目录
前言
Segnet原理篇讲解:【语义分割专栏】3:Segnet原理篇 - carpell - 博客园
代码地址,下载可复现:fouen6/Segnet_semantic-segmentation: 用于学习理解segnet原理
本篇文章收录于语义分割专栏,如果对语义分割领域感兴趣的,可以去看看专栏,会对经典的模型以及代码进行详细的讲解哦!其中会包含可复现的代码!(数据集文中提供了下载地址,下载不到可在评论区要取)
上篇文章已经带大家学习过了Segnet的原理,相信大家对于原理应该有了比较深的了解。本文将会带大家去手动复现属于自己的一个语义分割模型。将会深入代码进行讲解,如果有讲错的地方欢迎大家批评指正!
其实所有的深度学习模型的搭建我认为可以总结成五部分:模型的构建,数据集的处理,评价指标的设定,训练流程,测试。其实感觉有点深度学习代码八股文的那种意思。本篇同样的也会按照这样的方式进行讲解,希望大家能够深入代码去进行了解学习。
请记住:只懂原理不懂代码,你就算有了很好的想法创新点,你也难以去实现,所以希望大家能够深入去了解,最好能够参考着本文自己复现一下。
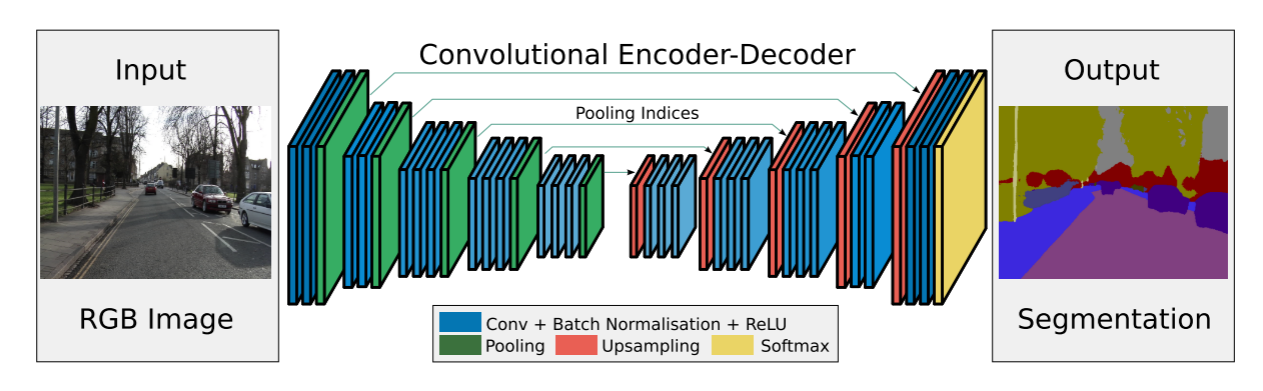
Segnet全流程代码
模型搭建(model)
首先是我们的crop函数,为什么需要用到这个,因为在测试的时候,我们不会对图像进行resize操作的,所以其就不一定是32的倍数,在下采样的过程中可能会出现从45->22的情况,但是上采样过程中就会变成22->44,这样就会造成shape的不匹配,所以需要对齐两者的shape大小。
python
def crop(upsampled, bypass):
h1, w1 = upsampled.shape[2], upsampled.shape[3]
h2, w2 = bypass.shape[2], bypass.shape[3]
# 计算差值
deltah = h2 - h1
deltaw = w2 - w1
# 计算填充的起始和结束位置
# 对于高度
pad_top = deltah // 2
pad_bottom = deltah - pad_top
# 对于宽度
pad_left = deltaw // 2
pad_right = deltaw - pad_left
# 对 upsampled 进行中心填充
upsampled_padded = F.pad(upsampled, (pad_left, pad_right, pad_top, pad_bottom), "constant", 0)
return upsampled_padded然后就是我们的Segnet模型代码了。其实还是非常好理解的,其编码器的结构就是VGG的结构,只不过其在maxpooling的时候需要保存索引,然后就是解码器的结构,其实就是对编码器做个对称就行了。写好模型参数之后,非常重要的,记得要进行参数的初始化哈,这样能够利于之后的训练过程。
python
class SegNet(nn.Module):
def __init__(self,num_classes=12):
super(SegNet, self).__init__()
self.encoder1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.encoder2 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
self.encoder3 = nn.Sequential(
nn.Conv2d(128,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
)
self.encoder4 = nn.Sequential(
nn.Conv2d(256,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
)
self.encoder5 = nn.Sequential(
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
)
self.decoder1 = nn.Sequential(
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
)
self.decoder2 = nn.Sequential(
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
)
self.decoder3 = nn.Sequential(
nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
self.decoder4 = nn.Sequential(
nn.Conv2d(128,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.decoder5 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,num_classes,kernel_size=1),
)
self.max_pool = nn.MaxPool2d(2,2,return_indices=True)
self.max_uppool = nn.MaxUnpool2d(2,2)
self.initialize_weights()
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x1 = self.encoder1(x)
