目录

想在vision_transformer里面加SENet
1.在model文件下新建一个python文件
2.把 模块文件里的整个SENet代码复制到新的python文件中
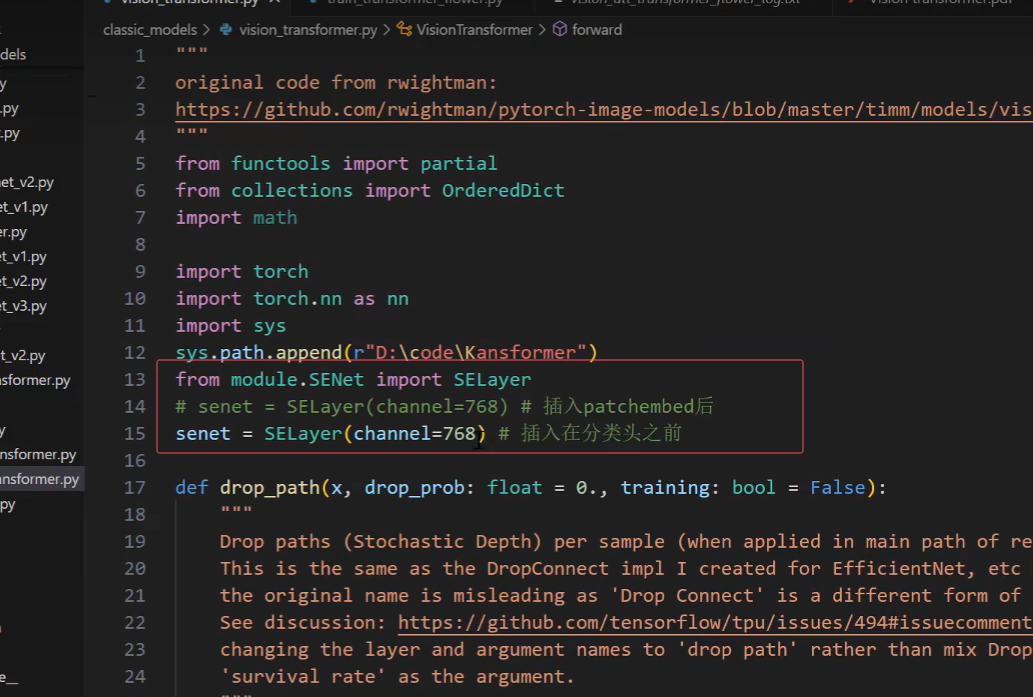
3.在开头导入 from model.SENet(新建文件名) import SELayer(新建文件中的类名)
4.在后面对SENet实例化
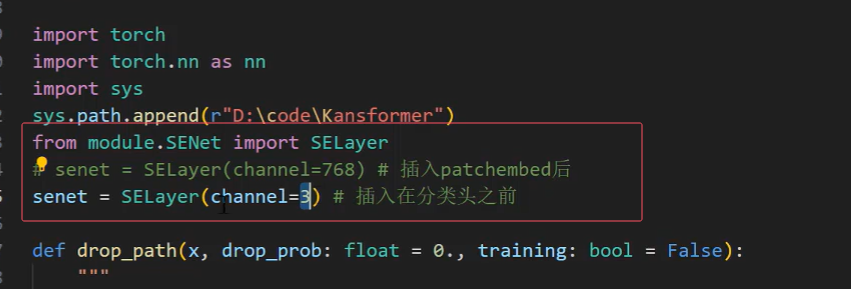
senet(自己定的命名)=SELayer( 类名)(channel=3)
//输入通道数 ,通道数填什么后面会说
注意:缝合模块,要注意通道数
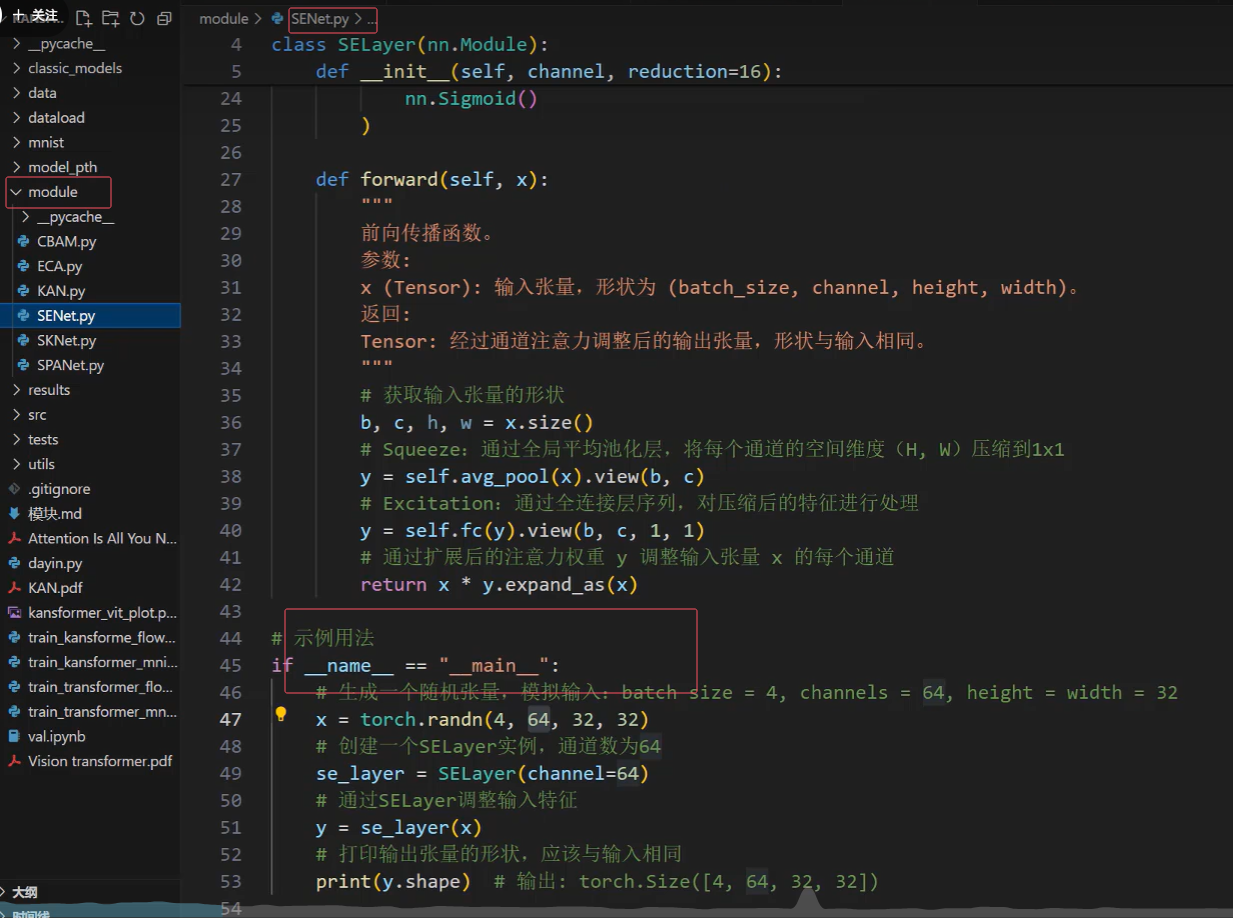
5.找到要改的这个类 class VisionTransformer(nn.Module):
