"在云计算的下半场,向量数据库将成为 AI 基础设施的核心。谁掌握了向量数据,谁就掌握了 AI 时代的数据引力。TOS Vectors 的使命,就是让每个企业都能轻松驾驭海量向量数据,释放 AI 的无限潜能。"
------ 产品愿景宣言
技术背景与挑战
传统的信息检索方式,更多是依赖关键词匹配。比如你在搜索框里输入"新能源车",搜索引擎可能会优先返回包含"新能源"和"汽车"两个关键词的页面。但是问题在于如果有人写的是"电动车",可能就错过了。如果有人写的是"绿色出行",虽然意思接近,但你也未必能搜到。检索引擎基于关键字的搜索看不懂语义。而向量不同,当文本被转化为向量时,它所表达的含义被编码在高维空间里。于是,"新能源车"和"电动车"的向量会非常接近,哪怕字面上完全不同。换句话说,机器第一次具备了理解"意思"的能力,而不仅仅是看字面。
在 AI 的世界里,这种"理解"是通过向量来实现的。当一段文字、一张图片、甚至一段音频被转化为向量后,它们就能被放进同一个"语义空间",AI 可以通过比较这些向量的距离,来判断"哪些东西相似",也就是"哪些东西更符合你的需求"。
然而,这种"语义理解"的智能飞跃,背后伴随着高昂的成本。向量数据不仅维度高、计算量大,而且增长速度惊人。当企业试图将这种能力落地到实际业务中时,很快就撞上了一堵墙:传统的数据库架构在处理海量向量时,不仅响应变慢,更让存储成本变成了天文数字。这种"智能需求"与"架构负担"之间的尖锐矛盾,将整个行业推向了转折点。
1. 传统向量数据库的架构困境与商业挑战
-
存算紧耦合架构的天然瓶颈:计算资源与存储容量强绑定,无法独立扩展。
-
成本昂贵:冷热数据同价存储,百亿级以上的向量数据存储及查询成本成为 AI 应用的不可承受之重。
-
资源利用率陷阱:为应对峰值流量必须过度配置资源,实际利用率普遍低于 30%。
2. 云原生向量数据库的时代机遇
-
存算分离架构革命:借鉴Snowflake的成功范式,云厂商普遍实现了计算与存储的独立弹性伸缩。
-
对象存储的经济性优势:利用对象存储底座,可以极大降低存储成本。
-
Serverless架构的终极弹性:真正实现按查询付费,让企业只为实际价值付费。
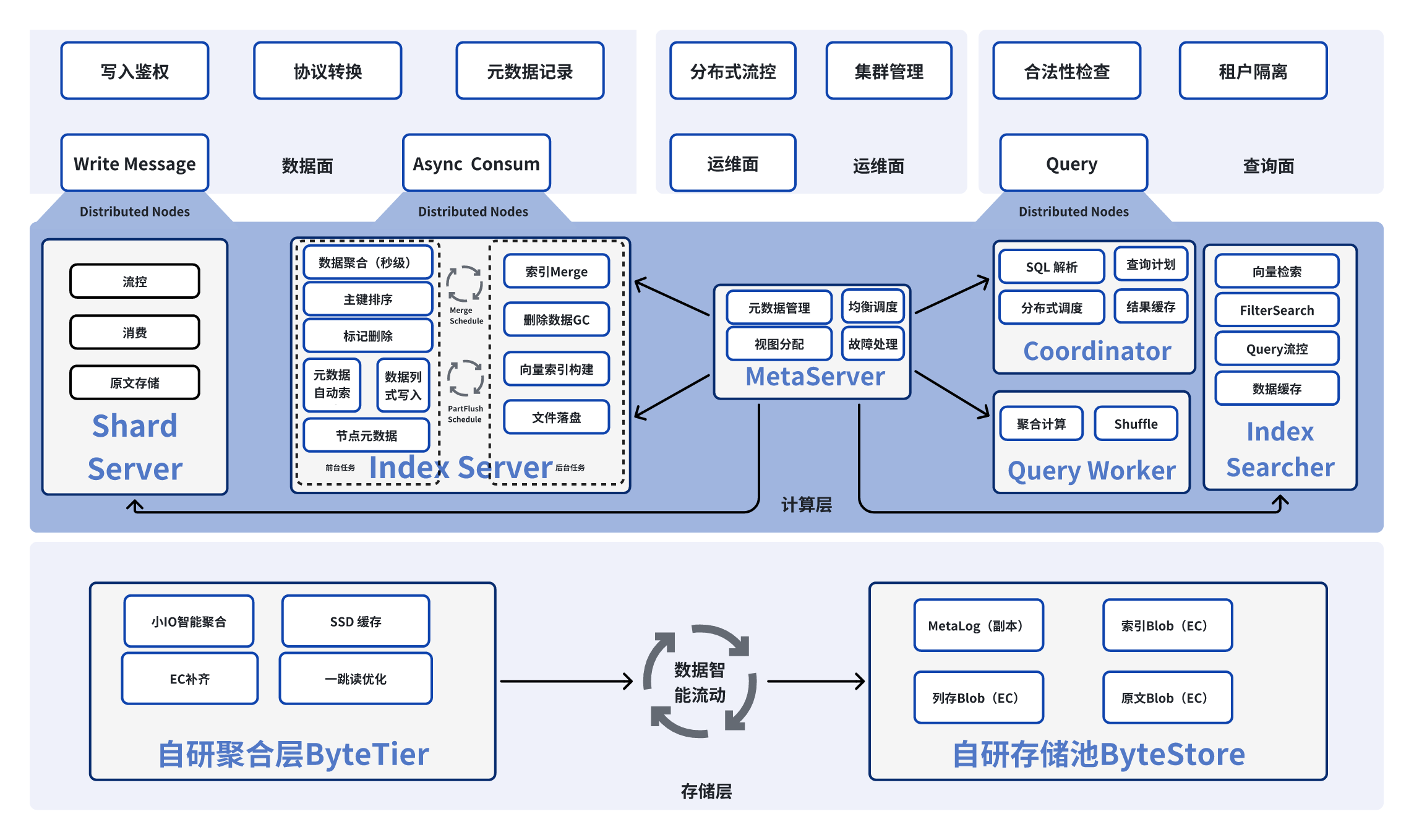
TOS Vector Bucket 架构设计
火山引擎对象存储 TOS 在火山引擎 Force 大会上宣布推出 Vector Bucket,其定位非常明确:面向大规模、长周期存储 、低频查询 的场景,提供高性价比的解决方案,不仅补足了高频/低频数据的分层需求,而且显著降低了企业大规模使用向量的门槛。 TOS Vector Bucket 整体架构采用了数据面与管控面彻底分离、存算及读写分离、元数据去中心化的设计范式,有效解决了传统向量数据库诸多痛点,包括:
