机器学习+城市规划第十三期:XGBoost的地理加权改进,利用树模型实现更精准的地理加权回归
在城市规划中,如何准确预测并分析地理因素对各类决策的影响,一直是一个亟待解决的难题。传统的地理加权回归(Geographically Weighted Regression, GWR)方法可以很好地处理空间数据的局部变异性,但对于高维数据的处理能力有限。今天,我们将讨论如何将 XGBoost 树模型引入地理加权回归中,提升预测精度,并通过 SHAP 值进行可解释性分析。
1. 地理加权回归:一个回顾
地理加权回归(GWR)是一种用于处理地理空间数据的方法。在传统的回归模型中,假设回归系数在所有样本中是相同的。但在现实中,许多现象在不同地区表现出不同的规律,因此需要允许每个地点的回归系数独立变化。GWR 就是通过在空间上给每个样本赋予不同的回归系数来捕捉这种局部性。
然而,传统的 GWR 模型在处理复杂的高维数据时,存在着一些挑战。比如,当数据维度较高时,如何精确地捕捉局部特征成为一个问题。
2. XGBoost:树模型的优势
XGBoost(eXtreme Gradient Boosting)是一种非常强大的集成学习算法,能够通过构建多个决策树并加权组合这些树来进行预测。XGBoost 的优势在于其高效性、可处理复杂非线性关系的能力、强大的正则化功能以及抑制过拟合的特性。与传统的 GWR 模型不同,XGBoost 能够自动选择特征并处理高维数据,同时考虑样本间的复杂非线性关系。
通过将 XGBoost 和 地理加权回归 相结合,我们能够在保留地理空间特性的同时,提升模型的预测能力。
3. 模型构建过程与公式推导
3.1 地理加权因子的计算
首先,我们需要计算每个样本的地理加权因子。地理加权因子反映了不同地理位置之间的距离对模型预测的影响。具体的计算公式如下:
GeoWeight ( i ) = 1 N ∑ j = 1 N e − d ( i , j ) σ \text{GeoWeight}(i) = \frac{1}{N} \sum_{j=1}^{N} e^{-\frac{d(i,j)}{ \sigma }} GeoWeight(i)=N1j=1∑Ne−σd(i,j)
其中:
- d ( i , j ) d(i,j) d(i,j) 为样本 i i i 和 j j j 之间的地理距离,通常通过经纬度计算;
- σ \sigma σ 为标准化参数,决定了权重衰减的速度。
在代码中,通过以下步骤来实现地理加权因子的计算:
python
geo_distances = euclidean_distances(coords) # 计算经纬度之间的欧几里得距离
geo_distances = (geo_distances - geo_distances.mean()) / geo_distances.std() # 标准化距离
geo_weights = np.exp(-geo_distances).mean(axis=1) # 对每个样本计算平均地理加权3.2 XGBoost 模型
XGBoost 是基于梯度提升(Gradient Boosting)算法的,梯度提升通过逐步添加新的树来减少模型的预测误差。每一棵新树的目标是减少前一棵树的误差。其回归目标函数可以表示为:
L = ∑ i = 1 n ( y i − y ^ i ) 2 + ∑ k = 1 K Ω ( f k ) \mathcal{L} = \sum_{i=1}^{n} (y_i - \hat{y}i)^2 + \sum{k=1}^{K} \Omega(f_k) L=i=1∑n(yi−y^i)2+k=1∑KΩ(fk)
其中, Ω ( f k ) \Omega(f_k) Ω(fk) 是正则化项,确保树的复杂度不会过高,避免过拟合。具体的正则化项是:
