全文链接:tecdat.cn/?p=42358
分析师:Li Ting
在数字化商业浪潮中,精准把握消费者网络购物意向已成为电商企业提升竞争力的核心命题**(** 点击文末"阅读原文"获取完整智能体、代码、数据、文档 )。
本文改编自团队为某电商平台完成的用户行为分析咨询项目,旨在通过真实业务场景下的数据洞察,揭示消费决策背后的逻辑。作为数据科学从业者,我们深知传统经验驱动的运营模式已难以应对海量动态数据,因此需借助量化分析工具构建更具普适性的预测框架。
项目通过多维度数据清洗与特征工程,构建了逻辑回归(LR)与决策树两类经典分类模型,并创新性地结合特征重要性分析优化模型结构。全文从业务问题拆解出发,依次阐述数据获取、预处理、探索性分析及模型构建全流程,重点呈现如何通过页面价值、停留时长等核心指标预测购买行为,同时针对类别不平衡问题提出权重调整策略。
值得关注的是,文中专题项目文件已分享在交流社群,阅读原文进群和 500 + 行业人士共同交流和成长,探讨如何将数据科学方法转化为电商转化率提升的实战方案。

关键词
逻辑回归;决策树;二分类问题;网络购物
一、目的
1.1 问题分析
随着电子商务的蓬勃发展,深入了解消费者网络购物行为及购买意图,对于商家优化销售策略至关重要。本研究的核心问题是预测消费者是否会在网络购物中完成购买行为。这一问题的解决对电子商务平台的推荐系统优化、营销策略制定以及用户体验提升均具有重要意义。通过对消费者网络行为数据的分析,能够揭示影响购买意向的关键因素,进而为商家提高转化率提供决策依据。
1.2 相关工作
国内研究表明,感知有用性、感知易用性、价格敏感度、信任度和便利性等是影响消费者网络购物意向的主要因素。同时,消费者的价格敏感度、促销活动参与度以及个人特征(如年龄、收入等)也对购买意向产生显著影响。国外研究指出,购物平台的用户评价与口碑、平台设计、用户体验、个性化推荐及互动功能等,均能有效提升消费者的购买意向。此外,在特定群体中,尤其是环保意识较强的消费者,可持续购买意向逐渐上升,环境因素和可持续性决策对其在线购物意向具有重要影响。
1.3 实现目标
本研究旨在通过数据分析与建模,实现对消费者网络购物意向的预测。具体目标包括:探究影响消费者购买决策的关键因素;构建逻辑回归和决策树分类模型以预测购买意向;评估模型的准确性与可靠性。