-
**扩展性瓶颈:**TOS Vector Bucket 采用存算分离架构。原文写入、索引构建、向量检索等各个服务均可实现弹性扩展,流量可以按租户(Account)、向量桶(Vector Bucket)、索引(Index)等多个维度在归属节点及物理集群间进行灵活调度,并且实现了热点节点的 10 秒级切换调度。
-
**存储成本:**TOS Vector Bucket 实现了智能数据分层。元数据、小 IO、消息原文写入自研高性能存储池 ,同时索引、列存会自动沉降到 对象存储 TOS,在确保高性能的基础上,降低了数据的存储成本。
-
**隔离性:**TOS Vector Bucket 复用 TOS Bucket 多租户管理能力,原生支持多租户,具备租户、Bucket、Index 三层隔离能力。
-
按需使用付费: TOS Vector Bucket 复用 TOS 对象的计算资源,能够弹性扩展、按需付费,用户只需要为使用到的资源买单。
整体架构如下图所示:
关键技术实现与创新
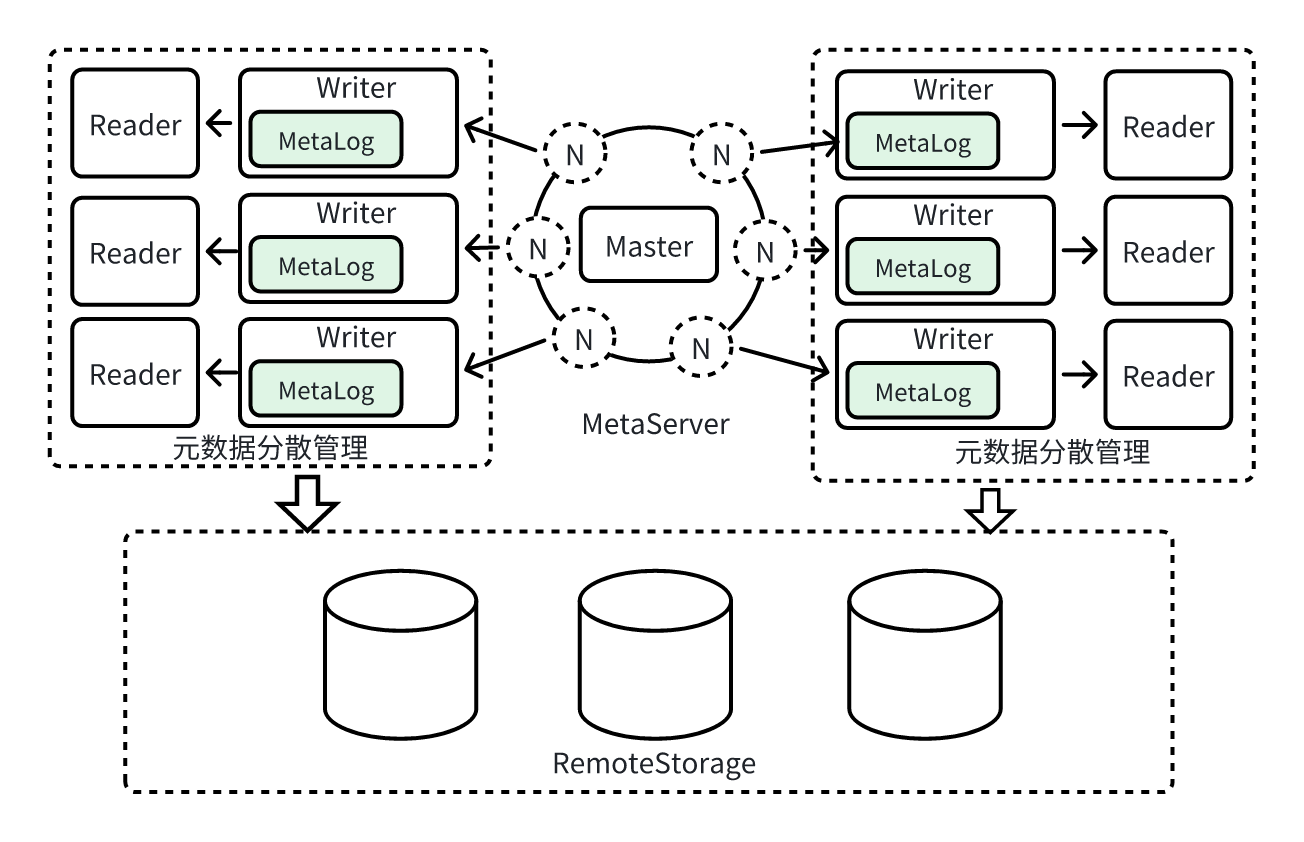
去中心化的存算分离
计算层整体采用去中心化的松耦合设计,我们将元数据按归属打散到了写入节点,并持久化到共享存储池。元数据服务(MetaServer)基于各节点负载和流量,实现自动负载均衡,元数据归属在秒级实现无损迁移。相较于"中心化 KV 完全共享元数据"的架构,去中心化的存算分离在性能、扩展、鲁棒性、故障域治理等维度均具有显著优势:
1. 写入IO链路在单节点内闭环,减少核心链路外部依赖,确保性能,提升稳定性。
元数据本地归属与缓存,减少跨节点 RPC 与中心读写,避免网络放大与序列化开销,显著提升吞吐,避免 P95/P99等长尾延迟带来的性能抖动。
2. 无中心化瓶颈,计算资源可无限水平扩展
元数据随写入归属分散,数据与元数据同向水平扩展,中心不再成为单点瓶颈。基于负载,实现分钟级自动均衡,打散流量,消除热点。
3. 鲁棒性与故障隔离
无中心单点,将故障半径有效控制在单节点内。基于共享的 MetaLog,实现了故障节点的分钟级感知和秒级数据接管,保障关键业务 SLO。
云原生(Cloud-Native)索引算法
相较于 HNSW 索引对内存和 SSD 巨大的资源消耗,TOS Vector Bucket 采用了字节自研的 Cloud-Native 向量索引库 Kiwi。Kiwi 支持包括更加适合磁盘的向量索引 DiskANN 在内的多种向量索引,从一开始就采用了 Cloud-Native 的设计,并在开源向量索引库的基础上做了极致的性能和工程优化。具体包括:
1. IO 性能优化:引入 io_uring,提升 15% 吞吐
