在自然语言处理领域,预训练语言模型(如BERT、GPT、T5)已成为基础设施。但如何让这些"通才"模型蜕变为特定任务的"专家"?微调策略正是关键所在。本文将深入剖析七种核心微调技术及其演进逻辑。
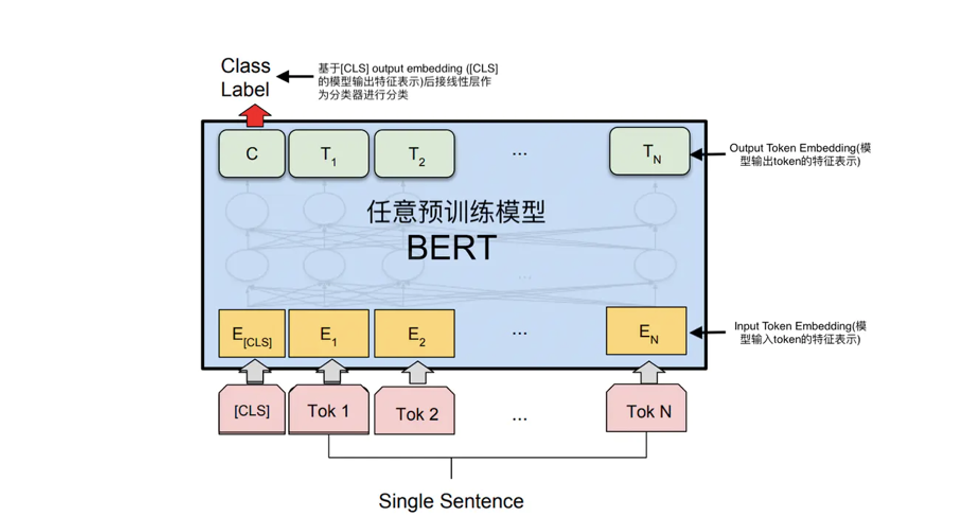
一、基础概念:为什么需要微调?
预训练模型在海量语料上学习了通用语言表征(词义、语法、浅层语义),但其知识是领域无关的。例如:
-
医学文本中的"阳性"与日常用语含义不同
-
金融领域的"多头"非指动物头部
-
法律文本的特殊句式结构
微调的本质:在预训练知识基础上,通过特定领域数据调整模型参数,使其适应下游任务,如文本分类、实体识别、问答系统等。
二、经典策略:全参数微调(Full Fine-tuning)
工作原理:解冻整个模型,在任务数据上更新所有权重
# PyTorch典型实现
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
optimizer = AdamW(model.parameters(), lr=5e-5)
for batch in dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()优势:
-
充分利用模型容量
-
适合大数据场景(>10k标注样本)
缺陷:
-
计算成本高(需存储所有梯度)
-
灾难性遗忘风险(丢失通用知识)
-
存储开销大(每个任务需独立模型副本)
研究显示:在GLUE基准上,全微调比特征提取(冻结编码器)平均高3.2个点(来源:Devlin et al., 2019)
三、参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
1. Adapter模块
设计:在Transformer层间插入小型全连接网络

-
参数占比:仅原模型的0.5%-8%
-
效果:在XTREME多语任务上可达全微调98%性能(Pfeiffer et al., 2020)
2. LoRA(Low-Rank Adaptation)
数学原理:权重更新ΔW=BA,其中B∈ℝ^{d×r}, A∈ℝ^{r×k} (r≪min(d,k))
# LoRA实现核心
class LoRALayer(nn.Module):
def __init__(self, r=8):
self.lora_A = nn.Parameter(torch.randn(input_dim, r))
self.lora_B = nn.Parameter(torch.zeros(r, output_dim))
def forward(x):
return x @ (W_original + self.lora_A @ self.lora_B)-
优势:无推理延迟
-
典型应用:ChatGPT的轻量适配
3. Prefix-Tuning
机制:在输入前添加可学习向量作为"软提示"
[P1][P2]...[Pk][原始输入] → [LM]-
参数节约:0.1%即可控制生成方向
-
实验:在表格到文本生成任务上超越直接微调(Li & Liang, 2021)
四、提示微调(Prompt-based Fine-tuning)
1. 人工模板(Manual Prompt)
情感分析示例:
输入:"这部电影太精彩了!"
