今天我们尝试对一份社交媒体成瘾的调查数据进行几项简单的分析,看看可以得出哪些有意思的结论?图1A是这份数据的说明,因为篇幅太长只把部分数据贴出来(图1B)。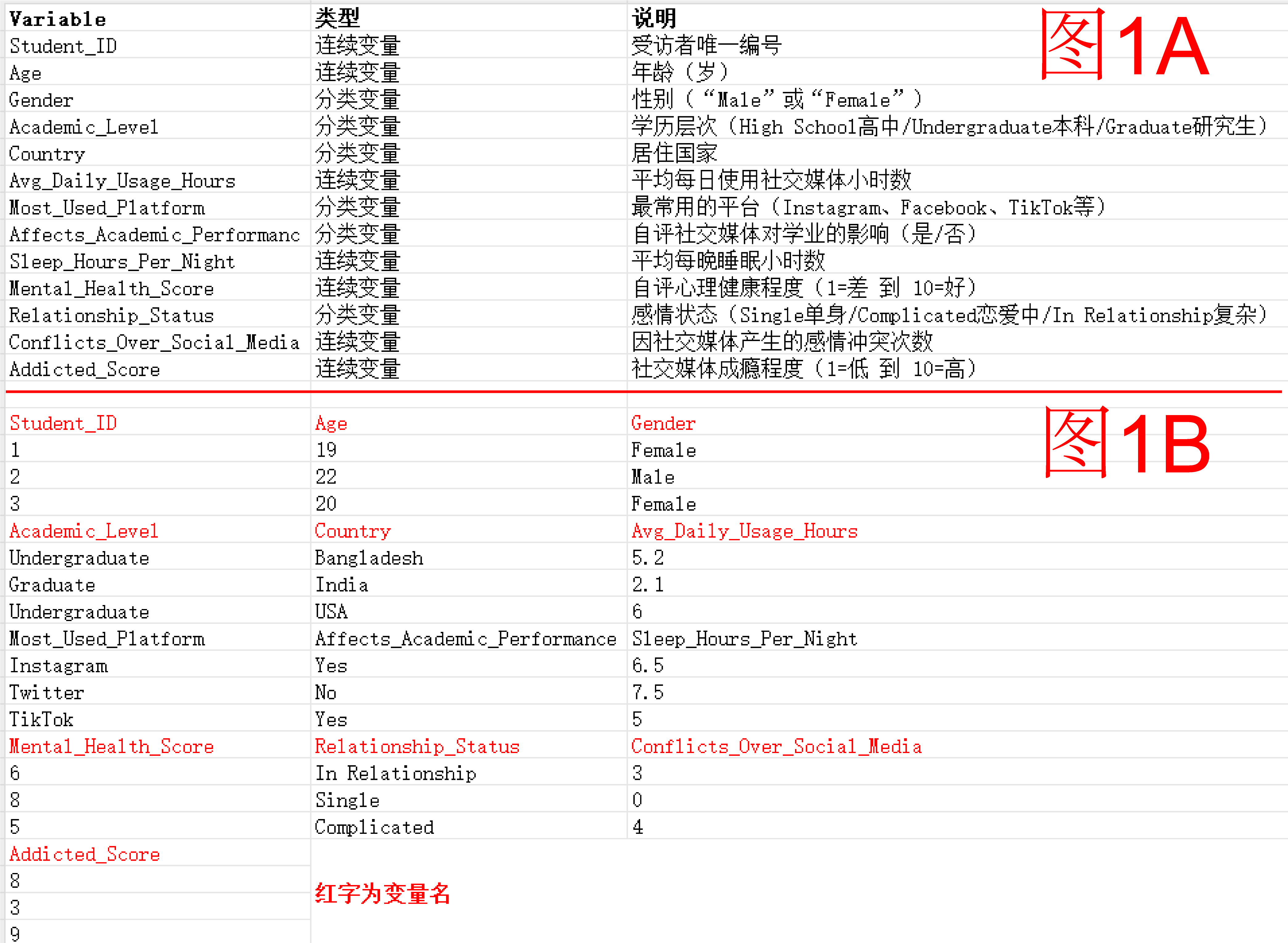
01 不同性别的成瘾程度会不同吗?
