2025深度学习发论文&模型涨点之------强化学习+卡尔曼滤波
强化学习(Reinforcement Learning, RL)与卡尔曼滤波(Kalman Filtering, KF)的交叉研究已成为智能控制与状态估计领域的重要前沿方向。
强化学习通过试错机制优化决策策略,而卡尔曼滤波则基于贝叶斯理论实现对动态系统状态的高效估计,二者在算法框架与数学基础上具有天然的互补性。随着部分可观测马尔可夫决策过程(POMDP)和深度强化学习(DRL)的快速发展,研究者们逐渐认识到将卡尔曼滤波的 probabilistic state estimation 能力与强化学习的 policy optimization 相结合,可显著提升智能体在复杂动态环境中的鲁棒性与样本效率。
我整理了一些强化学习+卡尔曼滤波【**论文+代码】**合集,以需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
Nature Champion-level drone racing using deep reinforcement learning
使用深度强化学习的冠军级无人机竞速
方法
深度强化学习训练:在仿真环境中使用深度强化学习训练无人机的控制策略。
数据驱动的噪声模型:通过在真实世界中收集的数据,估计感知和动态的残差模型,并将其集成到仿真环境中以提高策略的现实性。
视觉-惯性估计与门检测:结合视觉-惯性估计和门检测网络,将高维视觉和惯性信息转化为低维状态表示。
卡尔曼滤波融合:使用卡尔曼滤波器融合视觉-惯性估计和门检测的结果,以获得更准确的无人机状态估计。
创新点
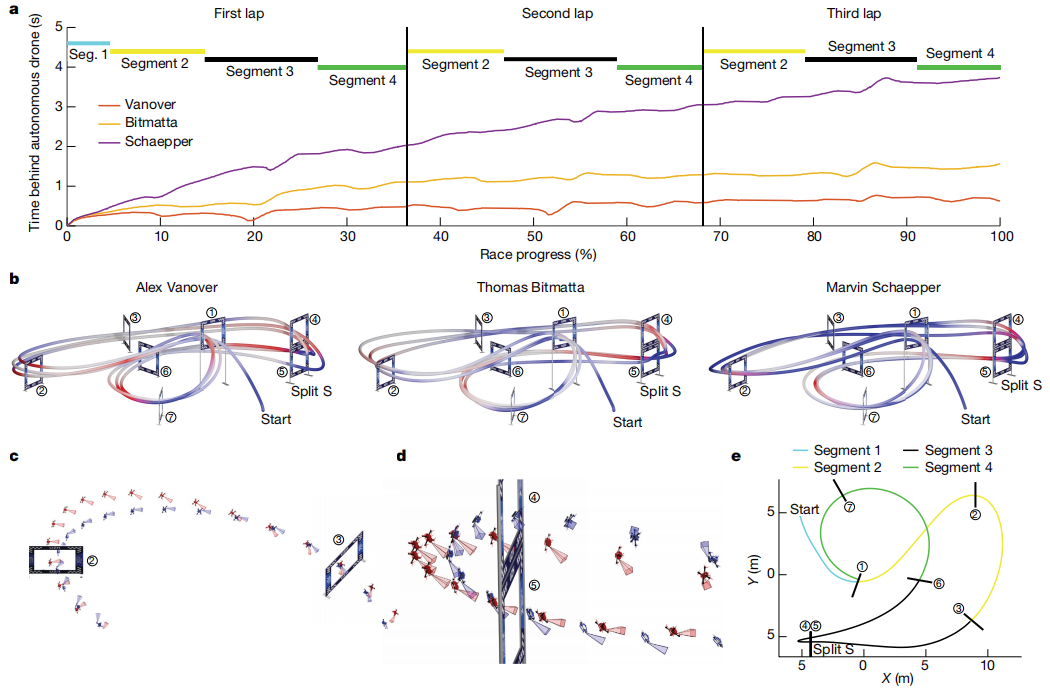
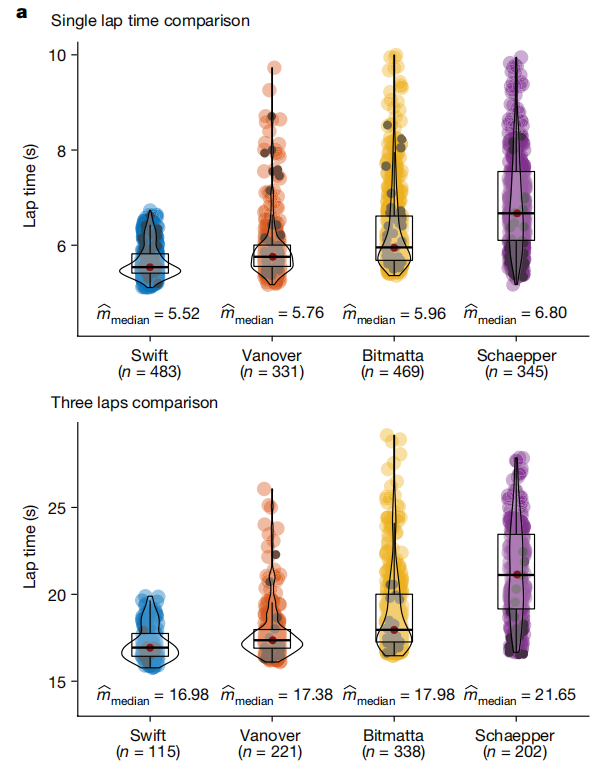