Ω ( f k ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f_k) = \gamma T + \frac{1}{2} \lambda \sum_{j=1}^{T} w_j^2 Ω(fk)=γT+21λj=1∑Twj2
在代码中,我们设置了 XGBoost 的回归参数,并通过加权因子训练模型:
python
params = {
'objective': 'reg:squarederror', # 回归任务
'max_depth': 6, # 树的最大深度
'eta': 0.1, # 学习率
'subsample': 0.8, # 随机采样比率
'colsample_bytree': 0.8, # 每棵树随机选择的特征比例
'eval_metric': 'rmse' # 使用RMSE作为评估指标
}3.3 模型训练与预测
通过将地理加权因子作为样本权重,XGBoost 模型能够更好地考虑地理因素对预测的影响。训练后,我们通过预测测试集的结果,并计算模型的 RMSE 来评估模型性能:
python
y_pred = model.predict(dtest)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"RMSE: {rmse}")4. 模型构建与训练:XGBoost + 地理加权回归
在这一部分,我们将构建并训练一个基于 XGBoost 的回归模型,同时结合 地理加权因子(Geo-Weighted Factors)来提升模型的准确性。XGBoost 是一种基于决策树的集成学习算法,它通过逐步加权不同的决策树来优化预测结果,适用于处理高维度数据,并且具有强大的正则化能力,能够有效避免过拟合。
4.1 数据准备和地理加权因子的计算
首先,我们加载数据并提取自变量和因变量。数据中的经纬度用于计算每个样本的地理加权因子。地理加权因子基于每对样本之间的欧几里得距离计算,权重随着距离的增大而减小。我们使用一个高斯衰减函数来计算地理加权因子,并通过标准化地理距离来确保其对模型的影响适当。
代码:
python
# 1. 加载数据
data = pd.read_csv('2000yangben.csv')
# 提取经纬度(第一列和第二列),因变量(第三列)和自变量(第四列到第七列)
latitude = data.iloc[:, 0].values
longitude = data.iloc[:, 1].values
y = data.iloc[:, 2].values
X = data.iloc[:, 3:].values
# 2. 计算地理加权因子
# 这里我们使用简单的地理距离加权作为示例(也可以根据需求调整加权方式)
# 计算每对数据点之间的地理距离(基于经纬度)
coords = np.vstack((latitude, longitude)).T
geo_distances = euclidean_distances(coords)
# 标准化地理距离(为了后续加权操作)
geo_distances = (geo_distances - geo_distances.mean()) / geo_distances.std()
# 对每个样本,计算其到其他样本的平均距离作为权重
geo_weights = np.exp(-geo_distances).mean(axis=1) # 对每个样本计算平均地理加权- 地理距离计算 :使用
euclidean_distances函数计算每对样本之间的欧几里得距离。地理距离是根据经纬度计算的,表示样本之间的空间距离。 - 标准化:将计算出的地理距离进行标准化,以消除尺度差异。
- 加权计算 :通过
np.exp(-geo_distances)使用高斯衰减函数来计算每对样本的加权。较近的样本将拥有较高的权重,较远的样本则权重较低。
4.2 数据标准化
接下来,使用 StandardScaler 对自变量进行标准化,使其均值为 0,方差为 1。这有助于提高模型的训练效率,避免因特征量级差异导致的训练不稳定。