我们使用bootstrap方法对男生女生的成瘾分数进行了求平均,发现女生的平均值为6.515187,置信区间为6.334350, 6.702478,女生的平均值为6.359707,置信区间为6.204545 6.519814(图2)。从平均值来看,女生略高于男生,但是由于两者的置信区间存在重合,因此在统计学上认为不同性别的成瘾分数不存在显著的高低差异。这说明可能其实大家都爱玩手机。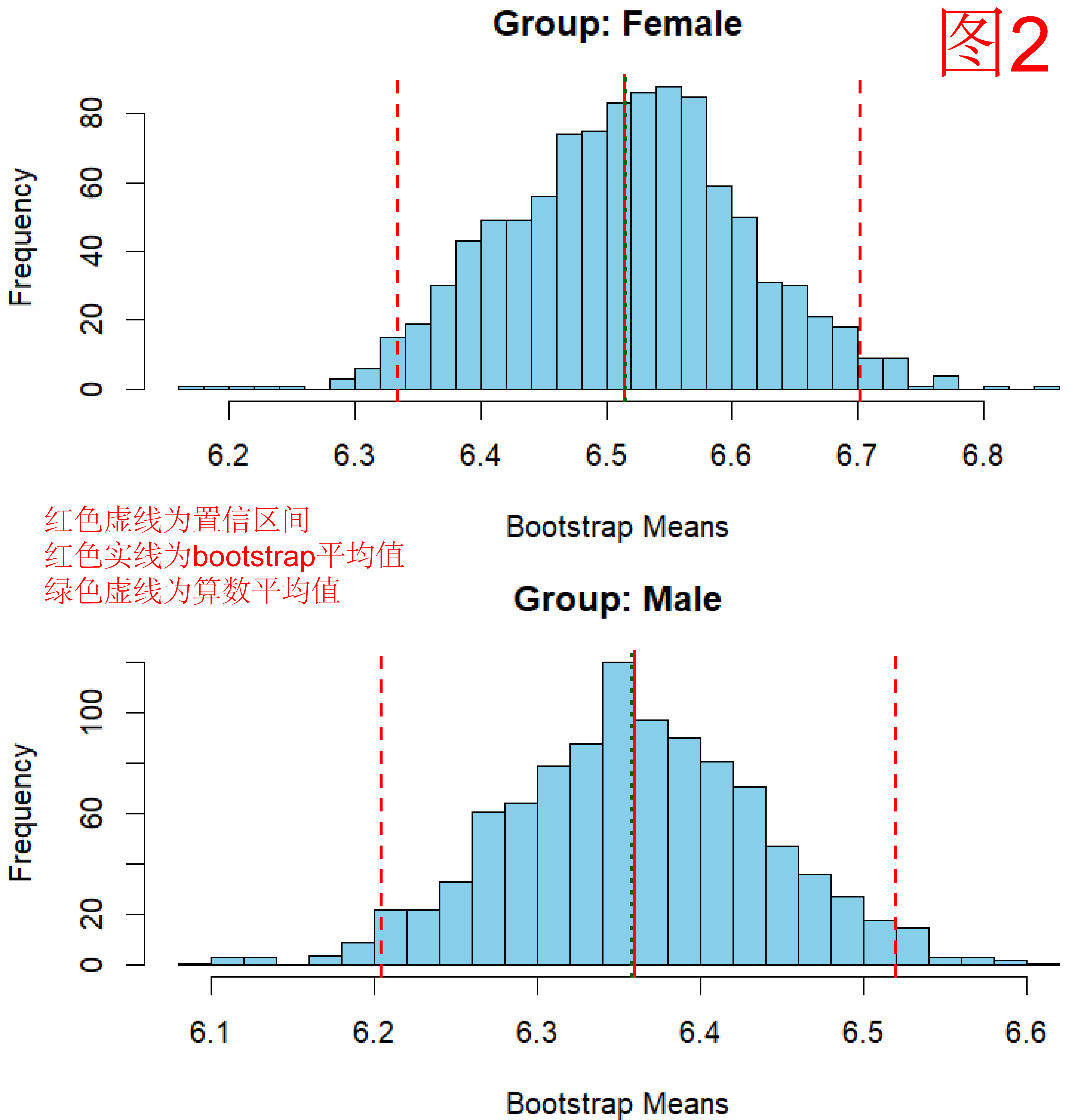
02 是什么在影响成瘾程度高低?
