目录
[3.1.DELETE 删除](#3.1.DELETE 删除)
[3.2.REMOVE 删除](#3.2.REMOVE 删除)
[4.1.SET (添加属性)](#4.1.SET (添加属性))
[4.2.NULL 值](#4.2.NULL 值)
[4.3.ORDER BY (排序)](#4.3.ORDER BY (排序))
[4.4.LIMIT 和 SKIP (限制)](#4.4.LIMIT 和 SKIP (限制))
1.节点语法
Cypher 采用一对圆括号来表示节点。如:(), (foo)。下面是一些常见的节点表示法:
bash
// 表示一个节点,但是没有属性
()
// 节点变量为 matrix
(matrix)
// 节点标签为 Movie 的节点
(:Movie)
// 节点变量为 matrix,节点标签为 Movie 的节点
(matrix:Movie)
// 节点变量为 matrix,节点标签为 Movie,节点属性 title 为 ET·Go 的节点
(matrix:Movie {title: "ET·Go"})
// 节点变量为 matrix,节点标签为 Movie,节点属性 title 为 Spider Man ,released 为 1997 的节点
(matrix:Movie {title: "Spider Man", released: 1997})1.1.CREATE--创建节点
create 语句是创建模型语句用来创建数据模型。
bash
// 创建简单节点
create (n)
// 创建多个节点
create (n),(m)
// 创建带标签和属性的节点并返回节点
create (n:person {name:"如来"}) return n
1.2.MATCH--查询节点
Neo4j CQL MATCH 命令用于
-
从数据库获取有关节点和属性的数据;
-
从数据库获取有关节点,关系和属性的数据。
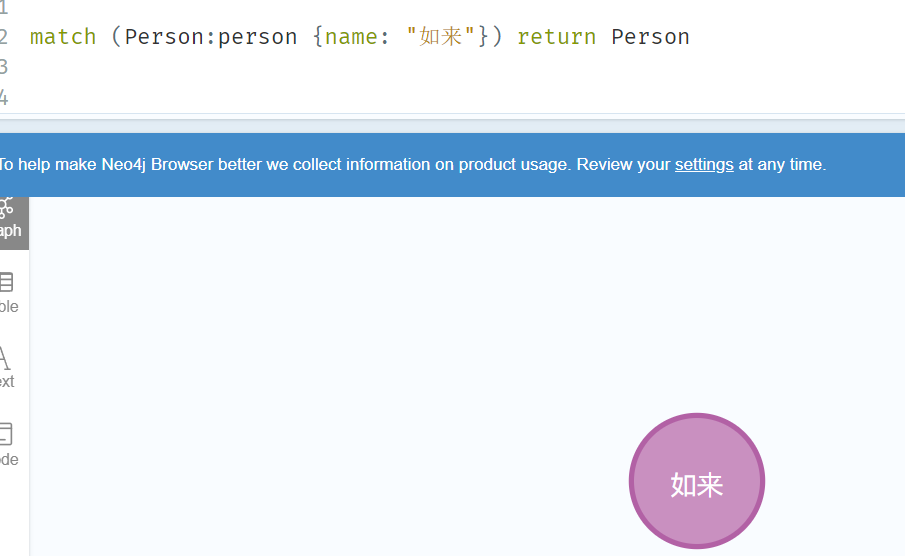
match (Person:person {name: "如来"}) return Person
Person:变量(任意)
person:标签
{}:属性
():节点
1.3.RETURN--返回节点
Neo4j CQL RETURN 子句用于
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
注意: RETURN、MATCH 两个需要搭配使用。
1.4.WHERE--过滤节点