Kiwi 在 IO 路径上全面采用 io_uring 高性能异步 I/O,替代传统 AIO 的线程池模型,通过减少系统调用次数、降低内核态/用户态切换成本、并利用提交队列与完成队列实现真正的异步化,加速磁盘访问效率。结合批量提交与批量回收策略,Kiwi 在中高并发场景下对磁盘带宽和 IOPS 的利用更加充分,整体搜索吞吐相比开源方案提升约15%,为磁盘友好的向量搜索提供了更高的底层 IO 性能。
2. 搜索性能优化:CPU--IO overlap + 动态 Beam + 智能 Entry-Point
Kiwi 在搜索阶段引入 CPU--IO 完全重叠调度 ,让距离计算、候选扩展与磁盘访问并行执行,显著降低 pipeline bubble 时间。为减少无效磁盘访问,Kiwi 提供 动态 beamwidth 控制 ,根据候选队列的结构特征和梯度动态调整 beam 大小,提高有效 IO 利用率。同时利用 DRAM/SSD 热节点,构建搜索友好的 entry-point 热启动策略 ,进一步减少初始 IO。最终结果是在低并发下平均延时下降 40%;而在达到硬件带宽瓶颈的最大 QPS 下,Kiwi 的平均延迟可比开源方案优化 最高 4×,实现高吞吐与低延迟的双提升。
3. 索引构建优化:SIMD、预取与优化 k-means,将构建速度提升 50%
在索引构建方面,Kiwi 通过 SIMD 加速距离计算(AVX512)、显式数据预取降低 cache miss,以及优化后的 k-means 聚类流程,全方位加速构建 pipeline 的 compute-bound 环节。同时改进多线程调度,使构建过程具备更高的并行利用效率并避免尾部线程拖慢进度。综合这些优化,Kiwi 的索引构建速度相比开源实现提升约 50%,在大规模向量数据集上尤其显著。
4. 索引--本地多层缓存协同:云原生场景下与纯本地 SSD 表现接近
针对云原生部署中常见的 remote-storage + 本地缓存组合,Kiwi 设计了索引与多层级本地缓存协同架构,涵盖 DRAM、SSD 与远程对象存储三层结构,并基于 SLRU 与查询模式优化缓存调度。通过查询预热、高频节点优先缓存、按需远程拉取等组合策略,Kiwi 在本地缓存充足时性能几乎与纯本地 SSD 部署一致;而在缓存不足时,通过 IO--compute overlap 与动态 beam 控制依然维持稳定时延和吞吐,使其特别适合混合云、远程存储等复杂环境。
5. 完善监控体系:细粒度指标拆解,直观定位瓶颈