6.找到其中的 def forward(self, x):
7.输出之前的形状
print(f"之前前前的形状为{x.shape}")# (32,3,224,224)
8.运行 train代码输出之前的形状
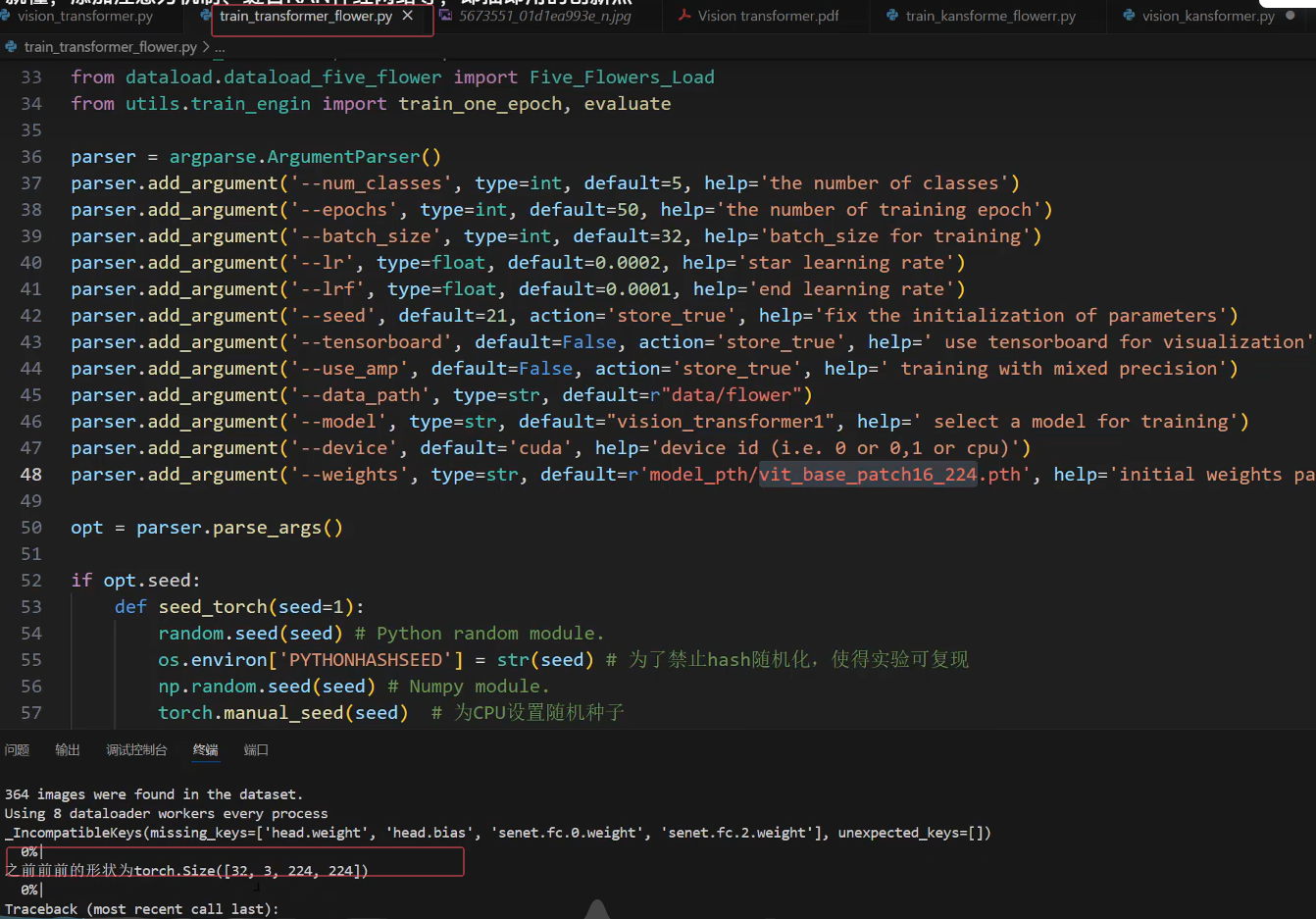
9.把输出的形状大小做注释,写在print(f"之前前前的形状为{x.shape}")的后面
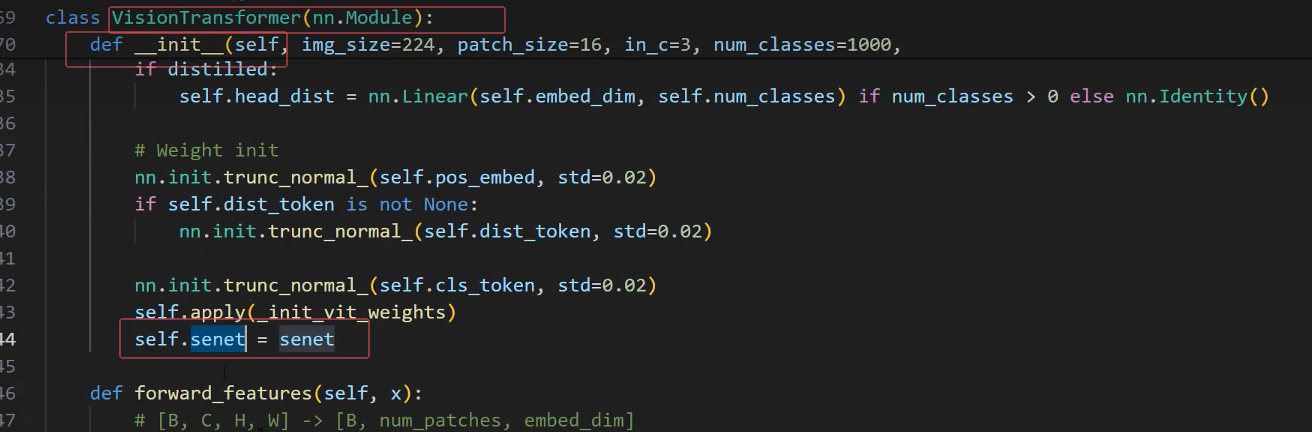
10.在 class VisionTransformer(nn.Module): 初始化里面找到def init ,在最后面加上
self.senet=senet
11.找到后面的 forward部分
python
x= self.senet(x)//对上x的通道数即可,由上面的【32,3,224,224】可知,通道数=3
