超越 Context Window:为何文件系统是 AI Agent 的终极记忆体
"AI 不会因为上下文太短而失败,它们失败是因为不知道如何管理遗忘。"
2025 年 12 月,Meta 以 20 亿美元收购 Agent 初创公司 Manus 的消息引爆了科技圈。除了惊人的估值,最让开发者好奇的是:Manus 到底解决了什么核心难题?答案可能比大多数人想象的要朴素得多------上下文工程(Context Engineering)。
如果你用过 AutoGPT 或早期的 Agent 框架,你一定经历过这种绝望:Agent 充满激情地出发,执行了 10 步之后,突然开始在一个死循环里打转,或者干脆忘记了最初是要"写一个贪吃蛇游戏",转而去研究"如何安装 Python"。
这就是 Agent 的"金鱼效应"。
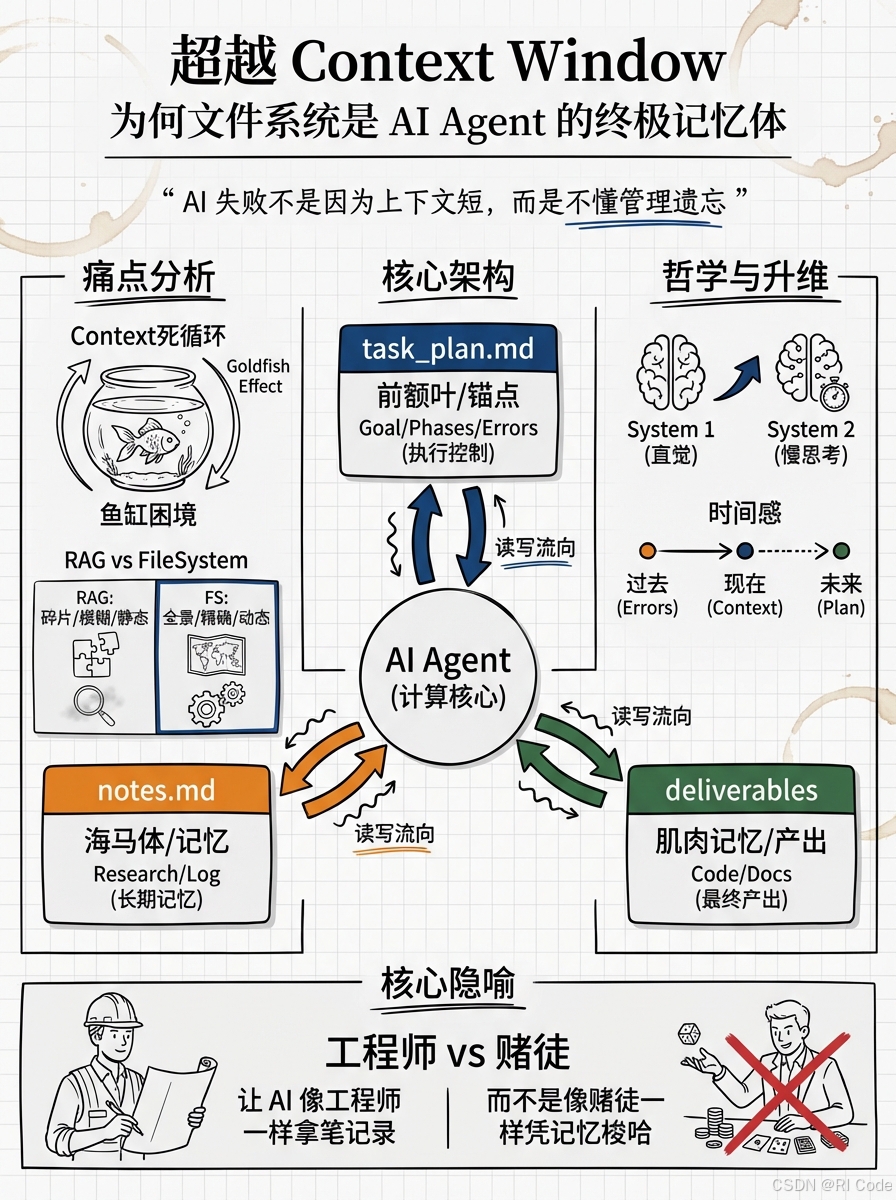
今天,我们将深入拆解 Claude Code 中的 Planning with Files 技能。这不仅是一个工具,更是一套源自 Manus 的工程哲学。它告诉我们:解决上下文限制的最好方法,不是扩大窗口,而是把记忆写进磁盘。
一、为什么 RAG 救不了 Agent?
