一、SkyWalking概述
SkyWalking是一款开源的APM(应用性能监控)系统,专门为微服务、云原生和容器化架构设计。它由Apache软件基金会孵化并毕业,已成为分布式系统监控领域的明星项目。
核心特性
- 分布式追踪:跨服务调用链路的完整追踪
- 服务拓扑分析:自动绘制服务间依赖关系图
- 性能指标监控:JVM、CLR、线程池等运行时指标
- 告警系统:基于规则的实时告警机制
- 日志集成:与分布式日志系统无缝对接
二、整体架构设计
SkyWalking采用模块化设计,主要分为以下几个核心组件:
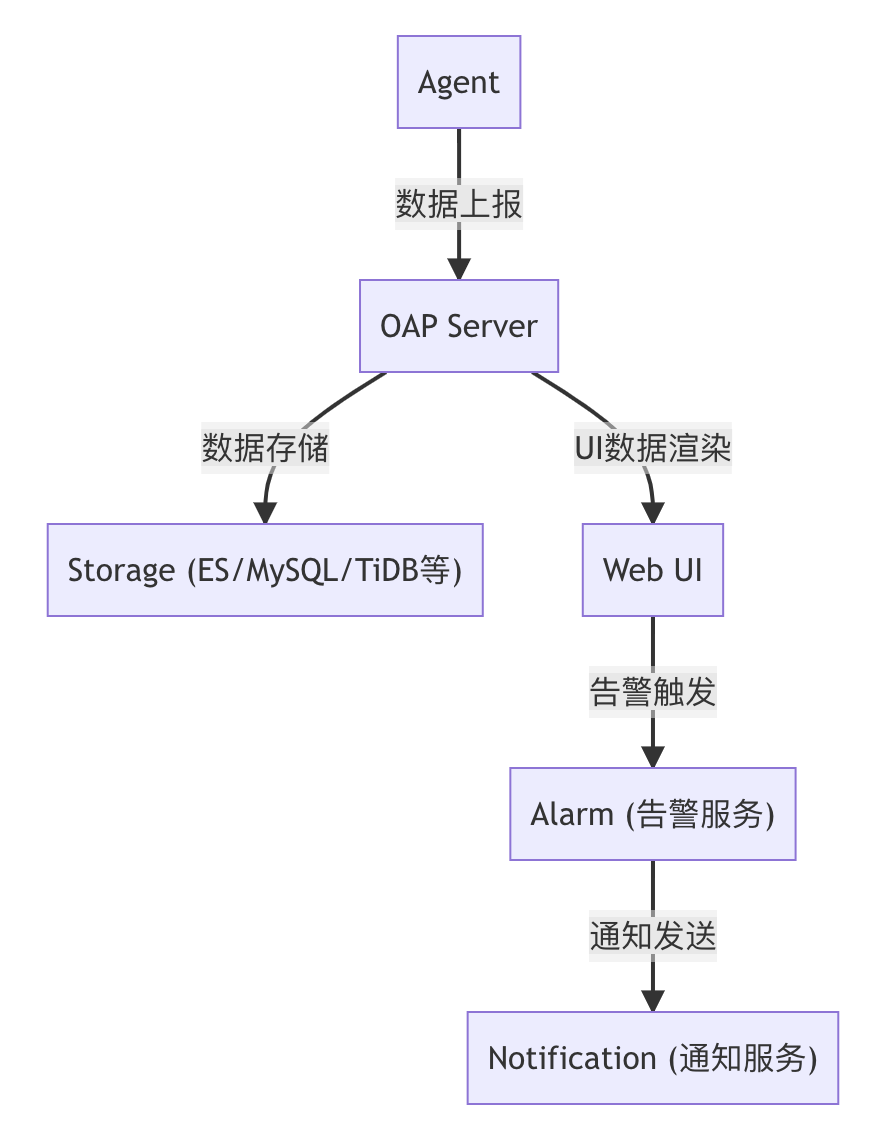
1. Agent/探针层
架构角色:数据采集端
实现机制:
- 基于Java Agent技术实现无侵入式埋点
- 支持多种语言的探针(Java, .NET, NodeJS等)
- 采用插件化架构,可按需扩展监控能力
核心功能:
- 方法级追踪数据采集
- JVM指标收集
- 上下文传播(跨进程/跨线程)
- 自适应采样控制
2. OAP(Observability Analysis Platform)服务层
架构角色:数据处理中枢
模块组成:
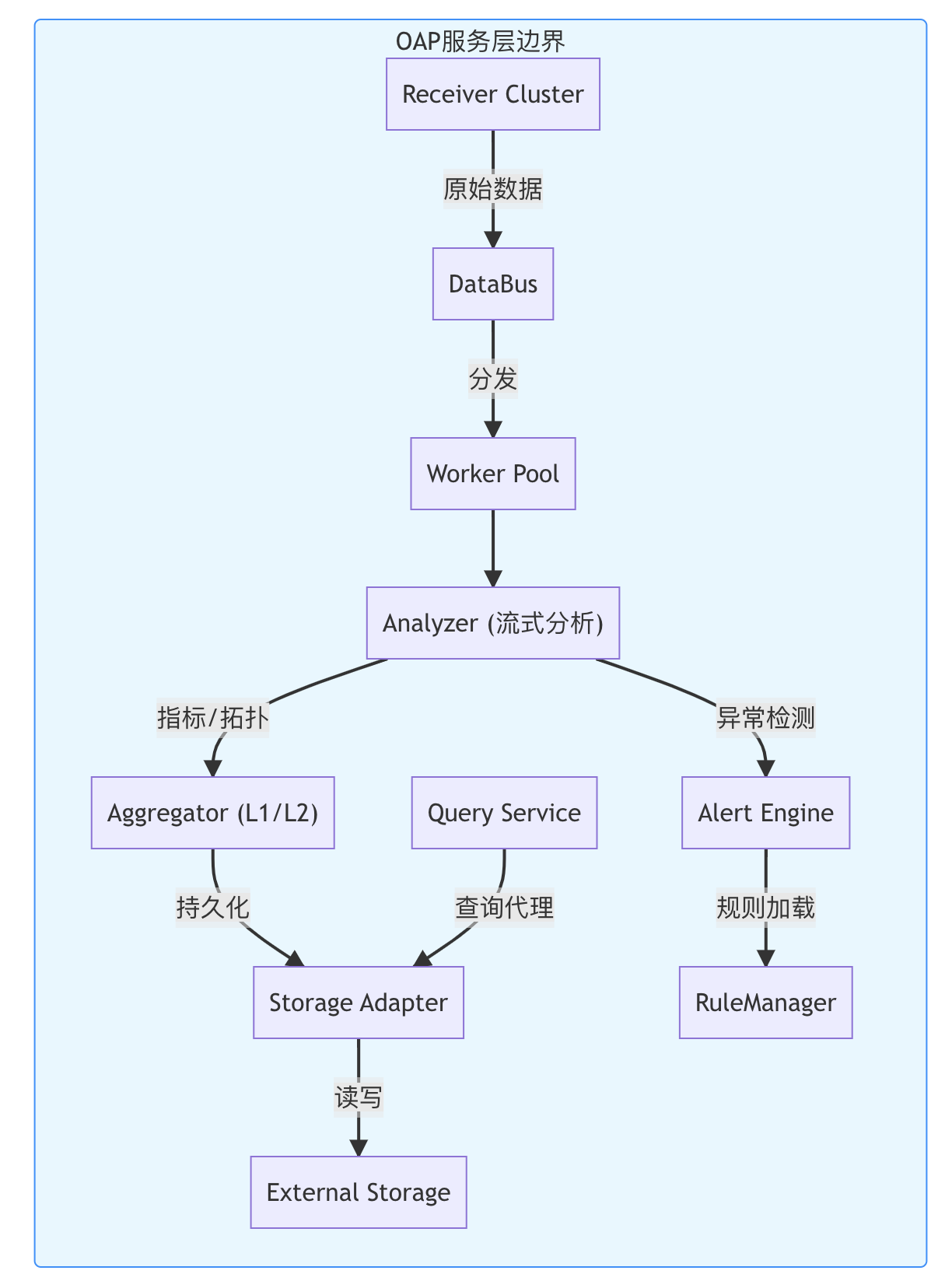
1. 接收层(Receiver)
- 协议支持:
- Agent上报:gRPC(SkyWalking原生协议)
- 第三方集成:HTTP/JSON(如OpenTelemetry)、Kafka(日志流)
- 关键组件:
- Receiver-Trace:调用链数据解析
- Receiver-Meter:Prometheus格式指标解析
- Receiver-JVM:Java探针性能数据接收
2. 数据总线(Data Bus)
- 作用:异步解耦接收层与分析层
- 实现:
- 内存队列(默认):基于Disruptor高性能环形队列
- 扩展支持:Kafka(集群部署时启用)
3. 分析引擎(Analyzer)
- 实时计算:
- OAL脚本:定义指标计算规则(如service_resp_time = avg(endpoint.latency))
- MAL引擎:数学告警表达式(如error_rate = sum(error)/sum(total))
- 拓扑构建:自动识别服务依赖关系(基于Trace的上下游分析)
4. 聚合器(Aggregator)
- 多级聚合:
- L1聚合:分钟级指标(原始精度)
