继承的概念及定义介绍
什么是继承,继承是面向对象而言的,他的地基是基于类而言的。最简单的介绍就是,一个类继承了另一个的成员,可以使用这个类成员,并且可以在此基础上,定义自己的成员,从而实现自己的功能。
继承这一概念是取自于生活中而言的,面向对象的语言创建就是基于生活中而抽取概念。一般市面上讲继承都会拿Person和Student,这两个类介绍。大体就是说,这个学生既有Person的特性又有Student的特性,那这时候我们就可以提取这个Person特性,把它单独创建成一个类,让Studnet继承他,这样子以后创建其他类时,比如Teacher,它也可以继承Person类,因为这些类都有一个共性就是人的特性,比如名字,身份证,年龄等等,这和我们生活中时很相似的,就像你和你的老师,都有身份证和年龄。我们一般管这个继承类叫做派生类/子类,被继承类叫做基类/父类。
先看看代码
cpp
class Person
{
protected:
string _name;
int _id;
int _age;
};
class Student : public Person
{
protected:
int _num; //学号
string _class;//班级
};他的语法是在派生类的后面加一个冒号 + 继承方式 + 类名,那什么是继承方式呢?继承方式和访问限定符的关键字一样,都是只有三个,private,protected,public。如果你没有指定继承方式,类是默认私有,结构体是默认公有。
这些继承方式和访问限定符搭配有九种不同的情况,详细满足了生活中的各种情况。这里的定义是,访问限定符和继承方式选择访问范围更小的哪一个。对于private的成员,在子类也不可见,也就是无法访问。私有成员只能在本类访问。但除了private成员都可以在子类访问。这里private(访问方式)是在访问限定符和继承方式之间选择权限更高的。拿上面的代码举例,Person的成员访问限定符是protected,继承方式是public,所以访问方式是protected,不是私有,所以他可以在Student里访问。这里九种的搭配方式属于有点太复杂了,一般使用继承就是要在子类里访问父类的成员,可是这里祖师爷居然连私有子类不能在子类里访问,这种情况都给我们想到。有点高估我们的需求了。虽然现实生活中确实有类似于这种情况,父亲去世后,资产没有全部给儿子,而是留去一部分给公益。但是对于我们使用这而言,很少有这种需求。这也可能是因为祖师爷再创建这部分知识的时候,也没有前人借鉴,只能取自于生活,原本是想着满足多种需求,没想到是想的复杂了。我们平常在使用的时候,一般就是protected加public的组合就够用了。
基类和派生类的对象的转换
首先支持子类对象自动转换到父类对象,这部分转换语法上称赋值兼容,也被称为切片或切割。子类转换到父类是不会产生临时对象的,这是他和内置类型隐式类型转换的本质区别。之所以,他被叫切片/切割,是一种比喻的手法,就像从子类中把父类的成员切割掉,然后再拷贝到父类中。实际上底层也和这很相似,底层是只会去匹配父类的域,赋值父类的成员。所以,这也被形象的比喻成切片。
cpp
Student s;
//没有产生临时对象
Person& p = s;
int i = 1;
double& d = i; //产生临时对象那父类可以转换成子类吗?实际上是可以的。不过这部分知识需要满足特定情形。设计到一些后面的知识。我们先知道他是有办法做到就行。本篇博客不对这部分知识讲解。
继承中的作用域
父类和子类是是一个域吗?还是他们不是一个域。如果不是一个域为啥子类可以访问父类的成员呢?答案是:两个独立的域,子类可以访问父类的成员,是因为他是protected的访问方式,这是c++的语法设计。这里再多嘴一句,这里的涉及的成员包括成员函数和成员变量,我在学习这部分知识的时候,就以为只有成员变量,就搞混了。
既然是两个独立的域?那如果子类和父类的成员重命,那这咋办?外界访问,是访问那个?这里就是就近原则,优先访问子类里的成员。这里语法上c++称为隐藏,也有人称重定义。这也是比喻的手法,仿佛子类的成员覆盖了父类的成员一样。实际上底层,人家就没去父类里去找。
大家看看这段代码结果是啥?