x,pool_indices1 = self.max_pool(x1)
x2 = self.encoder2(x)
x,pool_indices2 = self.max_pool(x2)
x3 = self.encoder3(x)
x,pool_indices3 = self.max_pool(x3)
x4 = self.encoder4(x)
x,pool_indices4 = self.max_pool(x4)
x5 = self.encoder5(x)
x,pool_indices5 = self.max_pool(x5)
x = self.max_uppool(x,pool_indices5)
x = crop(x, x5)
x = self.decoder1(x)
x = self.max_uppool(x,pool_indices4)
x = crop(x, x4)
x = self.decoder2(x)
x = self.max_uppool(x,pool_indices3)
x = crop(x, x3)
x = self.decoder3(x)
x = self.max_uppool(x,pool_indices2)
x = crop(x, x2)
x = self.decoder4(x)
x = self.max_uppool(x,pool_indices1)
x = crop(x, x1)
x = self.decoder5(x)
return x数据处理(dataloader)
数据集名称:CamVid

在这里进行下载,CamVid数据集有两种,一种是官方的就是上述的下载地址的,总共有32种类别,划分的会更加的细致。但是一般官网的太难打开了,所以我们可以通过Kaggle中的CamVid (Cambridge-Driving Labeled Video Database)进行下载。
还有一种就是11类别的(不包括背景),会将一些语义相近的内容进行合并,就划分的没有这么细致,任务难度也会比较低一些。(如果你在网上找不到的话,可以在评论区发言或是私聊我要取)
CamVid 数据集主要用于自动驾驶场景中的语义分割,包含驾驶场景中的道路、交通标志、车辆等类别的标注图像。该数据集旨在推动自动驾驶系统在道路场景中的表现。
数据特点:
- 图像数量:包括701帧视频序列图像,分为训练集、验证集和测试集。
- 类别:包含32个类别(也有包含11个类别的),包括道路、建筑物、车辆、行人等。
- 挑战:由于数据集主要来自城市交通场景,因此面临着动态变化的天气、光照、交通密度等挑战
这里我已经专门发了一篇博客对语义分割任务常用的数据集做了深入的介绍,已经具体讲解了其实现的处理代码。如果你对语义分割常用数据集有不了解的话,可以先去我的语义分割专栏中进行了解哦!! 我这里就直接附上代码了。
python
import os
from PIL import Image
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
from torch.utils.data import Dataset, DataLoader
import numpy as np
import torch
# 11类
Cam_CLASSES = [ "Unlabelled","Sky","Building","Pole",
"Road","Sidewalk", "Tree","SignSymbol",
"Fence","Car","Pedestrian","Bicyclist"]
# 用于做可视化
Cam_COLORMAP = [
[0, 0, 0],[128, 128, 128],[128, 0, 0],[192, 192, 128],
[128, 64, 128],[0, 0, 192],[128, 128, 0],[192, 128, 128],
[64, 64, 128],[64, 0, 128],[64, 64, 0],[0, 128, 192]
]
# 转换RGB mask为类别id的函数
def mask_to_class(mask):
mask_class = np.zeros((mask.shape[0], mask.shape[1]), dtype=np.int64)
for idx, color in enumerate(Cam_COLORMAP):
color = np.array(color)
# 每个像素和当前颜色匹配
matches = np.all(mask == color, axis=-1)
mask_class[matches] = idx
return mask_class
class CamVidDataset(Dataset):
def __init__(self, image_dir, label_dir):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = A.Compose([
A.Resize(224, 224),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.images = sorted(os.listdir(image_dir))
self.labels = sorted(os.listdir(label_dir))
assert len(self.images) == len(self.labels), "Images and labels count mismatch!"
