内核模块
模块最大的好处是可以动态扩展应用程序的功能而无须重新编译链接生成新的应用程序镜像,在微软的Windows系统上动态链接库DLL(Dynamic Link Library),Linux系统上的共享库so(shared object)文件的形式都属于广义上的模块。内核模块可以在linux内核运行期间动态扩展内核功能而无须重新启动系统,更无须为这些新增的功能重新编译一个新的系统内核镜像。内核模块的这个特性为内核开发者提供了极大的便利,因为编译一个新内核并重新启动将花费大量的时间。这本质上是解耦和开闭原则的实践。insmod就是向系统动态加载内核模块的命令。
powershell
insmod demodev.ko内核模块文件形式
以内核模块形式存在的驱动程序的数据组织形式是ELF (Executable and Linkable Format),内核模块是一种普通的可重定位目标文件。用file命令查看demodev.ko文件,可以得到类似如下的输出:
powershell
file demodev.ko
demodev.ko: ELF 32-bit LSB relocatable, Intel 80386, version 1 (SYSV), not strippedELF是Linux下非常重要的一种文件格式,常见的可执行程序都是以ELF的形式存在。在这里我们结合Linux源代码中定义的ELF相关数据结构(基于32位体系架构),给出ELF格式的一个结构图,如图所示:
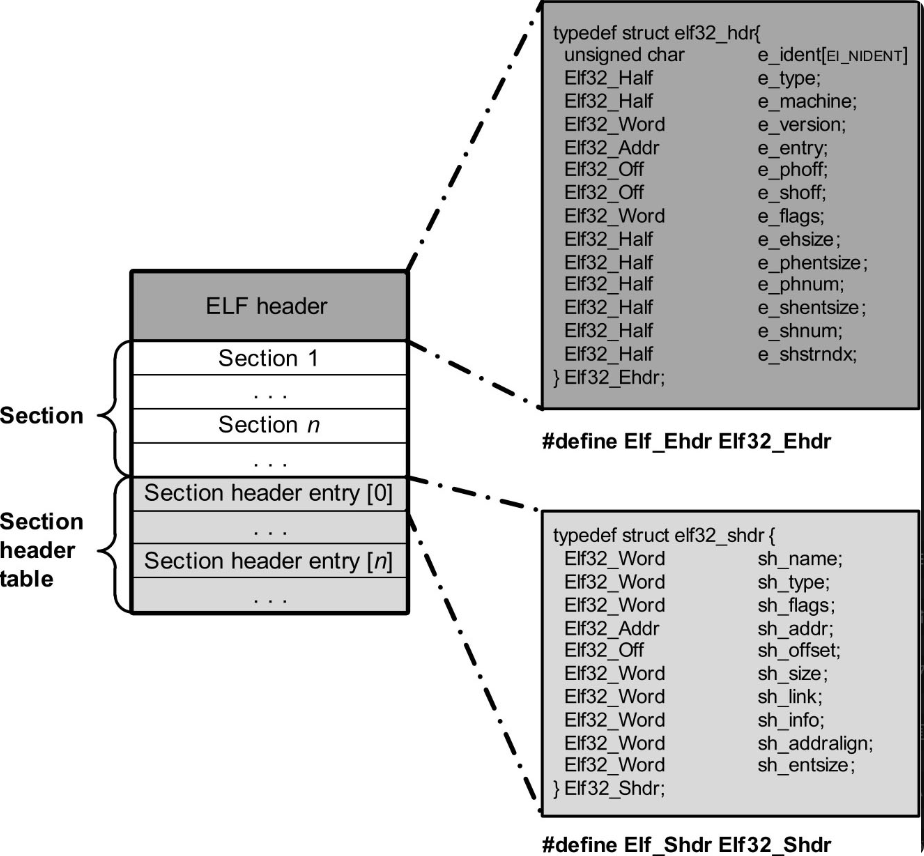
静态的ELF文件视图总体上可分为三大部分:头部的ELF header,中间的Section和尾部的Section header table。在Linux环境下读取ELF文件信息的工具---readelf。
ELFheader部分大小是52字节,位于文件头部。对于驱动模块文件而言,其中一些比较重要的数据成员如下:e_type表明文件类型,对于驱动模块,这个值是1,也就是说驱动模块是一个可定位的ELF文件(relocatable file)。e_shoff表明Section header table部分在文件中的偏移量。e_shentsize表明Section header table部分中每一个entry的大小(以字节计)。e_shnum表明Section header table中有多少个entry。因此,Section header table的大小便为e_shentsize×e_shnum个字节。e_shstrndx与Section header entry中的sh_name一起用来指明对应的section的name。
Section部分ELF文件的主体,位于文件视图中间部分的一个连续区域中。但是当模块被内核加载时,会根据各自属性被重新分配到新的内存区域(有些section也可能只是起辅助作用,因而在运行时并不占用实际的内存空间)。
Section header table部分该部分位于文件视图的末尾,由若干个(具体个数由ELF header中的e_shnum变量指定) Section header entry组成,每个entry具有同样的数据结构类型。对于设备驱动模块而言,一些比较重要的数据成员如下:sh_addr这个值用来表示该entry所对应的section在内存中的实际地址。在静态的文件视图中,这个值为0,当模块被内核加载时,加载器会用该section在内存中的实际地址来改写sh_addr (如果section不占用内存空间,该值为0)。sh_offset表明对应的section在文件视图中的偏移量。sh_size表明对应的section在文件视图中的大小(以字节计)。类型为SHT_NOBITS的section例外,这种section在文件视图中不占有空间。sh_entsize主要用于由固定数量entry组成的表所构成的section,如符号表,此种情况下用来表示表中entry的大小。
EXPORT_SYMBOL的内核实现
源码中充斥着像EXPORT_SYMBOL这样的宏,它用来向外界导出一个符号。如果没有独立存在的内核模块,作为单一的Linux内核镜像,导出符号就失去了意义。对于静态编译链接而成的内核镜像而言,所有的符号引用都将在静态链接阶段完成。然而内核模块不可避免地要使用到内核提供的功能(以调用内核函数的形式发生),作为独立编译链接的内核模块,必须要解决这种静态链接无法完成的符号引用问题(在内核模块所在的ELF文件中,这种引用被称为"未解决的引用")。处理"未解决引用"问题的本质是在模块加载期间找到当前"未解决的引用"符号在内存中的实际目标地址。内核和内核模块通过符号表的形式向外部世界导出符号的相关信息,这种导出符号的方式在代码层面以EXPORT_SYMBOL宏定义的形式存在。从全局来看,EXPORT_SYMBOL这类宏功能的完整实现需要经过三个部分来达成:EXPORT_SYMBOL宏定义部分,链接脚本链接器部分和使用导出符号部分。
