:带条件的计数比较
sql
-- 统计不同状态的订单数量
SELECT
status,
COUNT(*) AS total_orders,
COUNT(product_id) AS orders_with_product
FROM orders
GROUP BY status;结果可能如下:
| status | total_orders | orders_with_product |
|---|---|---|
| 0 | 300,000 | 290,000 |
| 1 | 500,000 | 495,000 |
| 2 | 200,000 | 198,000 |
这显示了总订单数与有商品订单数的差异,帮助分析订单质量。
案例3:性能优化实例
对于大表统计,可以使用近似计数优化:
sql
-- 使用EXPLAIN ANALYZE查看执行计划和性能
EXPLAIN ANALYZE SELECT COUNT(*) FROM orders;
-- 对于仅需近似值的场景,可以使用近似统计
SHOW TABLE STATUS LIKE 'orders'; -- 查看表的行数估计值
-- 创建汇总表进行性能优化
CREATE TABLE order_stats (
stat_date DATE PRIMARY KEY,
total_orders INT,
orders_with_product INT
);
-- 每日更新统计数据
INSERT INTO order_stats
SELECT
CURRENT_DATE(),
COUNT(*),
COUNT(product_id)
FROM orders;COUNT函数与索引的关系详解
索引选择策略
MySQL在执行COUNT操作时,会尝试选择最小的可用索引来减少I/O开销:
sql
-- 为测试准备不同大小的索引
CREATE INDEX idx_small ON orders(status); -- 小索引,不同值少
CREATE INDEX idx_large ON orders(user_id); -- 大索引,不同值多
-- 观察MySQL的索引选择
EXPLAIN SELECT COUNT(*) FROM orders;以user表为例:

通常MySQL会选择idx_small索引,因为它占用空间更小,可以减少I/O操作。
特定字段计数的索引优化
sql
-- 优化特定字段的COUNT
CREATE INDEX idx_product_id ON orders(product_id);
-- 比较优化前后