Kiwi 为生产环境提供了全面的可观测性与监控体系,将搜索流程拆解为 IO 阶段延迟、距离计算时间、候选扩展耗时、beamwidth 动态变化、cache hit/miss、pipeline stall 比例等关键维度,使性能分析颗粒度更细、瓶颈定位更加直接。通过这些指标,团队能够量化各类优化策略的实际收益并精准诊断性能问题,为持续优化 Kiwi 在云原生场景下的表现提供坚实基础。
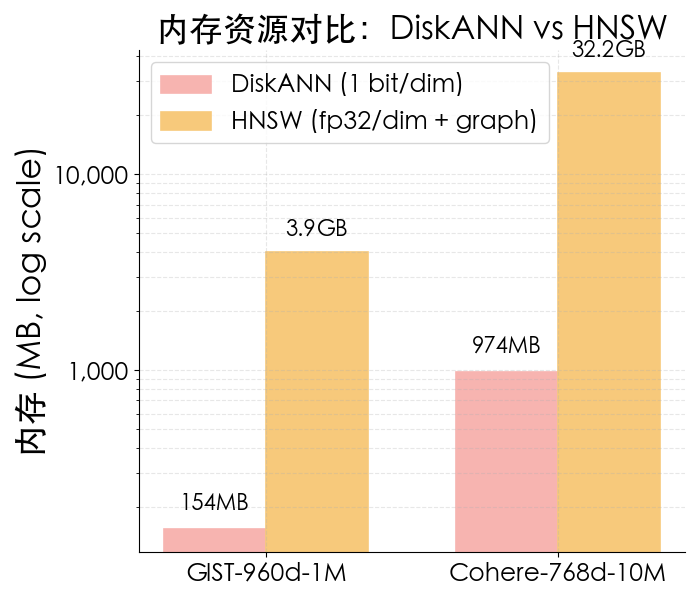
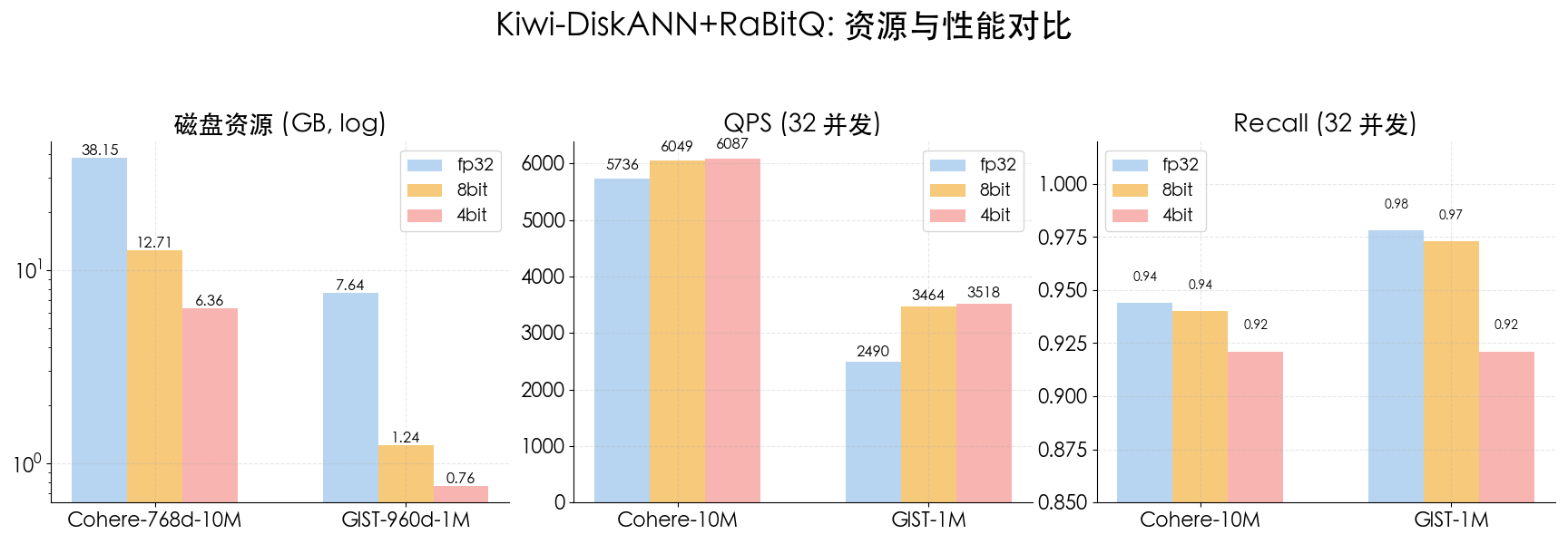
DiskANN 1-bit 量化实现>32×内存节省
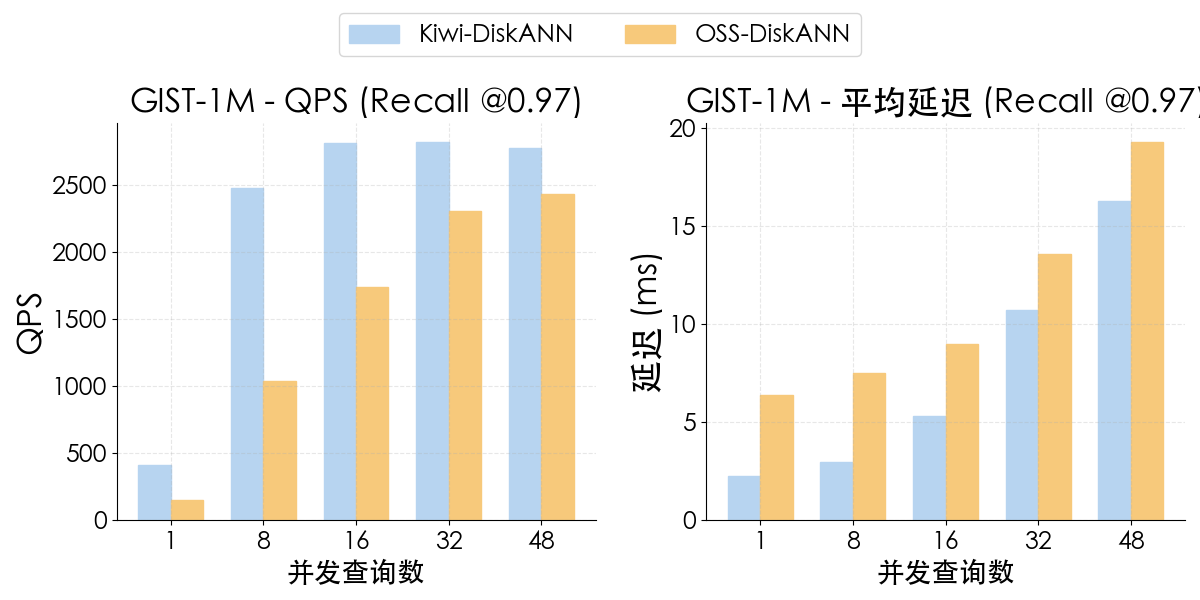
Kiwi-DiskANN 在低并发与高并发场景下均能显著降低延迟:在峰值吞吐下 延迟仅为 OSS-DiskANN 1/4,且 Kiwi 只需使用 16 核 CPU 即可达到峰值 QPS,相比 OSS-DiskANN(48 并发)显著减少了 CPU 资源消耗。
智能量化
Kiwi 在向量量化方面进行了系统性的增强,形成了PQ、LVQ 与 RaBitQ 并行支持 的量化体系,为不同场景提供兼顾精度、性能与构建成本的灵活选择。其中,LVQ(Local Vector Quantization) 是一种轻量级的 8-bit 量化技术,具有极低的构建成本与极小的精度损失,非常适合需要频繁更新或流式增量构建的业务场景。在低成本与在线构建性能至关重要的系统中,LVQ 能在保持高精度的同时几乎不增加额外负担。而 RaBitQ 作为当前 SOTA 的通用量化方法,支持从 1-bit 到多 bit 的灵活配置,在相同 bit 数下,其量化精度普遍显著高于传统 PQ;在中高 bit 配置下(例如 4--9 bit),RaBitQ 的构建速度更是远快于 PQ,非常适用于大规模数据集的高精度向量压缩。
RaBitQ 的核心思想是:把高维向量投影到一组精心设计的"方向"上,然后只记录每个方向上的符号或区间,从而用极少的 bit 重建原来的距离信息。
- 1-bit:只保留"方向感"的极简量化
在最基础的 1-bit 版本中,RaBitQ 会对每个向量归一化后做一次随机旋转,然后看它在某个方向上的投影是正还是负:正就是 1,负就是 0。这样,一个 D维向量就被压缩成 D个 bit(例如 512 维只需 64B)。虽然听起来很粗糙,但由于这些方向是精心构造的随机正交向量,1-bit RaBitQ 量化出的码本具有无偏性 与渐近最优的误差界:维度越高,误差越小。这也是 RaBitQ 能用极低 bit 做高精度估计的理论基础。
- 多-bit:比记录"正/负"更进一步,记录"落在哪个区间"
为获得更高精度,RaBitQ 会把每个投影值划分成多个区间,例如 4 个(2-bit)、8 个(3-bit)、16 个(4-bit)......