性能提升:Swift 在与人类世界冠军的比赛中多次获胜,并创下了最快比赛时间记录,例如在与 2019 年无人机竞速联盟世界冠军 Alex Vanover 的比赛中,Swift 的最快单圈时间比人类冠军快了半秒。
鲁棒性:Swift 在起跑和急转弯等关键赛段表现优于人类飞行员,例如在 Split-S 赛段,Swift 的平均速度比人类飞行员快,且在转弯时更加精准。
适应性:Swift 能够在不同的环境条件下保持高性能,尽管其感知系统假设环境外观与训练时一致,但通过在多样化条件下训练可以提高其鲁棒性。
论文2:
HyperController: A Hyperparameter Controller for Fast and Stable Training of Reinforcement Learning Neural Networks
HyperController:用于强化学习神经网络快速稳定训练的超参数控制器
方法
线性高斯动态系统建模:将超参数优化问题建模为未知的线性高斯动态系统。
卡尔曼滤波器学习:使用卡尔曼滤波器学习超参数目标函数的高效表示。
离散化状态变量:通过离散化状态变量,实现对线性高斯动态系统输出的最优一步预测。
独立优化超参数:分别优化每个超参数,而不是搜索全局超参数配置,减少了搜索空间。
创新点
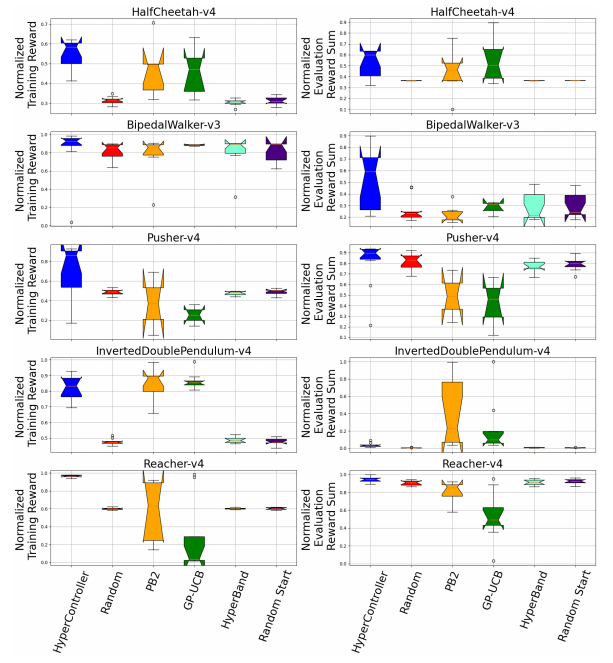
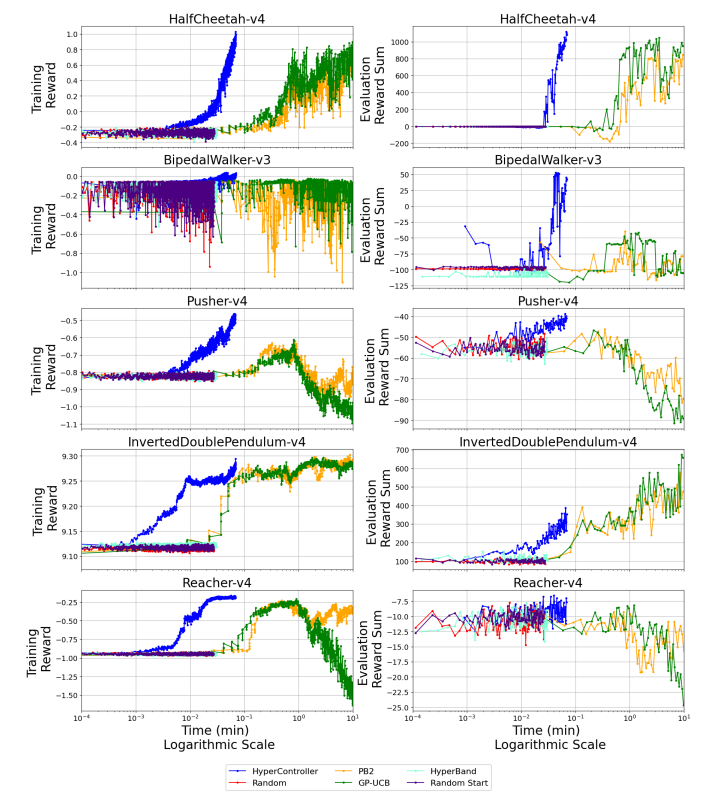
效率提升:与传统的贝叶斯优化方法相比,HyperController 的计算复杂度显著降低,例如在 OpenAI Gymnasium 的多个环境中,HyperController 的训练时间比 GP-UCB 和 PB2 等方法快了 10 倍以上。
性能提升:在多个强化学习任务中,HyperController 实现了更高的中位数奖励,例如在 HalfCheetah-v4 任务中,HyperController 的中位数奖励比其他方法高出 20% 以上。