我们把问卷中的连续变量作为自变量,社交媒体成瘾程度作为因变量,进行多元线性回归。看看哪些是显著影响成瘾程度的重要因素。结果发现(图3),模型整体拟合度极高(调整后的R²约为0.94),p值小于0.01,说明以上变量能很好地解释成瘾程度的变化。
·睡眠时间(Sleep_Hours_Per_Night)对成瘾程度有显著负向影响,系数约为 -0.21,且p值极小(< 0.001),说明睡得越少,成瘾得分越高。换句话说,睡眠不足的人更容易出现社交媒体成瘾问题。
·心理健康评分(Mental_Health_Score)同样显著且负相关,估计值约为 -0.67,表明心理健康状况越好,成瘾得分越低。心理状态不佳可能增加成瘾风险。
·社交媒体冲突(Conflicts_Over_Social_Media)则与成瘾程度呈显著正相关,估计值约为 0.67,说明经常因社交媒体产生冲突的人,成瘾风险更高。
·年龄和日均使用时长(Avg_Daily_Usage_Hours),并未显著影响成瘾程度,这意味着单纯的使用时间和年龄并非成瘾的关键因素。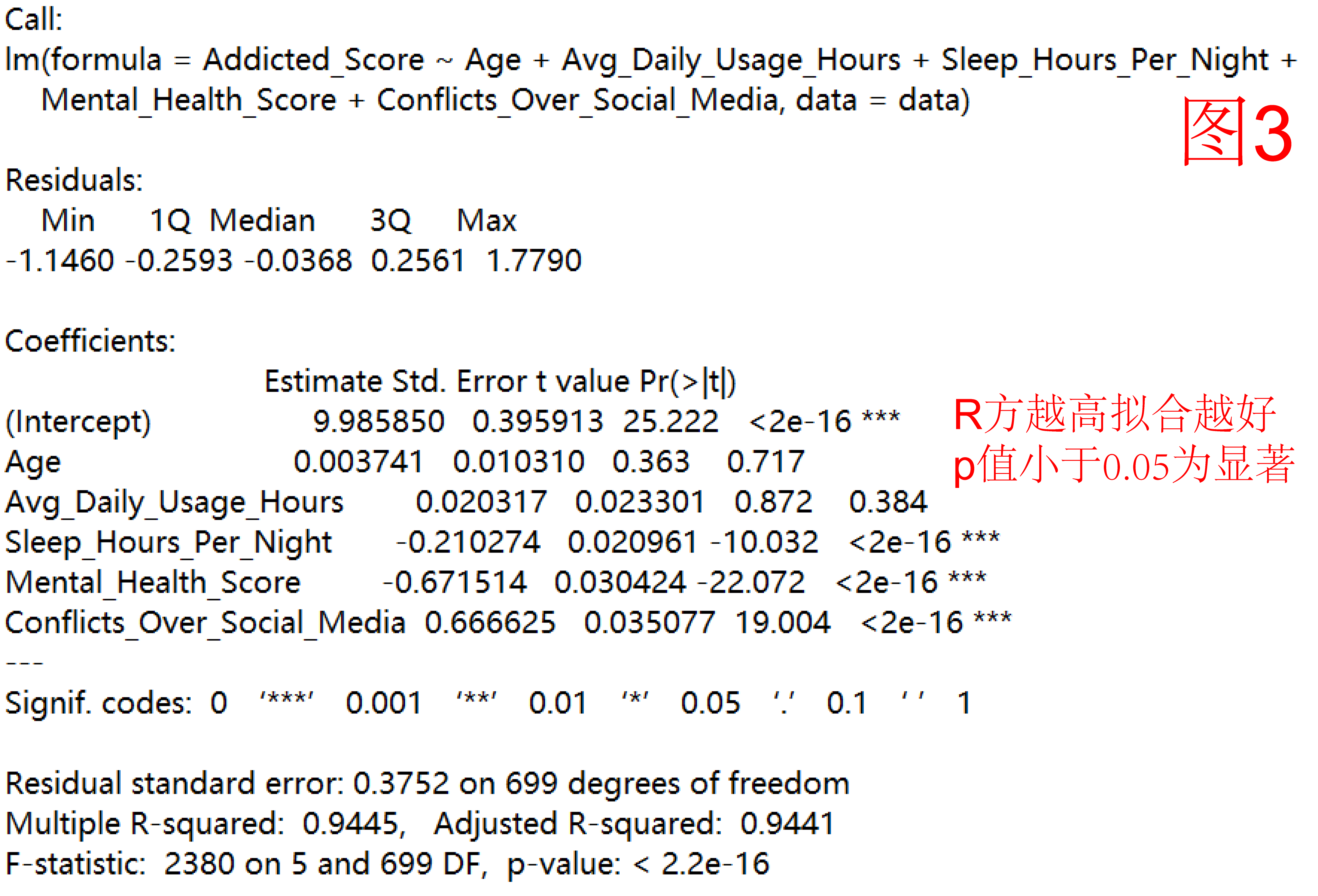
03 社交媒体成瘾者的几种"画像"