代码:
python
# 3. 数据预处理 - 标准化自变量
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)- StandardScaler :通过
fit_transform方法,标准化了自变量数据X,确保每个特征的均值为 0,方差为 1。这对于大多数机器学习模型来说,能显著提高训练稳定性和模型表现。
4.3 拆分数据集
使用 train_test_split 函数将数据集划分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的预测性能。同时,我们还将地理加权因子(geo_weights)一并拆分,以便在模型训练时作为样本权重使用。
代码:
python
# 4. 拆分数据集
X_train, X_test, y_train, y_test, geo_weights_train, geo_weights_test = train_test_split(X_scaled, y, geo_weights, test_size=0.2, random_state=42)- train_test_split:将数据分成训练集(80%)和测试集(20%)。由于我们引入了地理加权因子,它也会被拆分,确保模型能够根据地理加权因子训练。
4.4 模型训练:XGBoost
现在,我们使用 XGBoost 构建一个回归模型,并设置相关参数。XGBoost 是一种基于梯度提升的树模型,适用于回归和分类问题。通过调整模型的参数,可以进一步提升模型的准确性。
代码:
python
# 5. 使用XGBoost训练模型
# 创建DMatrix,包含自变量、因变量和加权因子
dtrain = xgb.DMatrix(X_train, label=y_train, weight=geo_weights_train)
dtest = xgb.DMatrix(X_test, label=y_test, weight=geo_weights_test)
# 设置XGBoost参数
params = {
'objective': 'reg:squarederror', # 回归任务
'max_depth': 6,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'eval_metric': 'rmse'
}
# 训练模型
model = xgb.train(params, dtrain, num_boost_round=100)-
DMatrix :XGBoost 使用 DMatrix 格式来处理数据,
dtrain和dtest分别是训练集和测试集的 DMatrix 对象。加权因子geo_weights_train和geo_weights_test被用作每个样本的权重。 -
XGBoost 参数:
objective='reg:squarederror':选择回归任务。max_depth=6:树的最大深度。eta=0.1:学习率。subsample=0.8:采样比例。colsample_bytree=0.8:每棵树使用的特征子集的比例。
4.5 模型评估:预测与RMSE
训练完成后,使用测试集对模型进行预测,并计算 RMSE(均方根误差) 来评估模型的表现。RMSE 越小,说明模型的预测效果越好。
代码:
python
# 6. 预测并评估模型
y_pred = model.predict(dtest)
# 计算RMSE(均方根误差)评估模型性能
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"RMSE: {rmse}")- mean_squared_error :计算预测值和实际值之间的均方误差(MSE),并通过
