前提条件:
1、吴恩达MCP课程(5):research_server_prompt_resource.py
2、server_config_prompt_resource.json文件
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"--y",
"@modelcontextprotocol/server-filesystem",
"."
]
},
"research": {
"command": "uv",
"args": ["run", "research_server_prompt_resource.py"]
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
}代码
原课程用的anthropic的,下面改成openai,并用千问模型做测试
python
from dotenv import load_dotenv
import openai
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from contextlib import AsyncExitStack
import json
import asyncio
import os
load_dotenv()
class MCP_ChatBot:
def __init__(self):
self.exit_stack = AsyncExitStack()
self.client = openai.OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_BASE")
)
# Tools list required for OpenAI API
self.available_tools = []
# Prompts list for quick display
self.available_prompts = []
# Sessions dict maps tool/prompt names or resource URIs to MCP client sessions
self.sessions = {}
async def connect_to_server(self, server_name, server_config):
try:
server_params = StdioServerParameters(**server_config)
stdio_transport = await self.exit_stack.enter_async_context(
stdio_client(server_params)
)
read, write = stdio_transport
session = await self.exit_stack.enter_async_context(
ClientSession(read, write)
)
await session.initialize()
try:
# List available tools
response = await session.list_tools()
for tool in response.tools:
self.sessions[tool.name] = session
self.available_tools.append({
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
})
# List available prompts
prompts_response = await session.list_prompts()
if prompts_response and prompts_response.prompts:
for prompt in prompts_response.prompts:
self.sessions[prompt.name] = session
self.available_prompts.append({
"name": prompt.name,
"description": prompt.description,
"arguments": prompt.arguments
})
# List available resources
resources_response = await session.list_resources()
if resources_response and resources_response.resources:
for resource in resources_response.resources:
resource_uri = str(resource.uri)
self.sessions[resource_uri] = session
except Exception as e:
print(f"Error {e}")
except Exception as e:
print(f"Error connecting to {server_name}: {e}")
async def connect_to_servers(self):
try:
with open("server_config_prompt_resource.json", "r") as file:
data = json.load(file)
servers = data.get("mcpServers", {})
for server_name, server_config in servers.items():
await self.connect_to_server(server_name, server_config)
except Exception as e:
print(f"Error loading server config: {e}")
raise
async def process_query(self, query):
messages = [{"role":"user", "content":query}]
while True:
response = self.client.chat.completions.create(
model="qwen-turbo",
tools=self.available_tools,
messages=messages
)
message = response.choices[0].message
# 检查是否有普通文本内容
if message.content:
print(message.content)
messages.append({"role": "assistant", "content": message.content})
break
# 检查是否有工具调用
elif message.tool_calls:
# 添加助手消息到历史
messages.append({
"role": "assistant",
"content": None,
"tool_calls": message.tool_calls
})
# 处理每个工具调用
for tool_call in message.tool_calls:
tool_id = tool_call.id
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
print(f"Calling tool {tool_name} with args {tool_args}")
# 获取session并调用工具
session = self.sessions.get(tool_name)
if not session:
print(f"Tool '{tool_name}' not found.")
break
result = await session.call_tool(tool_name, arguments=tool_args)
# 添加工具结果到消息历史
messages.append({
"role": "tool",
"tool_call_id": tool_id,
"content": result.content
})
else:
break
async def get_resource(self, resource_uri):
session = self.sessions.get(resource_uri)
# Fallback for papers URIs - try any papers resource session
if not session and resource_uri.startswith("papers://"):
for uri, sess in self.sessions.items():
if uri.startswith("papers://"):
session = sess
break
if not session:
print(f"Resource '{resource_uri}' not found.")
return
try:
result = await session.read_resource(uri=resource_uri)
if result and result.contents:
print(f"\nResource: {resource_uri}")
print("Content:")
print(result.contents[0].text)
else:
print("No content available.")
except Exception as e:
print(f"Error: {e}")
async def list_prompts(self):
"""List all available prompts."""
if not self.available_prompts:
print("No prompts available.")
return
print("\nAvailable prompts:")
for prompt in self.available_prompts:
print(f"- {prompt['name']}: {prompt['description']}")
if prompt['arguments']:
print(f" Arguments:")
for arg in prompt['arguments']:
arg_name = arg.name if hasattr(arg, 'name') else arg.get('name', '')
print(f" - {arg_name}")
async def execute_prompt(self, prompt_name, args):
"""Execute a prompt with the given arguments."""