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
label_path = os.path.join(self.label_dir, self.labels[idx])
image = np.array(Image.open(img_path).convert("RGB"))
label_rgb = np.array(Image.open(label_path).convert("RGB"))
# RGB转类别索引
mask = mask_to_class(label_rgb)
#mask = torch.from_numpy(np.array(mask)).long()
# Albumentations 需要 (H, W, 3) 和 (H, W)
transformed = self.transform(image=image, mask=mask)
return transformed['image'], transformed['mask'].long()
def get_dataloader(data_path, batch_size=4, num_workers=4):
train_dir = os.path.join(data_path, 'train')
val_dir = os.path.join(data_path, 'val')
trainlabel_dir = os.path.join(data_path, 'train_labels')
vallabel_dir = os.path.join(data_path, 'val_labels')
train_dataset = CamVidDataset(train_dir, trainlabel_dir)
val_dataset = CamVidDataset(val_dir, vallabel_dir)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, pin_memory=True, num_workers=num_workers)
val_loader = DataLoader(val_dataset, shuffle=False, batch_size=batch_size, pin_memory=True, num_workers=num_workers)
return train_loader, val_loader评价指标(metric)
我们这里语义分割采用的评价指标为:PA(像素准确率),CPA(类别像素准确率),MPA(类别平均像素准确率),IoU(交并比),mIoU(平均交并比),FWIoU(频率加权交并比),mF1(平均F1分数)。
这里我已经专门发了一篇博客对这些平均指标做了深入的介绍,已经具体讲解了其实现的代码。如果你对这些评价指标有不了解的话,可以先去我的语义分割专栏中进行了解哦!! 我这里就直接附上代码了。
python
import numpy as np
__all__ = ['SegmentationMetric']
class SegmentationMetric(object):
def __init__(self, numClass):
self.numClass = numClass
self.confusionMatrix = np.zeros((self.numClass,) * 2)
def genConfusionMatrix(self, imgPredict, imgLabel):
mask = (imgLabel >= 0) & (imgLabel < self.numClass)
label = self.numClass * imgLabel[mask] + imgPredict[mask]
count = np.bincount(label, minlength=self.numClass ** 2)
confusionMatrix = count.reshape(self.numClass, self.numClass)
return confusionMatrix
def addBatch(self, imgPredict, imgLabel):
assert imgPredict.shape == imgLabel.shape
self.confusionMatrix += self.genConfusionMatrix(imgPredict, imgLabel)
return self.confusionMatrix
def pixelAccuracy(self):
acc = np.diag(self.confusionMatrix).sum() / self.confusionMatrix.sum()
return acc
def classPixelAccuracy(self):
denominator = self.confusionMatrix.sum(axis=1)
denominator = np.where(denominator == 0, 1e-12, denominator)
classAcc = np.diag(self.confusionMatrix) / denominator
return classAcc
def meanPixelAccuracy(self):
classAcc = self.classPixelAccuracy()
meanAcc = np.nanmean(classAcc)
return meanAcc
def IntersectionOverUnion(self):
intersection = np.diag(self.confusionMatrix)
union = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(
self.confusionMatrix)
union = np.where(union == 0, 1e-12, union)
IoU = intersection / union
return IoU
def meanIntersectionOverUnion(self):
mIoU = np.nanmean(self.IntersectionOverUnion())
return mIoU
def Frequency_Weighted_Intersection_over_Union(self):
denominator1 = np.sum(self.confusionMatrix)
denominator1 = np.where(denominator1 == 0, 1e-12, denominator1)
freq = np.sum(self.confusionMatrix, axis=1) / denominator1
denominator2 = np.sum(self.confusionMatrix, axis=1) + np.sum(self.confusionMatrix, axis=0) - np.diag(
self.confusionMatrix)
denominator2 = np.where(denominator2 == 0, 1e-12, denominator2)
iu = np.diag(self.confusionMatrix) / denominator2
FWIoU = (freq[freq > 0] * iu[freq > 0]).sum()
return FWIoU
def classF1Score(self):
tp = np.diag(self.confusionMatrix)
fp = self.confusionMatrix.sum(axis=0) - tp
fn = self.confusionMatrix.sum(axis=1) - tp