x=self.forward_features(x)//特征提取- 返回文件开头,填写channel=3
python
senet(自己定的命名)=SELayer( 类名)(channel=3)13.保存代码,开始运行trian代码
加在Patch Embedding之后,进入 Transformer Blocks之前:(三维转四维)
1.先找到 class VisionTransformer(nn.Module):
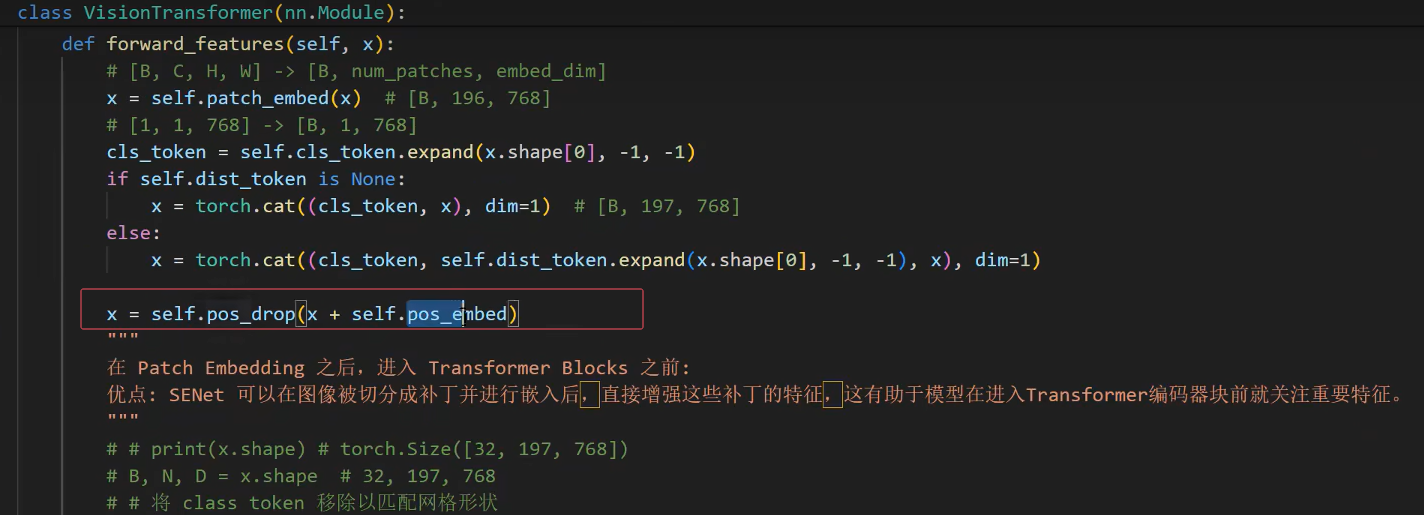
中的 def forward_features(self, x):
x = self.pos_drop(x + self.pos_embed)
//pos_embed模块使用的地方,如果找不到问ai
2.找到Transformer Blocks
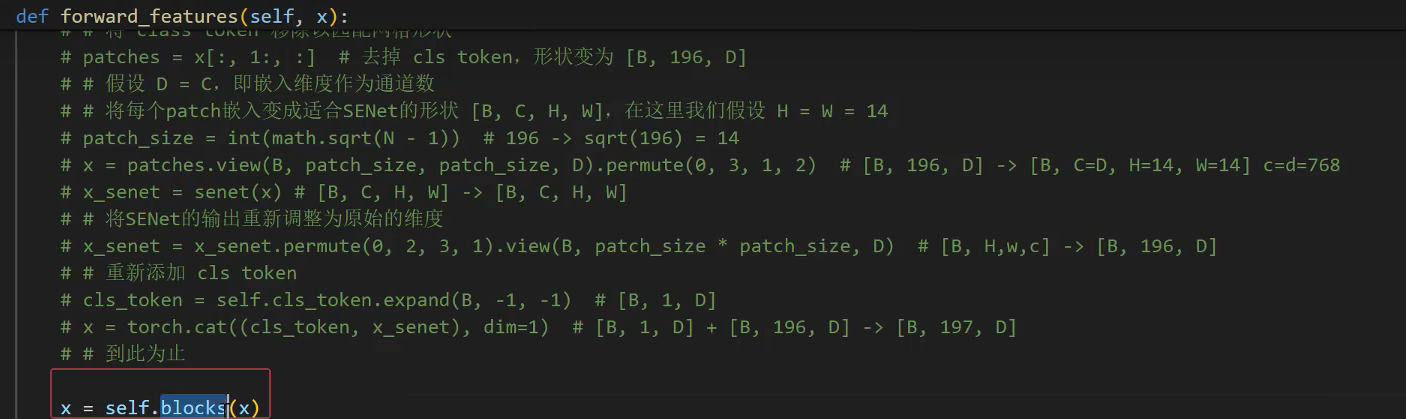
3.在两者中间加SENet,先打印x的形状