每多 1 个 bit,对应的区间数翻倍,距离估计的误差就进一步下降。关键是:多-bit RaBitQ 仍然沿用它的随机旋转框架,因此保留了 1-bit 版本中"无偏估计 + 渐近最优误差"的理论保证。也就是说,它不仅精度更高,而且其在"bit 数---误差"之间达到了理论上最优的下降速度。
下图展示了 RaBitQ 在二维空间上 2-bit 量化时如何构建码本。左侧蓝色的点是规则网格上的向量集合;右侧红点是对这些向量归一化后的结果。最后,对这些红点施加一次随机旋转,就得到用于量化的最终码本 。整个过程本质上是:先取一组均匀分布的方向 → 归一化 → 随机旋转 → 作为多-bit 量化的方向集合。
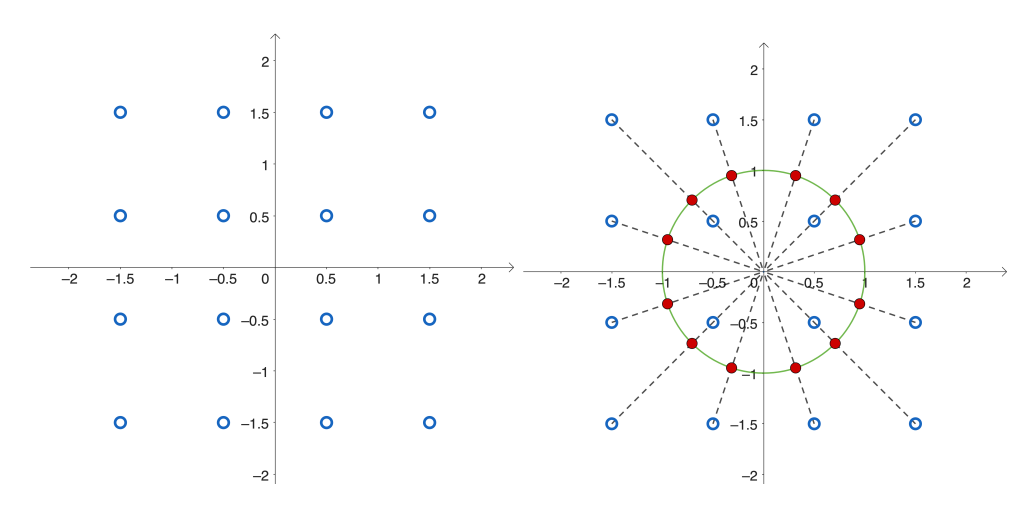
From Jianyang Gao, et.al., "Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neighbor Search", SIGMOD 2025, available at https://arxiv.org/abs/2409.09913
在与 DiskANN 的深度融合中,Kiwi 进一步实现了多 bit 量化在不同存储层级的最优分配:
-
在内存层,Kiwi 支持 1-bit PQ 与 1-bit RaBitQ 等极低 bit 量化,以最小的内存 footprint 支撑高并发搜索。
-
在磁盘层,Kiwi 支持高 bit 的高精度量化,包括 8-bit LVQ 与 4--9 bit RaBitQ,使磁盘索引在相同存储预算下具备更高精度。
在多个 benchmark 中,Kiwi 的量化方案展现了显著优势。例如,在 4-bit 配置下:
-
**索引存储成本相比全精度降低高达 80%,**在保证高精度的前提下显著减少磁盘使用量。
-
4-bit RaBitQ(磁盘)将召回率从全精度的 0.97 下降至 0.92,明显优于 DiskANN + Disk-PQ 的 4-bit 方案(Recall≈0.90)
多租户隔离
TOS Vectors 通过命名空间隔离、基于角色的权限控制、隔离限流机制、审计日志和动态资源调度,确保每个租户的数据安全、资源公平分配与操作透明,从而实现高效的多租户环境管理:
-
命名空间隔离: 在火山引擎 TOS Vectors 中,每个租户都有一个唯一的命名空间(Namespace)。命名空间不仅仅是一个逻辑隔离单元,它还支持独立的访问控制以及配额配置。不同租户的向量数据(VectorData)和元数据(如 VectorBucket 和 VectorIndex)会逻辑隔离分开存储,避免了跨租户的数据泄露风险。每个租户的命名空间可以灵活地扩展,支持海量数据存储和快速查询。
-
