实验目标:
本节课实验将完成Spark 4种部署模式的另外2种,分别是Yarn、windows模式。
实验准备工作:
- 三台linux虚拟机
- spark的压缩包
实验步骤
Spark-yarn
- 解压缩文件,并重命名为spark-yarn。
tar zxvf spark-3.0.0-bin-hadoop3.2.tgz
mv spark-3.0.0-bin-hadoop3.2 spark-yarn

- 修改配置文件
(1)修改hadoop配置文件/opt/software/hadoop/hadoop-2.9.2/etc/hadoop/yarn-site.xml,并分发给其他节点。
①修改配置文件:

是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
②分发给其他节点:

(2)返回到spark-yarn目录,修改conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置。
mv spark-env.sh.template spark-env.sh
v i spark-env.sh

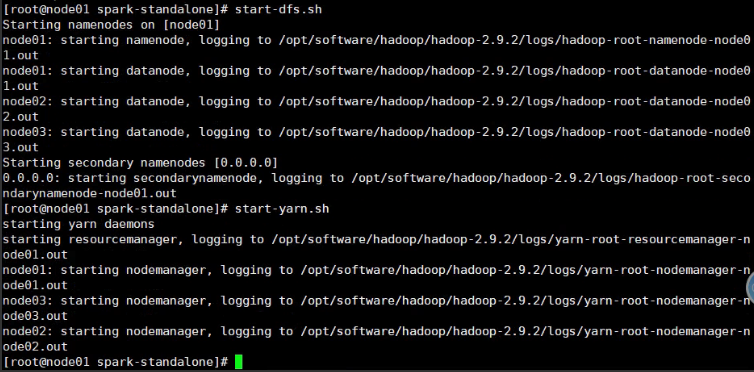
(3)启动HDFS以及Yarn集群
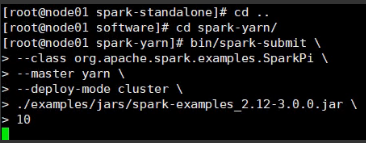
(4)提交测试应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
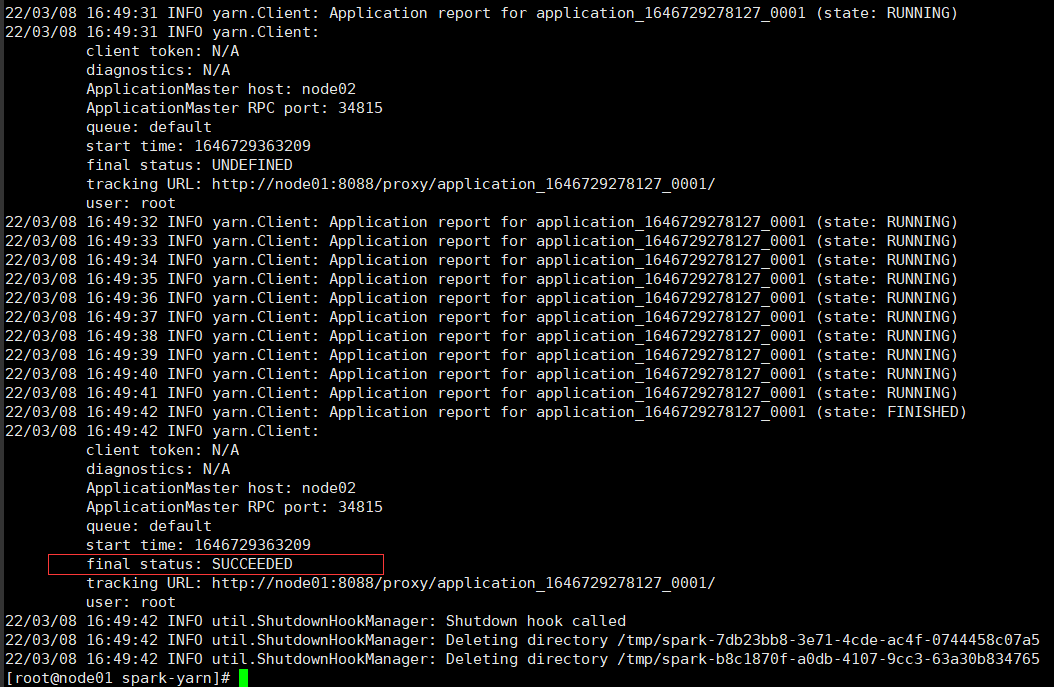