- L2聚合:小时/天级指标(降精度存储)
- 优化策略:时间窗口滚动计算(减少重复扫描)
5. 告警引擎(Alert Engine)
- 规则触发:
- 流式检测(如service_sla < 99%持续5分钟)
- 支持动态加载规则(无需重启服务)
- 输出事件:通过gRPC/Kafka推送至Alarm Service
6. 存储适配层(Storage Adapter)
- 多存储支持:
- 时序数据:Elasticsearch(默认)、TiDB
- 元数据:H2(嵌入式)、MySQL
- 分片策略:按时间分片(如metrics-202306)
7. 查询引擎(Query Engine)
- 统一接口:
- GraphQL:拓扑/追踪查询
- PromQL:指标查询(兼容Prometheus)
- 缓存优化:热点数据LRU缓存
核心价值:
- 实时流式分析(Analyzer + Aggregator)
- 可插拔架构(通过Storage Adapter对接不同存储)
- 一体化观测能力(Metrics/Tracing/Logging联动)
3. UI层
架构特点:
- 基于React+Ant Design实现
- 动态仪表盘配置
- 拓扑图自动布局算法
- 多租户支持
三、核心架构设计亮点
1. 混合探针模型
java
/**
* Java Agent的入口方法,由JVM在应用主程序启动前自动调用
*
* @param args 从-javaagent参数传入的配置字符串(如agent.jar=config.properties)
* @param inst JVM提供的Instrumentation实例,用于类加载拦截和字节码修改
*/
public static void premain(String args, Instrumentation inst) {
// 1. 创建插件扫描器
// PluginConfig会加载plugins/目录下的所有插件定义文件(如apm-dubbo-plugin.xml)
// PluginFinder根据这些配置建立"类名->对应插件"的映射关系
PluginFinder finder = new PluginFinder(new PluginConfig());
// 2. 安装字节码增强器
// 将Instrumentation实例与插件扫描器绑定,后续所有类加载时都会触发扫描器检查
// ByteBuddyAgent内部通过java.lang.instrument.ClassFileTransformer实现字节码注入