二、数据获取
2.1 获取方式
该数据集为二分类问题数据集(查看文末了解数据免费获取方式 ),包含12330个样本和18个属性,其中17个为特征变量,1个为目标变量(是否购买)。具体属性及其含义见表1。

| 属性 | 含义 |
|---|---|
| Administrative | 管理页面数 |
| Administrative_Duration | 管理页面停留时长 |
| Informational | 信息页面数 |
| Informational_Duration | 信息页面停留时长 |
| ProductRelated | 产品相关页面数 |
| ProductRelated_Duration | 产品相关页面停留时长 |
| BounceRates | 跳出率 |
| ExitRates | 退出率 |
| PageValues | 页面价值 |
| SpecialDay | 距离特殊日期(节日)的时间 |
| Month | 月份 |
| OperatingSystems | 用户购物时使用的操作系统 |
| Browser | 用户购物时使用的浏览器 |
| Region | 用户购物时的地区 |
| TrafficType | 用户购物时使用的流量类型 |
| VisitorType | 访客类型(新用户及二次购物用户) |
| Weekend | 是否在周末访问 |
| Revenue | 是否购买 |
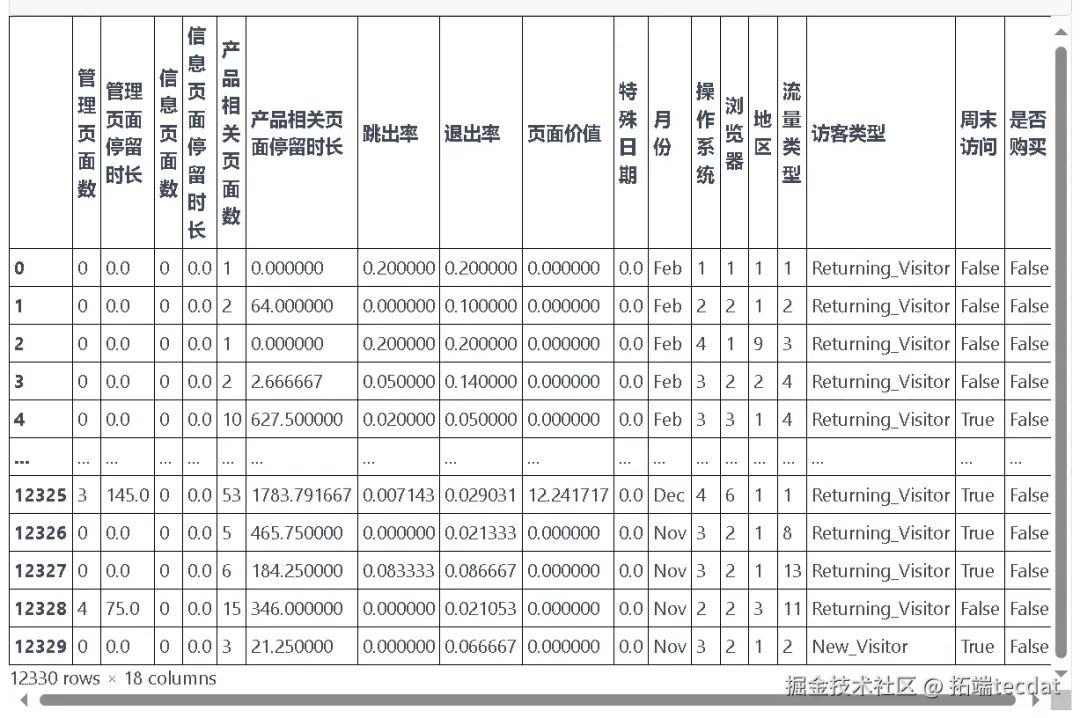
2.2 预处理
2.2.1 缺失值处理
对数据集各属性的空值数量进行统计,发现所有属性均无缺失值,因此无需进行缺失值处理。
2.2.2 分类变量转换
为便于后续数据分析与模型构建,将"月份"和"访客类型"两列分类变量转换为数值型变量,对应关系分别见表2和表3。
| 访客类型 | 对应的数值型变量 |
|---|---|
| Returning_Visitor | 0 |
| New_Visitor | 1 |
| 月份 | 对应的数值型变量 |
|---|---|
| Feb | 2 |
| Mar | 3 |
| Apr | 4 |
| May | 5 |
| June | 6 |
| Jul | 7 |
| Aug | 8 |
| Sep | 9 |