在 LLM 时代,我们习惯于用 RAG(检索增强生成)来解决知识不足的问题。把文档切片、存入向量数据库、检索 Top-K。但在 Agent 的长程任务中,RAG 往往失效了。
为什么?因为 Agent 需要的不是"知识片段",而是"状态全景"。
当一个 Agent 正在重构 50 个文件中的 API 调用时,它需要的不是"API 的文档定义"(静态知识),而是"我已经改了哪 20 个?剩下哪 30 个?上一步报错的文件是谁?"(动态状态)。
向量检索是模糊的、碎片化的;而文件系统是精确的、结构化的。
Planning with Files 的核心理念就是:将文件系统作为 Agent 的外部显式记忆(External Explicit Memory)。
相比单纯扩展上下文窗口,文件系统有三个不可替代的优势:
- 容量无限:磁盘存储远超任何上下文窗口,只在需要时加载相关部分
- 压缩可逆:上下文中的信息经模型压缩后难以恢复,文件中的原始文本可精确读取
- 跨任务复用:同一份笔记可以在多个相关任务中持续发挥作用
二、"三驾马车"模式:给 Agent 装上大脑结构
这套技能强制 Agent 在执行复杂任务时,维护三个特定的 Markdown 文件。这听起来像是增加了繁琐的手续,实则是构建了 Agent 的思维骨架。
1. task_plan.md ------ 前额叶(执行控制)
这是整个系统的指挥中心。它不仅仅是一个 Todo List,它是 Agent 的注意力锚点。
在 LLM 中存在著名的 "Lost in the Middle" 现象:当上下文超过 30k tokens 时,模型往往会忽略中间的信息,只记得开头和结尾。
task_plan.md 的妙处在于,Agent 被强制要求在每次关键决策前重新读取这个文件。这就相当于把"当前目标"和"进度状态"强行刷到了上下文的最末端(Recency Bias),让模型瞬间找回注意力焦点。
一个标准的 task_plan.md 包含:
- Goal: 永恒的北极星指标
- Phases: 状态机的流转节点
- Key Questions: 动态更新的知识缺口
- Decisions Made: 架构决策的快照(防止反复横跳)
- Errors Encountered : 这一点至关重要------显式记录错误。普通 Agent 遇到报错会默默重试直到崩溃;而高级 Agent 会把错误写下来,分析原因,避免重蹈覆辙
2. notes.md ------ 海马体(长期记忆)
这是 Agent 的草稿纸和知识库。
在传统的 ReAct 循环中,观察结果(Observation)往往转瞬即逝。如果 Agent 查了 5 个 API 文档,这 5 次搜索结果会迅速占满上下文。
通过 notes.md,Agent 可以将 Research 阶段的成果压缩并持久化:
- "我查了 Stripe 的 API,关于退款的限制是..." -> 写入
notes.md - 下次需要时,只需读取
notes.md,而不需要重新搜索或回翻几千 tokens 的对话历史
3. Deliverables ------ 肌肉记忆(产出物)
将最终产出(代码、文档、报告)与过程文件分离。这保持了工作区的整洁,也让 Agent 明确"我在思考"(Plan/Notes)和"我在产出"(Deliverables)的界限。
三、实战演示:重构一个遗留系统
让我们通过一个真实的场景,看看这套系统是如何运作的。
任务:将一个基于 Flask 的老旧后端重构为 FastAPI,涉及 12 个 Endpoints。
阶段 1:初始化 (The Setup)
Agent 不会直接开始写代码。它首先创建 task_plan.md:
markdown
# Task Plan: Flask to FastAPI Migration
## Goal
Migrate all 12 endpoints from Flask to FastAPI preserving business logic.