ByteBuddyAgent.install(inst, finder);
}支持三种数据采集模式:
- 自动探针:零代码修改
- 手动埋点:通过@Trace注解等
- 服务网格集成:Istio/Envoy数据适配
2. 高性能数据处理流水线
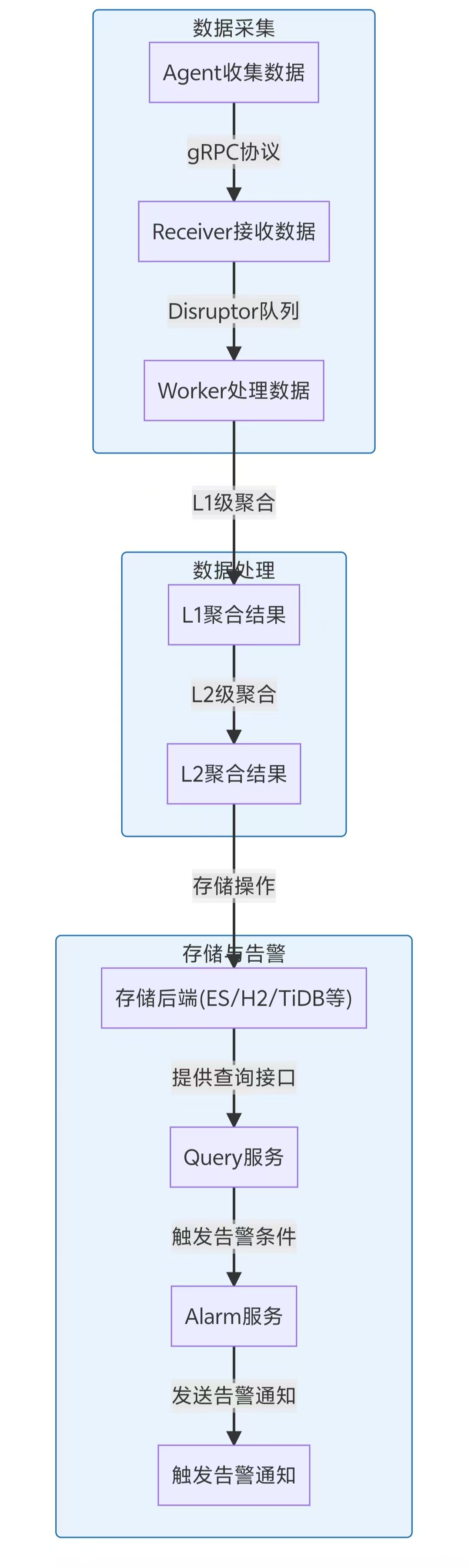
关键优化点:
- 异步非阻塞IO模型
- 多级缓冲队列
- 批处理写优化
- 压缩传输
3. 可扩展存储架构
XML
# 存储模块配置(支持动态扩展)
storage:
# 1. 存储类型选择器 - 核心扩展点
# 通过环境变量SW_STORAGE动态指定存储类型(默认elasticsearch)
# 可扩展值:elasticsearch/h2/mysql/tidb/influxdb等
selector: ${SW_STORAGE:elasticsearch}
# 2. Elasticsearch配置组 - 插件化实现案例
elasticsearch:
# 命名空间隔离(多租户支持)
nameSpace: ${SW_NAMESPACE:""}
# 集群节点动态配置 - 支持水平扩展
# 格式:ip1:port,ip2:port 可通过SW_STORAGE_ES_CLUSTER_NODES覆盖
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
# 其他可扩展参数示例:
# - indexShardsNumber: 分片数扩展
# - bulkActions: 批量写入规模调整 支持存储类型:
- Elasticsearch(生产推荐)
- H2(开发测试)
- TiDB/MySQL(关系型方案)
- BanyanDB(SkyWalking自研时序数据库)
四、分布式协调与一致性保障机制
该架构通过分片路由、多级聚合和一致性协议的组合,在分布式环境下实现数据有序处理。
1. 数据分片路由机制
- 哈希分片策略 :Agent根据TraceID/ServiceID等关键字段计算哈希值,确定目标OAP节点,确保相同业务链路的请求始终路由到同一节点处理
- 动态负载均衡 :OAP集群通过心跳检测实时同步节点负载状态,Agent侧动态调整路由权重(如基于CPU/内存使用率)
- 混合角色设计 :默认所有OAP节点均为Mixed角色(同时承担接收和聚合),大规模部署时可分离为Receiver和Aggregator两类专用节点