| Oct | 10 |
| Nov | 11 |
| Dec | 12 |
2.2.3 异常值处理
通过查看数据集统计信息发现,"管理页面停留时长""信息页面停留时长""产品相关页面停留时长"三列数据的最大值远高于平均值,且标准差较大,可能存在异常值。采用IQR方法对异常值进行处理,先过滤零值,再使用非零数值计算第25百分位数和第75百分位数,以1.5倍IQR作为异常值阈值。处理后,三列数据的标准差降低,最大值与平均值的差距缩小,数据分布更加均匀,波动减少。
三、数据探索与分析
3.1 数据探索
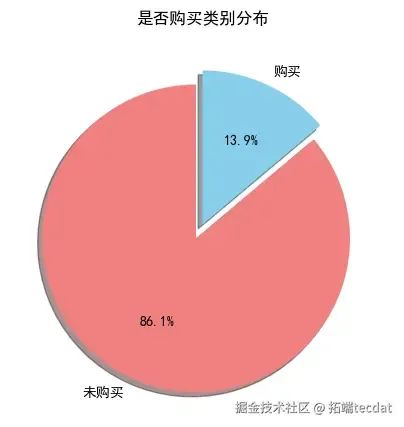
3.1.1 目标变量类别分布
目标变量"是否购买"的类别分布显示,购买人数占比13.9%,未购买人数占比86.1%,类别分布不均衡。为避免对模型拟合产生影响,在后续模型构建中通过Class Weights参数调整模型权重。
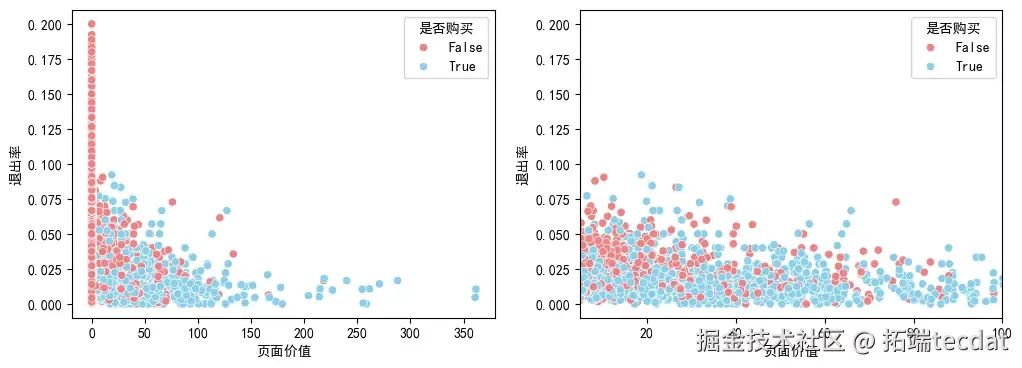
3.1.2 目标变量在页面价值和退出率上的分布差异
散点图分析表明,未购买用户集中在页面价值0-10且退出率大于0.02的页面;购买用户在页面价值10-40的页面分布较为密集,且退出率大部分集中在0.04以下。
3.1.3 目标变量在页面价值和产品相关页面停留时长上的分布差异
核密度估计图显示,购买用户浏览页面的页面价值均值约为30,未购买用户的页面价值均值接近0;购买用户的产品相关页面停留时长主要集中在0-1500个时间单位,未购买用户则集中在0-500个时间单位,表明购买用户的产品相关页面停留时长更长。
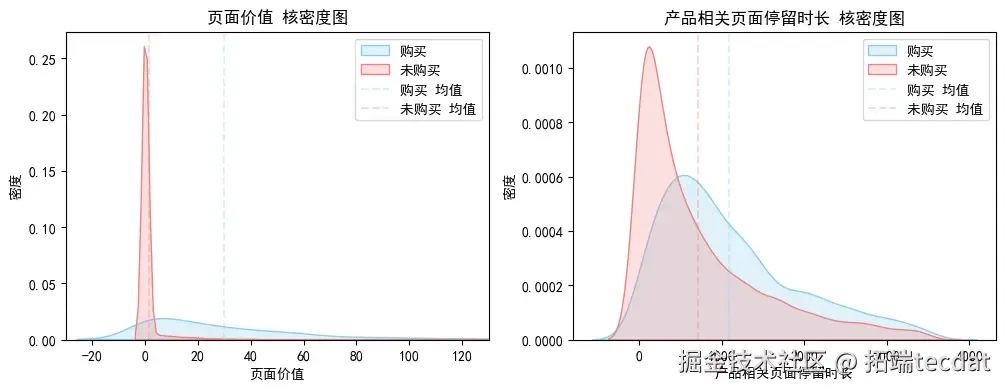
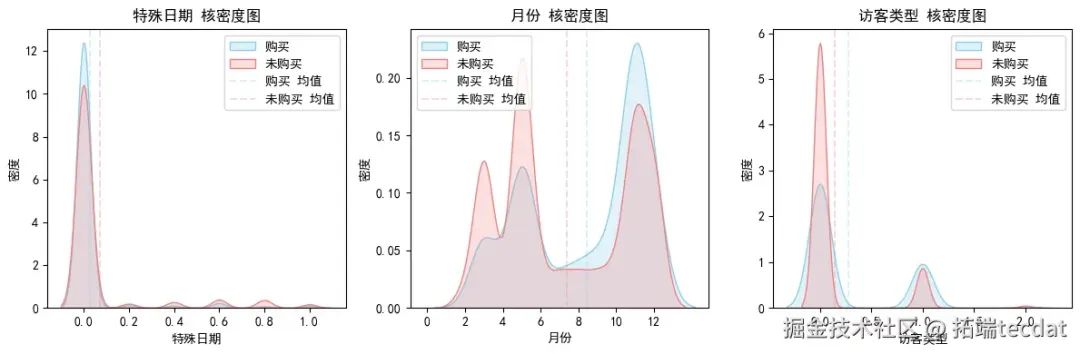
3.1.4 目标变量在特殊日期、月份和访客类型上的分布差异
核密度估计图显示,临近特殊日期(节日)对用户购买率有一定提升,但影响不大;4-6月和10-12月是购买高峰期,其中10-12月也是浏览平台的高峰期;老用户(访客类型为0)的购买率高于新用户。
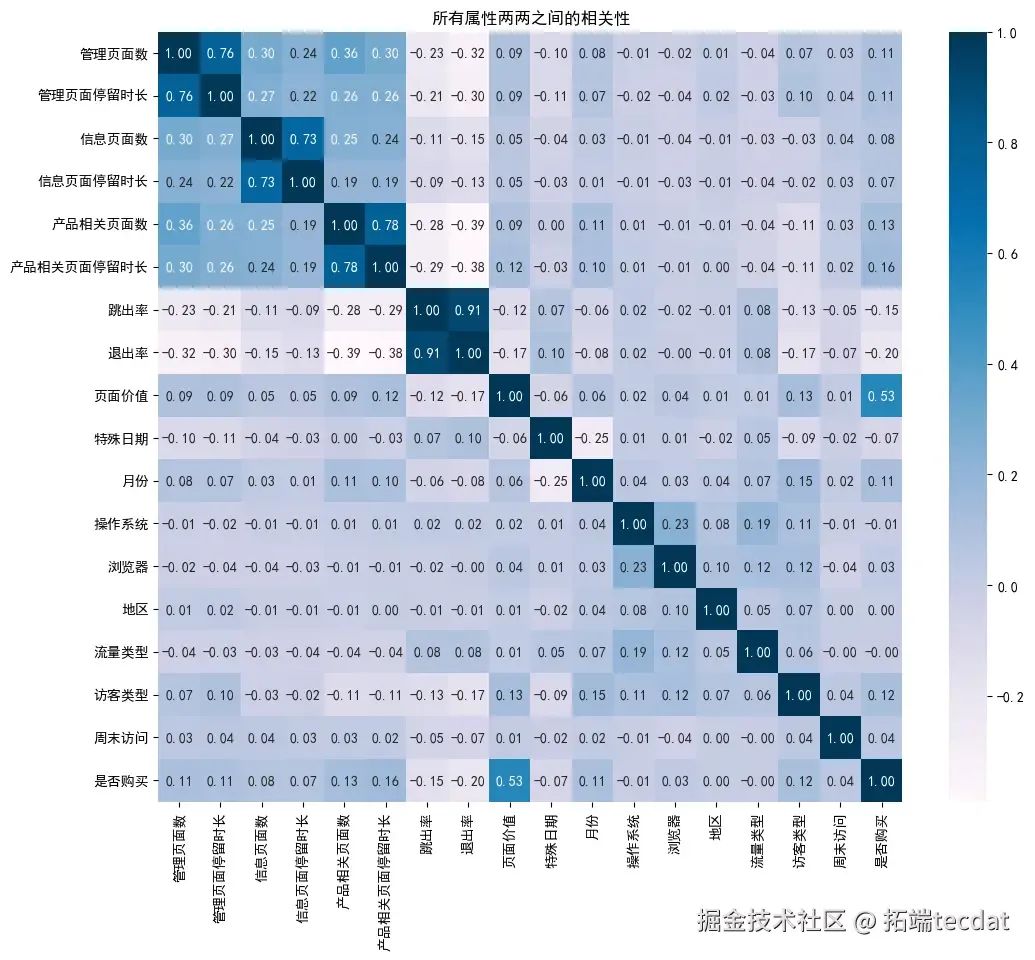
3.1.5 相关性热力图识别相关特征