cpp
#include <stdio.h>
#include <iostream>
#include <string>
using namespace std;
class Person
{
public:
void fun()
{
}
protected:
string _name;
int _id;
int _age;
};
class Student : public Person
{
public:
void fun(int i)
{
}
protected:
int _num; //学号
string _class;//班级
};
int main()
{
Student s;
s.fun();
s.fun(1);
return 0;
}是符合重载呢 还是符合隐藏 还是直接无法运行呢
答案是无法运行,编译直接报错。这里成员函数是构成隐藏的,注意这里构成隐藏只需要满足名字相同就可以,至于其他条件是否有参数(成员函数)不管,这里没有指定域,所以默认在子类去找,首先函数名匹配,但发现形参不匹配,因此会编译报错。
这里建议尽量不要在继承体系中定义同名成员,会有很多坑,实际中也很少这样做。
派生类的默认成员函数
这里所谓的默认是指我们不写,编译器自动生成,这里就不介绍取地址重载和const修饰的取地址重载,这两个的使用少到可怜,基本不用自己实现。
构造函数
这里语法规定,我们不用在子类的构造函数里去再自己写一个父类的构造函数,完成父类的初始化,语法也不允许你这样做,他让你直接调用父类的构造函数,这里调用必须是在初始化列表里,这里是和初始化顺序有关,你必须先初始化父类成员再初始化子类成员,这其实很好理解,你和你父亲的关系,肯定是先有你父亲才有你吧。如果你不显示调用,那编译器会自动调用。要注意,编译器只能调用父类的默认构造函数,如果父类没有默认构造函数,那你需要手动调用。
cpp
Student(string name, int id, int age,int num,string cls)
:Person(name,id,age),
_num(num),
_class(cls)
{
}拷贝构造
和构造函数类似,必须调用父类的拷贝构造函数,但不过你必须要显示调用,因为拷贝构造是有参数的,编译器不能自动调用,如果你不写,那调用的是默认的构造函数,那这效率就不能保证了。
cpp
Student(const Student& s)
:Person(s),
_num(s._num),
_class(s._class)
{
}赋值重载
赋值重载也是一样,调用父类的赋值重载,如果你不写,编译器会调用父类的赋值重载,但是如果你显示调用就必须指定域名,因为默认会在子类中寻找,这里因为构成隐藏,导致会栈溢出。也是一样,如果不写编译器自动调用父类的赋值重载,但是如果涉及到深拷贝,你必须显式调用。
cpp
Son& operator=(const Son& s)
{
if (&s != this)
{
//你可以直接不调用
//如果涉及到了深拷贝 就要显示调用
//Father::operator(s)
_c = s._c;
}
return *this;
}析构函数
析构函数没有上面这么多规矩,因为栈的先进后出的特性,决定必须是父类后被析构。这里祖师爷为了防止你瞎搞,直接语法规定子类析构函数调用完成后,自动调用父类的析构函数。所以,你根本不用自己写,只用管自己子类的析构编写就行了。这里即使你在子类的析构函数调用了父类的析构函数,编译器还是会在子类析构函数执行完毕后,自动调用父类的析构函数。
继承与友元
友元不能继承,这里一句话就能说清楚,你父亲的朋友不一定是你的朋友,友元是双向奔赴,不是单方面继承,和爱情一样,你喜欢人家,人家不喜欢你,那叫舔狗。
继承与静态成员