powershell
<include/linux/module.h>
#define__EXPORT_SYMBOL(sym,sec) \
extern typeof(sym)sym; \
__CRC_SYMBOL(sym,sec) \
static const char__kstrtab_##sym[] \
__attribute__((section("__ksymtab_strings"),aligned(1)))\
=MODULE_SYMBOL_PREFIX#sym; \
static const struct kernel_symbol__ksymtab_##sym \
__used \
__attribute__((section("__ksymtab"sec),unused)) \
={(unsigned long)&sym,__kstrtab_##sym}
#define EXPORT_SYMBOL(sym) \
__EXPORT_SYMBOL(sym,"")
#define EXPORT_SYMBOL_GPL(sym) \
__EXPORT_SYMBOL(sym,"_gpl")
#define EXPORT_SYMBOL_GPL_FUTURE(sym) \
__EXPORT_SYMBOL(sym,"_gpl_future")从源代码可以看出,每个EXPORT_SYMBOL宏实际上定义了两个变量:
powershell
static const char *__kstrtab_my_exp_function = "my_exp_function";//tab是table的缩写
static const struct kernel_symbol __ksymtab_my_exp_function =
{ (unsigned long)& my_exp_function, __kstrtab_my_exp_function };第一个变量是char型指针,用来表示导出的符号名称;第二个变量类型是struct kernel_symbol数据结构,用来表示一个内核符号的实例,struct kernel_symbol的定义为:
powershell
<include/linux/module.h>
struct kernel_symbol
{
unsigned long value;
const char*name;
};value是该符号在内存中的地址,name是符号名。所以,用EXPORT_SYMBOL(my_exp_function)来导出符号"my_exp_function",实际上是要通过struct kernel_symbol的一个对象告诉外部世界关于这个符号的两点信息:符号名称和地址。由EXPORT_SYMBOL等宏导出的符号,与一般的变量定义并没有实质性的差异,唯一的不同点在于它们被放在了特定的section中。
上面的__kstrtab_my_exp_function(symbol的名称)会被放置在一个名为"__ksymtab_strings"的section中,__ksymtab_my_exp_function(symbol实例)会放置在一个名为"__ksymtab"的section中(对于EXPORT_SYMBOL_GPL和EXPORT_SYMBOL_GPL_FUTURE而言,其struct kernel_symbol实例所在的section名称则分别为"__ksymtab_gpl"和"__ksymtab_gpl_future")。对这些section的使用需要经过一个中间环节,即链接脚本与链接器部分。链接脚本告诉链接器把所有目标文件中的名为"__ksymtab"的section放置在最终内核(或者是内核模块)镜像文件的名为"__ksymtab"的section中(对于目标文件中的名为"__ksymtab_gpl"、"__ksymtab_gpl_future"、"__kcrctab"、"__kcrctab_gpl"和"__kcrctab_gpl_future"的section都同样处理),看看下面的这个具体的链接脚本的例子就很清楚了。
powershell
<arch/x86/kernel/vmlinux.lds>
__ksymtab : AT(ADDR(__ksymtab) - 0xC0000000)
{ __start___ksymtab = .; *(__ksymtab) __stop___ksymtab = .; }