precision = tp / (tp + fp + 1e-12)
recall = tp / (tp + fn + 1e-12)
f1 = 2 * precision * recall / (precision + recall + 1e-12)
return f1
def meanF1Score(self):
f1 = self.classF1Score()
mean_f1 = np.nanmean(f1)
return mean_f1
def reset(self):
self.confusionMatrix = np.zeros((self.numClass, self.numClass))
def get_scores(self):
scores = {
'Pixel Accuracy': self.pixelAccuracy(),
'Class Pixel Accuracy': self.classPixelAccuracy(),
'Intersection over Union': self.IntersectionOverUnion(),
'Class F1 Score': self.classF1Score(),
'Frequency Weighted Intersection over Union': self.Frequency_Weighted_Intersection_over_Union(),
'Mean Pixel Accuracy': self.meanPixelAccuracy(),
'Mean Intersection over Union(mIoU)': self.meanIntersectionOverUnion(),
'Mean F1 Score': self.meanF1Score()
}
return scores训练流程(train)
到这里,所有的前期准备都已经就绪,我们就要开始训练我们的模型了。
python
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--data_root', type=str, default='../../data/CamVid/CamVid(11)', help='Dataset root path')
parser.add_argument('--data_name', type=str, default='CamVid', help='Dataset class names')
parser.add_argument('--model', type=str, default='Segnet', help='Segmentation model')
parser.add_argument('--num_classes', type=int, default=12, help='Number of classes')
parser.add_argument('--epochs', type=int, default=50, help='Epochs')
parser.add_argument('--lr', type=float, default=0.005, help='Learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum')
parser.add_argument('--weight-decay', type=float, default=1e-4, help='Weight decay')
parser.add_argument('--batch_size', type=int, default=8, help='Batch size')
parser.add_argument('--checkpoint', type=str, default='./checkpoint', help='Checkpoint directory')
parser.add_argument('--resume', type=str, default=None, help='Resume checkpoint path')
return parser.parse_args()首先来看看我们的一些参数的设定,一般我们都是这样放在最前面,能够让人更加快速的了解其代码的一些核心参数设置。首先就是我们的数据集位置(data_root),然后就是我们的数据集名称(classes_name),这个暂时没什么用,因为我们目前只用了CamVid数据集,然后就是检测模型的选择(model),我们选择Segnet模型,数据集的类别数(num_classes),训练epoch数,这个你设置大一点也行,因为我们会在训练过程中保存最好结果的模型的。学习率(lr),动量(momentum),权重衰减(weight-decay),这些都属于模型超参数,大家可以尝试不同的数值,多试试,就会有个大致的了解的,批量大小(batch_size)根据自己电脑性能来设置,一般都是为2的倍数,保存权重的文件夹(checkpoint),是否继续训练(resume)。
python
def train(args):
if not os.path.exists(args.checkpoint):
os.makedirs(args.checkpoint)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
n_gpu = torch.cuda.device_count()
print(f"Device: {device}, GPUs available: {n_gpu}")
# Dataloader
train_loader, val_loader = get_dataloader(args.data_root, batch_size=args.batch_size)
train_dataset_size = len(train_loader.dataset)
val_dataset_size = len(val_loader.dataset)
print(f"Train samples: {train_dataset_size}, Val samples: {val_dataset_size}")
# Model
model = get_model(num_classes=args.num_classes)
model.to(device)
# Loss + Optimizer + Scheduler
criterion = nn.CrossEntropyLoss(ignore_index=0)
#optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
scaler = torch.cuda.amp.GradScaler()
# Resume
start_epoch = 0
best_miou = 0.0
if args.resume and os.path.isfile(args.resume):
print(f"Loading checkpoint '{args.resume}'")
checkpoint = torch.load(args.resume)
start_epoch = checkpoint['epoch']
best_miou = checkpoint['best_miou']
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
print(f"Loaded checkpoint (epoch {start_epoch})")
# Training history
history = {
'train_loss': [],
'val_loss': [],
'pixel_accuracy': [],
'miou': []
}
print(f"🚀 Start training ({args.model})")