权限控制: TOS Vectors 采用基于角色的访问控制(RBAC)策略,允许租户根据其角色分配不同级别的权限。每个租户的管理员可以为用户配置个性化的访问控制策略,限制对向量桶(VectorBucket)和索引(VectorIndex)的访问。权限控制可以为每个向量存储桶设置不同的读写权限,确保数据的安全性和私密性。租户还可以为不同的角色生成独立的访问密钥(Access Key)和密钥 ID(Secret Key),支持动态权限变更。
-
资源调度与限制: TOS Vectors 采用高效的资源调度引擎,保证每个租户在高并发场景下的资源公平分配。通过监控各租户的存储、计算、网络资源使用情况,系统可以动态调整资源配额,防止某个租户的过度使用影响到其他租户的性能。资源配额支持动态扩展和缩减,租户可以根据实际需求灵活调整资源配置,避免资源浪费。
-
审计与日志: 为了加强透明性和操作追踪,TOS Vectors 对每个租户的操作进行详细的审计日志记录。这些日志包括关键的数据操作记录,如向量桶/向量索引的创建/删除/修改等。通过日志,管理员可以实时审计每个租户的操作行为,识别潜在的安全风险或资源滥用。此外,租户自身也能访问日志数据,用于调试和操作优化。
性能测试
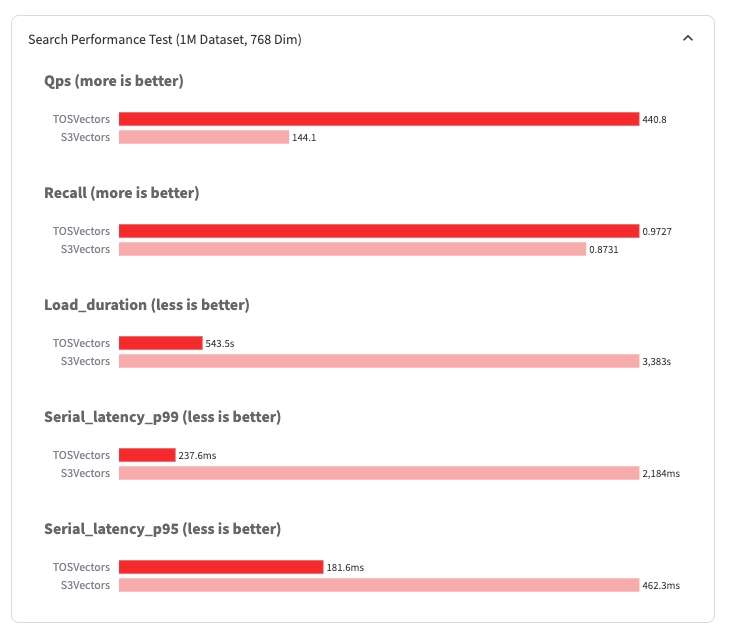
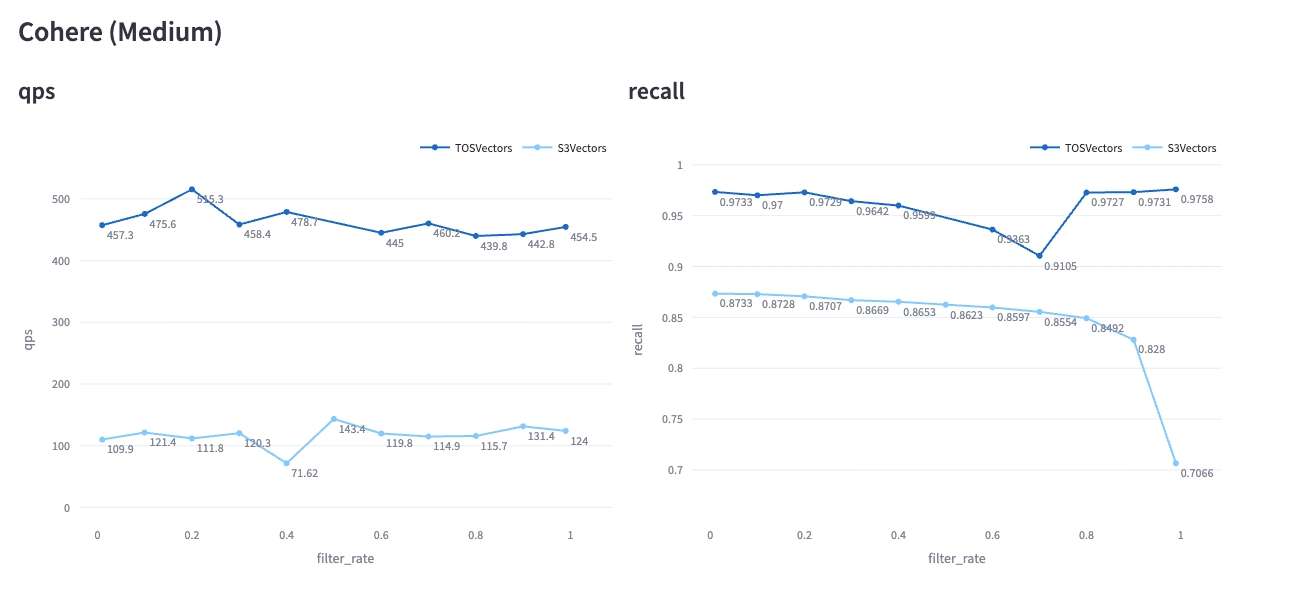
我们使用 VectorDBBench Medium Cohere (768dim, 1M) 数据集对 TOS Vector Bucket 和 S3 Vector Bucket 进行测试。测试结果对比如下:
TOS Vector Bucket 的写入性能、纯向量检索、带Filter的向量检索 QPS、Recall 均优于相同数据集及测试条件下的 S3 Vector Bucket。并且在 Filter 查询场景,我们会根据过滤后的数据集大小自动进行查询优化,避免 Recall 的急剧下降,将 Recall 维持在一个比较平稳的水平。
应用场景与案例
TOS Vectors 的产品形态面向多种应用场景:
-
首先通过与火山引擎高性能向量数据库的协同组合,打造更完整的方案竞争力。
-
同时进一步与 火山方舟 Embedding API 等能力深度结合,增强生态黏性,为用户提供从 向量生成、存储到检索 的一站式体验。
与火山方舟结合
多模态应用场景下,用户调用方舟 Embedding 模型 后,可以直接将生成的向量数据存入 TOS Vector Bucket,以便后续的检索和查询,从而支撑各种跨文本、图像、音频、视频等多模态内容的检索需求。这不仅显著提升了检索效率,也增强了火山在多模态存储与搜索场景下的整体方案黏性。与此同时,TOS Vector Bucket 还能与 TOS Bucket(FNS/HNS) 以及方舟 AIGC 链路深度结合,为在线 AIGC 应用提供统一的数据存储与检索能力。这样一来,无论是生成内容的存放,还是后续的语义级调用,都能在同一个架构下完成,真正实现存储/生成/检索的一体化闭环。