__ksymtab_gpl : AT(ADDR(__ksymtab_gpl) - 0xC0000000)
{ __start___ksymtab_gpl = .; *(__ksymtab_gpl) __stop___ksymtab_gpl = .; }
__ksymtab_gpl_future : AT(ADDR(__ksymtab_gpl_future) - 0xC0000000)
{
__start___ksymtab_gpl_future = .;
*(__ksymtab_gpl_future) __stop___ksymtab_gpl_future = .;
}
__kcrctab : AT(ADDR(__kcrctab) - 0xC0000000)
{ __start___kcrctab = .; *(__kcrctab) __stop___kcrctab = .; }
__kcrctab_gpl : AT(ADDR(__kcrctab_gpl) - 0xC0000000)
{ __start___kcrctab_gpl = .; *(__kcrctab_gpl) __stop___kcrctab_gpl = .; }
__kcrctab_gpl_future : AT(ADDR(__kcrctab_gpl_future) - 0xC0000000)
{ __start___kcrctab_gpl_future = .; *(__kcrctab_gpl_future) __stop___kcrctab_gpl_future = .; }
__ksymtab_strings : AT(ADDR(__ksymtab_strings) - 0xC0000000)
{ *(__ksymtab_strings) }这里之所以要把所有向外界导出的符号统一放到一个特殊的section里面,是为了在加载其他模块时用来处理那些"未解决的引用"符号。注意这里由链接脚本定义的几个变量__start___ksymtab、__stop___ksymtab、__start___ksymtab_gpl、__stop___ksymtab_gpl、__start___ksymtab_gpl_future、__stop___ksymtab_gpl_future,它们会在对内核或者是某一内核模块的导出符号表进行查找时用到。内核源码中为使用这些链接器产生的变量作了如下的声明:
powershell
<kernel/module.c>
extern const struct kernel_symbol __start___ksymtab[];
extern const struct kernel_symbol __stop___ksymtab[];
extern const struct kernel_symbol __start___ksymtab_gpl[];
extern const struct kernel_symbol __stop___ksymtab_gpl[];
extern const struct kernel_symbol __start___ksymtab_gpl_future[];
extern const struct kernel_symbol __stop___ksymtab_gpl_future[];
extern const unsigned long __start___kcrctab[];
extern const unsigned long __start___kcrctab_gpl[];
extern const unsigned long __start___kcrctab_gpl_future[];内核代码便可以直接使用这些变量而不会引起编译错误。
还是我最喜欢的老环节,总结一下:
1.内核驱动是通过模块的形式加载到内核。在软件开发中有很多相似的过程,比如linux用户态的so,windows的ddl。
2.模块的后缀是.ko,文件格式是ELF。
3.模块向其他模块或者内核导出符号是通过EXPORT_SYMBOL宏实现。
4.EXPORT_SYMBOL背后是由内核源码/链接脚本实现。
再深入思考一点,我们能得到什么,或者说更加抽象的经验是什么:
1.解耦。将驱动功能与内核的基础功能分开。内核基础功能稳定性好,而驱动则是经常变化。
2.需要通过框架实现解耦后的部件间相互依赖的问题。
忽然在脑海里想到那么几个问题:
在我们的实际开发中会遇到驱动的bug导致整个内核panic重启的情况。这种问题是否可以得到优化呢?做到类似用户态的进程隔离。驱动死了内核可以不用收到影响。
我们总会考虑用户态进程的loading。驱动的loading是否有衡量方法。但是一般驱动都是做简单业务逻辑,不会涉及复杂的算法产生巨大的CPU开销。这个问题的必要性不是那么高。