session = self.sessions.get(prompt_name)
if not session:
print(f"Prompt '{prompt_name}' not found.")
return
try:
result = await session.get_prompt(prompt_name, arguments=args)
if result and result.messages:
prompt_content = result.messages[0].content
# Extract text from content (handles different formats)
if isinstance(prompt_content, str):
text = prompt_content
elif hasattr(prompt_content, 'text'):
text = prompt_content.text
else:
# Handle list of content items
text = " ".join(item.text if hasattr(item, 'text') else str(item)
for item in prompt_content)
print(f"\nExecuting prompt '{prompt_name}'...")
await self.process_query(text)
except Exception as e:
print(f"Error: {e}")
async def chat_loop(self):
print("\nMCP Chatbot Started!")
print("Type your queries or 'quit' to exit.")
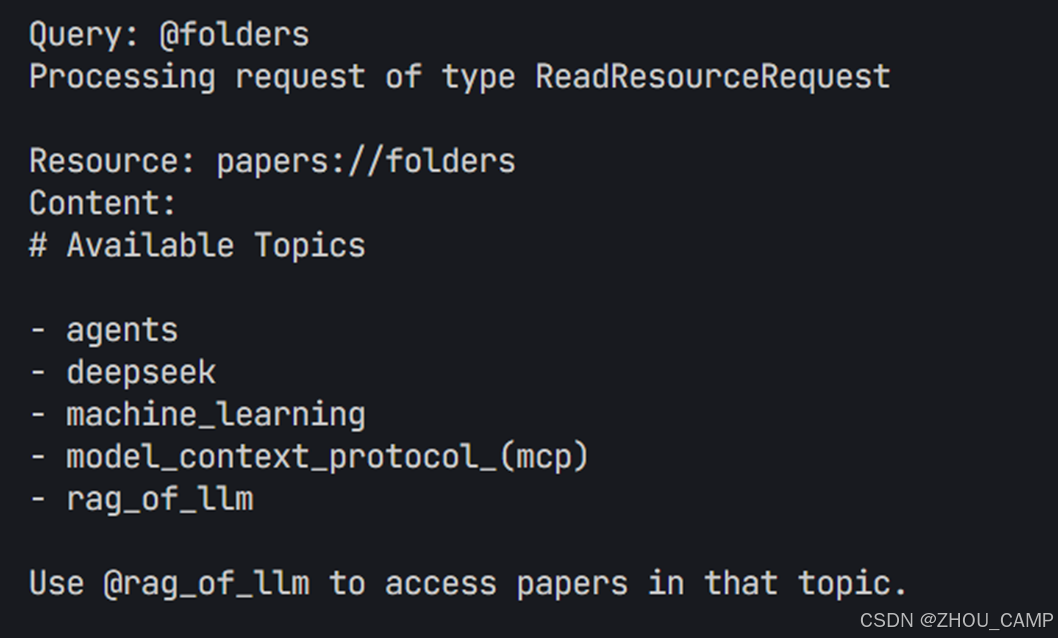
print("Use @folders to see available topics")
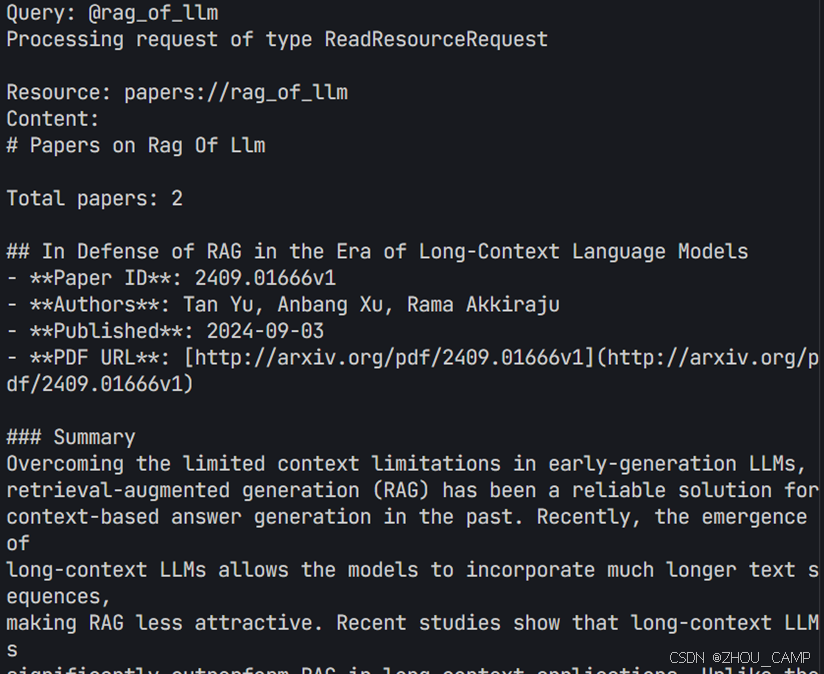
print("Use @<topic> to search papers in that topic")