相关性热力图显示,"管理页面数""管理页面停留时长""信息页面数""信息页面停留时长""产品相关页面数""产品相关页面停留时长""跳出率""退出率"八列数据之间相关性较高。结合相关性矩阵和VIF值,最终选择保留"管理页面停留时长""信息页面停留时长""产品相关页面停留时长""跳出率"等特征。
3.2 数据分析
分析结果表明:页面价值与退出率呈负相关,高页面价值和长停留时间有助于提高购买可能性;页面价值与购买行为呈正相关,相关系数为0.53;4-6月和10-12月是购买高峰期,商家可在此期间加大促销力度;老用户购买意愿更强,需注重提升老用户忠诚度;操作系统、浏览器、流量类型、地区和周末访问等因素对购买行为影响不显著。
四、模型的建立与评估
4.1 模型建立
4.1.1 特征选择
通过相关性分析和VIF值计算,删除"管理页面数""信息页面数""产品相关页面数""退出率"等相关性较高的特征,保留"管理页面停留时长""信息页面停留时长""产品相关页面停留时长""跳出率""页面价值""特殊日期""月份""访客类型"等特征。

4.1.2 逻辑回归模型
逻辑回归模型是一种用于二分类问题的线性模型,通过Sigmoid函数将线性回归结果转换为概率值。其核心公式为:
P(y=1 \| X) = \\frac{1}{1+e\^{-(\\beta_0 + \\beta_1X_1 + \\beta_2X_2 + \\cdots + \\beta_nX_n)}}
其中,(P(y=1 | X))表示预测为购买的概率,(X_1, X_2, \cdots, X_n)为输入特征,(\beta_0, \beta_1, \cdots, \beta_n)为模型参数。该模型的系数可直观反映各特征对目标变量的影响程度,因此适用于本研究的二分类问题。
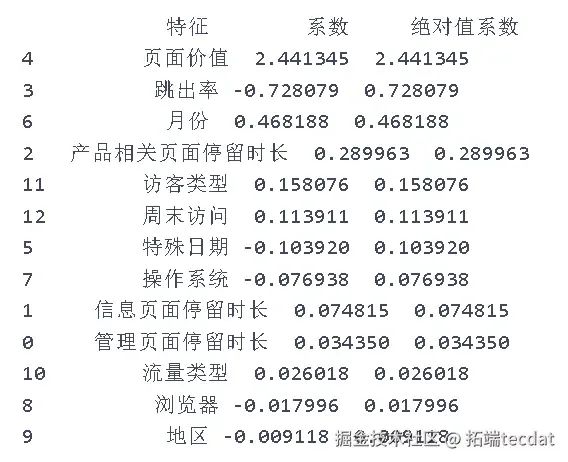
4.1.3 决策树模型
决策树模型通过递归分割数据集构建树状结构,以实现分类或回归目标。其核心是选择最佳特征分裂点,最大化数据集纯度。考虑到数据中可能存在的非线性关系,引入决策树模型作为逻辑回归模型的补充。
4.2 模型评估
4.2.1 逻辑回归模型
将特征选择后的数据集代入逻辑回归模型,模型准确度为89%。对未购买的预测效果较好(精确率96%、召回率91%、F1分数93%),但对购买的预测效果较差(精确率59%、F1分数66%),存在较多误判和漏判情况。
