
长视频理解是多模态大模型关键能力之一。尽管OpenAI GPT-4o、Google Gemini等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。近日,智源研究院联合上海交通大学等机构,正式发布新一代超长视频理解模型:Video-XL-2。相较于上一版本的Video-XL,该模型在多个维度全面优化了多模态大模型对长视频内容的理解能力:
-
效果更佳:Video-XL-2 在长视频理解任务中表现出色,在 MLVU、Video-MME、LVBench 等主流评测基准上达到了同参数规模开源模型的领先水平。
-
长度更长:新模型显著扩展了可处理视频的时长,支持在单张显卡上高效处理长达万帧的视频输入。
-
速度更快:Video-XL-2 大幅提升了处理效率,编码 2048 帧视频仅需 12 秒,显著加速长视频理解流程。
目前,Video-XL-2 的模型权重已全面向社区开放。未来,该模型有望在影视内容分析、异常行为监测等多个实际场景中展现重要应用价值。
项目主页:https://unabletousegit.github.io/video-xl2.github.io/
模型hf链接:https://huggingface.co/BAAI/Video-XL-2
仓库链接:https://github.com/VectorSpaceLab/Video-XL
技术简介
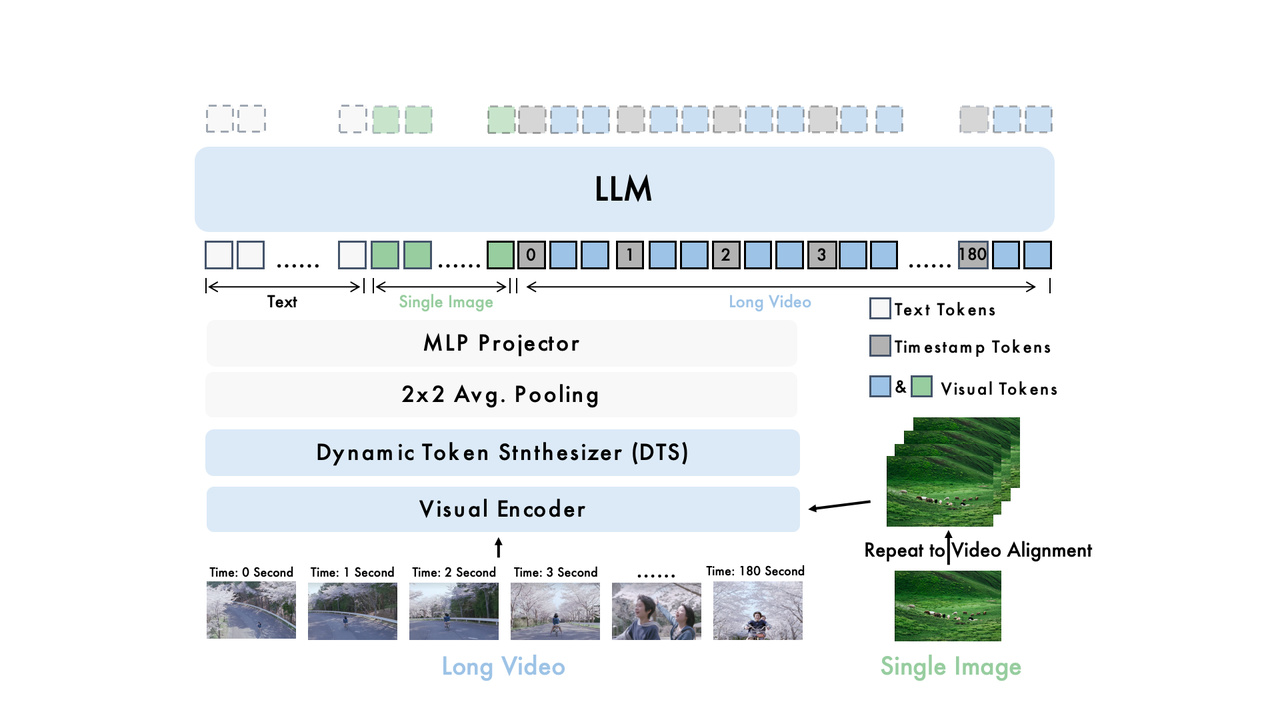
图1:Video-XL-2的模型架构示意图
在模型架构设计上,Video-XL-2 主要由三个核心组件构成:视觉编码器(Visual Encoder) 、动态 Token 合成模块 (Dynamic Token Synthesis, DTS) 以及大语言模型(LLM)。具体而言,Video-XL-2 采用 SigLIP-SO400M 作为视觉编码器,对输入视频进行逐帧处理,将每一帧编码为高维视觉特征。随后,DTS 模块对这些视觉特征进行融合压缩,并建模其时序关系,以提取更具语义的动态信息。处理后的视觉表征通过平均池化与多层感知机(MLP)进一步映射到文本嵌入空间,实现模态对齐。最终,对齐后的视觉信息输入至 Qwen2.5-Instruct,以实现对视觉内容的理解与推理,并完成相应的下游任务。

图2:Video-XL-2的训练阶段示意图
在训练策略上,Video-XL-2 采用了四阶段渐进式训练 的设计 ,逐步构建其强大的长视频理解能力。