在语音合成与语音编辑领域,一个长期存在的挑战是如何在修改语音内容的同时,保持原始语音的自然性、连贯性和说话人特征。近日,一款名为 PlayDiffusion 的新型 AI 语音修复模型应运而生,成功实现了这一目标。
PlayDiffusion 是一个具备细粒度语音编辑能力 的语音修复模型,能够在不破坏语音整体结构的前提下,实现对特定词语或句子片段的精准修改。更重要的是,修改后的语音能够无缝衔接原语音 ,听感自然流畅,几乎无法察觉修改痕迹。
核心功能亮点
1、精准语音修改
支持对语音中单个词或短语进行修改,例如将一句话中的"小明"替换为"小红",而不影响其余部分的语音风格和语调。
2、上下文保留机制
在编辑过程中,系统会保留语音的上下文信息,确保修改区域与周围语音之间实现平滑过渡。
3、说话人特征一致性
修改后的语音在音色、语速、语调等方面与原始语音高度一致,避免了传统语音编辑中常见的"换声"问题。
4、广泛适用性
特别适用于需要频繁修改语音内容的场景,如语音播报、有声读物制作、广告配音、视频解说 等领域。
工作原理详解
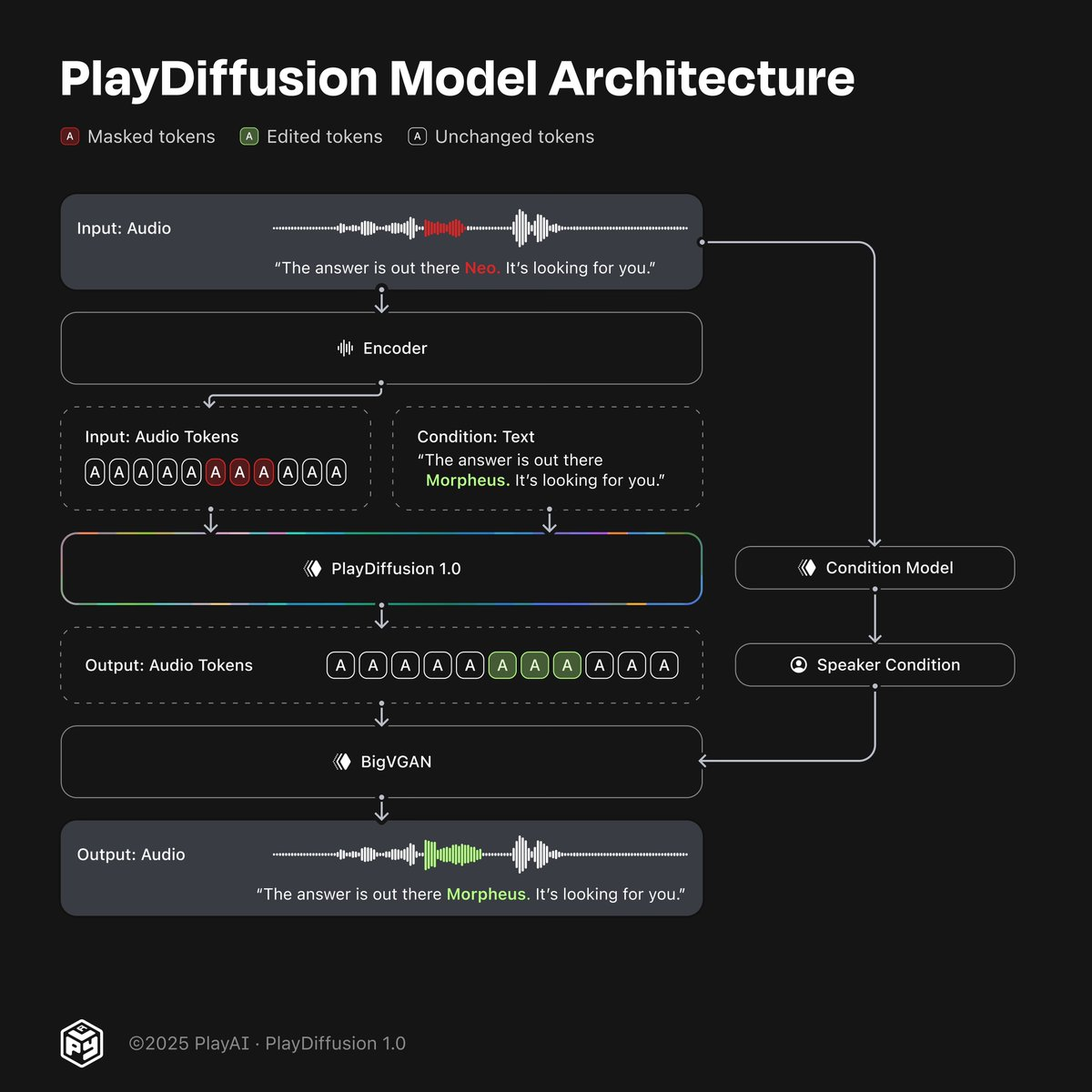
PlayDiffusion 的核心在于其基于扩散模型的非自回归编辑架构 ,具体流程如下:
1、音频编码
首先,输入的语音波形被编码为一个离散空间中的 token 序列,形成一种更紧凑的表示形式。这一过程既适用于真实录制的语音,也适用于由 Text-to-Speech(TTS)模型生成的语音。
2、局部遮罩处理
当用户希望修改某段语音时,系统会自动遮盖该区域的音频 token,准备进行编辑。
3、条件扩散去噪
一个基于更新文本的条件扩散模型 被用于对遮罩区域进行去噪处理。在这个过程中,系统利用周围的上下文信息来生成新的语音 token,从而保证语音的连贯性和说话人特征的一致性。
4、语音解码输出
编辑完成的 token 序列通过 BigVGAN 解码器转换回高质量的语音波形,最终输出编辑后的语音。
借助非自回归扩散模型 的强大建模能力,PlayDiffusion 能够在语音编辑边界处保持极佳的上下文一致性,显著提升了语音编辑的质量和可控性。
PlayDiffusion 的推出标志着语音编辑技术迈入了一个新阶段------从"只能重新录音"到"精细编辑、无缝融合"。它不仅是语音处理领域的一项重大突破,更为 AI 驱动的内容创作开辟了全新的可能性。