go
ini
体验AI代码助手
代码解读
复制代码
# 逻辑回归模型训练与评估
x_train, x_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
log_model = LogisticRegression(class_weight='balanced')
log_model.fit(x_train_scaled, y_train)
y_pred_log = log_model.predict(x_test_scaled)
print("逻辑回归模型准确率:", accuracy_score(y_test, y_pred_log))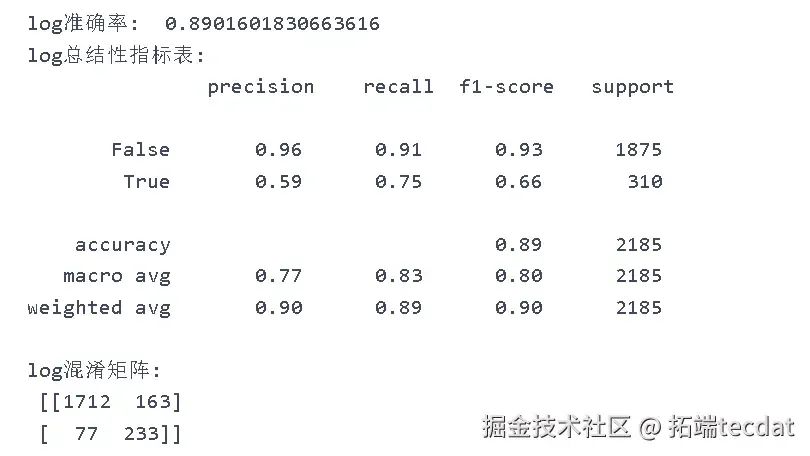
4.2.2 决策树模型
决策树模型的准确度为88%。对未购买的预测效果良好(精确率92%、召回率94%、F1分数93%),但对购买的预测效果较差(精确率59%、召回率53%、F1分数56%),漏判和误判情况较为严重。
go
ini
体验AI代码助手
代码解读
复制代码
# 决策树模型训练与评估
dt_model = DecisionTreeClassifier(random_state=42, class_weight='balanced')
dt_model.fit(x_train, y_train)
y_pred_dt = dt_model.predict(x_test)
print("决策树模型准确率:", accuracy_score(y_test, y_pred_dt))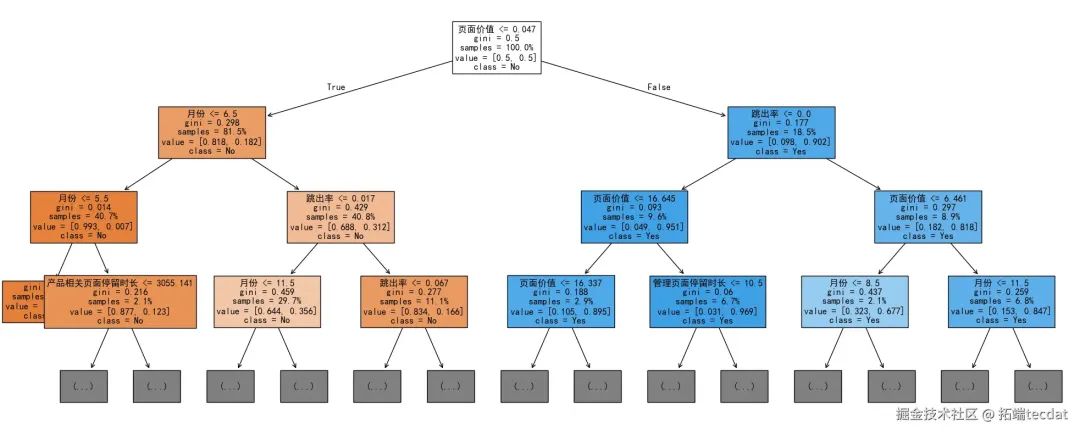
4.2.3 调优后的逻辑回归模型
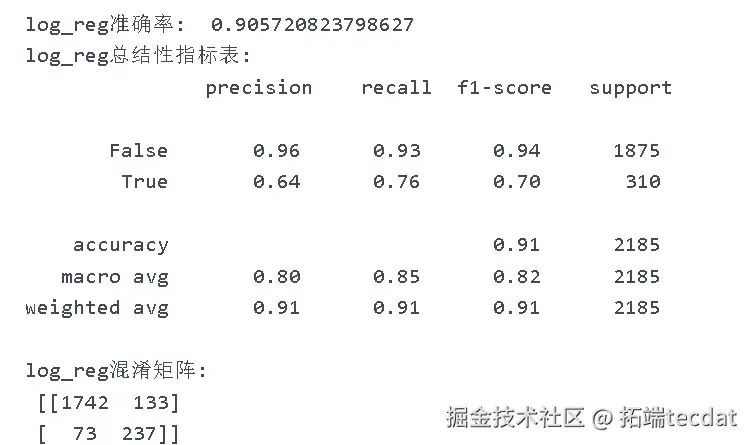
通过决策树算法筛选出特征重要性大于0.05的4个特征(页面价值、产品相关页面停留时长、管理页面停留时长、跳出率),再次代入逻辑回归模型。优化后的模型准确度提升至91%,对未购买的预测效果(精确率96%、召回率93%、F1分数94%)和购买的预测效果(精确率64%、F1分数70%)均有所改善。
go
ini
体验AI代码助手
代码解读
复制代码