查看node01:8088页面
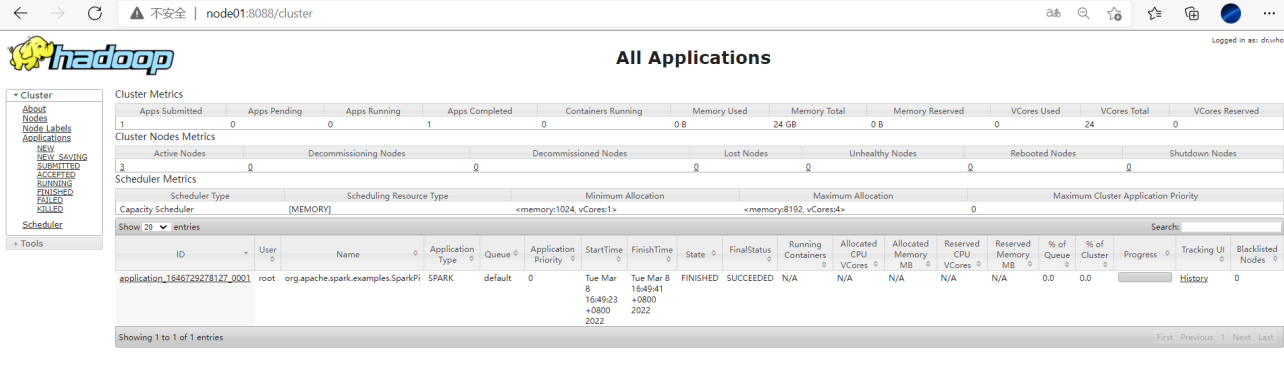
配置历史服务
由于 spark-shell 停止掉后,集群监控 node01:4040 页面就看不到历史任务的运行情况,所以 开发时都配置历史服务器记录任务运行情况。
- 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
- 修改 spark-default.conf 文件,配置日志存储路径
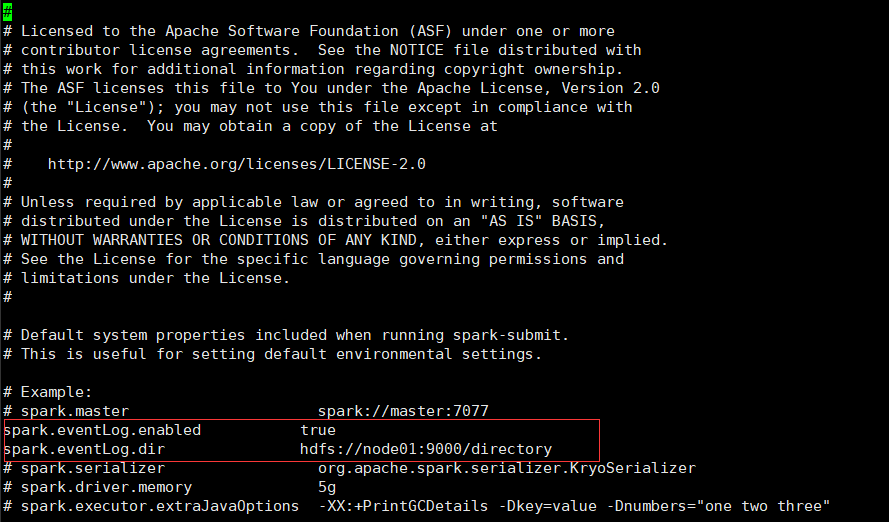
注意: 需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
h d fs dfs -mkdir /directory
- 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node01:9000/directory
-Dspark.history.retainedApplications=30"
参数含义:
⚫ 参数 1 含义:WEB UI 访问的端口号为 18080
⚫ 参数 2 含义:指定历史服务器日志存储路径
⚫ 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 开启历史服务,并且重新提交应用
sbin /start-history-server.sh
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