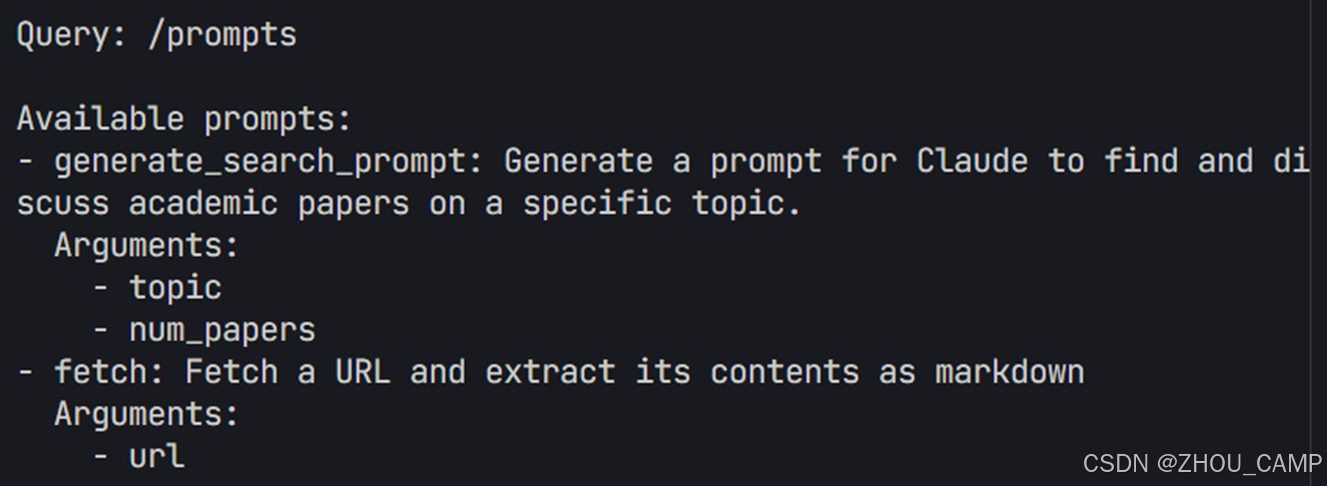
print("Use /prompts to list available prompts")
print("Use /prompt <name> <arg1=value1> to execute a prompt")
while True:
try:
query = input("\nQuery: ").strip()
if not query:
continue
if query.lower() == 'quit':
break
# Check for @resource syntax first
if query.startswith('@'):
# Remove @ sign
topic = query[1:]
if topic == "folders":
resource_uri = "papers://folders"
else:
resource_uri = f"papers://{topic}"
await self.get_resource(resource_uri)
continue
# Check for /command syntax
if query.startswith('/'):
parts = query.split()
command = parts[0].lower()
if command == '/prompts':
await self.list_prompts()
elif command == '/prompt':
if len(parts) < 2:
print("Usage: /prompt <name> <arg1=value1> <arg2=value2>")
continue
prompt_name = parts[1]
args = {}
# Parse arguments
for arg in parts[2:]:
if '=' in arg:
key, value = arg.split('=', 1)
args[key] = value
await self.execute_prompt(prompt_name, args)