像 SQL 一样,Neo4j CQL 在 CQL MATCH 命令中提供了 WHERE 子句来过滤 MATCH 查询的结果。
sql
MATCH (n:person) where n.name='孙悟空' or n.name='猪八戒' RETURN n 2.关系语法
Cypher 使用一对短横线(即"--")表示:一个无方向关系。有方向的关系在其中一端加上一个箭头(即"<--"或"-->")。方括号表达式 [...] 可用于添加关系信息。里面可以包含变量、属性和或者类型信息。关系的常见表达方式如下:
sql
// 无方向关系
--
// 有方向关系,指向一个节点
-->
// 有方向的关系,关系变量为 reole
-[role]->
// 有方向的关系,关系标签为 ACTED_IN
-[:ACTED_IN]->
// 有方向的关系,关系标签为 ACTED_IN,关系变量为 role
-[role:ACTED_IN]->
// 有方向的关系,关系标签为 ACTED_IN,关系变量为 role,属性 roles 的值为 Neo
-[role:ACTED_IN {roles: ["Neo"]}]->2.1.创建关系
Neo4j 图数据库遵循属性图模型来存储和管理其数据。 根据属性图模型,关系应该是定向的。 否则,Neo4j 将抛出一个错误消息。 基于方向性,Neo4j 关系被分为两种主要类型。
- 单向关系
- 双向关系
使用新节点创建关系
sql
CREATE (n:person {name:'杨戬'})-[r:师傅]->(m:person {name:'玉鼎真人'}) return type(r)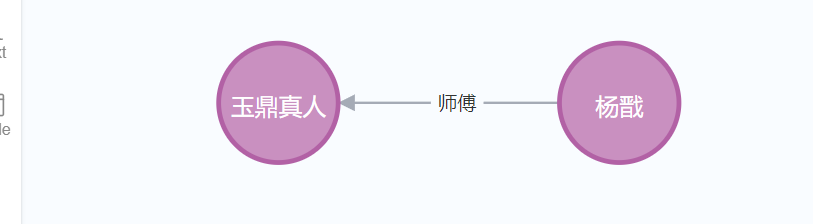
sql
create (n:person {name:'沙僧'}),(m:person{name:'唐僧'}) create (n)-[r:`师傅`{relation:'师傅'}]->(m) return r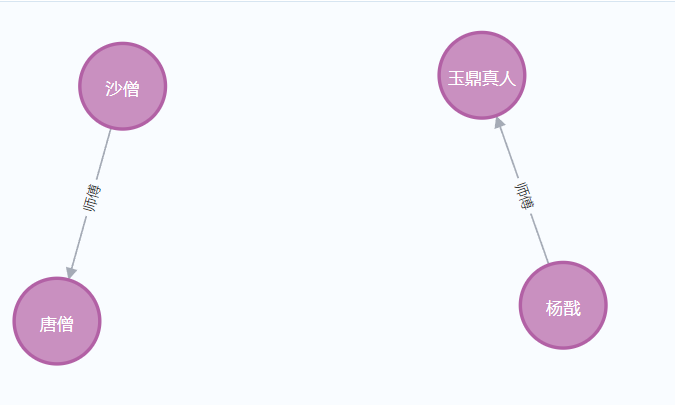
2.2.查询关系
sql
MATCH (a)-[r:师傅]->(b)
RETURN a, r, b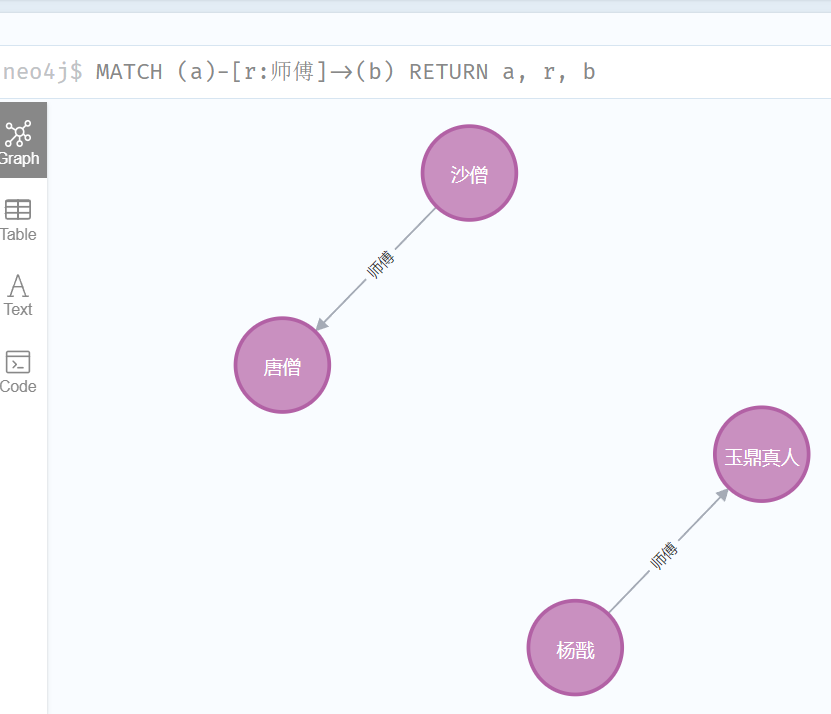
3.删除语法
3.1.DELETE 删除
-
删除节点;
-
删除节点及相关节点和关系。
sql
# 删除节点(前提:节点不存在关系)
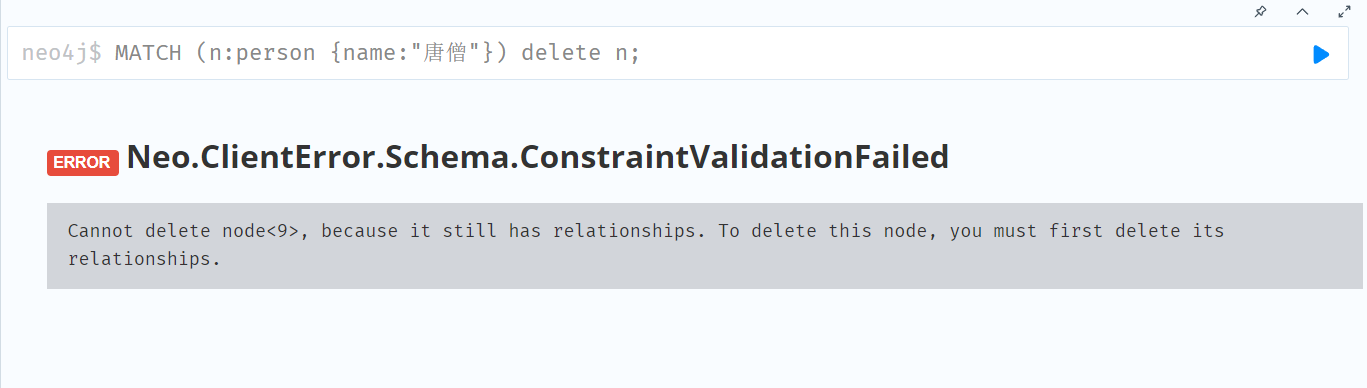
MATCH (n:person {name:"白龙马"}) delete n;
