在现代电力系统的运维管理中,红外热成像 已经成为检测设备隐患、预防故障的重要手段。相比传统可见光图像,红外图像可揭示设备温度分布,从而更直观地反映过热、老化等问题。而在AI赋能下,通过实例分割技术对热成像中的电力设备进行精细识别与区域分割,为智能巡检系统提供了关键能力支持。
本文将介绍一个专注于电力设备的热成像实例分割数据集,该数据集通过红外图像标注,助力模型精准识别高压场景中的关键部件,为智能运维提供视觉基础。
一、数据集概述
该数据集主要包含高压电力系统中典型设备的红外热成像图像 ,并为每张图像中存在的设备进行了像素级别的实例分割标注。相较于常规目标检测框(bounding box),实例分割更精确地描绘出设备的形状轮廓,适用于精细识别与空间分析任务。数据集中共标注了以下 3 类关键电力设备:
| 类别编号 | 类别名 | 说明 |
|---|---|---|
| 0 | Bushing |
套管,高压电流引出设备的重要绝缘部件,过热可能导致放电事故 |
| 1 | Current_Transformer |
电流互感器(CT),用于测量与保护,次级短路可能导致升温 |
| 2 | Lightning_Arrester |
避雷器(LA),防止雷击冲击电网,老化或失效后可能局部发热 |
这些设备在电力运维中均为重点监测对象,尤其在高温环境或负荷较大的情况下更易发生热故障。
-
📊 图像总数 :8385 张
-
🏷 目标类别数 :3类
-
📁 标注格式 :YOLO 格式、json格式、Mask格式
每张图像都配有精确的目标轮廓标注,并标注了对应的部件类别,用于支持目标分割任务。标注后的数据集如下所示:
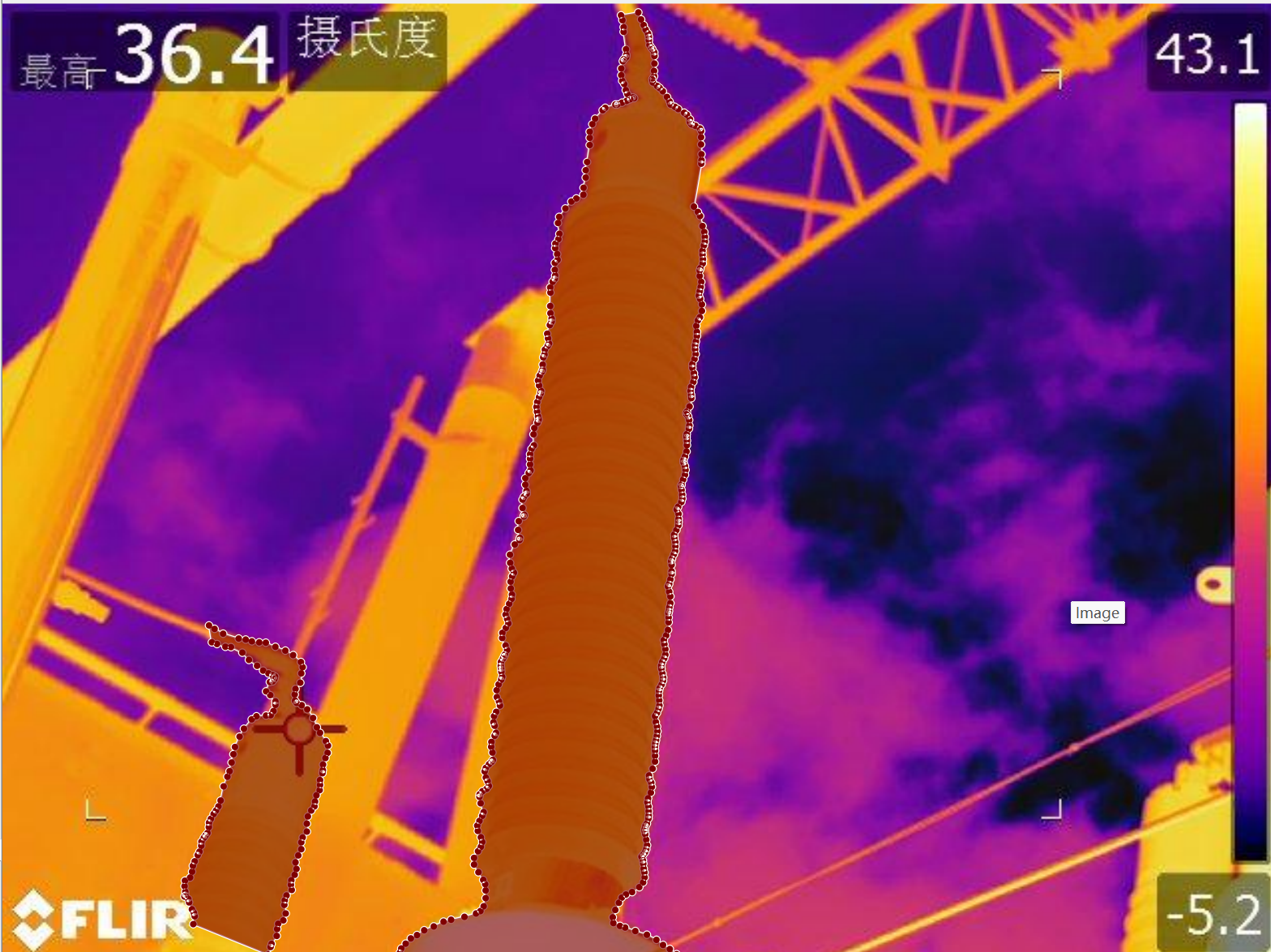


二、数据集标签介绍
为了方便在不同任务或模型中使用,该热成像实例分割数据集提供了三种主流的标签格式:YOLO格式、JSON格式、Mask格式。
3.1 分割 JSON 格式
JSON 标签格式是通过 LabelMe 工具标注生成的。LabelMe 是一款轻量级且功能强大的开源图像标注工具,广泛应用于实例分割、目标检测和图像分类等视觉任务。它支持手动绘制多边形、矩形等多种标注形状,并将标注结果以结构化的 JSON 文件形式保存,便于后续数据处理与模型训练。
3.2 分割 yolo 格式
为了支持 YOLO 系列实例分割模型(如 YOLOv11-seg)的训练,本文提供了将 LabelMe 生成的 JSON 标注文件转换为 YOLO 实例分割格式 的转换代码。该过程的核心在于:提取 JSON 文件中的多边形坐标点,并将其按照图像尺寸进行归一化处理,以满足 YOLO 格式对坐标规范的要求。代码如下所示:
python
import json
import os
class_dict = {
"Bushing": 0,
"Current_Transformer": 1,
"Lightning_Arrester": 2
}
def translate_info(label_json, label_txt):
# 检查json文件是否存在
assert os.path.exists(label_json), "file:{} not exist...".format(label_json)
# read json
with open(label_json, "r") as f1:
data = json.load(f1)
img_height = data['imageHeight']
img_width = data['imageWidth']
object_num = len(data['shapes'])
with open(label_txt, "w") as f:
for index in range(object_num):
seg_label = []
# 获取每个object的类别信息和关键点信息
class_name = data['shapes'][index]['label']
class_index = class_dict[class_name] # 目标id从0开始
seg_label.append(class_index)
seg_points = data['shapes'][index]['points']
for point in seg_points:
point_x = round(point[0] / img_width, 6)
point_y = round(point[1] / img_height, 6)
seg_label.append(point_x)
seg_label.append(point_y)
info = [str(i) for i in seg_label]
f.write(" ".join(info) + "\n")
def main():
label_json_path = r"./data/labels_json"
label_txt_path = r"./data/labels_yolo"
label_list = os.listdir(label_json_path)