for epoch in range(start_epoch, args.epochs):
model.train()
train_loss = 0.0
t0 = time.time()
for images, masks in tqdm(train_loader, desc=f'Epoch {epoch+1}/{args.epochs} [Train]'):
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(images)
loss = criterion(outputs, masks)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
train_loss += loss.item() * images.size(0)
train_loss /= train_dataset_size
history['train_loss'].append(train_loss)
# Validation
model.eval()
val_loss = 0.0
evaluator = SegmentationMetric(args.num_classes)
with torch.no_grad():
for images, masks in tqdm(val_loader, desc=f'Epoch {epoch+1}/{args.epochs} [Val]'):
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
loss = criterion(outputs, masks)
val_loss += loss.item() * images.size(0)
predictions = torch.argmax(outputs, dim=1)
if isinstance(predictions, torch.Tensor):
predictions = predictions.cpu().numpy()
if isinstance(masks, torch.Tensor):
masks = masks.cpu().numpy()
evaluator.addBatch(predictions, masks)
val_loss /= val_dataset_size
history['val_loss'].append(val_loss)
scores = evaluator.get_scores()
print(f"\n📈 Validation Epoch {epoch+1}:")
for k, v in scores.items():
if isinstance(v, np.ndarray):
print(f"{k}: {np.round(v, 3)}")
else:
print(f"{k}: {v:.4f}")
history['pixel_accuracy'].append(scores['Pixel Accuracy'])
history['miou'].append(scores['Mean Intersection over Union(mIoU)'])
# Save best
if scores['Mean Intersection over Union(mIoU)'] > best_miou:
best_miou = scores['Mean Intersection over Union(mIoU)']
torch.save({
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'best_miou': best_miou,
}, os.path.join(args.checkpoint, f'{args.model}_best.pth'))
print(f"Saved best model! mIoU: {best_miou:.4f}")
scheduler.step()
print(f"🕒 Epoch time: {time.time() - t0:.2f}s\n")
print("🎉 Training complete!")然后就是我们的训练流程了。训练流程也是有套路的哦,我们该怎么去搭建一个更好的训练流程,可以从多方面入手的。
首先我们确定我们的代码运行设备,基本上都是要GPU的。然后就是加载我们处理好的数据,这里就是dataloader的那部分了,加载好数据之后,我们加载我们构建好的模型,这就是我们在model那部分做的工作。然后就是loss函数,Optimizer 和 Scheduler,这是我们比较重要的几个部分。loss函数的选择有很多,不同的loss函数在一定程度上会决定我们的模型收敛好坏,像语义分割任务就基本上都是用交叉熵损失函数了。Optimizer 也有很多,SGD,Adam之类的,都可以去尝试下。Scheduler就是我们的学习策略,学习率的更新,希望一开始学习率大,训练到后期学习率小,这样加速收敛,避免震荡。然后还有个scaler,这是AMP(自动混合精度训练),能够节省我们的内存,让我们的小电脑也能跑起来模型。
还有个断点重训功能,为了避免因为一些意外的情况导致训练中断,可能这是我们训练好久的结果,所以我们可以通过这个功能继续从断点进行训练。然后就是训练了,我们加载数据,通过模型的预测与mask得到损失,然后梯度误差反传,更新模型参数。当一个epoch中的数据都训练结束之后,我们就需要评估下我们的模型怎么样了,这里就是根据我们的评价指标进行评价,其中我们标记best_mIoU,当更好的时候就重新保存模型文件。
最后当训练结束后我们就会获得最好的模型参数的文件了。
完整代码:
python
import argparse
import os
import time
from tqdm import tqdm
import numpy as np
import torch
import torch.nn as nn
from datasets.CamVid_dataloader11 import get_dataloader
from model import get_model
from metric import SegmentationMetric
os.environ['NO_ALBUMENTATIONS_UPDATE'] = '1'
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--data_root', type=str, default='../../data/CamVid/CamVid(11)', help='Dataset root path')
parser.add_argument('--data_name', type=str, default='CamVid', help='Dataset class names')
parser.add_argument('--model', type=str, default='Segnet', help='Segmentation model')
parser.add_argument('--num_classes', type=int, default=12, help='Number of classes')
parser.add_argument('--epochs', type=int, default=50, help='Epochs')
parser.add_argument('--lr', type=float, default=0.005, help='Learning rate')
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum')