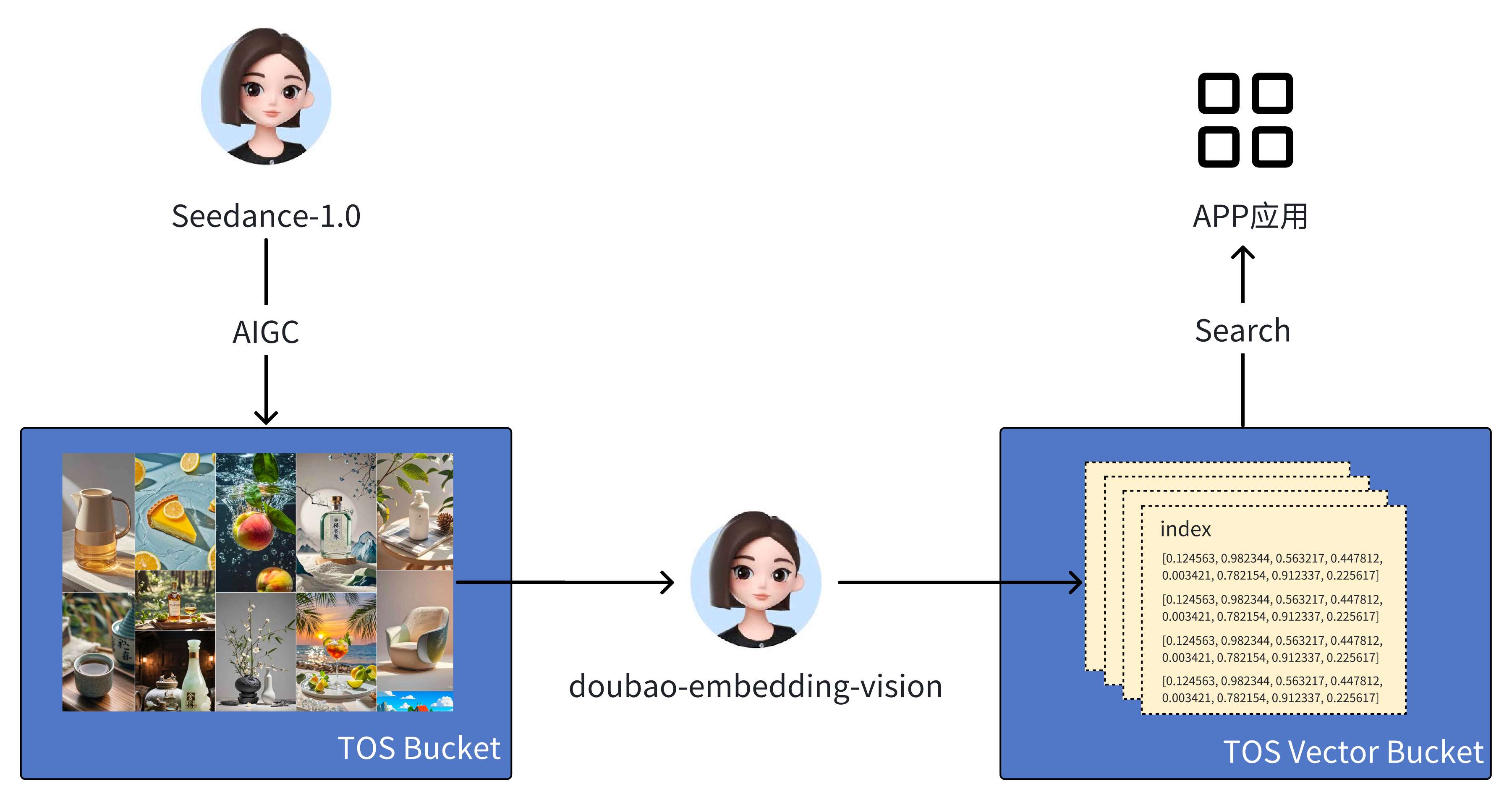
与火山数据库产品结合
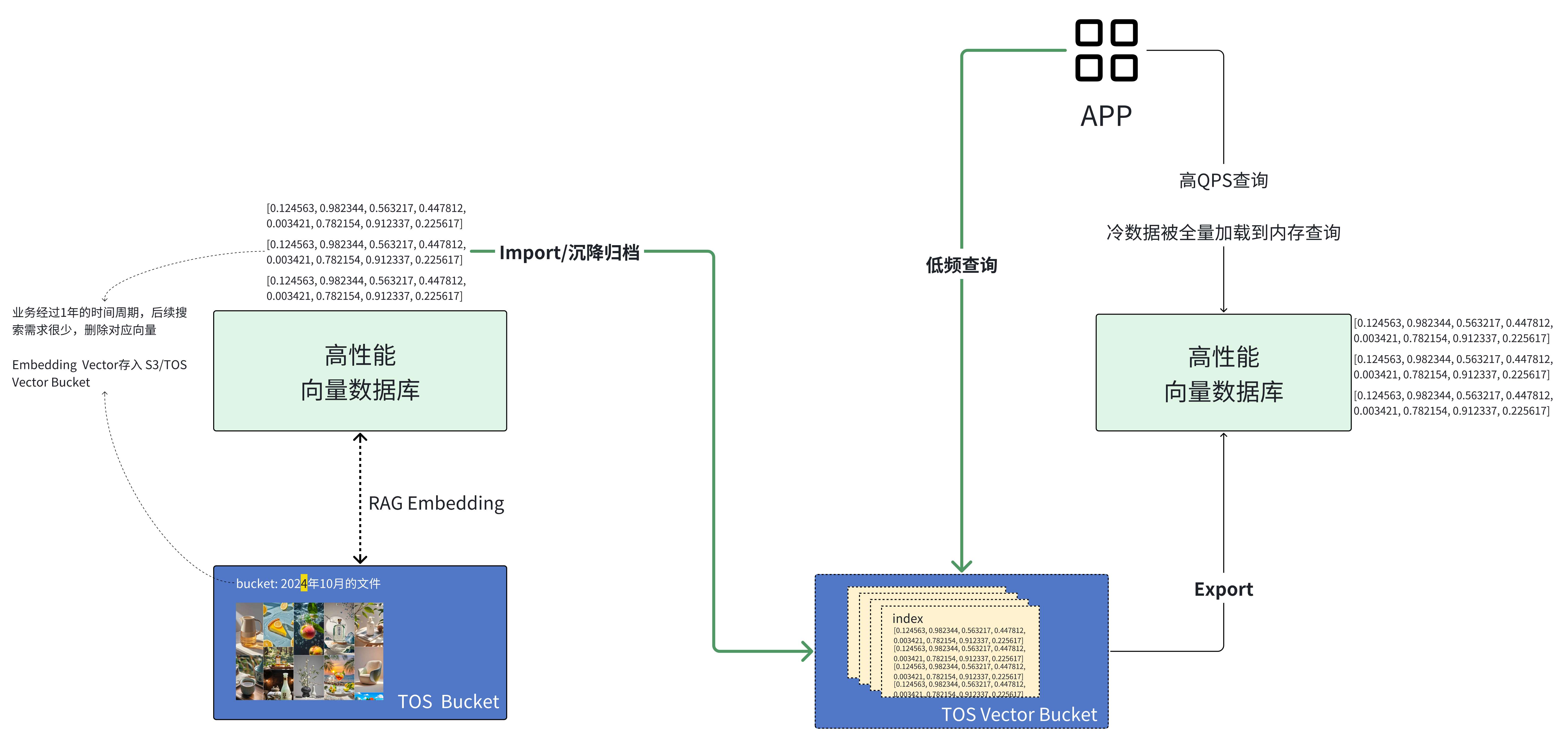
在实际应用中,数据的流动性对向量系统尤为关键。TOS Vectors 不仅支持从高性能向量数据库 Import 导入数据,也支持将数据 Export 导出到高性能数据库,实现冷热数据之间的灵活迁移。比如,在一个典型的业务场景中,用户可以借助 Vector Bucket 获得原生的向量语义能力:高频向量数据存放在云搜索服务或 VikingDB 中,用于实时查询;而历史数据则沉淀到 TOS Vectors,以更低的成本进行长期存储和低频检索。这样一来,既能保证系统在实时业务中保持高性能,随时调取沉淀在 TOS Vectors 中的低频数据,做到性能与成本的双重优化。
在构建智能应用时,分层搜索是提升性能与降低成本的关键手段。通过让向量数据库负责数据的 ingestion 管理,并与 TOS Vectors 结合,可以实现高低频数据的分层检索。常见有两种实现方式:其一,基于 TTL 策略,当向量数据超出设定的生命周期时,数据库会自动将其写入 Vector Bucket,并在查询时提供 混合搜索 能力,让新旧数据都能被统一检索;其二,直接在 Vector Bucket 上构建向量索引,形成低频层的 分层查询 通道。无论采用哪种方式,本质上都是在实时性与成本之间找到平衡,让企业既能享受毫秒级的在线检索,又能以极低成本沉淀长期向量记忆。
与火山 AI agent 结合
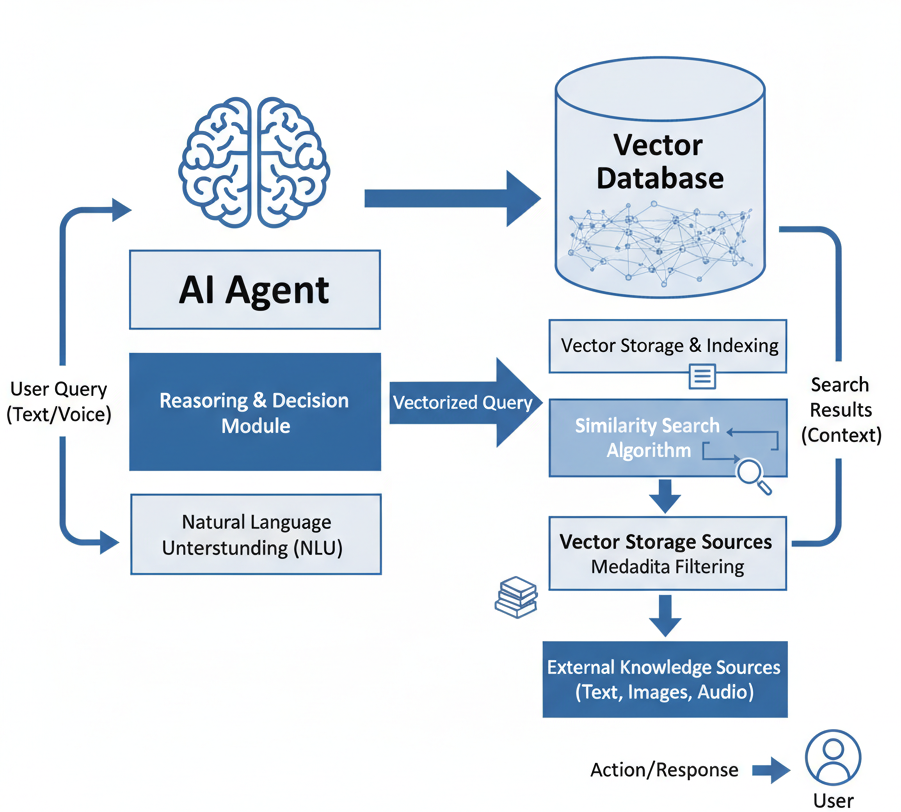
对于 Agent 应用而言,往往需要同时依赖对象存储与向量数据库才能顺利落地。然而,当 Agent 规模较小时,即便只是购买一台 1 core 的实例型产品,成本依然不容小觑。Vector Bucket 提出了全新的 Serverless 形态,让开发者可以基于 TOS 快速构建 Agent 应用:按需调用、灵活扩缩容,不必为闲置资源买单,从而显著降低了早期试错和规模扩展的成本。
对于常规交互型 Agent 而言,用户往往对响应延迟有较高要求,因此在设计长期记忆时,通常需要采用分层存储策略。一方面,将高频访问的记忆(如用户的核心偏好、近期的任务执行结果、对话交互记录)存放在向量数据库 中,以便在交互中实现毫秒级的高频检索;另一方面,将低频访问的记忆(如半年前的交互记录或历史执行结果)沉淀到 TOS Vector 中,允许秒级延迟,以此换取更低的总体存储成本和更广阔的长期记忆空间。这样的分层能力可以平衡 速度、成本与记忆深度,为 Agent 构建出既聪明又经济的长期记忆体系。
