图像数据与显存
知识点回顾
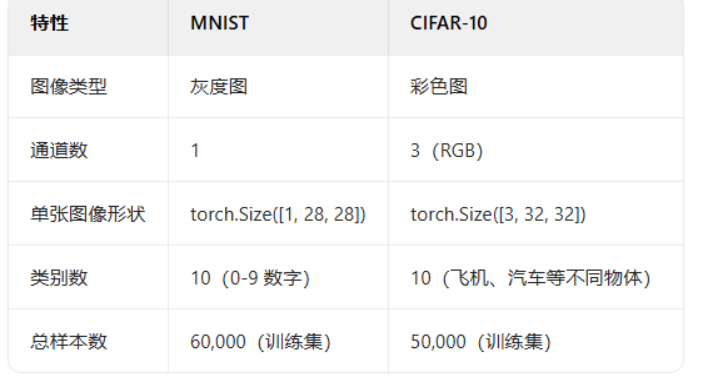
1.图像数据的格式:灰度和彩色数据
2.模型的定义
3.显存占用的4种地方
a.模型参数+梯度参数
b.优化器参数
c.数据批量所占显存
d.神经元输出中间状态
4.batchisize和训练的关系
python
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
torch.manual_seed(42)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#加载CIFAR10数据集
trainset = torchvision.datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=transform
)
#创建数据加载器
train_loader = torch.utils.data.DataLoader(
trainset,
batch_size=4,
download=True,
shuffle=True
)
# CIFAR-10的10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
#随机图片
sample_idx = torch.randint(0, len(trainset), (1,)).item()
img, label = trainset[sample_idx]
#打印形状
print(img.shape)
print(classes[label])
#定义图像显示
def imshow(img):
img = img / 2 + 0.5
nping = img.numpy()
plt.imshow(np.transpose(nping, (1, 2, 0)))
plt.axis('off')
plt.show()
imshow(img)
class MLP(nn.Module):
def __init__(self, input_size=3072, hidden_size=128, output_size=10):
super(MLP, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
model = MLP()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
from torchsummary import summary
print("\n模型信息")
summary(model, (3, 32, 32))显存占用部分
-
模型参数与梯度:模型的权重(Parameters)和对应的梯度(Gradients)会占用显存,尤其是深度神经网络(如 Transformer、ResNet 等),一个 1 亿参数的模型(如 BERT-base),单精度(float32)参数占用约 400MB(1e8×4Byte),加上梯度则翻倍至 800MB(每个权重参数都有其对应的梯度)。
-
部分优化器(如 Adam)会为每个参数存储动量(Momentum)和平方梯度(Square Gradient),进一步增加显存占用(通常为参数大小的 2-3 倍)
-
其他开销。
python
#参数占用内存
"""
3.1模型参数与梯度参数
参数和梯度占用,二者大致相等
原来数据类型转化成float32 4B
"""
model = MLP()
total_params = sum(p.numel() for p in model.parameters())
print('Total parameters:', total_params)
print(f"Total parameters (float32): {total_params * 4 / 1024 / 1024:.2f}MB")
"""
3.2优化器参数
Adam优化器参数占用,存储有额外状态
"""
"""
3.3数据批量的显存占用
"""
"""
3.4前向/反向传播中间变量
"""