# 特征重要性分析与模型调优
dt = DecisionTreeClassifier(random_state=42)
dt.fit(x_train, y_train)
importance = dt.feature_importances_
top_features = importance_df.head(4)['Feature'].values
x_train_selected = x_train[top_features]
x_test_selected = x_test[top_features]
log_reg_model = LogisticRegression(class_weight='balanced')
log_reg_model.fit(x_train_selected, y_train)
y_pred_reg = log_reg_model.predict(x_test_selected)
print("调优后逻辑回归模型准确率:", accuracy_score(y_test, y_pred_reg))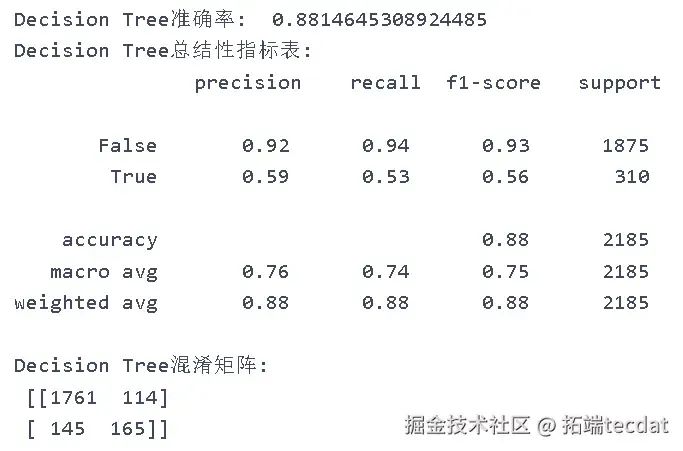
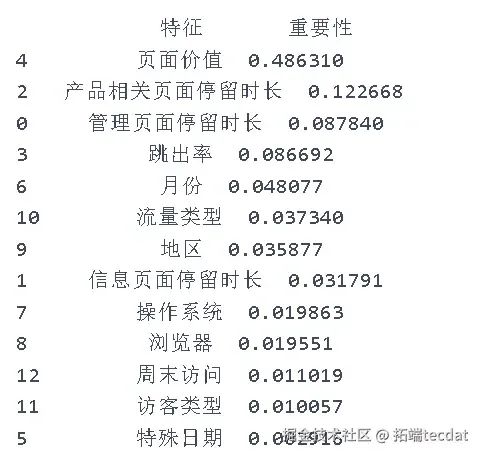
4.2.4 模型评估总结
综合比较三个模型,调优后的逻辑回归模型(log_reg)准确度最高(91%),对购买的预测精确率(64%)和F1分数(70%)也相对较高,整体预测效果最佳,更符合研究目标。
五、总结与展望
5.1 项目实现功能
本研究实现了基于用户页面浏览行为(管理页面、信息页面、产品相关页面)、页面价值及浏览时间的消费者网络购物意向预测。商家可依据分析结果,针对产品质量、营销策略和用户画像等方面进行调整,以提高网络购物转化率。
5.2 优缺点
优点:通过建立逻辑回归和决策树模型,对消费者网络购物意向进行了系统分析,筛选出关键影响因素,并优化得到了性能较优的模型。
缺点:数据集目标变量类别分布不均衡,尽管调整了模型权重,结果仍偏向于未购买类别的预测。
5.3 改进想法
未来可通过增加少数类(购买)样本量、生成合成数据或减少多数类样本量等方式平衡类别分布;尝试使用对不平衡数据处理能力更强的算法,如随机森林、梯度提升树等,进一步提升模型对少数类的预测性能。
参考文献
