一、TF-IDF
TF的概念:指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。
词频(TF) =某个词在文章中的出现次数 **/**文章的总词数
IDF的概念:逆向文档频率。IDF的主要思想是:如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
逆文档频率(IDF)=log(语料库的文档总数 / (包含该词的文档数+1))
TF一IDF=词频(TF)×逆文档频率(IDF)
代码实现:
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
data=open("task2_1.txt",'r')
x=data.readlines()
vt=TfidfVectorizer()
tfidf=vt.fit_transform(x)
print(tfidf)
wordlist=vt.get_feature_names()
print(wordlist)
df=pd.DataFrame(tfidf.T.todense(),index=wordlist)
print(df)
for i in range(len(x)):
featurelist=df.iloc[:,i].to_list()
resdict={}
for j in range(0,len(wordlist)):
resdict[wordlist[j]]=featurelist[j]
resdict=sorted(resdict.items(),key=lambda x:x[1],reverse=True)
print(resdict)1.通过from sklearn.feature_extraction.text import TfidfVectorizer导入TF-IDF的方法
2.task2_1.txt的内容中可以将每一行的英文看作是一篇文章,求每一个词在其中的TF-IDF
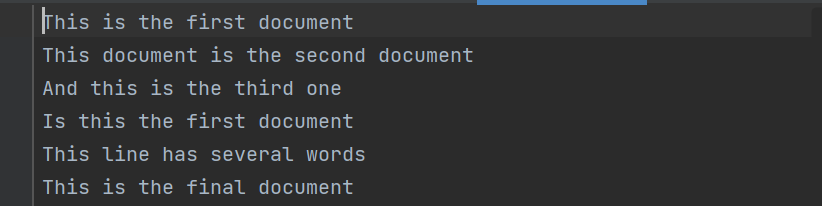
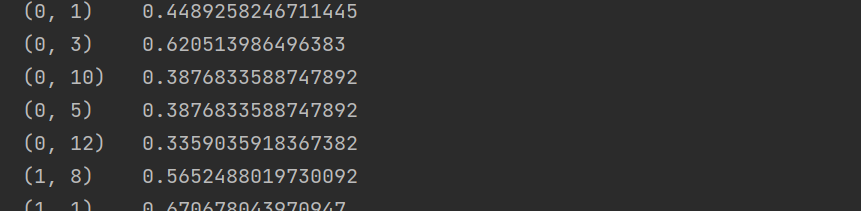
3.通过vt=TfidfVectorizer()初始化一个vt的对象,通过vt.fit_transform(x)方法求出单词在每一行语句中的tf-idf
4.通过调用vt.get_feature_names()方法获取经过 TF-IDF 拟合后生成的词汇表(所有不重复的特征词)
二、红楼梦小说关键词提取(具体案例)
1.将红楼梦小说的内容进行分卷,将每一回的内容存取到txt文件中,以每一个回的名称来命名。
python
import os
import jieba
import pandas as pd
file=open(r'.\红楼梦\红楼梦.txt',encoding="utf-8")
flag=0
juan_file=open(r'.\红楼梦\开头.txt','w',encoding="utf-8")
for line in file:
if '卷 第' in line:
juan_name=line.strip()+'.txt'
path=os.path.join(r'.\红楼梦\分卷',juan_name)
if flag==0:
juan_file=open(path,'w',encoding="utf-8")
flag=1
else:
juan_file.close()
juan_file=open(path,'w',encoding="utf-8")
continue
if '手机电子书·大学生小说网' not in line:
juan_file.write(line)
juan_file.close()
file.close()通过每一回的名称都有'卷 第'这个字符串来定位切割,通过juan_name=line.strip()+'.txt'来命名文件
path=os.path.join(r'.\红楼梦\分卷',juan_name)来得到每个文件地址
2.将每一回的内容提取出来放到h_content中
python
for roots,directories,files in os.walk(r'.\红楼梦\分卷'):
for file in files:
# 仅处理txt文件(避免遍历其他无关文件)
if file.endswith('.txt'):
# 拼接文件完整路径
file_path = os.path.join(roots, file)
h_root.append(file_path) # 保存文件路径
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
h_content.append(content) # 保存文件内容3.使用jieba库加载红楼梦专属词库解决专有名词分词错误,使用jieba库的cut方法进行分词,用停用词StopwordsCN.txt对分词后的词库进行过滤。
python
jieba.load_userdict(r'.\红楼梦\红楼梦词库.txt')
stopwords = pd.read_table(
r'.\红楼梦\StopwordsCN.txt',
encoding="utf-8", # 若报错可改为encoding='gbk
)
file_to_jieba=open(r'.\红楼梦\分词汇总.txt','w',encoding="utf-8")
for index,row in my_set.iterrows():
#iterrows遍历行数据
juan_ci=''#空的字符串,处理后的单词依次添加到juanci后面
# filePath = row['filePath']
fileContent =row['file_content']
segs=jieba.cut(fileContent)
#对文本内容进行分词,返回一个可遍历的迭代器
for seg in segs:
#遍历每一个词
if seg not in stopwords.stopword.values and len(seg.strip())>0:#剔除停用词和字符为o的内容
juan_ci += seg+' '
#juan_ci=juan_ci+'电子书
file_to_jieba.write(juan_ci+'\n')
file_to_jieba.close()4.最后使用tf_idf的方法对得到的内容求出每个词的tf-idf
python
from sklearn.feature_extraction.text import TfidfVectorizer
data=open(r".\红楼梦\分词汇总.txt",'r',encoding="utf-8")
x=data.readlines()
vt=TfidfVectorizer()
tfidf=vt.fit_transform(x)
# print(tfidf)
wordlist=vt.get_feature_names()