parser.add_argument('--weight-decay', type=float, default=1e-4, help='Weight decay')
parser.add_argument('--batch_size', type=int, default=8, help='Batch size')
parser.add_argument('--checkpoint', type=str, default='./checkpoint', help='Checkpoint directory')
parser.add_argument('--resume', type=str, default=None, help='Resume checkpoint path')
return parser.parse_args()
def train(args):
if not os.path.exists(args.checkpoint):
os.makedirs(args.checkpoint)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
n_gpu = torch.cuda.device_count()
print(f"Device: {device}, GPUs available: {n_gpu}")
# Dataloader
train_loader, val_loader = get_dataloader(args.data_root, batch_size=args.batch_size)
train_dataset_size = len(train_loader.dataset)
val_dataset_size = len(val_loader.dataset)
print(f"Train samples: {train_dataset_size}, Val samples: {val_dataset_size}")
# Model
model = get_model(num_classes=args.num_classes)
model.to(device)
# Loss + Optimizer + Scheduler
criterion = nn.CrossEntropyLoss(ignore_index=0)
#optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
scaler = torch.cuda.amp.GradScaler()
# Resume
start_epoch = 0
best_miou = 0.0
if args.resume and os.path.isfile(args.resume):
print(f"Loading checkpoint '{args.resume}'")
checkpoint = torch.load(args.resume)
start_epoch = checkpoint['epoch']
best_miou = checkpoint['best_miou']
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
print(f"Loaded checkpoint (epoch {start_epoch})")
# Training history
history = {
'train_loss': [],
'val_loss': [],
'pixel_accuracy': [],
'miou': []
}
print(f"🚀 Start training ({args.model})")
for epoch in range(start_epoch, args.epochs):
model.train()
train_loss = 0.0
t0 = time.time()
for images, masks in tqdm(train_loader, desc=f'Epoch {epoch+1}/{args.epochs} [Train]'):
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = model(images)
loss = criterion(outputs, masks)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
train_loss += loss.item() * images.size(0)
train_loss /= train_dataset_size
history['train_loss'].append(train_loss)
# Validation
model.eval()
val_loss = 0.0
evaluator = SegmentationMetric(args.num_classes)
with torch.no_grad():
for images, masks in tqdm(val_loader, desc=f'Epoch {epoch+1}/{args.epochs} [Val]'):
images = images.to(device)
masks = masks.to(device)
outputs = model(images)
loss = criterion(outputs, masks)
val_loss += loss.item() * images.size(0)
predictions = torch.argmax(outputs, dim=1)
if isinstance(predictions, torch.Tensor):
predictions = predictions.cpu().numpy()
if isinstance(masks, torch.Tensor):
masks = masks.cpu().numpy()
evaluator.addBatch(predictions, masks)
val_loss /= val_dataset_size
history['val_loss'].append(val_loss)
scores = evaluator.get_scores()
print(f"\n📈 Validation Epoch {epoch+1}:")
for k, v in scores.items():
if isinstance(v, np.ndarray):
print(f"{k}: {np.round(v, 3)}")
else:
print(f"{k}: {v:.4f}")
history['pixel_accuracy'].append(scores['Pixel Accuracy'])
history['miou'].append(scores['Mean Intersection over Union(mIoU)'])
# Save best
if scores['Mean Intersection over Union(mIoU)'] > best_miou:
best_miou = scores['Mean Intersection over Union(mIoU)']
torch.save({
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'best_miou': best_miou,
}, os.path.join(args.checkpoint, f'{args.model}_best.pth'))
print(f"Saved best model! mIoU: {best_miou:.4f}")
scheduler.step()
print(f"🕒 Epoch time: {time.time() - t0:.2f}s\n")
print("🎉 Training complete!")