label_list = [label for label in label_list if label.endswith('.json')]
for label_name in label_list:
label_name = label_name.split(".json")[0]
label_xml = os.path.join(label_json_path, label_name + ".json")
label_txt = os.path.join(label_txt_path, label_name + ".txt")
translate_info(label_xml, label_txt)
if __name__ == "__main__":
main()3.3 分割 mask 格式
为了支持 UNet 及其变体(如 UNet++、Attention-UNet 等)等语义分割模型的训练,本文提供了将 LabelMe 格式的 JSON 标注文件转换为 mask 标签图的方法。在转换过程中,根据 JSON 文件中每个电力设备的多边形轮廓信息,在与原始红外图像尺寸一致的空白图像上绘制对应的填充区域,从而生成像素级的 mask 图像。
在生成的 mask 中,背景区域的像素值为 0,各电力设备实例的区域像素值依次递增(如 1 表示 Bushing,2 表示 Current_Transformer,3表示 Lightning_Arrester),满足多类别实例分割任务的需求。所有生成的 mask 标签图与原始图像保持相同命名,便于训练过程中进行自动加载与配对使用。
python
import cv2
import json
import numpy as np
import os
class_dict = {
"Bushing": 1,
"Current_Transformer": 2,
"Lightning_Arrester": 3
}
def json_to_mask(image_path, json_path, save_mask_path):
# 读取 JSON 文件
with open(json_path, mode='r', encoding="utf-8") as f:
configs = json.load(f)
# 获取图像尺寸
shapes = configs["shapes"]
image = cv2.imread(image_path)
imageHeight, imageWidth = image.shape[:2]
# 创建空白图像用于生成掩码
mask = np.zeros((imageHeight, imageWidth), np.uint8)
# 绘制轮廓,将所有有标注的区域填充为 对应的数值
for shape in shapes:
label_name = shape["label"]
points = np.array(shape["points"], dtype=np.int32)
cv2.drawContours(mask, [points], -1, class_dict[label_name], -1) # 255 表示白色,-1 表示填充
# 保存生成的掩码图像
cv2.imwrite(save_mask_path, mask)
return mask
if __name__ == "__main__":
save_mask_root = r'./labels_mask' # 保存mask图路径
json_root = r'./labels_json' # 读取json路径
image_root = r'./images' # 原始图像
# 确保保存目录存在
os.makedirs(save_mask_root, exist_ok=True)
# 遍历 JSON 文件并生成掩码
for file in os.listdir(json_root):
name, ext = os.path.splitext(file)
image_path = os.path.join(image_root, f"{name}.jpg")
save_mask_path = os.path.join(save_mask_root, f"{name}.png")
json_path = os.path.join(json_root, file)
# 检查图像和 JSON 文件是否存在
if os.path.exists(image_path) and os.path.exists(json_path):
json_to_mask(image_path, json_path, save_mask_path)基于上述处理流程,热成像电力设备实例分割数据集已完成图像与标签的标准化转换,统一提供以下内容:
-
经过预处理并转换为
.jpg格式的红外图像; -
对应的三种类型标注文件,包括:
-
YOLO 格式(适用于 YOLO 系列的实例分割模型,如 YOLOv8/v11-seg);
-
Mask 图像格式(适用于 UNet 及其变体,如 UNet++、Attention-UNet 等语义分割模型);
-
LabelMe 原始 JSON 格式(用于可视化查看和进一步标注编辑)。
-
下载链接 :热成像实例分割电力设备数据集