二叉搜索树和平衡二叉树
二叉搜索树,左子节点小于父节点发值,右子节点大于父节点的值。如果需要查找8,需要三次,而顺序查找需要6次。
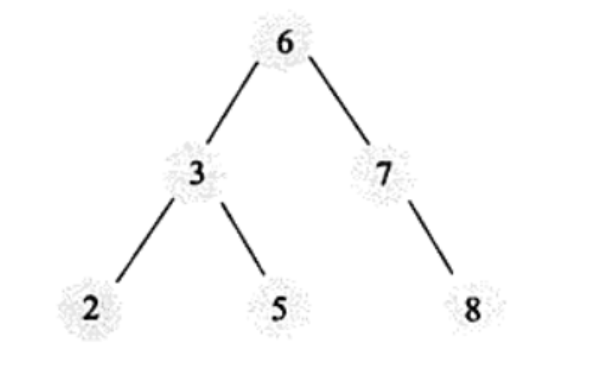
同样是二叉搜索树,下图的情况查找效率会很低,从而引出平衡二叉树(AVL树),平衡二叉树要求任何节点的子树高度最大差为1。平衡性确保查找的速度可以很快,避免了二叉搜索树的极端情况。
B树和B+树
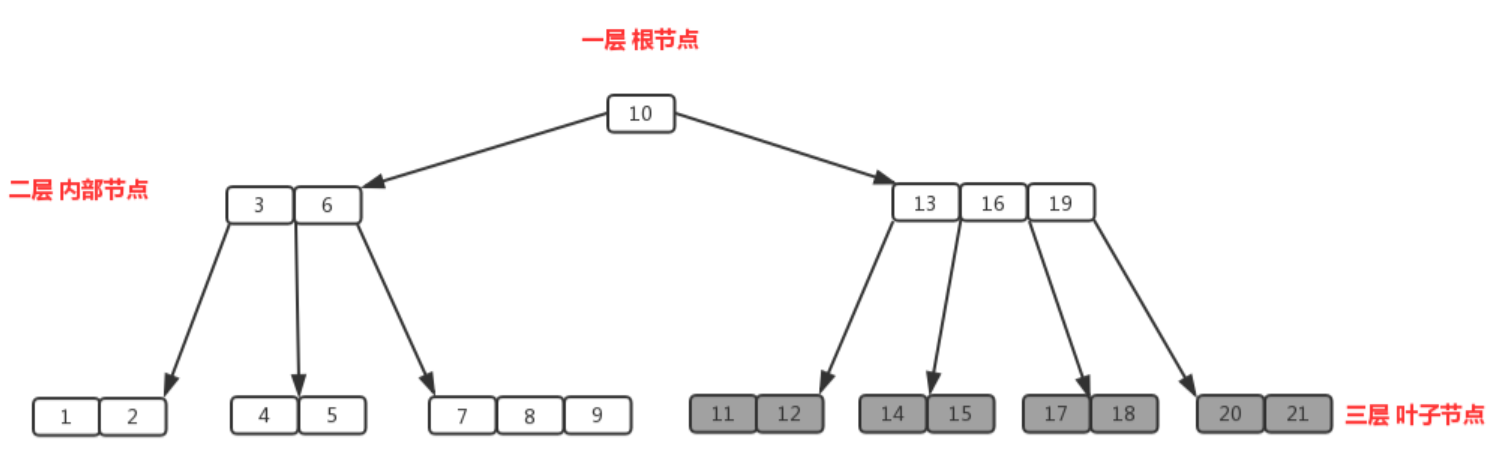
平衡二叉树随着节点的增加,树的高度会越来越高,会增加磁盘的I/O次数,影响查询效率,从而引出了B树,B树不限制一个节点只能由2个子节点,从而降低树的高度。
B树可以将节点的大小优化为磁盘块的大小,每次读取可以有效加载多个节点,B树常用于数据库库等需要高效访问磁盘的场景。
B+树是对B树的升级,B+树只有叶子节点存数据,非叶子节点只存索引。叶子节点包含所有索引,叶子节点构成一个有序链表,范围查找更快。由于非叶子节点只存索引,B+树比B树的非叶子节点可以存更多索引,高度更低,磁盘I/O次数更少。
B+树结构图
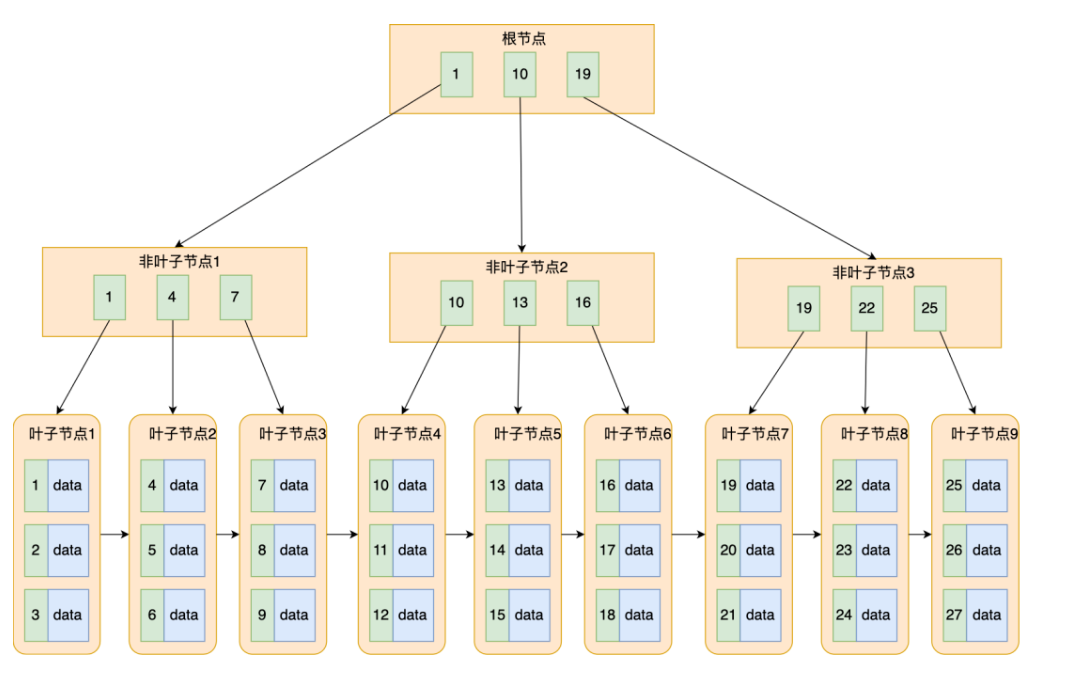
B树与B+树差异:
- 叶子节点(最底部的节点)才会实际存放数据(索引+记录),非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
- 非叶子节点的索引也会同时存在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少索引;