对于那些对反馈延迟不敏感的 Agent,比如需要处理复杂任务的场景,它们通常拥有较长的离线处理窗口,可以容忍一定的查询延迟。但与此同时,由于任务本身的复杂性,这类 Agent 往往需要在更大范围的企业向量数据中进行检索,并尽可能沉淀下更多的长期记忆。在这种情况下,TOS Vectors 就成为支撑这一需求的关键基础设施:它既能承载海量的语义向量存储,又能保证长期数据的可持续积累,让 Agent 在知识深度和记忆广度上不断进化,从而真正具备面向复杂任务的智能能力。
总结与展望
核心优势总结
TOS Vector Bucket 立足云原生技术底座,以架构领先性、自研先进向量索引、企业级可靠性、生态开放性四大核心优势,为企业数字化转型提供高弹性、低成本、可信赖的向量数据存储支撑:
-
通过存算分离、读写分离、去中心化的云原生分布式架构实现了企业级按需弹性计费,精准匹配业务动态伸缩需求,从底层架构上破解传统方案"重资产投入"痛点。
-
依托自研索引算法优化+智能分层存储技术,构建生产级数据处理能力,满足高并发、低延迟的严苛场景要求,支撑核心业务的稳定运行。
-
具备全链路企业级多租户能力,覆盖大型组织从权限治理到合规审计的全流程需求,保障数据安全与管理效率。
-
打造多云兼容+开源友好的开放生态,打破传统厂商技术绑定限制,支持企业跨云部署与开源工具兼容,实现数据基础设施的自主可控与生态协同。
通过技术与生态的双重壁垒,助力企业以更低成本、更高效率拥抱云原生时代的数据驱动创新,为数字化转型构建长期可持续的竞争优势。
未来规划
1. 深度绑定火山体系,构建智能数据流动闭环,实现更加智能分层的存储和调度
与火山 VectorDB 原生打通,依托火山生态的技术积淀,实现数据在多引擎间的智能分层存储与动态调度------让企业数据按需流动至最优引擎(如向量搜索场景适配 Milvus/OpenSearch/VikingDB、全文检索适配 TLS),从"静态存储"转向"动态价值释放",彻底解决传统方案"数据孤岛"与"引擎适配成本高"的痛点,为 AI、 Analytics 等场景提供更高效的数据底座支撑。
2. 混合搜索引擎增强,覆盖全场景检索需求
打造向量 + 全文 + 结构化的混合搜索架构,突破单一搜索模式的局限------既能满足 AI 应用的语义理解(向量搜索),也能支撑传统业务的精准匹配(全文/结构化搜索),覆盖从推荐系统、智能客服到日志分析的全场景需求,为企业核心业务提供"更高效、更全面、更精准"的搜索能力保障。
3. 生态体系完善
提供可视化控制台、CLI 工具及多语言 SDK,覆盖从开发、运维到监控的全流程需求,降低企业集成成本,提升团队效率;同时开源核心算法,吸引全球开发者参与迭代,形成"技术输出-社区反馈-产品优化"的正循环,既强化产品的技术先进性,也通过社区影响力扩大市场渗透力。