np.sqrt()获取 RMSE。RMSE 值越小,表示模型的预测误差越小。
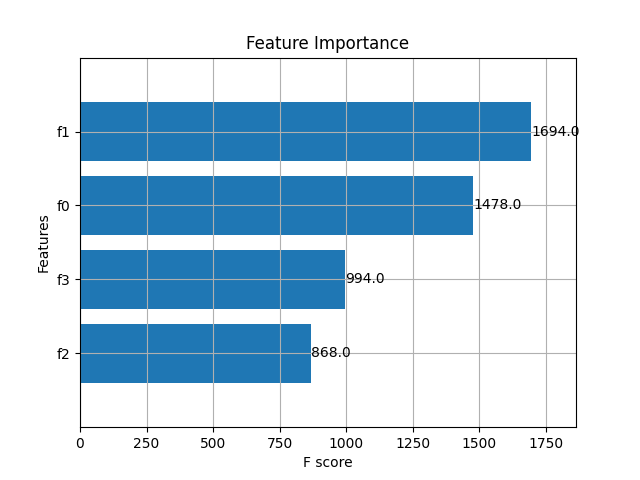
4.6 特征重要性可视化
XGBoost 提供了特征重要性可视化功能,我们可以通过绘制特征的重要性来观察哪些特征对模型的预测有最大影响。
代码:
python
# 7. 可视化特征重要性排序
xgb.plot_importance(model, importance_type='weight', max_num_features=10, height=0.8)
plt.title("Feature Importance")
plt.show()- plot_importance :该方法通过绘制特征重要性图,展示了各个特征对模型的重要性,
importance_type='weight'表示按特征在树中出现的次数来衡量特征重要性。
好的,以下是第六小节关于 SHAP值的计算与可视化 的详细讲解:
6. SHAP值计算与可视化
在机器学习模型中,SHAP(SHapley Additive exPlanations)值是非常重要的解释工具,它帮助我们理解每个特征对模型预测结果的贡献。SHAP 值是基于博弈论的思想,通过计算每个特征在不同样本中的贡献,来解释复杂模型的决策过程。在本小节中,我们将利用 SHAP 值来分析 XGBoost 模型,并进行可视化,特别是关注 Wind speed 特征对模型预测的影响。
6.1 SHAP值的计算
首先,我们使用 SHAP 库的 Explainer 类来计算模型的 SHAP 值。Explainer 类能够从训练好的 XGBoost 模型中提取出每个特征对预测的贡献,并生成 SHAP 值。接着,我们提取对应于 Wind speed 特征的 SHAP 值,用于后续的可视化分析。
代码:
python
# 7. SHAP值计算与可视化
X_test_df = pd.DataFrame(X_test, columns=data.columns[3:]) # 将测试集转化为 pandas DataFrame
# 使用训练数据和模型来创建SHAP解释器
explainer = shap.Explainer(model, X_train) # 创建解释器
shap_values = explainer(X_test_df) # 计算测试集的SHAP值
# 获取Wind speed的SHAP值
shap_values_for_feature = shap_values.values[:, 0] # 假设我们要看 'Wind speed' 对应的 SHAP 值X_test_df:将X_test转换为一个 Pandas DataFrame,以便能够传递列名给 SHAP 解释器。shap.Explainer(model, X_train):通过训练数据X_train和训练好的模型model来初始化 SHAP 解释器。shap_values = explainer(X_test_df):计算测试集X_test_df的 SHAP 值。每个 SHAP 值表示该特征对模型预测结果的贡献。
6.2 SHAP值的可视化
接下来,我们通过可视化 SHAP 值来分析 Wind speed 特征对模型预测的影响。我们将绘制散点图来展示每个样本的 SHAP 值,并根据 SHAP 值的变化对地理位置进行颜色映射,颜色的深浅表示 Wind speed 特征的 SHAP 值大小。
在地理信息学中,利用 SHAP 值与经纬度的结合进行空间分析,能够帮助我们更直观地了解某些特征在不同位置对模型输出的影响。我们使用 matplotlib 绘制散点图,展示地理位置和 Wind speed SHAP 值的关系。
代码:
python
# 8. 使用matplotlib绘制散点图
plt.figure(figsize=(10, 8))