if __name__ == '__main__':
args = parse_arguments()
train(args)模型测试(test)
这里就到了我们的最后一步了,测试我们的模型。
python
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--image_dir', type=str, default='./datasets/test', help='Input image or folder')
parser.add_argument('--checkpoint', type=str, default='./checkpoint/Segnet_best.pth', help='Checkpoint path')
parser.add_argument('--model', type=str, default='Segnet', help='Segmentation head')
parser.add_argument('--num_classes', type=int, default=12, help='Number of classes')
parser.add_argument('--save_dir', type=str, default='./predictions', help='Directory to save results')
parser.add_argument('--overlay', type=bool, default=True, help='Save overlay image')
return parser.parse_args()同样的来看,我们所需要的一些参数设定哈!我们所需要进行测试的图片文件夹(image_dir),我们训练时候所保存的权重文件夹(checkpoint),我们使用的检测模型(model),还有数据集的类别数(num_classes),保持的结果的文件夹(save_dir),还要个非常重要的参数,是否将预测图覆盖在原图上(overlay),通过这个我们可以更好的看语义分割的效果怎么样。
python
def load_image(image_path):
image = Image.open(image_path).convert('RGB')
transform = T.Compose([
#T.Resize((224, 224)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
return transform(image).unsqueeze(0), image # tensor, PIL image
#把类别mask ➔ 彩色图 (用VOC_COLORMAP)
def mask_to_color(mask):
color_mask = np.zeros((mask.shape[0], mask.shape[1], 3), dtype=np.uint8)
for label in range(len(Cam_COLORMAP)):
color_mask[mask == label] = Cam_COLORMAP[label]
return color_mask
def save_mask(mask, save_path):
color_mask = mask_to_color(mask)
Image.fromarray(color_mask).save(save_path)
def overlay_mask_on_image(raw_image, mask, alpha=0.6):
mask_color = mask_to_color(mask)
mask_pil = Image.fromarray(mask_color)
mask_pil = mask_pil.resize(raw_image.size, resample=Image.NEAREST)
blended = Image.blend(raw_image, mask_pil, alpha=alpha)
return blended然后来看测试过程中会用到的一些函数,当然测试首先肯定要加载我们的图片呐。注意看这里有个细节,加载图片的时候我们进行了标准化的,为什么这么做?因为我们在训练模型的时候,图片就进行了标准化的操作,所有测试图片,我们肯定要保持图片和训练时候的条件一样。然后为了更好的可视化,我们需要将预测的mask图转换为彩色图。根据VOC_COLORMAP的颜色进行转换即可。还有个overlay_mask_on_image函数,通过将预测的可视化图与原图进行叠加混合能够让我们更加直观。
python
def predict(args):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Device: {device}")
# 模型
model = get_model(num_classes=args.num_classes)
checkpoint = torch.load(args.checkpoint, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
os.makedirs(args.save_dir, exist_ok=True)
# 预测单张 or 批量
if os.path.isdir(args.image_dir):
image_list = [os.path.join(args.image_dir, f) for f in os.listdir(args.image_dir) if f.lower().endswith(('jpg', 'png', 'jpeg'))]
else:
image_list = [args.image]
print(f"🔎 Found {len(image_list)} images to predict.")