else:
print(f"Unknown command: {command}")
continue
await self.process_query(query)
except Exception as e:
print(f"\nError: {str(e)}")
async def cleanup(self):
await self.exit_stack.aclose()
async def main():
chatbot = MCP_ChatBot()
try:
await chatbot.connect_to_servers()
await chatbot.chat_loop()
finally:
await chatbot.cleanup()
if __name__ == "__main__":
asyncio.run(main())代码解释
这段代码实现了一个基于MCP(Model Context Protocol)的聊天机器人,能够连接到多个MCP服务器,使用它们提供的工具、提示和资源。下面是对代码的详细解释:
类结构与初始化
python
class MCP_ChatBot:
def __init__(self):
self.exit_stack = AsyncExitStack()
self.client = openai.OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_BASE")
)
# Tools list required for OpenAI API
self.available_tools = []
# Prompts list for quick display
self.available_prompts = []
# Sessions dict maps tool/prompt names or resource URIs to MCP client sessions
self.sessions = {}AsyncExitStack:用于管理多个异步上下文管理器,确保资源正确释放openai.OpenAI:创建OpenAI客户端,使用环境变量中的API密钥和基础URLavailable_tools:存储可用工具列表,用于OpenAI API的工具调用功能available_prompts:存储可用提示列表,用于快速显示sessions:字典,将工具名称、提示名称或资源URI映射到对应的MCP客户端会话