# 删除关系
MATCH (n:person {name:"沙僧"})<-[r]-(m) delete r return type(r);注意:删除结点的前提是节点没有关系。
3.2.REMOVE 删除
有时基于客户端要求,我们需要向现有节点或关系添加或删除属性。我们使用Neo4j CQL REMOVE 子句来删除节点或关系的现有属性。
-
删除节点或关系的标签;
-
删除节点或关系的属性。
sql
// 删除属性
MATCH (n:role {name:"fox"}) remove n.age return n;
// 创建节点(两个标签)
CREATE (m:role:person {name:"cat233"})
// 删除标签
MATCH (m:role:person {name:"cat233"}) remove m:person return m4.功能补充
4.1.SET (添加属性)
有时,根据我们的客户端要求,我们需要向现有节点或关系添加新属性。要做到这一点,Neo4j CQL 提供了一个SET子句。
向现有节点或关系添加新属性;
添加或更新属性值。 MATCH (n:role {name:"cat"}) set n.age=32 return n
4.2.NULL 值
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
sql
// 查询是否为空
match (n:`西游`) where n.label is null return id(n),n.name,n.tail,n.label4.3.ORDER BY (排序)
Neo4j CQL 在 MATCH 命令中提供了 ORDER BY 子句,对 MATCH 查询返回的结果进行排序。 我们可以按升序或降序对行进行排序。默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用 DESC 子句。
sql
// 按 id 进行降序
MATCH (n:`西游`) RETURN id(n),n.name order by id(n) desc4.4.LIMIT 和 SKIP (限制)
Neo4j CQL 已提供 LIMIT 子句和 SKIP 来过滤或限制查询返回的行数。 LIMIT 返回前几行,SKIP 忽略前几行。
sql
// 前两行
MATCH (n:`西游`) RETURN n LIMIT 2
// 忽略前两行
MATCH (n:person) RETURN n SKIP 2