EXPLAIN ANALYZE SELECT COUNT(product_id) FROM orders;创建索引后,COUNT(product_id)可以使用覆盖索引,避免访问主表数据,性能显著提升。
COUNT函数常见误区与最佳实践
误区1:使用COUNT(1)替代COUNT(*)认为更快
sql
-- 两者性能几乎相同
SELECT COUNT(*) FROM large_table;
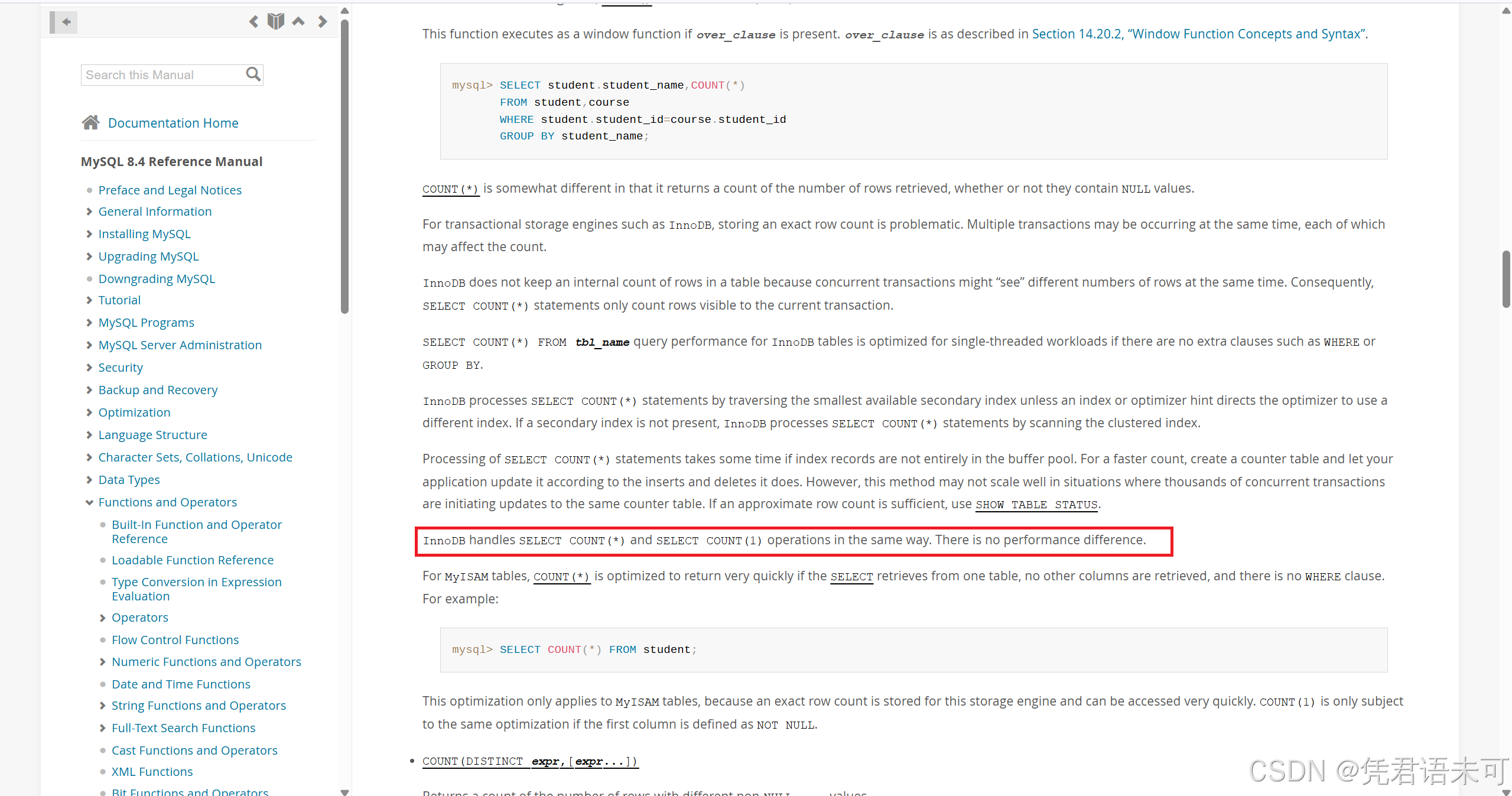
SELECT COUNT(1) FROM large_table; 事实:现代MySQL优化器使两者性能基本一致,COUNT(*)的语义更为清晰。而且我们从MySQL的官网描述中也可以看出二者在性能上没有差异 !
误区2:COUNT(字段名)可直接替代WHERE条件过滤
sql
-- 错误示例
SELECT COUNT(status) FROM orders; -- 不会过滤status=0的记录,只会过滤NULL
-- 正确用法
SELECT COUNT(*) FROM orders WHERE status <> 0;实践示例
以user表为例:
sql
-- 1. 统计基本行数
SELECT COUNT(*) FROM users;
-- 2. 需要排除NULL值时
SELECT COUNT(email) FROM users;
-- 3. 高效统计组合条件
SELECT
COUNT(*) AS total_users,
SUM(CASE WHEN age > 30 THEN 1 ELSE 0 END) AS users_over_30,
COUNT(email) AS users_with_email
FROM users;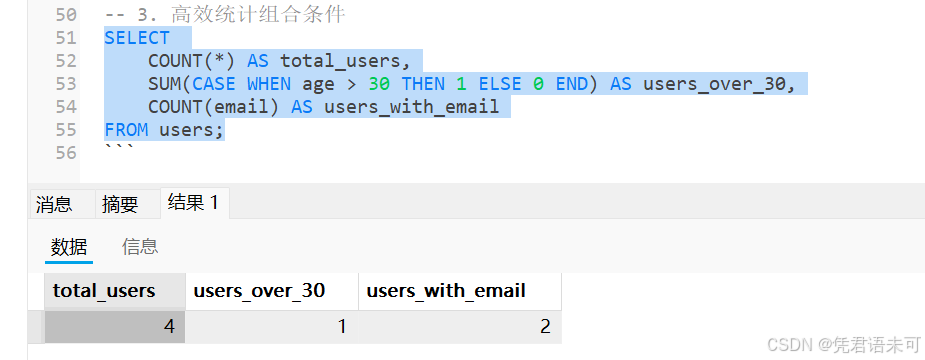
总结
MySQL的COUNT函数虽看似简单,但内部机制与优化策略却十分精妙。理解这些差异可以帮助我们:
-
选择合适的COUNT形式:大多数情况下使用COUNT(*)计数总行数,需要排除NULL值时使用COUNT(字段名)
-
优化大表统计:
- 考虑使用汇总表预计算
- 对于MyISAM表利用其元数据快速统计
- 建立合适的索引支持特定字段计数
-
避免常见陷阱:
- 不要迷信COUNT(1)比COUNT(*)快
- 理解NULL值对COUNT(字段名)的影响
- 注意COUNT与GROUP BY结合使用的性能影响
通过深入理解这些COUNT函数的内部原理和适用场景,我们可以在实际开发中更加得心应手地处理各种统计需求,提升查询性能和代码质量。