性能区别
1.单点查询
B 树查询
- 最快查询时间 :B 树进行单个索引查询时,若要查找的索引恰好在非叶子节点,无需再向下遍历,能在 O(1) 时间代价内查到,这是它最快的情况。但平均来看,由于节点既存索引又存记录,查询时可能要访问到叶子节点才能找到索引,不确定性较大,所以查询波动大。
- 平均时间:理论上平均时间比 B + 树稍快些,不过实际中因为其查询的不确定性,在大规模数据和频繁查询场景下,优势可能不明显。
B + 树查询
- 结构优势:B + 树非叶子节点仅存放索引,不存实际记录数据。相同数据量下,相比 B 树,B + 树的非叶子节点能存放更多索引,树的层级会更少,变得更 "矮胖" 。
- I/O 次数 :数据库中查询涉及磁盘 I/O 操作,B + 树层级少,查询底层节点(叶子节点获取数据)时所需的磁盘 I/O 次数就会更少,在实际应用尤其是磁盘 I/O 开销较大的场景下,整体查询效率更稳定,性能表现往往更好。
2、插入和删除效率
- **B + 树:**有冗余节点 。删除节点常可直接从叶子节点删,不怎么动非叶子节点;删除根节点也不易致树复杂变形。插入时节点饱和会分裂,但最多影响一条路径,还能自动平衡,不搞复杂旋转,插入删除都高效。
- **B 树:**无冗余节点 。删除节点(尤其根节点)会让树复杂变形,要各种调整;插入推测也因需维持结构平衡,比 B + 树麻烦,插入删除效率低。
3.范围查询