## Phases
- [x] Phase 1: Analysis & Dependency Mapping
- [ ] Phase 2: Core Middleware & Auth Migration
- [ ] Phase 3: Endpoint Migration (Batch 1: Users)
- [ ] Phase 4: Endpoint Migration (Batch 2: Products)
- [ ] Phase 5: Verification阶段 2:研究与积累 (Research Loop)
Agent 扫描代码库,发现老的鉴权逻辑很复杂。它不会把所有代码都塞进上下文,而是将分析结果写入 notes.md:
markdown
# Notes
## Auth Logic Analysis
- Uses `flask_login` currently.
- Dependency: `User` model in `models.py`.
- **Decision**: Port to `FastAPI` dependency injection system using `OAuth2PasswordBearer`.阶段 3:决策与记录 (Decision Making)
在迁移过程中,Agent 发现了一个循环依赖问题。
普通 Agent 可能会尝试修复 -> 失败 -> 再尝试 -> 再失败,直到耗尽 Token。
Planning-with-Files Agent 会这样做:
- 捕获错误 :将
ImportError写入task_plan.md的Errors Encountered区域 - 分析策略:读取 Plan,看到这个错误已经出现过一次
- 调整决策 :在
Decisions Made中记录:"由于循环依赖,决定将 DTO 模型拆分到单独的schemas.py文件" - 执行:执行拆分
阶段 4:状态机流转 (State Transition)
每完成一批迁移,Agent 就会在 task_plan.md 中打钩。
这不仅仅是为了给人类看,更是为了告诉未来的自己:"这一步已经稳了,不要再回头怀疑这部分代码。"
四、适用边界:什么时候该用,什么时候别用
任何工具都有它的适用边界。Planning with Files 不是银弹。
适合使用的场景
- 多阶段复杂任务:需要 3 个以上阶段、跨越不同领域
- 研究密集型任务:需要收集大量外部信息并综合
- 长时间跨度任务:可能中断后恢复,需要重建上下文
- 需要回溯决策的任务:架构决策需要被记录和审查
不适合使用的场景
- 简单查询任务:单次工具调用即可完成,无需额外开销
- 快速探索性任务:过度结构化会阻碍灵活性
- 实时性要求高的任务:文件 I/O 延迟在毫秒级敏感系统中可能成为瓶颈
与 TodoWrite 的关系
Planning with Files 并非要取代 TodoWrite。TodoWrite 更适合轻量级任务追踪,3 文件模式则针对持久化、知识积累、复杂协调进行了优化。选择取决于任务复杂度------简单任务用 Todo,复杂任务用 Files。
五、为什么这改变了游戏规则?
Planning with Files 实际上实现了一个慢思考(System 2) 循环。
- LLM 的直觉是 System 1:快速、直接、容易出错
- 文件系统强化的循环是 System 2:规划、记录、反思、修正
这套机制最大的价值,在于它赋予了 Agent "时间感"。
普通的 Agent 生活在"永远的现在"(Eternal Now),只有当前的上下文。
拥有文件系统的 Agent 拥有了"过去"(Decisions/Errors)和"未来"(Phases)。
六、实践建议:从模式到习惯
渐进式采用
首次接触?从单一文件 task_plan.md 开始,熟悉后再引入 notes.md 和交付物文件。
模板定制
默认模板是通用起点,但应根据需求定制。例如增加"风险项"部分记录潜在风险,或增加"依赖项"部分追踪外部依赖。
与版本控制集成
task_plan.md 和 notes.md 本身也是文本文件,可以纳入 Git。这为任务级别的回滚和历史追踪提供了可能------当一个决策路径被证明不可行时,可以快速恢复到之前的状态。
结语
技术圈常说:"Talk is cheap, show me the code."
但在 Agent 开发中,我要说:"Code is ephemeral, show me the plan."
如果你正在构建或使用 AI Agent,试着强迫它(或者强迫你自己)使用这套 3 文件模式。你会发现,原本不可控的随机过程,突然变成了可预测的工程流水线。
这就是 20 亿美元背后的秘密:让 AI 学会像工程师一样,拿笔记录,而不是像赌徒一样,凭记忆梭哈。
本文的核心方法论来源于 Manus 团队的官方博客《Context Engineering for AI Agents: Lessons from Building Manus》。