Windows 模式
- 将文件 spark-3.0.0-bin-hadoop3.2.tgz 解压缩到无中文无空格的路径中。
- 启动本地环境
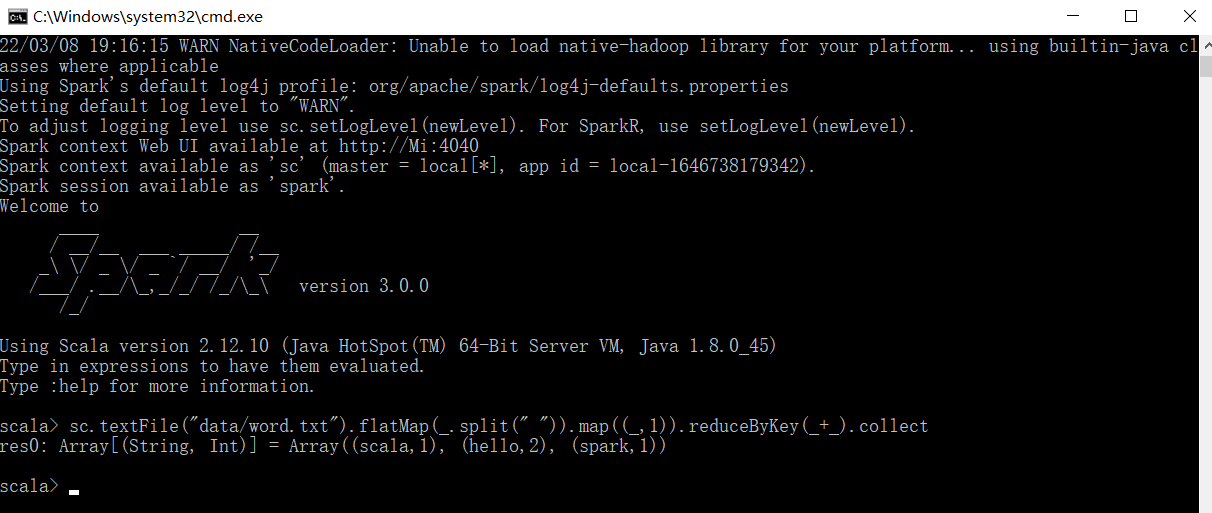
执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境
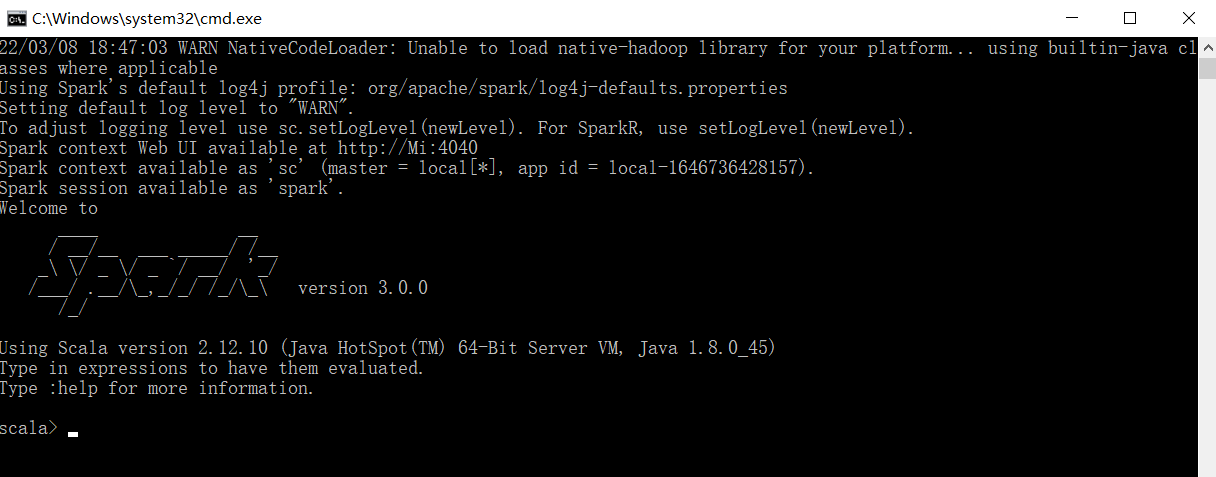
在命令行工具中执行如下代码指令。
sc.textFile("data/word.txt").flatMap(.split(" ")).map((,1)).reduceByKey(+).collect