前两个阶段主要利用图像/视频-文本对,完成DTS模块的初始化 与跨模态对齐 ;第三阶段则引入更大规模,更高质量的图像与视频描述数据,初步奠定模型对视觉内容的理解能力 ;第四阶段,在大规模、高质量且多样化的图像与视频指令数据上进行微调,使Video-XL-2 的视觉理解能力得到进一步提升与强化,从而能够更准确地理解和响应复杂的视觉指令。
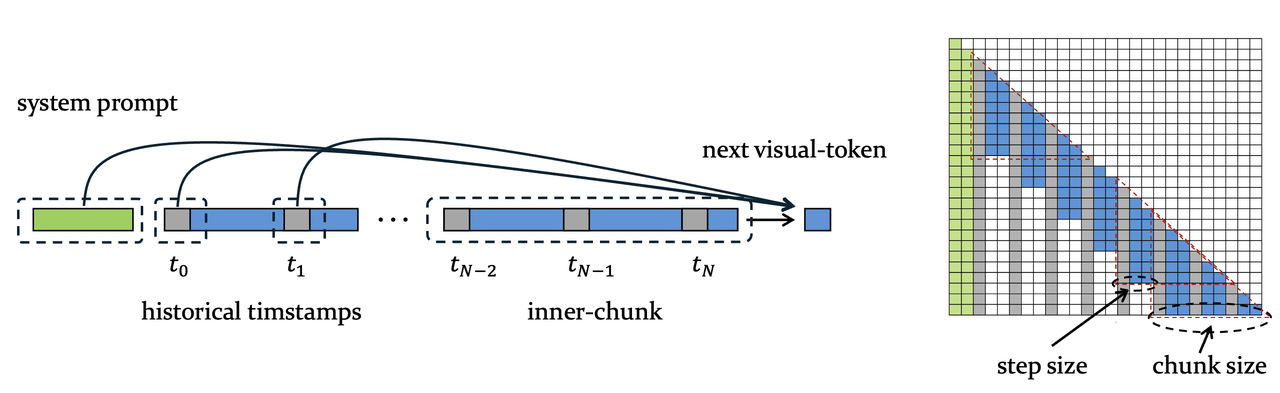
图3. Chunk-based Prefilling
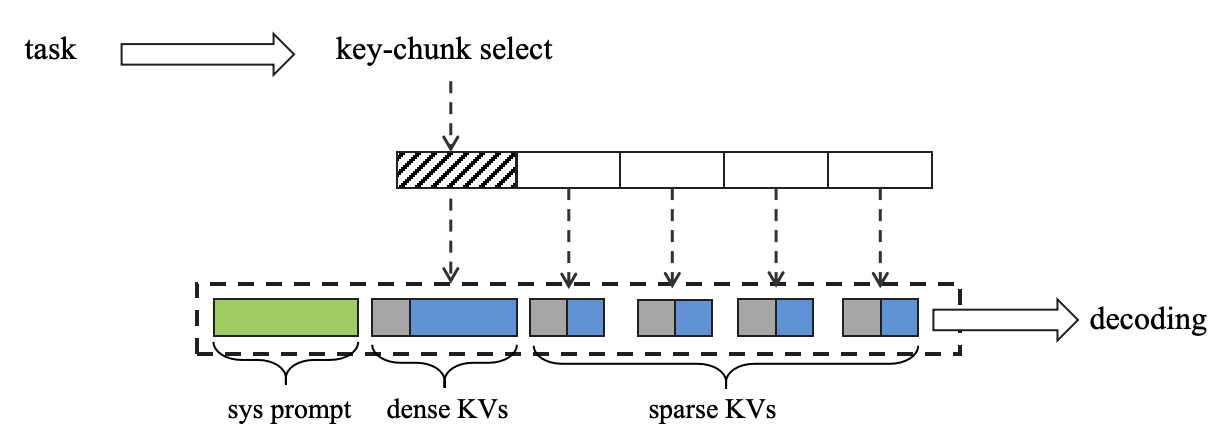
图4. Bi-granularity KV Decoding
此外,Video-XL-2还系统性设计了效率优化策略 。首先,Video-XL-2引入了分段式的预装填策略 (Chunk-based Prefilling,如图3所示):将超长视频划分为若干连续的片段(chunk),在每个 chunk 内部使用稠密注意力机制进行编码,而不同 chunk 之间则通过时间戳传递上下文信息。该设计显著降低了预装填阶段的计算成本与显存开销。其次,Video-XL-2还设计了基于双粒度KV的解码机制(Bi-granularity KV Decoding,如图4所示):在推理过程中,模型会根据任务需求,选择性地对关键片段加载完整的KVs(dense KVs),而对其他次要片段仅加载降采样后的稀疏的KVs(sparse KVs)。