这部分其实就是聚类,因为我们要追求真实性,所以要把所有变量都纳入分析,但层次聚类和K-mean聚类都是针对连续变量的,因此在这里我们使用了Gower距离 + PAM 聚类的方法,聚类前使用轮廓系数确定聚类簇数(图4A)。结果把所有受访者分为了4个群体(图4B):
类群1:重度依赖型
以年轻本科女生为主,日均使用时间最长(5.64h),多使用Instagram,普遍认为影响学业,精神状态差、冲突多、成瘾程度最高,为典型的高风险群体。
类群2:理性使用者
以年长研究生男性为主,使用时间最短(3.79h),多用 Facebook,学业影响最小,心理状态最佳、成瘾最低,是最健康节制的一群用户。
类群3:适度使用者
与类群1相似的年轻女性群体,但使用时长较短(3.83h)、影响较小、心理状态良好、成瘾程度低,表现出较好的自控力和使用节制。
类群4:隐性高风险者
研究生男性居多,使用时间高(5.44h),以 TikTok 为主,学业受影响,心理状态一般,成瘾程度高,可能为娱乐性或被动沉迷的使用者。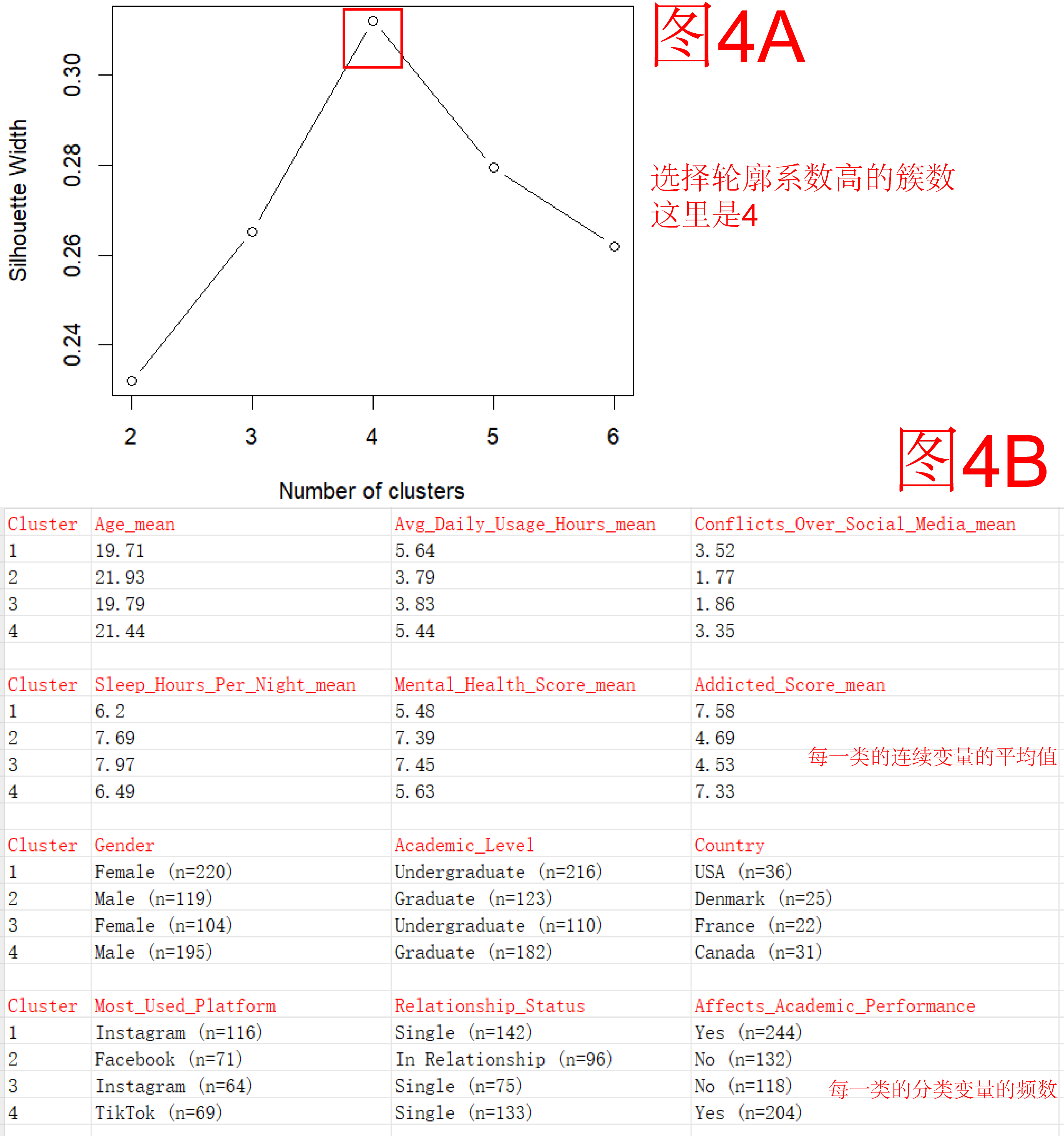
数据无偿分享供练习使用,只求一个小小的关注。
TomatoSCI科研数据分析平台,欢迎大家来访!