python
#1.打印x的形状
print(x.shape)# torch.Size([32,197,768])
#2.设置参数放对应的值
B, N,D = x.shape # 32, 197,768
# 3.将class token移除以匹配网格形状
patches = x[:, 1:, :] #去掉 cls token,形状变为[B,196,D]
# 假设D=C,即嵌入维度作为通道数
#4.将每个patch嵌入变成适合SENet的形状[B,C,H,W],在这里我们假设H=W=14
patch_size = int(math.sqrt(N - 1)) # 196 -> sqrt(196) = 14,即切片大小
x = patches.view(B, patch_size, patch_size, D).permute(0, 3, 1, 2) # [B, 196, D] -> [B, C=D, H=14, W=14] c=d=768, primute里面的0,表示第一个B不变位置,3对应原本的D-》D放第二个位置,原本1位和2位的patch_size, patch_size 都后移一位
# 注意:这里的C=D=768-》channel=768
#5.重新输入调整
x_senet = senet(x) # [B, C, H, W] -> [B, C, H, W]
#6.将SENet的输出重新调整为原始的维度
x_senet = x_senet.permute(0, 2, 3, 1).view(B, patch_size * patch_size, D) # permute后的结果:[B, H,w,c] -> [B, 196, D]
# 7.重新添加 cls token
cls_token = self.cls_token.expand(B, -1, -1) # [B, 1, D]