这一机制有效缩短了推理窗口长度,从而大幅提升解码效率。得益于上述策略的协同优化,Video-XL-2 实现了在单张显卡上对万帧级视频的高效推理,显著增强了其在实际应用场景中的实用性。
实验效果
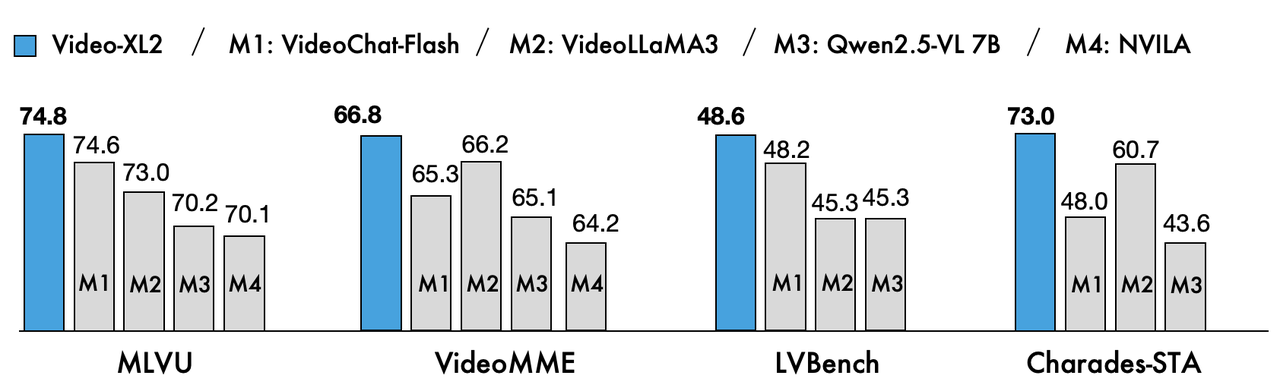
图5:Video-XL-2的主要对比结果
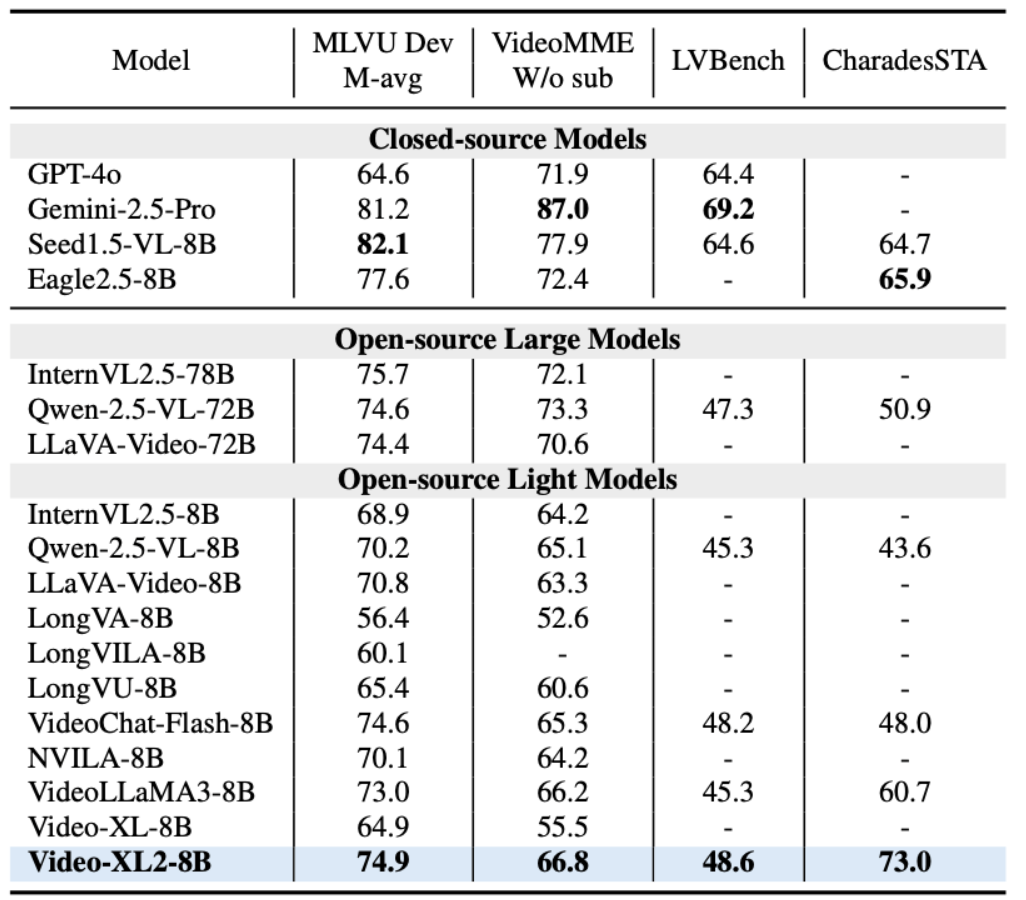
表1:Video-XL-2的全面对比结果
在模型具体表现方面,Video-XL-2 在 MLVU、VideoMME 和 LVBench 等主流长视频评测基准上全面超越现有所有轻量级开源模型,达成当前最先进性能(SOTA),相较第一代 Video-XL 实现了显著提升。尤其值得关注的是,在 MLVU 和 LVBench 上,Video-XL-2 的性能已接近甚至超越了如 Qwen2.5-VL-72B 和 LLaVA-Video-72B 等参数规模高达 720 亿的大模型。此外,在时序定位(Temporal Grounding)任务中,Video-XL-2 也表现出色,在 Charades-STA 数据集上取得了领先的结果,进一步验证了其在多模态视频理解场景中的广泛适用性与实际价值。