模板:"整体而言,这是一部[MASK]的电影。"
模型预测:MASK位置→"精彩"(positive)2. P-Tuning v2
创新点:用双向LSTM生成连续提示
prompt_embeddings = LSTM(torch.randn(prompt_length, hidden_dim))
inputs_embeds = torch.cat([prompt_embeddings, token_embeddings])- 效果:在SuperGLUE上超越离散提示12.7%(Liu et al., 2021)
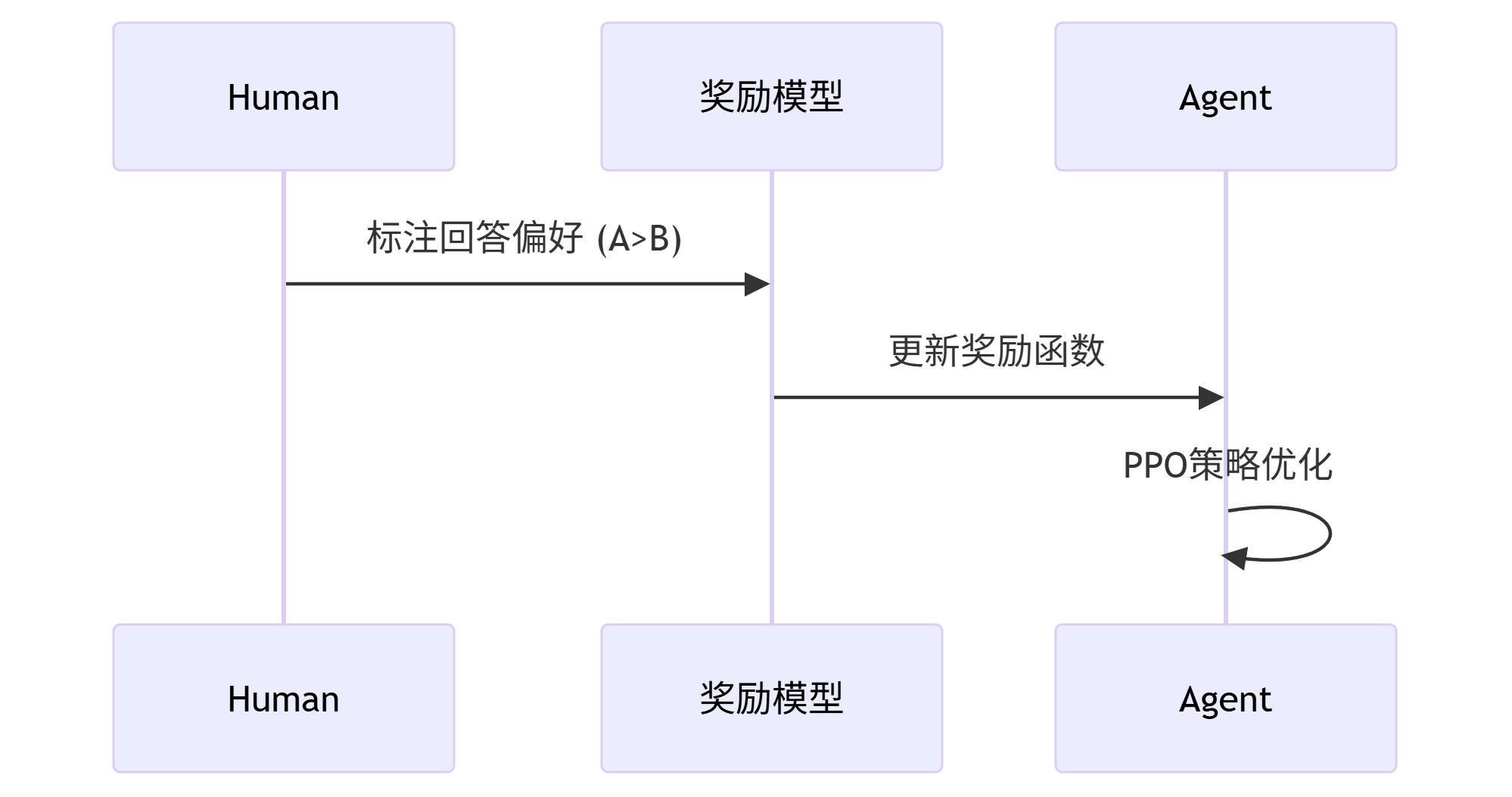
五、强化学习微调(RLHF)
三阶段流程:
-
监督微调(SFT)
-
奖励模型训练(RM):人类标注偏好数据
-
PPO强化学习:优化策略满足RM
典型应用:
-
ChatGPT的对话对齐
-
Claude的安全响应机制
六、策略选型指南
| 策略 | 适用场景 | 数据需求 | 计算成本 | 典型任务 |
|---|---|---|---|---|
| 全微调 | 大数据/高性能需求 | >10k样本 | ★★★★★ | 文本分类、NER |
| Adapter | 多任务部署 | 1k-10k样本 | ★★☆ | 跨语言理解 |
| LoRA | 大模型轻量化适配 | 几百样本 | ★☆☆ | GPT对话微调 |
| P-Tuning | 少样本学习 | <100样本 | ★★☆ | 关系抽取 |
| RLHF | 对齐人类偏好 | 偏好数据 | ★★★★ | 对话系统 |
七、前沿方向探索
-
模块化组合(MOD-Squad)
-
将Adapter视为乐高积木
-
动态组合适配器处理多任务
-
-
黑箱优化(Black-Box Tuning)
-
仅通过API访问模型
-
梯度估计优化提示(如ZO-PGD)
-
-
神经架构搜索(NAS for PEFT)
-
自动搜索Adapter结构
-
Google的AutoPEFT方案提升12%效率
-
"未来的微调将像给模型'注射疫苗'------用最小干预激发特定免疫力" ------ 斯坦福NLP组负责人Christopher Manning
结语
从全参数微调到RLHF,微调策略的演进本质是效率与性能的博弈。在选择策略时需考虑:
-
数据规模与质量
-
硬件限制(显存/算力)
-
任务复杂度
-
部署要求(模型体积/延迟)