x = torch.cat((cls_token, x_senet), dim=1) # [B, 1, D] + [B, 196, D] -> [B, 197, D]4.在class VisionTransformer(nn.Module):的init里面对senet示例化
python
self.senet=senet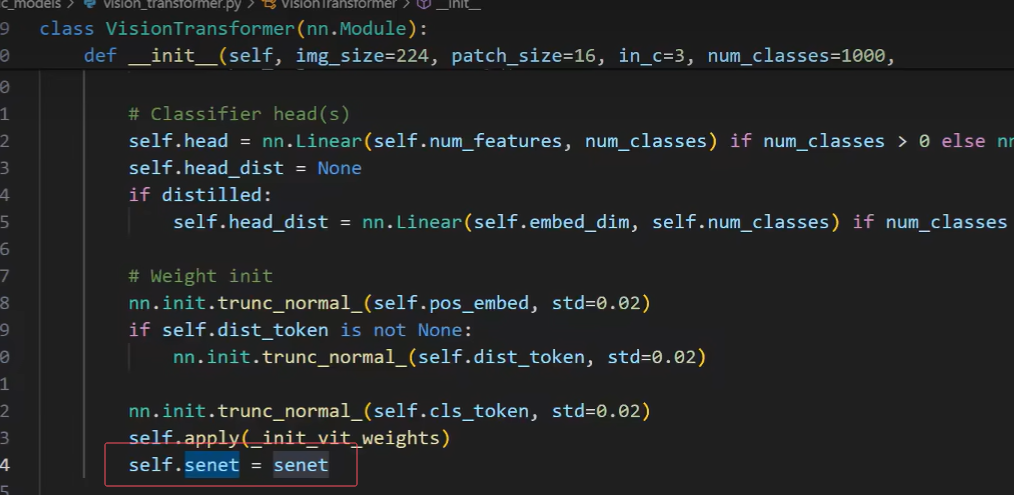
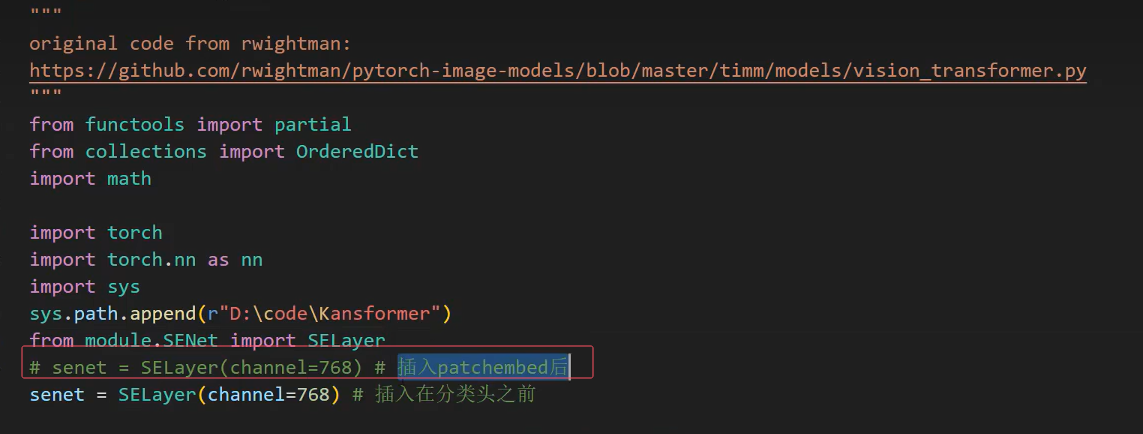
5.注意到channel=768,把开头import后面的channel改为768
加到MLP Head之前(二维转4维)
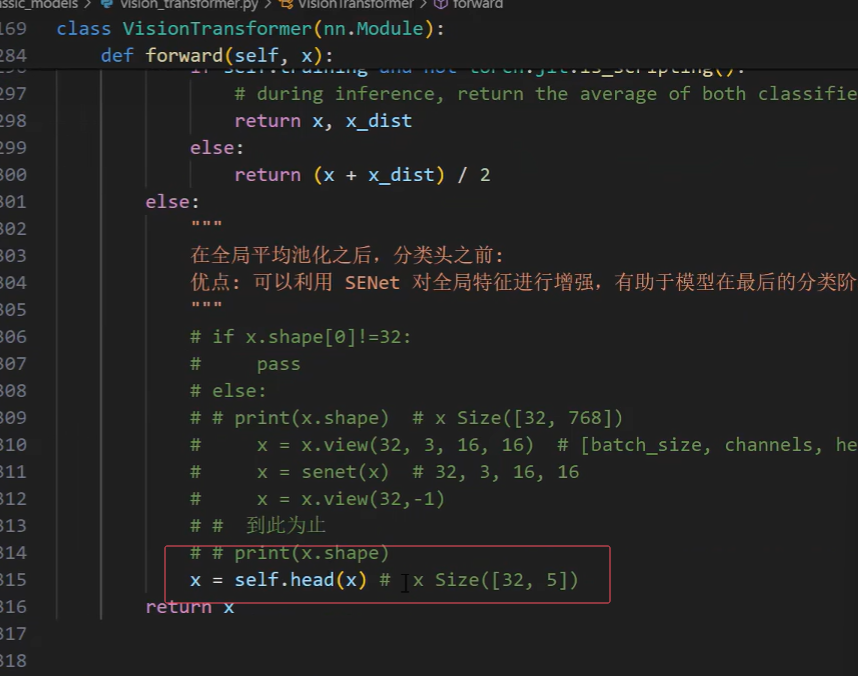
1.找到要改的这个类 class VisionTransformer(nn.Module): ,找到其中的 def forward(self, x):
找到MLPHead应用的地方
