任务
实战(二):MLP 实现图像多分类
基于 mnist 数据集,建立 mlp 模型,实现 0-9 数字的十分类 task:
1、实现 mnist 数据载入,可视化图形数字;
2、完成数据预处理:图像数据维度转换与归一化、输出结果格式转换;
3、计算模型在预测数据集的准确率;
4、模型结构:两层隐藏层,每层有 392 个神经元
参考资料
1、载入mnist 数据,可视化图形数字
载入数据
python
#load the mnist data
from tensorflow.keras.datasets import mnist
(X_train, y_train),(X_test, y_test) = mnist.load_data()
python
print(type(X_train), X_train.shape)
#<class 'numpy.ndarray'> (60000, 28, 28),训练样本有 60000个,每个都是 28 * 28 像素组成的 Array可视化部分数据
python
#可视化部分数据
img1 = X_train[0] #取第一个数据
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(3,3))
plt.imshow(img1)
plt.title(y_train[0])# 标签作为 title
plt.show()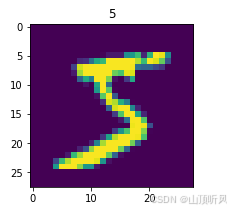
2、数据预处理
图像数据维度转换与归一化
python
img1.shape# (28,28), 可以看出是 28 行 28 列
#需要转换成 784列的新的数组
python
#format the input data
feature_size = img1.shape[0] * img1.shape[1] # 行数*列数
print(feature_size)# 784
#把原来的数据进行 reshape
X_train_format = X_train.reshape(X_train.shape[0], feature_size)#第一个参数是样本数量
print(X_train_format.shape)# (60000, 784), 60000个样本, 784列
X_test_format = X_test.reshape(X_test.shape[0], feature_size)#第一个参数是样本数量
print(X_test_format.shape)#(10000, 784)
python
#归一化:图像数据是 0-255,区间太大,需要归一化到 0-1之间
#normalize the input data
X_train_normal = X_train_format/255
X_test_normal = X_test_format/255
print(X_train_format[0]) #原数据
python
print(X_train_normal[0]) #归一化后的数据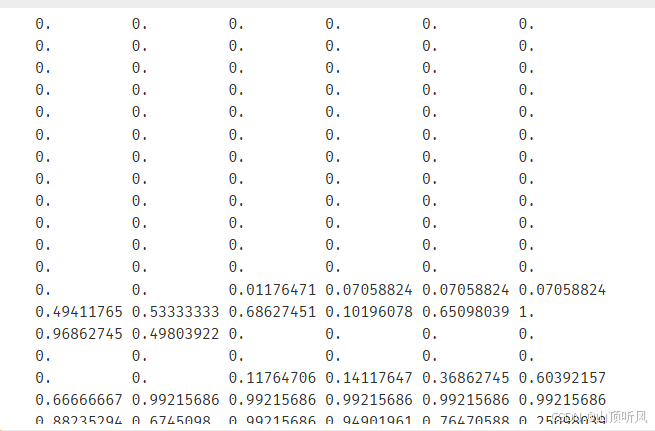
输出结果格式转换
python
#数据预处理:输出结果也需要进行转换,转换成 0001这样的标签
#format the output data(labels)
from tensorflow.keras.utils import to_categorical
y_train_format = to_categorical(y_train)
y_test_format = to_categorical(y_test)
print(y_train[0])# 5, 第一副图像是 5
print(y_train_format[0])#[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] # 第 5 个是 13、计算模型在预测数据集的准确率
创建 MLP 模型
python
# set up the model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
mlp =Sequential()
mlp.add(Dense(units = 392, activation = 'sigmoid', input_dim = feature_size))
#第二层有 392 个神经元,input_dim 为一开始的输入数据
mlp.add(Dense(units = 392, activation = 'sigmoid'))# 第三层
mlp.add(Dense(units = 10, activation = 'softmax')) # 输出层为0-9 10个数字
mlp.summary()
配置模型
python
#config the model
mlp.compile(loss = 'categorical_crossentropy' , optimizer = 'adam')
#categorial_crossentropy: 这个是用于多分类的损失函数; optimizer:优化方法训练模型
python
#train the model
mlp.fit(X_train_normal, y_train_format, epochs = 10)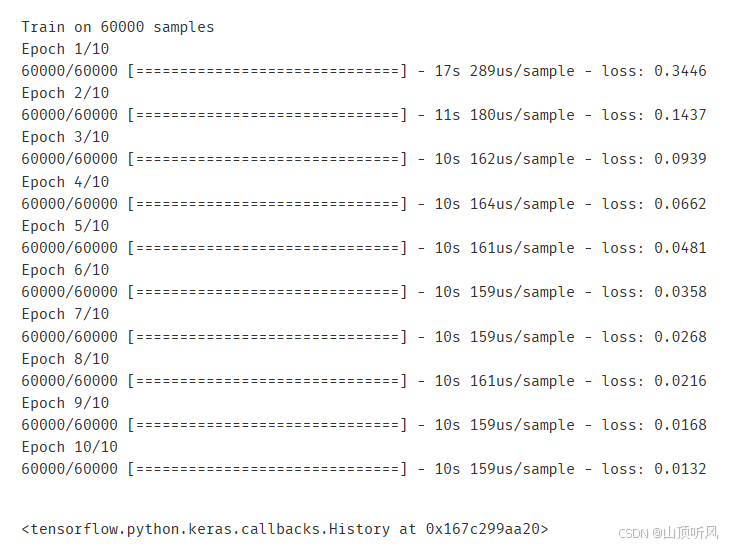
评估模型
训练集
python
#预测训练集数据
y_train_predict = mlp.predict_classes(X_train_normal)
print(y_train_predict)
python
#计算对训练集预测的准确率
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train, y_train_predict)
print(accuracy_train)#0.9964833333333334测试集
python
#看下 测试集 的准确率
y_test_predict = mlp.predict_classes(X_test_normal)
accuracy_test = accuracy_score(y_test, y_test_predict)
print(accuracy_test)#0.981, 比较高,说明模型对图片的预测还是比较准确的展示出图形,看预测结果与实际是否相符
python
#选几幅图展示出来,看看预测结果是否一样
img2 = X_test[100] # 随便选择,这里选择第 11 幅图
fig2 = plt.figure(figsize = (3,3))
plt.imshow(img2)
plt.title(y_test_predict[100])
plt.show()#展示的是测试集第 11 张图片的图形 以及 预测的标签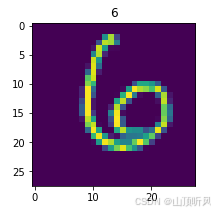
4、图像数字多分类实战总结
1、通过 mlp 模型,实现了基于图像数据的数字自动识别分类;
2、完成了图像的数字化处理与可视化;
3、对 mlp 模型的输入、输出数据格式有了更深的认识,完成了数据预处理与格式转换;
4、建立了结构更为复杂的 mlp 模型
5、mnist 数据集地址:http://yann.lecun.com/exdb/mnist/