# 使用与测试集对应的经纬度数据
latitude_test = latitude[:len(X_test)] # 只取与 X_test 匹配的经纬度
longitude_test = longitude[:len(X_test)] # 只取与 X_test 匹配的经纬度
# 绘制散点图,颜色根据 SHAP 值变化
scatter = plt.scatter(longitude_test, latitude_test, c=shap_values_for_feature, cmap='coolwarm', s=10, alpha=0.7)
# 添加颜色条
plt.colorbar(scatter, label="SHAP value (Wind speed)")
# 设置标题和标签
plt.title('Geographical SHAP Values for Wind speed')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
# 显示图形
plt.show()- 散点图 :在图中,我们使用经纬度作为坐标轴,
c=shap_values_for_feature设置了点的颜色来表示Wind speed对预测结果的 SHAP 值。颜色从蓝色(低 SHAP 值)到红色(高 SHAP 值)变化,展示了地理位置上Wind speed特征对模型预测的贡献。 cmap='coolwarm':我们使用coolwarm色系,它是一种经典的红紫蓝渐变色系,适合展示正负贡献的变化。红色代表较高的 SHAP 值,蓝色代表较低的 SHAP 值。plt.colorbar():为散点图添加了颜色条,标明颜色与 SHAP 值的对应关系。
6.3 结果解读
通过 SHAP 可视化,我们可以直观地看到 Wind speed 特征对模型预测的影响。以下是一些可能的观察点:
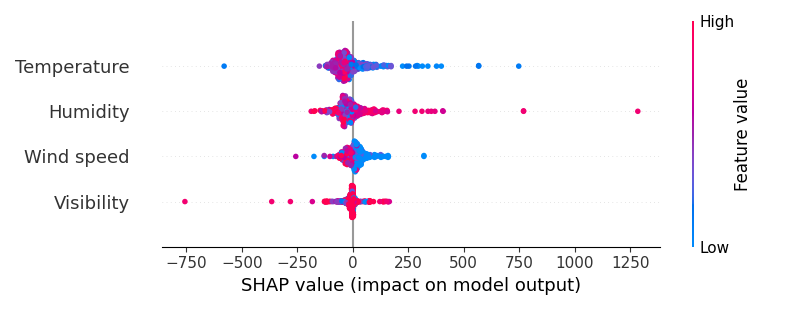
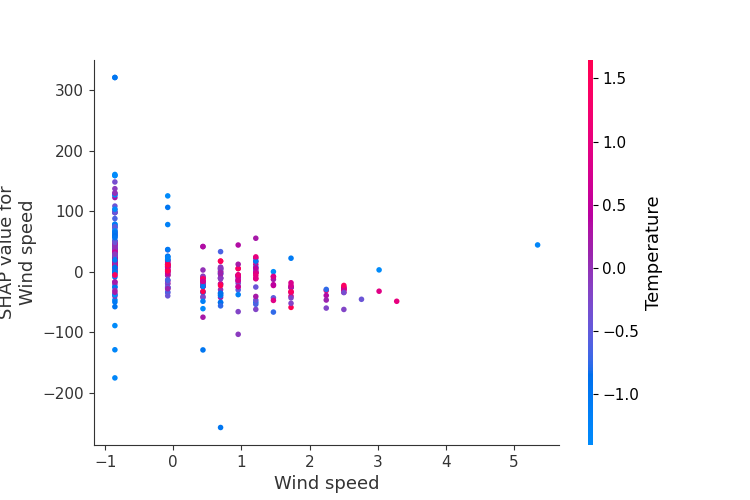
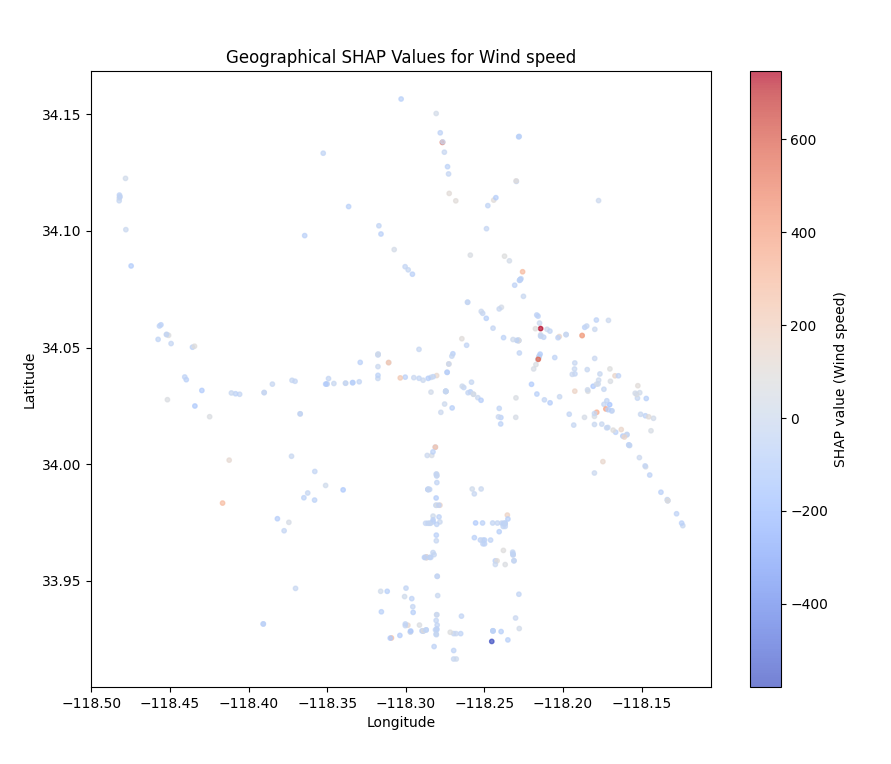
- 高 SHAP 值的区域 :在这些区域,
Wind speed特征对模型预测的影响较大。通常,这意味着该特征在这些地理位置上起到了重要的作用。 - 低 SHAP 值的区域 :这些区域中,
Wind speed特征对模型预测的影响较小,可能意味着该特征在这些地方的影响被其他特征所替代。
通过这种方式,城市规划人员可以获得更为精准的地理空间分析,帮助在不同地区采取更加定制化的规划和决策。
总结
在这一小节中,我们使用 SHAP 值来分析 Wind speed 特征对模型预测的贡献,并通过散点图进行可视化。通过结合 SHAP 值与地理位置,我们能够深入理解每个特征在不同地区对预测结果的影响,从而为城市规划提供更具解释力的决策依据。
6. 适用场景:城市规划中的应用
在城市规划中,地理加权回归模型(GWR)通常用于以下几个方面:
- 土地价格预测:不同地理位置的土地价格受周围环境、基础设施等多因素的影响。通过引入地理加权回归模型,城市规划者可以更准确地预测不同位置的土地价值。
- 交通流量预测:不同地理位置的交通流量存在显著差异,考虑地理因素后,能够更好地预测高峰时段的交通需求,为交通规划提供数据支持。
- 环境影响评估:城市中的污染源、绿地分布等影响区域环境质量,通过地理加权回归模型,能够精准分析环境因素的地理分布和影响,帮助城市规划者进行合理的环境规划。
6. 总结
本次介绍了如何将 XGBoost 模型与地理加权回归相结合,通过考虑地理加权因子提升预测精度。我们通过 SHAP 值对模型进行可解释性分析,为城市规划中的决策提供了更加精细的工具。在未来的城市规划中,结合机器学习与地理加权回归,将为更智能、高效的决策提供有力支持。
原创声明:本教程由课题组内部教学使用,利用CSDN平台记录,不进行任何商业盈利。