服务器连接
python
async def connect_to_server(self, server_name, server_config):
# 创建服务器参数、建立连接并初始化会话
# 获取可用工具、提示和资源这个方法负责:
- 使用提供的配置创建
StdioServerParameters - 通过
stdio_client建立与服务器的连接 - 创建并初始化
ClientSession - 获取服务器提供的工具、提示和资源
- 将它们添加到相应的列表和字典中
python
async def connect_to_servers(self):
# 从配置文件加载服务器信息并连接到每个服务器这个方法从server_config_prompt_resource.json文件加载服务器配置,并为每个服务器调用connect_to_server方法。
查询处理
python
async def process_query(self, query):
# 处理用户查询,使用OpenAI API和可用工具这个方法是聊天机器人的核心,它:
- 创建包含用户查询的消息列表
- 调用OpenAI API,传递消息和可用工具
- 处理API的响应:
- 如果有普通文本内容,打印并添加到消息历史
- 如果有工具调用,执行每个工具调用并将结果添加到消息历史
工具调用的处理流程:
- 从响应中提取工具ID、名称和参数
- 从
sessions字典中获取对应的会话 - 调用工具并获取结果
- 将结果添加到消息历史中
资源和提示管理
python
async def get_resource(self, resource_uri):
# 获取并显示指定URI的资源内容这个方法用于获取和显示资源内容,特别是论文资源。它会:
- 从
sessions字典中获取对应的会话 - 对于以