稳定性:HyperController 在训练过程中能够保持稳定的性能提升,例如在 1000 次迭代后,HyperController 的最终训练奖励和评估奖励和的中位数均高于其他方法。
论文3:
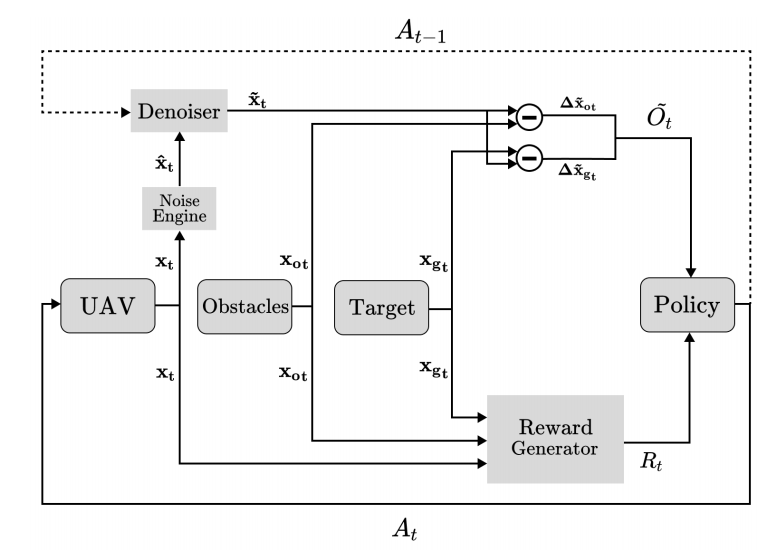
Sim-to-Real Deep Reinforcement Learning based Obstacle Avoidance for UAVs under Measurement Uncertainty
基于Sim-to-Real深度强化学习的无人机避障方法:应对测量不确定性
方法
近端策略优化(PPO):使用 PPO 算法在仿真环境中训练无人机的避障策略。
噪声注入:在训练和评估过程中引入不同水平的高斯噪声,以模拟真实传感器的测量不确定性。
去噪技术:使用低通滤波器和卡尔曼滤波器等去噪技术来提高在有偏噪声环境下的性能。
仿真到现实(Sim-to-Real)转移:将仿真中训练的策略直接部署到真实世界中的无人机上,无需进一步修改。
创新点
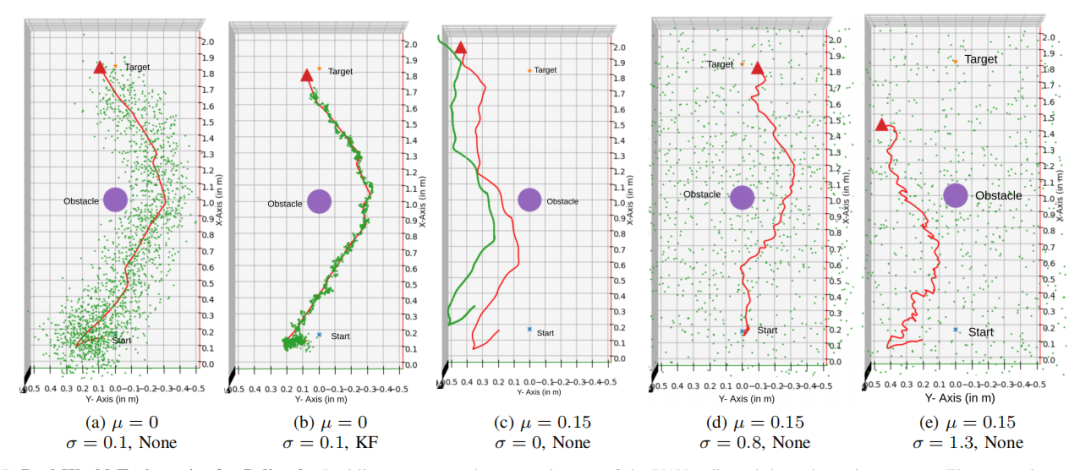
性能提升:在有偏噪声环境下,通过人为注入特定方差的噪声,可以显著提高无人机的避障性能,例如在有 0.15 米偏置的情况下,注入 0.8 米的标准差噪声可以使成功率达到 100%,而没有噪声时成功率为 0%。
鲁棒性:训练时加入小量噪声的策略(Policy 2)在各种噪声环境下表现更为稳定,例如在标准差为 3.0 的无偏噪声环境下,Policy 2 的成功率达到 56%,而未加入噪声训练的策略(Policy 1)成功率为 0%。
适应性:通过在仿真环境中进行广泛的训练和测试,验证了策略在真实世界中的有效性,例如在真实环境中,Policy 2 在加入 0.8 米标准差噪声后,所有试验均成功到达目标。