for img_path in tqdm(image_list):
img_tensor, raw_img = load_image(img_path)
img_tensor = img_tensor.to(device)
with torch.no_grad():
output = model(img_tensor)
pred = torch.argmax(output.squeeze(), dim=0).cpu().numpy()
# 保存 mask
base_name = os.path.basename(img_path).split('.')[0]
mask_save_path = os.path.join(args.save_dir, f"{base_name}_mask.png")
save_mask(pred, mask_save_path)
# 保存 overlay
if args.overlay:
overlay_img = overlay_mask_on_image(raw_img, pred)
overlay_save_path = os.path.join(args.save_dir, f"{base_name}_overlay.png")
overlay_img.save(overlay_save_path)
print(f"Saved: {mask_save_path}")
if args.overlay:
print(f"Saved overlay: {overlay_save_path}")
print("🎉 Prediction done!")然后就到了预测环节,其实流程跟train的流程差不多,但是不在需要像train的时候什么梯度反传更新参数了,直接预测得出结果然后保存即可。
首先确定设备哈,一般都是GPU的,然后就是就是加载数据和模型了,最后预测保存结果即可,这些代码应该还是比较容易理解的,直接看代码即可。
完整代码:
python
import argparse
import os
import torch
import numpy as np
from PIL import Image
from tqdm import tqdm
from model import get_model
import torchvision.transforms as T
from datasets.CamVid_dataloader11 import *
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--image_dir', type=str, default='./datasets/test', help='Input image or folder')
parser.add_argument('--checkpoint', type=str, default='./checkpoint/Segnet_best.pth', help='Checkpoint path')
parser.add_argument('--model', type=str, default='Segnet', help='Segmentation head')
parser.add_argument('--num_classes', type=int, default=12, help='Number of classes')
parser.add_argument('--save_dir', type=str, default='./predictions', help='Directory to save results')
parser.add_argument('--overlay', type=bool, default=True, help='Save overlay image')
return parser.parse_args()
def load_image(image_path):
image = Image.open(image_path).convert('RGB')
transform = T.Compose([
#T.Resize((224, 224)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
return transform(image).unsqueeze(0), image # tensor, PIL image
#把类别mask ➔ 彩色图 (用VOC_COLORMAP)
def mask_to_color(mask):
color_mask = np.zeros((mask.shape[0], mask.shape[1], 3), dtype=np.uint8)
for label in range(len(Cam_COLORMAP)):
color_mask[mask == label] = Cam_COLORMAP[label]
return color_mask
def save_mask(mask, save_path):
color_mask = mask_to_color(mask)
Image.fromarray(color_mask).save(save_path)
def overlay_mask_on_image(raw_image, mask, alpha=0.6):
mask_color = mask_to_color(mask)
mask_pil = Image.fromarray(mask_color)
mask_pil = mask_pil.resize(raw_image.size, resample=Image.NEAREST)
blended = Image.blend(raw_image, mask_pil, alpha=alpha)
return blended
def predict(args):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Device: {device}")
# 模型
model = get_model(num_classes=args.num_classes)
checkpoint = torch.load(args.checkpoint, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
os.makedirs(args.save_dir, exist_ok=True)
# 预测单张 or 批量
if os.path.isdir(args.image_dir):
image_list = [os.path.join(args.image_dir, f) for f in os.listdir(args.image_dir) if f.lower().endswith(('jpg', 'png', 'jpeg'))]
else:
image_list = [args.image]
print(f"🔎 Found {len(image_list)} images to predict.")
for img_path in tqdm(image_list):
img_tensor, raw_img = load_image(img_path)
img_tensor = img_tensor.to(device)
with torch.no_grad():
output = model(img_tensor)
pred = torch.argmax(output.squeeze(), dim=0).cpu().numpy()
# 保存 mask
base_name = os.path.basename(img_path).split('.')[0]
mask_save_path = os.path.join(args.save_dir, f"{base_name}_mask.png")
save_mask(pred, mask_save_path)
# 保存 overlay
if args.overlay:
overlay_img = overlay_mask_on_image(raw_img, pred)
overlay_save_path = os.path.join(args.save_dir, f"{base_name}_overlay.png")
overlay_img.save(overlay_save_path)
print(f"Saved: {mask_save_path}")
if args.overlay:
print(f"Saved overlay: {overlay_save_path}")
print("🎉 Prediction done!")
if __name__ == '__main__':
args = parse_arguments()
predict(args)效果图
我就训练了50个epoch,效果也没有很好,不过理解其原理即可。效果图如下所示

结语
希望上列所述内容对你有所帮助,如果有错误的地方欢迎大家批评指正!
并且如果可以的话希望大家能够三连鼓励一下,谢谢大家!
如果你觉得讲的还不错想转载,可以直接转载,不过麻烦指出本文来源出处即可,谢谢!