2. 分布式计算协同
|-------------|------------------------------------------|
| 处理阶段 | 协调机制 |
| 初次聚合 | Receiver节点完成本地指标计算,需跨节点聚合的数据通过Data Bus分发 |
| 二次聚合 | Aggregator节点按分片规则接收数据,完成全局聚合后写入存储 |
| 冲突解决 | 采用时间戳+版本号机制,对重复数据执行去重(如选择时间戳最新的记录) |
3. 一致性保障技术
- 最终一致性模型 :通过异步批处理实现指标聚合,容忍秒级延迟但保证最终结果准确
- 向量时钟(Vector Clock) :记录数据版本演化路径,解决跨节点时钟不同步导致的分歧
- 幂等设计 :所有数据处理操作支持重复执行,避免网络重传导致的数据重复计算
4. 容错与恢复
- 检查点(Checkpoint) :定期持久化处理进度,故障恢复时从最近检查点继续处理
- 冗余副本 :关键数据在多个OAP节点保留副本,主节点故障时自动切换
- 补偿机制 :对超时/失败任务启动重试或回滚,确保数据不丢失
五、性能优化实践
****1. Agent端优化:
- 适当调整采样率
- 过滤非关键Span
- 启用压缩传输
2. 服务端优化:
core:`
`default:`
`# 调整工作线程数`
`restThreads: ${SW_CORE_REST_THREADS:2}`
`# 增大处理队列`
`restQueueSize: ${SW_CORE_QUEUE_SIZE:10000}`
`3. 存储层优化:
a. ES分片策略优化
b. 冷热数据分离
c. 索引生命周期管理
六、与其他APM系统架构对比
|-------|------------|--------|----------|
| 特性 | SkyWalking | Zipkin | Pinpoint |
| 代码侵入性 | 低 | 中 | 低 |
| 扩展性 | 高(模块化) | 一般 | 一般 |
| 存储多样性 | 支持多种 | 有限 | HBase为主 |
| 语言支持 | 多语言 | 多语言 | Java为主 |
| 云原生支持 | 优秀 | 一般 | 有限 |
结语
SkyWalking通过其模块化、可扩展的架构设计,在分布式系统监控领域展现出强大的适应能力。其架构演进始终围绕三个核心原则:
- 对业务透明:最小化侵入性
- 高性能处理:应对大规模部署
- 开放生态:多语言多协议支持