训练和测试的规范写法
知识点回顾:
1.彩色和灰度图片测试和训练的规范写法:封装在函数中
2.展平操作:除第一个维度batchsize外全部展平
3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
torch.manual_seed(42)
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
print(device)
python
#1预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081,))
]
)
#2加载数据集
train_dataset = datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root="./data",
train=False,
download=True,
transform=transform
)
#3创建数据加载器
batch_size = 64
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False
)
#4定义模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 128)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
model = MLP()
model = model.to(device)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
python
#5训练模型(记录每个iteration的loss)
def train(model, train_loader, test_loader, criterion, optimizer, epochs, device):
model.train() #设置为训练模式
#记录损失
all_iter_losses = [] #记录所有batch的loss
iter_indices = [] #记录每个iteration的索引
for epoch in range(epochs):
running_loss = 0.0 #记录每个epoch的loss
correct = 0 #记录每个epoch的correct
total =0 #记录每个epoch的total
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()#梯度清零
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
#记录当前iteration的损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
#统计准确率和损失
running_loss += loss.item()
#`_`来表示我们不关心第一个返回值(即最大值),只关心第二个返回值(即最大值的索引),这个索引就是模型预测的类别。
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
#每100个batch打印一次训练状态
if (batch_idx + 1) % 100 == 0:
print(f"Epoch:{epoch + 1}/{epochs}|Batch:{batch_idx + 1}/{len(train_loader)}",
f"|单batch损失:{iter_loss:.4f}|累计平均损失:{running_loss/(batch_idx + 1):.4f}|")
#测试,打印结果
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
epoch_test_loss, epoch_test_acc = test(model, test_loader, criterion,device)
print(f"Epoch{epoch + 1}/{epochs}完成|训练准确率:{epoch_train_acc:.2f}|测试准确率:{epoch_test_acc:.2f}")
#绘制所有iteration损失函数
plot_iter_losses(all_iter_losses, iter_indices)
return epoch_test_acc
python
#6测试模型
def test(model, test_loader, criterion, device):
model.eval() # 设置为评估模式
test_loss = 0
correct = 0
total = 0
with torch.no_grad():#测试时关闭梯度计算
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
avg_loss = test_loss / len(test_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
python
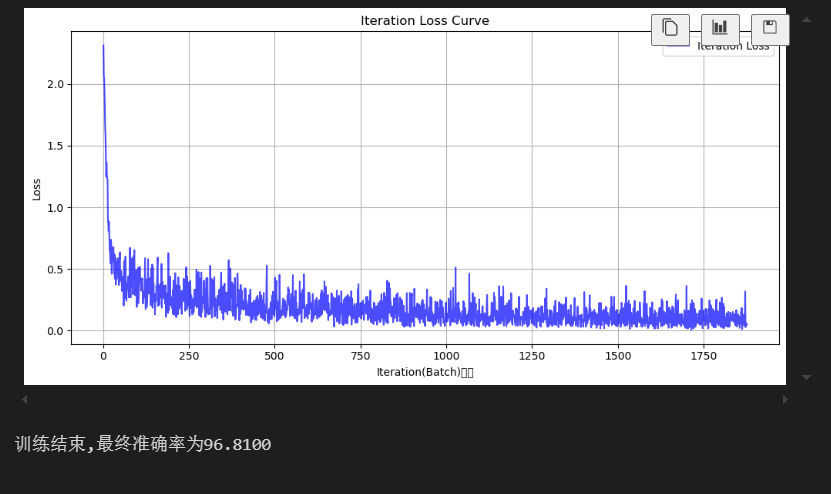
#7绘制损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 5))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch)序号')
plt.ylabel('Loss')
plt.title('Iteration Loss Curve')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
python
#8执行训练和测试(epochs=2 验证结果)
epochs = 2
print("开始训练")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, epochs, device)
print(f"训练结束,最终准确率为{final_accuracy:.4f}")