1 韩雁雁. 国内消费者网络购物参与意愿实证研究的Meta分析D. 青岛大学, 2016.
2 祝长华, 林姗姗, 林李坚, 等. 消费者网络购物行为意向影响因素研究J. 韶关学院学报, 2016, 37(02): 7-12.
3 耿波. 基于TAM的消费者网络购物意向的影响因素分析J. 统计与决策, 2012, (23): 105-107.
4 Eri Y, Islam A M, Daud K A K. Factors that Influence Customers' Buying Intention on Shopping OnlineJ. International Journal of Marketing Studies, 2011, 3(1): 128.
5 Zhao Z, Omar A N, Zaki O H. Appraisal factors of sustainable purchase intentions in online shopping platform context: PLS-SEM with theory extensionsJ. Journal of Retailing and Consumer Services, 2025, 82: 104118.
关于分析师
在此对 Li Ting 对本文所作的贡献表示诚挚感谢,她在四川大学完成了数据科学与大数据技术专业的学习,专注机器学习领域。擅长 Python、深度学习、数据可视化。Li Ting 在数据分析与建模领域具备扎实的专业基础,能够熟练运用机器学习算法解决实际业务问题,尤其在消费者行为分析、预测模型构建等方面积累了丰富经验。其专业技能与项目需求高度契合,为本文的数据处理、模型优化及业务洞察提供了重要支持。
数据获取
在公众号后台回复"电商数据",可免费获取完整数据。

本文中分析的完整智能体、数据、代码、文档** 分享到会员群**,扫描下面二维码即可加群!

资料获取
在公众号后台回复"领资料",可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末**"阅读原文"**
获取完整智能体、
代码、数据和文档。
点击标题查阅往期内容
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线