静态成员可以继承,但是在继承体系中他们只有一个静态成员,也就是说,他们共享一个成员,他和中央空调一样,谁都可以用,但是不单独属于某一个人。
复杂的虚拟继承和菱形继承
一般来讲,学继承到这里就应该结束了。但是c++支持多态继承,这就很复杂了。虽然这很符合生活中的情形,你既有你爸爸的特征又有你妈妈的特征,你不仅可以继承你爸爸的财产还可以继承你妈妈的财产。但是这放在编程里可就复杂了。随便举一个例子,如图
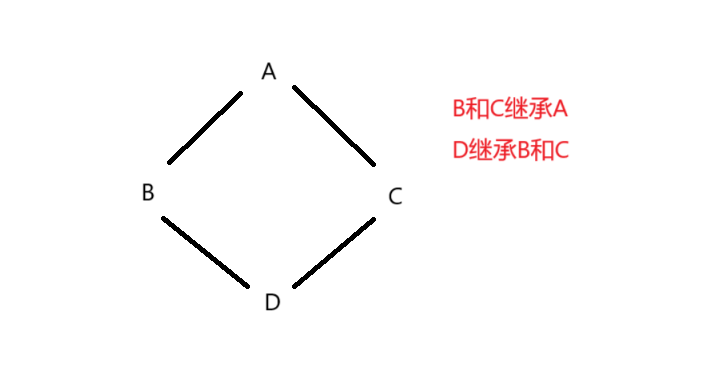
我就问你,D里是有两份A的成员呢?还是只有一份呢?两份不就重复了吗?这不是没意义吗?重复的多继承一份成员, 如果你继承的不是财产是负债呢?按照我们祖师爷原来的语法是这样的,D有两个A的成员,你要赋值,需要指定类域。后面为了补齐这个坑,他增加了一个虚继承的语法,就是说,B和C虚继承A,这样子,B和C就不是直接存储A的成员,而是存储一个指针,这个指针指向一块地址,我们称这块地址指向的空间虚基表,这个指针叫虚基表指针,虚基表存储一个偏移量,这块存储指针的地址加上偏移量就是这个成员的地址。也就是说,他把重复的成员存储提取,只存取一份,B和C里都共用这个,只不过他们的偏移量可能不同,但不过都可以通过偏移量找到那个共同的成员地址,访问该成员。一般这个被提取的成员是在最后或者开头,我们访问这个成员也是可以直接访问,就算通过类域访问,也可以通过偏移量找到,就算切片,也是可以通过偏移量完成赋值。正是因为他的这种偏移量设计,才让访问得到统一。但其实这底层是很复杂,一般底层涉及地址和指针这块结合,就不简单。

我们可以计算一下不加虚拟继承和加上虚拟继承的大小,你会发现加了虚拟继承的还多4字节,这咋还多呢?实际上这是分情况的,你这里数据比较小,但如果你的数据是一个数组呢?数据类型为int,大小为128,你看这不对半节省吗。所以他是能解决数据冗余的问题。这里还涉及第二个问题就是第二语义性的问题,你多出来的成员A到底是算B的还是算C的,还是算D的。你要知道这是一个D类型的对象,应该算D的吧。如果这个A的成员表示一个人的IDCard,你还觉得它可以算C的还是D的,因此直接把它单独提取,谁都可以共用他。
注意这里的语法是在腰部的位置虚继承他,不是在最终类的位置虚继承。这里成员A在这里的继承体系中只有一份,既然只有一份,那他就会只调用一次构造函数。即使你在每个类里都显示调用了A的构造函数,那天也只会在D类的位置里调用A的构造函数。
上面的这种情况我们称为菱形继承。实际上多继承可以认为是c++的一个缺陷,祖师爷设计的时候也是没想好,出发点是很好,可是一到别人使用的时候,就发现你这不对呀。然后祖师爷就苦思冥想,咋改这个坑。这里如果直接把菱形继承禁止掉,多继承就不会有这么多问题,但是他确实保留了,那我们就只能谨慎使用了。如果非要使用菱形继承,就要使用菱形虚拟继承,解决数据冗余和第二语义性问题。其实我们库里的IO流就是这样设计的,这我也不知道他是咋想的。
总结
关于c++的继承确实有点复杂,但这确实证明了c++非常灵活,只要你能把握住,想咋玩就咋玩。一般我们不全使用继承,也会使用组合,主要看那个更符合语义。比如轮胎和车子,这个就更适合组合,就是在车类里私有声明一个 轮胎类。但是有时候还是继承符合语义,那我们就用继承。如果你发现他既符合组合的语义又符合继承的语义,那优先使用组合。这里其实和黑白盒测试相关。黑盒测试(看不见内部实现,通过功能写测试 ) ,白盒测试(看见内部实现,根据内部实现写测试 ),为啥使用组合,这下明白了吧,明显组合使用更简单,也就是我们的黑盒测试。如果使用的是继承,那你就要全方面考虑情况,搭配白盒测试,你就要看懂内部实现的代码。优先使用组合还有一个原因就是,高内聚(功能单一)低耦合(相关程度低),这是软件开发的一个评判的黄金原则。