2.在前面 print(x.shape)->运行train代码
python
if x.shape[o]!=32: #如果第一个不是,32pass
pass
else:
x = x.view(32, 3, 16, 16) # [batch_size, channels, height, width] 把768化为3*16*16,编成4维的
#注意这里的channel=3
x = senet(x)# 32,3,16,16 进入SENet
x= x.view(32,-1) # -1表示默认计算后面3个的维度,即3*16*16,-1也可以写768
#结束
print(x.shape)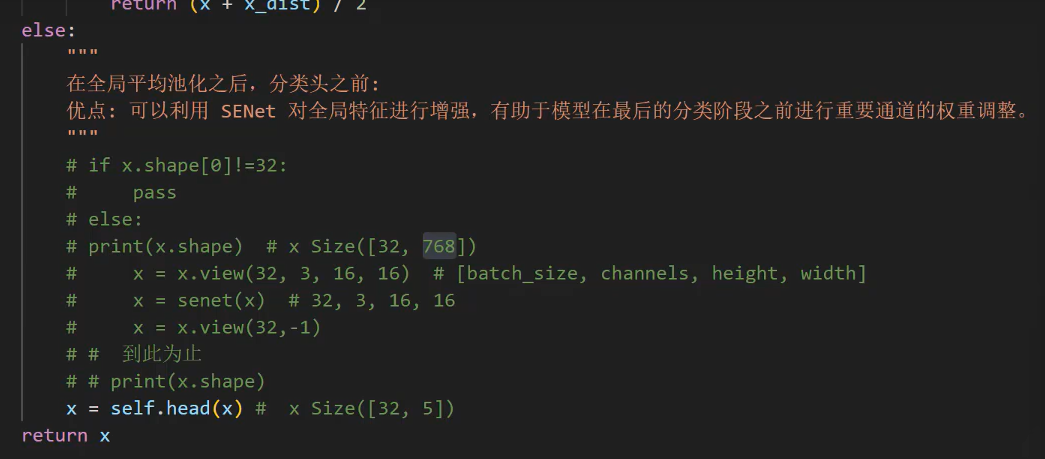
4.在代码前面加
python
from module.SENet import SELayer
senet = SELayer(channel=3)