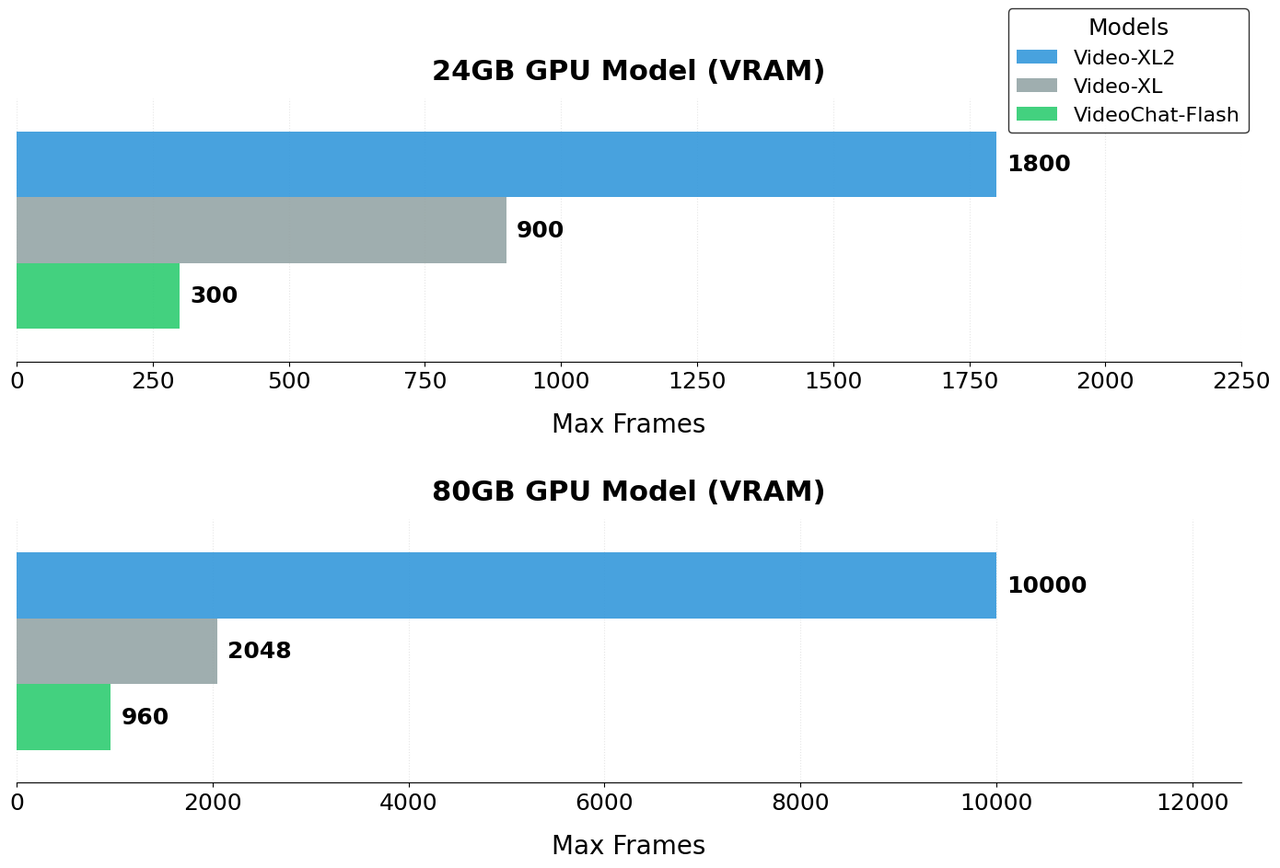
图6:Video-XL-2 输入长度的对比展示
除了效果上的提升,Video-XL-2在视频长度方面也展现出显著优势 。如图6所示,在单张24GB消费级显卡(如 RTX 3090 / 4090)上,Video-XL-2可处理长达千帧的视频;而在单张 80GB 高性能显卡(如 A100 / H100)上,模型更支持万帧级视频输入,远超现有主流开源模型。相较于VideoChat-Flash 和初代 Video-XL,Video-XL-2显著拓展了视频理解的长度并有效降低了资源需求,为处理复杂的视频任务提供了有力的支撑。

图7:Video-XL-2 Prefilling 速度的对比展示
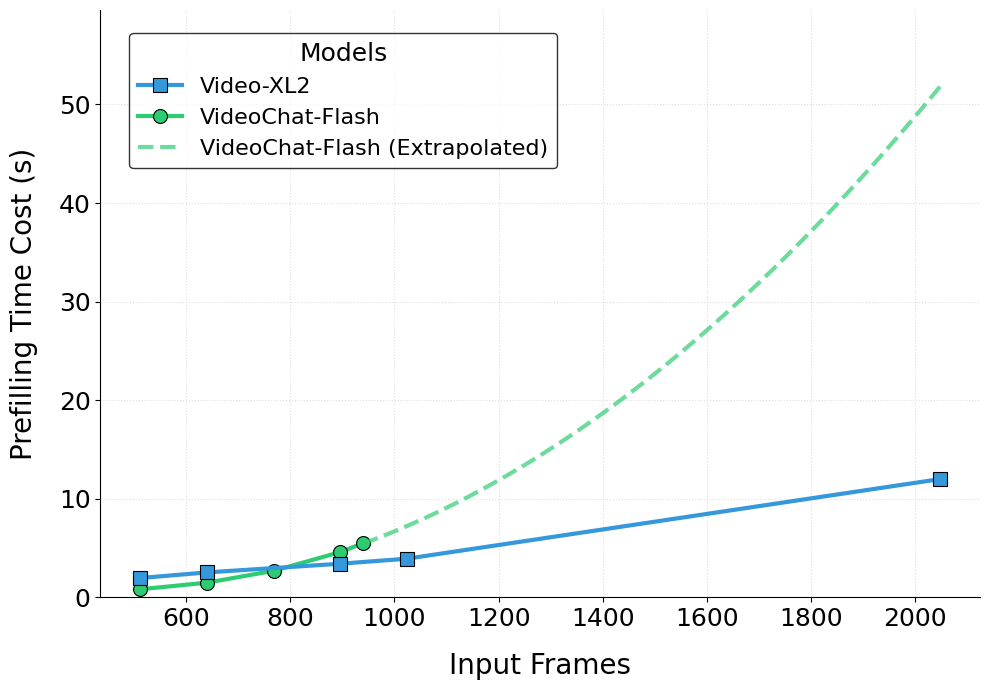
图8:Video-XL-2 Prefilling 速度和输入帧数的关系图
最后,Video-XL-2 在速度上也展现出卓越性能。如上图所示,Video-XL-2仅需12秒即可完成 2048 帧视频的预填充。更重要的是,其预填充时间与输入帧数之间呈现出近似线性增长,体现了其出色的可扩展性。相比之下,Video-XL与VideoChat-Flash 在输入长视频条件下的工作效率明显落后于Video-XL-2。
应用潜力
以下是一些具体的例子,将展示 Video-XL-2 在实际应用中的巨大潜力:
Example 1 电影情节问答:

Question: A bald man wearing a green coat is speaking on the phone. What color is the phone?
Answer: The phone's color is red
Example 2 监控异常检测:

Question: Is there any unexpected event happening in this surveillance footage?
Answer: There is physical altercation between the customers and the store employees
Example 3: 影视作品内容总结
Example4:游戏直播内容总结
得益于出色的视频理解能力与对超长视频的高效处理性能,Video-XL-2 在多种实际应用场景中展现出很高的应用潜力。例如,它可广泛应用于影视内容分析、剧情理解、监控视频中的异常行为检测与安全预警等任务,为现实世界中的复杂视频理解需求提供高效、精准的技术支撑。