papers://开头的URI,如果找不到对应会话,会尝试使用任何处理papers的会话 - 调用
read_resource方法获取资源内容 - 打印资源内容
python
async def list_prompts(self):
# 列出所有可用的提示这个方法列出所有可用的提示及其描述和参数。
python
async def execute_prompt(self, prompt_name, args):
# 执行指定的提示,并处理结果这个方法执行指定的提示,并将结果传递给process_query方法进行处理。它处理不同格式的提示内容,确保能够正确提取文本。
聊天循环
python
async def chat_loop(self):
# 主聊天循环,处理用户输入这个方法是聊天机器人的主循环,它:
- 打印欢迎信息和使用说明
- 循环接收用户输入
- 根据输入的不同格式执行不同操作:
- 如果输入是
quit,退出循环 - 如果输入以
@开头,调用get_resource方法获取资源 - 如果输入以
/开头,执行命令(如列出提示或执行提示) - 否则,调用
process_query方法处理普通查询
- 如果输入是
资源清理
python
async def cleanup(self):
# 清理资源这个方法调用exit_stack.aclose()来清理所有资源。
主函数
python
async def main():
chatbot = MCP_ChatBot()
try:
await chatbot.connect_to_servers()
await chatbot.chat_loop()
finally:
await chatbot.cleanup()主函数创建MCP_ChatBot实例,连接到服务器,运行聊天循环,并确保在结束时清理资源。
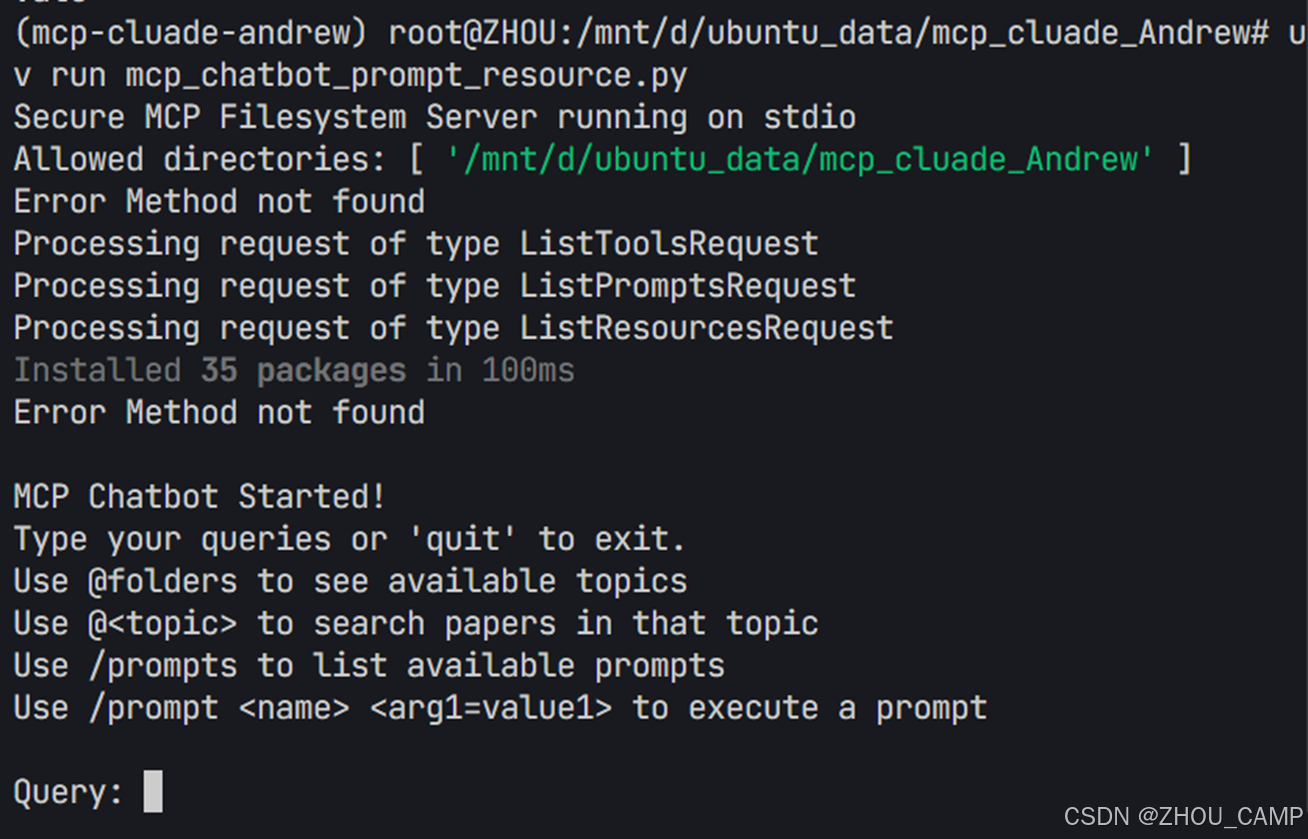
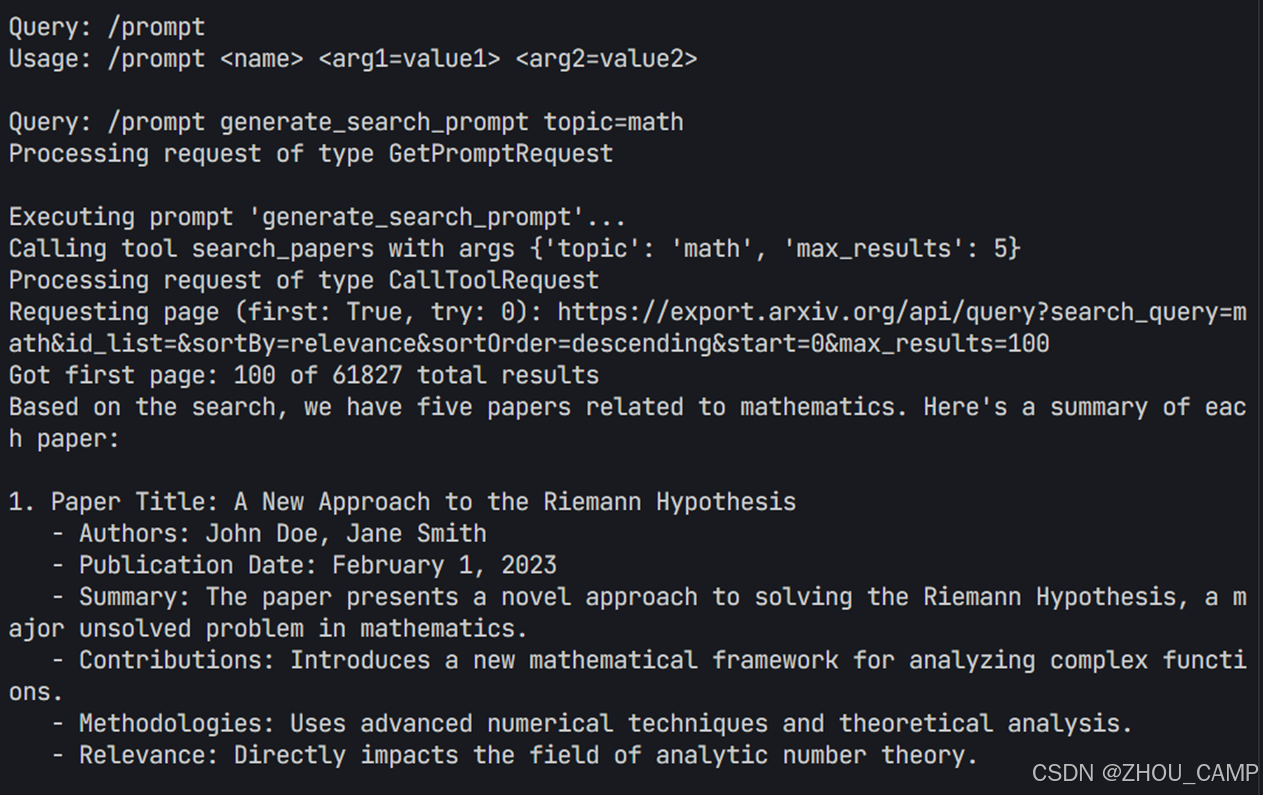
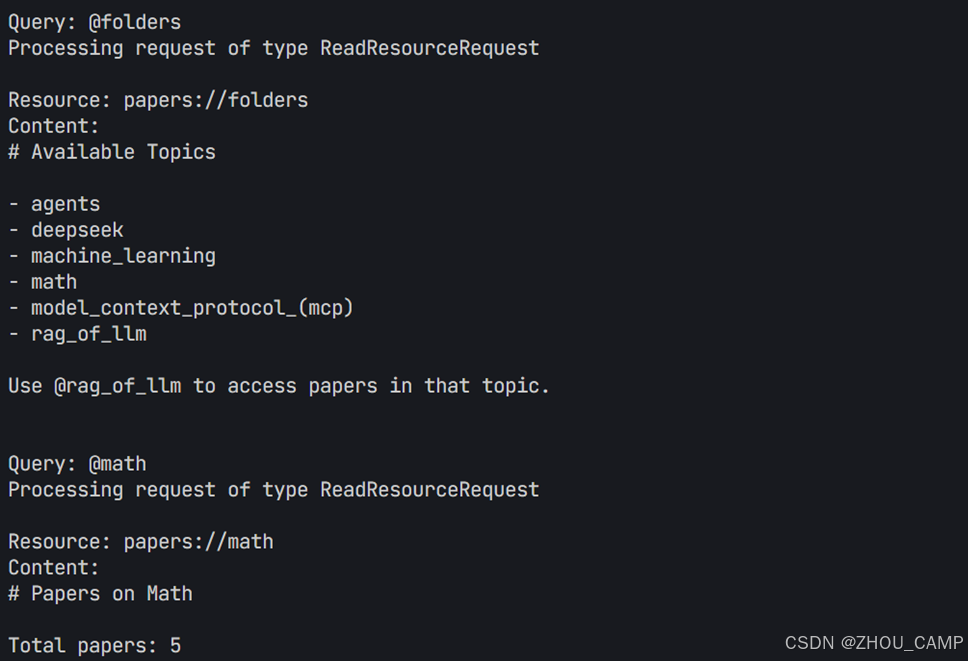
代码运行结果
uv run mcp_chatbot_prompt_resource.py