- **B 树:**范围查询时,由于没有叶子节点链表结构,只能从根节点开始逐层遍历整棵树,递归进入子节点判断数据是否在范围内。比如查询成绩在 80 - 90 分之间的学生信息,需多次从根节点出发,在不同层级节点间查找判断,多次磁盘 I/O 操作,效率较低。适用于单个索引查询场景。
- **B + 树:**叶子节点由链表串联。进行范围查询时,先找到范围起始值对应的叶子节点,像查询 10 - 20 号订单,定位到 10 号订单所在叶子节点后,可顺着链表顺序找到 20 号订单节点,无需反复回溯根节点,减少磁盘 I/O,范围查询效率高,常用于数据库等大量范围检索场景。
在MySQL中B+树
MySQL中的存储方式是按存储引擎不同而不同的,最常用的就是InnoDB存储引擎,它采用的B+树作为索引的数据结构。
InnoDB中的B+树结构
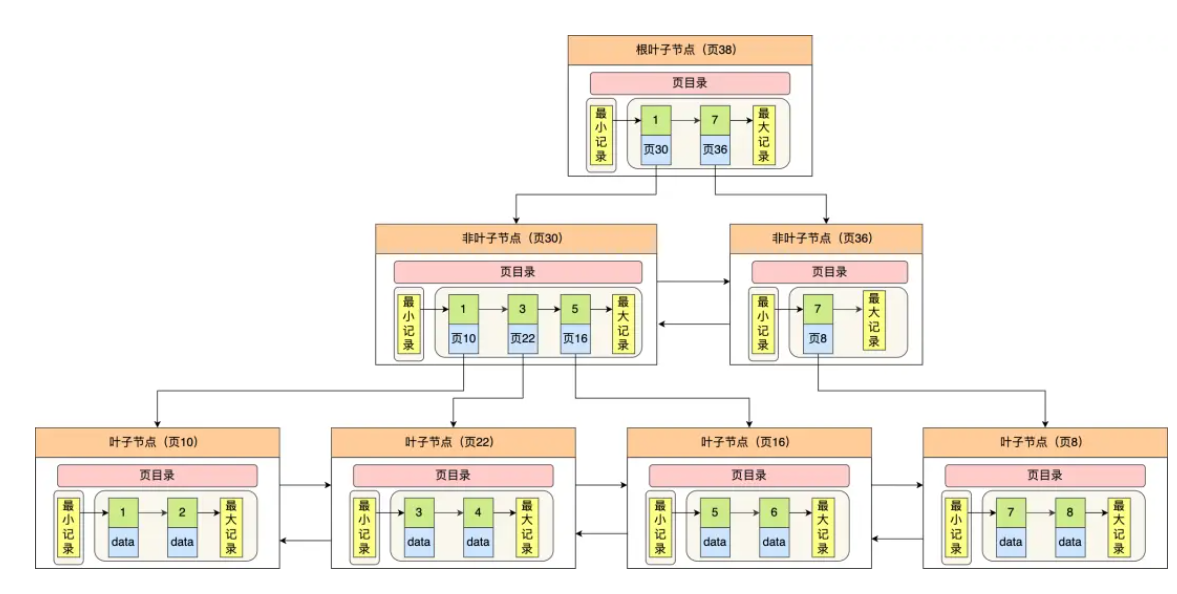
1.叶子节点连接方式
- 特点:叶子节点通过双向链表连接 。
- 优势:具备双向遍历能力,在范围查询时,既可以从起始点向右遍历获取大于起始值的数据,也能向左遍历获取小于起始值的数据 。例如在查询某时间段前后的订单记录时,双向链表能灵活满足不同方向的范围检索需求,提高查询效率。
2.节点内容与数据页
- 特点:B + 树节点即数据页,存放用户记录及相关信息,默认大小为 16KB 。
- 作用:数据页这种存储结构能将相关数据集中存放,减少磁盘 I/O 次数。比如在查询用户表中某部分用户记录时,若这些记录在同一数据页,一次 I/O 操作就能读取到,提升数据读取效率 。同时,固定的 16KB 大小便于 InnoDB 进行页管理和内存分配等操作 。
此外B+树索引分为聚簇索引(主键索引)和非聚簇索引(二级索引)。